一种基于Android 系统的大数据计算和存储平台
2021-10-12刘勇陆小慧
[刘勇 陆小慧]
1 研究背景
1.1 Hadoop
Hadoop 是一个由Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop 实现了一个分布式文件系统HDFS(Hadoop Distributed File System),HDFS 有高容错性的特点,并设计用来部署在相比小型机更为廉价的(Low-cost)PC服务器上;而且它提供高吞吐量(High throughput)来访问应用程序的数据,适合那些有着超大数据集(Large data set)的应用程序。HDFS 放宽了POSIX 的要求,可以以流的形式访问(Streaming access)文件系统中的数据。
Hadoop 框架最核心的设计是HDFS 和MapReduce:HDFS 为海量的数据提供了存储方式,MapReduce 为海量的数据提供了计算方式。
目前Hadoop 在大数据的通行市场上占据主导地位。基于开源免费、硬件廉价、开发便利这3 个原因使得Hadoop 市场份额逐年高速递增。事实上在软件的成本之外,硬件产生的经济成本更为可观,如何降低硬件成本是每一个应用运营商都在考虑并寻求解决方案的课题。
1.2 计算芯片
目前Intel 公司的CPU 占据着市场的主导地位,导致PC 服务器的CPU 价格居高不下,一颗服务器至强E3 型号的4 核CPU 处理器价格在1 500 元左右。而智能终端所用的CPU 处理器,如联发科MT6582 处理器只有42 元。这两者价格相差30 倍左右,功耗相差1 000 倍左右。而两者之间的性能差距,平均到单核上,至强处理器只有智能终端处理器的5 倍左右。
一台100 个智能终端组成的集群(如手机集群),成本可以控制在1 到2 万元,物理体积和一台普通PC 服务器相当,计算性能是一台PC 服务器的5~10 倍,功耗可以控制在PC 服务器的1/10 到1/20。
1.3 Hadoop on Android
在现有技术上,基于智能终端的Android 系统不能支持Hadoop 的运行,本方案是建立一个中间层保障Hadoop和Android 之间的适配以及运行。
本文所述智能终端以手机终端进行举例,不限制于运行Android 系统的手机终端、PAD、机顶盒,以及运行Android 系统的各类手持设备。
2 系统定义与关键技术
2.1 系统定义
一个大数据计算集群是由分布式软件和硬件集群一起组成的,本文研究并提供一个优秀的廉价、易用、便携的大数据计算和存储平台。使用本平台后,能快速、方便且更为廉价地为企业提供分布式计算、云计算服务。
2.1.1 Hadoop on Android
基于Android 系统的Hadoop 分布式计算平台,使得Hadoop 可以在 Android 系统上正常运行;并且提供Hadoop 运行时软件和硬件的健康监控,损坏时触发对软件的修复或对硬件的替换。
2.1.2 软件架构
图1 为移动云计算中间平台在软件系统的位置,该平台位于Android 系统和Hadoop 之间。
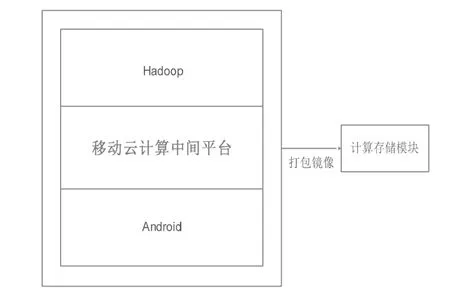
图1 软件架构
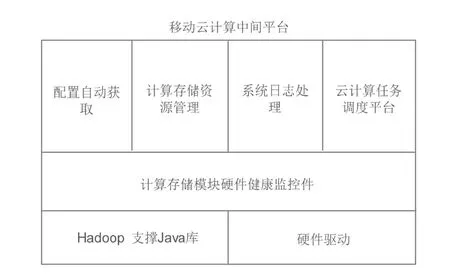
图2 移动云计算中间平台内功能模块
模块一:硬件驱动
移动云计算中间平台为操作系统加载硬件驱动,该驱动主要为网络控制器服务。
模块二:Hadoop 支撑Java 库
移动云计算中间平台为Hadoop 提供Android 系统缺少的Java 库。Android 系统支持一部分Java 功能,该平台可补足Android 系统中缺少的Java 库。
模块三:硬件健康监控
移动云计算中间平台为智能终端提供硬件健康监控,监控并提供修复操作。当硬件出现问题后会进行重连/重启操作,多次重连/重启失败后,提示替换该硬件。监控功能使用心跳检测机制以及温度检测来监控硬件。
模块四:配置自动获取
网络配置自动化:移动云计算中间平台能够在第一次启动时,为智能终端分发一个固定地址,当在无线连接下,IP 地址由无线DHCP 自动分配,读取分配的IP 地址写入Hadoop 配置文件中。
同时,根据加入集群的智能终端的计算能力、存储大小来自动设置Hadoop 的运行配置。
模块五:计算存储资源管理
在当前Hadoop 计算和存储控制的基础上整合到平台中,对计算和存储的资源进行软件管理,基于计算存储资源的饱和度来进行资源平衡处理。
当集群接收外来写入和计算任务时,先确认当前集群中机器的资源使用状况,然后调取Hadoop 的任务分配方法:存储已经超出设定限额上限的将不接受写入操作,计算超出设定限额上限的将不接受计算任务;当存储低于设定限额下限时将优先写入,直到到达设定限额的上限;当计算低于设定限额下限时将优先接受计算任务;直到到达设定限额的上限;其他处于上限和下限之间的机器获取任务时进行随机分配。
模块六:系统日志处理
当系统日志大于设定的范围值时,日志的存储进行FIFO(First in first out) 存储。也就是先删除远期日志,然后存储最新的日志。
模块七:云计算任务调度
提供给外部接口进行云计算管理,该管理包括启动、停止、暂停、定时等功能。
2.2 技术方案
图3 为移动云计算中间平台功能流程图,详细描述了一台智能终端在安装移动云计算中间平台后各模块的工作流程情况。
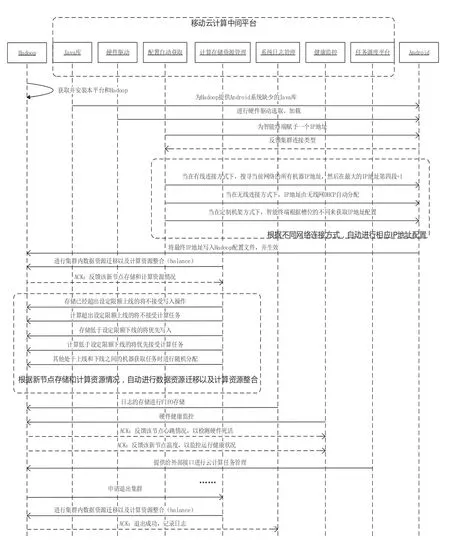
图3 移动云计算中间平台功能流程图
2.2.1 Android API 接口的封装
Hadoop 通过移动云计算中间平台对底层Android 系统调用各API 功能接口进行数据读写、计算等任务。
(1)手机内存数据读写
getFileDir():得到Hadoop 在手机内存存储数据的位置/data/data/Hadoop/files
getCacheDir():得到Hadoop 在手机内存缓存数据的位置/data/data/Hadoop/cache
openFileInput(String name):直接得到/data/data/Hadoop/files/name 文件的输入流
openFileOutput(String name,int mode):直接得到/data/data/Hadoop/files/name 文件的输出流,mode 为写入文件时的权限
Context.MODE_PRIVATE:私有模式(默认模式),只能被应用本身和同一群组的人访问;写入的内容覆盖原文件内容
Context.MODE_APPEND:追加模式也是私有模式,只能被应用本身和同一群组的人访问;如果文件存在就追加内容,如果文件不存在就新建文件并写入内容
Context.MODE_WORLD_READABLE:所有人可读权限
Context.MODE_WORLD_WRITEABLE:所有人可写权限
(2)SDcard 数据读写
getExternalStorageDirectory():得到Hadoop 所在智能终端的SDcard 位置/storage/sdcard
getExternalStorageState():得到Hadoop 所在智能终端的SDcard 的当前状态,比较常用的是MEDIA_MOUNTED
使用FileInputStream 读取文件
使用BufferReader 读取文件
httpConnection 读取流保存成String 数据
使用FileOutputStream 写入文件
使用BufferedWriter 写入文件
(3)Hadoop 计算使用Java 的加(+)减(-)乘(*)除(/)四则运算
2.2.2 Hadoop on Android 存储和计算过程
Hadoop HDFS 集群有两类节点,并以“管理者—工作者”模式运行,即一个NameNode(管理者,Master)和多个DataNode(工作者)。每一个NameNode 和DataNode 都各对应一台智能终端。
NameNode 是管理者(Master),主要负责管理HDFS文件系统,具体包括namespace 管理、block 管理;DataNode 主要是用来存储数据文件。HDFS 将一个文件分割成一个个的block,这些block 可能存储在一个DataNode 上或者是多个DataNode 上。DataNode 负责实际的底层文件的读写,如果客户端client 程序发起了读HDFS 上的文件的命令,那么首先将这些文件分成block,然后NameNode 将告知client 这些block 数据是存储在哪些DataNode 上的,之后,client 将直接和DataNode 交互。
(1)Hadoop on Android 存储数据过程
我们以文件上传到分布式集群进行Hadoop on Android 存储数据的过程进行举例。
NameNode 负责管理存储在Hadoop HDFS 上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的数据节点(DataNode)集合。它把该信息存储在内存中的文件分配表里。
例如,客户端发送一个请求给NameNode,说它要将“swimmer.txt”文件写入到HDFS。那么,其执行流程如图4 所示。具体为:
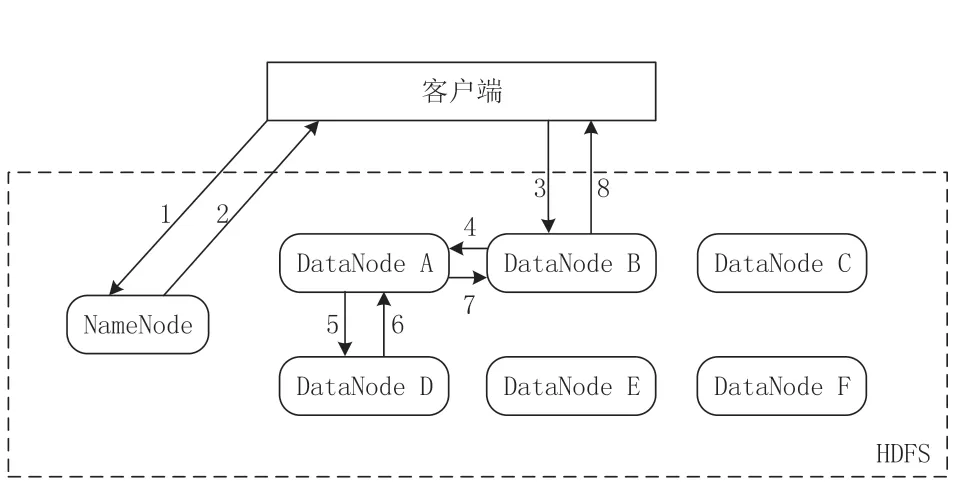
图4 文件上传到Hadoop on Android 分布式集群流程图
步骤1,客户端发消息给NameNode,说要将“swimmer.txt”文件写入。
步骤2,NameNode 发消息给客户端,叫客户端写到DataNode A、B 和D,并直接联系DataNode B。
步骤3,客户端发消息给DataNode B,叫它保存一份“swimmer.txt”文件,并且发送一份副本给DataNode A和DataNode D。
步骤4,DataNode B 发消息给DataNode A,叫它保存一份“swimmer.txt”文件,并且发送一份副本给DataNode D。
步骤5,DataNode A 发消息给DataNode D,叫它保存一份“swimmer.txt”文件。
步骤6,DataNode D 发确认消息给DataNode A。
步骤7,DataNode A 发确认消息给DataNode B。
步骤8,DataNode B 发确认消息给客户端,表示写入完成。
这样,一份“swimmer.txt”文件就保存在了分布式集群A、B、D 三个数据节点(智能终端)上。
(2)Hadoop on Android 计算过程
在Hadoop on Android 中,每个MapReduce 任务都被初始化为一个Job,每个Job 又可以分为两种阶段:map阶段和reduce 阶段。这两个阶段分别用两个函数表示,即map 函数和reduce 函数。map 函数接收一个
2.2.3 无线连接
一般常见的智能终端,在安装移动云计算中间平台和Hadoop 之后,使用稳定的无线连接,经过本平台对Hadoop 进行配置后,即可进行Hadoop 之上的各组件的使用。

图5 Hadoop on Android 处理大数据集的过程
比如你所在的办公室,可以把大家的智能终端集中到一个集群内,实现计算资源和存储资源共享。一个人的手机无法做到的较大计算量,通过十几个人的手机就可以组建起集群,然后完成本来不能完成的计算量。
无线连接又分为WIFI 网络与移动网络(4G/5G/……)两种集群组建方式;具体实现过程,在实施例里详细描述。
3 具体实施方式及附图
3.1 实施例一 无线网络(WIFI,4G、5G,……)连接
无线网络(含WIFI,4G、5G、……)的组网图如图6 所示,连接流程以如下步骤(见图7 所示)进行:
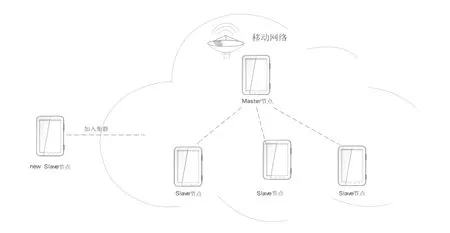
图6 无线网络连接组网图
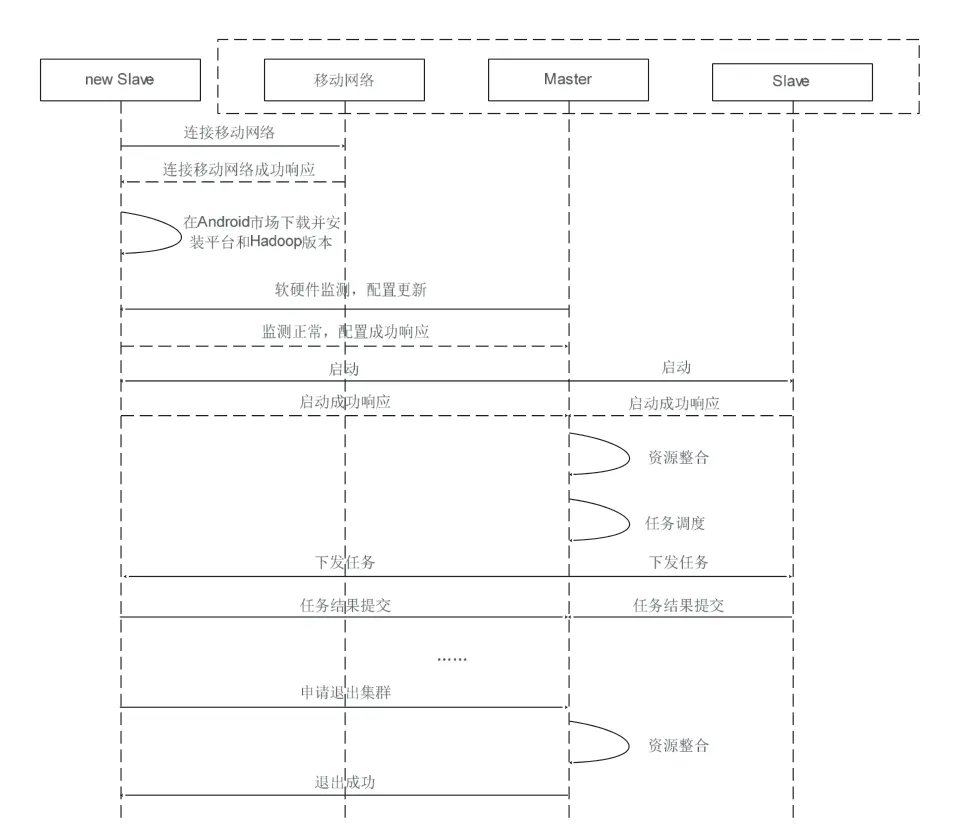
图7 无线网络连接流程图
步骤1,将智能终端移入现有集群无线网络。
步骤2,获取并安装好移动云计算中间平台及Hadoop 平台。
步骤3,使用移动云计算中间平台配置Hadoop 系统网络(具体过程可见图3)。
在这里,我们设置连接方式Connection 参数 1:WIFI,2:移动网络。
在本实施例,Connection 传入参数2,则移动云计算中间平台根据该移动网络里面的DHCP 机制给新加入节点(智能终端)分配IP 地址;并写入集群配置文件中去。
步骤4,启动Hadoop 集群组件。
步骤5,进行集群内数据资源迁移以及计算资源整合(balance)。
在这里,移动云计算中间平台会根据新节点(智能终端)的存储和计算资源情况,自行进行数据资源迁移以及计算资源整合。我们设置每个节点的存储资源上限为总存储资源的80%以及下限为总存储资源的5%;设置每个节点的CPU 计算资源上限为CPU 利用率达到80%以及下限为CPU 利用率达到5%;其中上限、下限的设置阈值可以按需调整。
移动云计算中间平台根据设置阈值,进行如下操作:
当该节点存储已经超出设定限额上限时将不接受写入操作;
当计算超出设定限额上限时将不接受计算任务;
当存储低于设定限额下限时将优先写入,直到到达设定限额的上限;
当计算低于设定限额下限时将优先接受计算任务;直到到达设定限额的上限;
其他处于上限和下限之间时,获取任务时进行随机分配。
对于移动网络(Connection=2),考虑到传输速率以及流量资费的因素,我们设置一个数据压缩参数Compress参数1:压缩,0:不压缩。
当Connection=2 时,Compress 参数默认设置为1,数据传输时进行压缩,以获得高传输速率,降低流量资费。
当Connection=1 时,Compress 参数默认设置为0,数据传输不进行压缩,同时可减轻CPU 运算压力。
步骤6,调用本平台接口,提交Hadoop 任务进行运行。
步骤7,各数据节点完成任务计算,并反馈给主节点。
退出集群步骤:
步骤8,某个数据节点申请退出集群。
步骤9,主节点进行数据资源迁移并进行计算资源整合(balance)。
步骤10,资源整合完成后,数据节点退出集群。
3.2 实施例二 典型应用场景
在本实施例,我们举个典型应用场景进行详细描述本平台及系统的工作流程。
假设在一个房间,我们有5 个人手持5 台性能不一的Android 系统的智能手机,测试使用一款大型游戏,该游戏因计算量大且产生数据多,在一些计算和存储性能都比较低的手机,因不符合该游戏运行最低要求,运行非常卡顿甚至无法运行。我们可以使用本文的技术来解决,使得每台手机都能流畅的运行该游戏。
图8 示例画出2 台设备即Master 主节点与一台Slave 节点之间的业务流程;Master与其他Slave 节点之间的业务流程与图8 所示的业务流程一样。
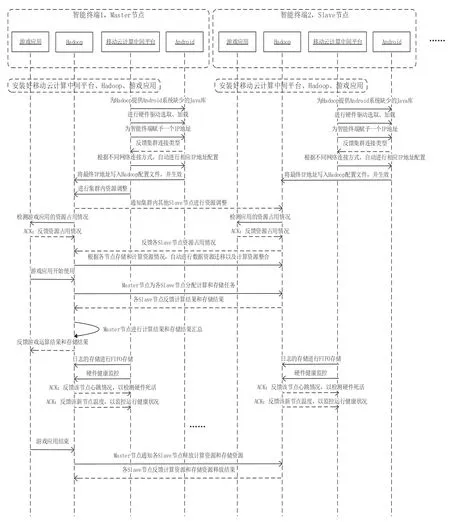
图8 典型应用场景流程图
步骤1,安装好移动云计算中间平台、Hadoop、游戏应用。
步骤2,移动云计算中间平台对Android系统及Hadoop 平台进行相关配置并生效(具体过程可见图3)。
步骤3,各节点检测游戏应用占用资源情况,并反馈到各节点的Hadoop 平台;各Slave 节点Hadoop 平台收到后,反馈到Master 节点。
步骤4,Master 节点根据各节点存储和计算资源情况,自动进行数据资源迁移以及计算资源整合。
步骤5,游戏应用开始使用,Master 节点收到使用行为和任务后,为各Slave 节点分配计算和存储任务。
步骤6,各Slave 节点向Master 节点反馈计算结果和存储结果,Master 节点进行计算结果和存储结果汇总。
步骤7,Master 节点反馈游戏应用运算结果和存储结果。
步骤8,在游戏应用的计算任务和存储任务进行过程中,移动云计算中间平台进行日志的存储,使用FIFO 方式存储。
步骤9,在游戏应用的计算任务和存储任务进行过程中,移动云计算中间平台进行各节点的硬件健康监控。
步骤10,游戏应用结束,Master 节点通知各Slave 节点释放计算资源和存储资源。
步骤11,各Slave 节点向Master 节点反馈计算资源和存储资源释放结果。
4 总结
通过本文,我们实现了移动云计算中间平台,一种基于Android 系统的Hadoop 分布式计算平台,该平台使得Hadoop 可以在 Android 系统上运行;并且清楚地描述了智能终端可以非常方便的组建、加入/移出无线网络组建的分布式集群。通过上述两点,实现了使用更为廉价且方便更换的智能终端作为平台,降低了分布式集群的成本。这样,我们就提供一个优秀的廉价、易用、便携的大数据计算和存储平台。使用本平台后,能快速、方便且更为廉价地为企业或团体提供分布式计算、云计算服务。
后续改进思考:
因无线网络存在地理位置、覆盖范围等弱网络影响因素,以及智能终端存在运动中、通话中、低电量等场景,数据传输存在不稳定性。因此,为了提高通信及数据传输的稳定性,我们可以改造智能终端,使用有线连接方式,这样集群的可靠性可以得到保障,数据传输速度可以得到加强。
使用有线连接方式的集群硬件来源可以为定制的智能终端,也可以使用现有智能终端进行有线通信的改造。如对智能终端数据传输接口进行改造,通过转换数据传输接口为双绞线或者光纤线通信,以增强数据传输的稳定性等。
此外,对于个人智能终端加入集群存在的隐私担忧,也可以通过在设备上划分独立存储区域、数据通信认证、个人数据保护等手段以保证隐私。在此不再行文赘述。
