基于粒子群算法优化设计RBM网络结构*
2021-10-09闻一波雷菊阳
闻一波 雷菊阳
(上海工程技术大学机械与汽车工程学院 松江 201620)
1 引言
受限玻尔兹曼机[1](RBM)是一种生成式随机神经网络,网络具有两层结构:可见层和隐藏层,采用层内无连接、层间全连接的方式。因其简单的网络结构和对比散度算法[2]的出现,RBM在分类、特征学习、降维等方面[3~5]得到了广泛应用。但是目前却很少有关于RBM网络结构设计的研究,也没有通用的规则[6]去制定其结构。文献[7]中提出遗传算法优化设计RBM网络结构的方法,该方法使用效果显著,受此启发探索其他方法去设计RBM网络结构。
粒子群算法是一种基于群体的智能优化算法[8],该算法具有群体智能、内在并行性、结构简单、收敛快速[9]等优点。粒子群算法作为一种进化算法,在处理非线性问题寻优方面有较好的鲁棒性和收敛性。
在制定RBM网络结构时,由于结构只有两层,所以可见层与隐藏层决定模型的复杂度。如果可见层的特征太多造成宁滥毋缺的局面,便会大大增加模型复杂度,倘若过分减少特征反而会导致输入样本包含信息过少,也不利于模型对于数据的学习。隐藏层的作用可以看作是对可见层特征的学习[10]和提取,隐藏层数目设置过大,模型计算过于复杂,太小又无法学习到可见层不同样本的差异,导致最后分类预测效果很差。
综合以上,PSO-RBM主要解决两个问题:一是利用粒子群算法给RBM筛选样本的特征,二是利用粒子群算法对隐藏层数目进行优化选择。
2 PSO-RBM算法设计
2.1 算法过程
粒子群算法作为RBM网络结构的优化设计,首先在搜索空间中初始化种群和速度,然后根据适应度函数计算出种群中不同个体的适应度值,接着利用速度和位置公式[11]进行更新调整。经过多次迭代后为RBM模型挑选出最优的个体,进而确定可见层特征维数以及隐藏层数目,将这些参数再应用到RBM中进行训练便得到结构简单的RBM模型。在整个算法设计过程中,根据已知的粒子群算法模型进行设计算法需要解决两个问题:个体变量和适应度函数设计。
2.2 个体变量设计
个体由两部分组成,分别为可见层特征维数和隐藏层数目。可见层中每一个神经元代表一个特征,特征维数过多导致模型计算复杂,维数过少则无法保证可见层本应包含的信息量,因此需要对可见层特征进行筛选。本文采用标称型数据,假定1代表选用该特征,0代表舍弃该特征。而粒子群算法通常适用于连续性变量问题,所以在个体变量设计时需要做出调整,方法如下:
假设可见层特征维数为N,生成N维的随机向量Xi=[xi1,xi2,…,xik,…,xiN](k<N),其中xik服从[-1,1]的均匀分布,该向量代表可见层特征是否选用的实数表达形式,那么在算法迭代更新过程中便可始终保持连续性。而在RBM模型中求解适应度值时将该向量转变为标称型变量,方式如下:
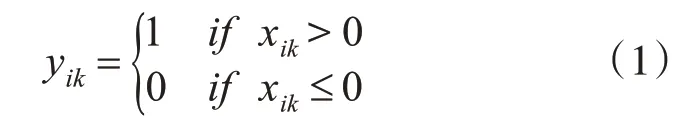
式(1)中1和0分别代表选用和舍弃,yik代表第i个个体中可见单元转变后对第k个特征的取舍。对于隐藏层数目,因为可见层与隐藏层之间是无向连接并且隐藏层神经元之间的状态相互是条件独立[12]的,所以只需要随机生成一个实数迭代训练且在RBM中取整即可。
综上,一个个体可以表示为pop(i)=[xi1,xi2,…,xiN,bi],其中pop(i)代表第i个个体,bi代表第i个个体中隐藏层数目实数表示。
2.3 适应度函数设计
RBM模型将个体转变后获取参数进行训练,然而评价RBM模型优劣需要一个衡量指标。本文采用重构误差[13]的方法,即输入数据与重构输入数据之间的差值。重构误差公式如下(采用二阶范数):
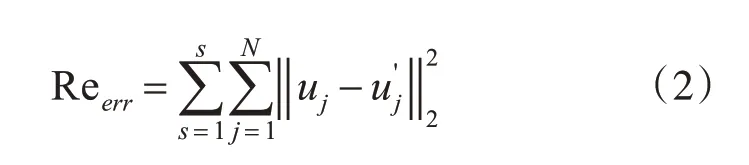
式中S和N分别代表训练样本个数和可见层特征维数,uj代表训练样本集中在第j维特征数据向量,代表输入样本重构后可见层第j维特征数据向量。所以适应度函数根据式(2)进行了定义,如下:
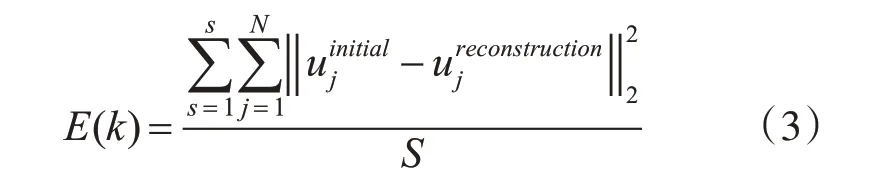
其中S和N的含义与式(2)一致,uinitial j代表在N维特征维数的原始数据中被选中的第j维的向量。代表被选中的第j维特征数据向量经过输入重构后的向量。式(3)表示一个个体在经过PSO-RBM模型训练后的重构误差与训练数据样本总数之商,很容易得到结论,适应度值E(k)越小,则该个体转变后的模型参数在RBM模型使用中效果越好。
3 实验分析
实验使用Matlab软件编程分析,将PSO-RBM应用到MNIST手写体数据集上优化RBM网络结构,然后与传统的RBM网络结构在正确率和训练时间比较,测试经过粒子群算法优化过的结构是否优于传统结构。MNIST数据集包含70000个样本,其中60000个样本作为训练数据,10000个作为测试数据。每一个样本代表一个手写数字,维度为28×28,展开为行向量为1×784,所以可见层特征维数N为784。最后加上一个隐藏层数目参数,那么最终在粒子群算法中每个个体的维数等于785。
粒子群优化算法中,参数设置如下:学习因子c1=c2=1.494,因为个体由两部分构成,所以它们的速度和位置搜索空间都不同。可见层特征维数:速度Vmax=0.2,Vmin=-0.2位置Fpopmax=1,Fpopmin=-1。隐藏层数目:速度Lmax=5,Lmin=-5位置Lpopmax=150,Lpopmin=-80。种群数目设为5,迭代50次停止。为了提高算法求解效率,在求适应度值时RBM模型训练次数设为1。由于粒子群算法不是全局收敛容易陷入局部极小值[14],因此实验一共实施5次,选取其中一次结果作为示例。
图1表示示例迭代次数与各代中的最佳适应度值的变化关系,从图中看出随着迭代次数的增加,PSO-RBM较为快速的收敛到最优处。将最优个体转变后得到可见层特征维数由784下降到314,隐藏层数目为149。
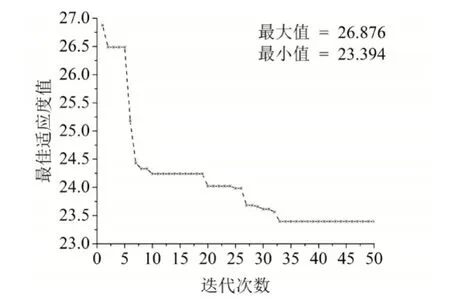
图1 最佳适应度收敛曲线
图2展示了十张从原始数字到降维后的数字图片,图中上部五张为原始数据集中的数字图片,下部五张为经过降维后的图片。能够看出个体中可见层特征维数对原始数据维数进行了筛选,虽然降维后的图片没有原来的图片清晰,不过也充分保留了数字的基本特征。

图2 原始数字及降维后的数字
由于RBM是无监督学习[15],当前只是优化网络结构并没有实际运用到测试数据中测试其网络性能,因此要实现对MNIST手写体数据集的分类预测还要在原有RBM上增加一个分类器。本文采用神经网络[16]作为分类器,选用三种RBM网络结构比较分析,结构如下:
1)RBM,原始数据特征维数和较少的隐单元数目即784-100。
2)RBM,原始数据特征维数和较多的隐单元数目即784-400。
3)PSO-RBM,经过粒子群算法优化后的RBM即314-149。
从表中看出PSO-RBM的错误率低于结构1)高于结构2),不过训练时间却是最短的。结构2)虽然错误率最低但是它的训练时间太长甚至达到PSO-RBM的15倍左右,时间成本太高。综上可以得到结论:
1)个体中可见层特征维数转变后对原始数据的特征进行了筛选,舍弃了原始数据中共同的特征,降低了数据特征维数。
2)粒子群算法优化RBM后的网络结构从错误率和训练时间上综合分析,在一定程度上提升了RBM模型性能。
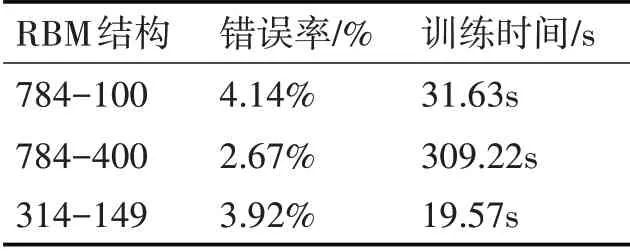
表1 三种RBM结构试验结果
4 结语
本文研究了受限玻尔兹曼机网络结构的设计方法,结合粒子群算法完成可见层特征和隐藏层数目的优化选择。通过在MNIST数据集上进行对比实验,实验结果表明,采用PSO-RBM优化后得到的RBM网络结构在错误率和训练时间上与传统结构相比较,在综合性能上有一定的优势。本文作为粒子群算法优化RBM网络结构的开端,考虑到粒子群算法仍存在缺点,因此PSO-RBM还具备提高的潜力。在今后的工作中将不断改进PSO,提高PSO-RBM的优化能力,使得RBM网络结构朝着简单、高效的方向发展。
