基于核密度估计的集成剪枝和增量学习时间序列预测方法*
2021-10-09朱钢樑
朱钢樑
(南京航空航天大学计算机科学与技术学院 南京 210016)
1 引言
时间序列预测(TSP)是机器学习和数据工程领域中一个重要且活跃的研究课题,在许多数据挖掘应用中具有不可或缺的重要性。一般而言,时间序列涉及各种研究领域,例如:经济(股票价格,失业率和工业生产),流行病学(传染病病例率),医学(心电图和脑电图)和气象学(温度,风速和降雨量)[1]。许多研究关心的是平稳时间序列预测而不是非平稳时间序列预测。然而,实际的时间序列几乎都是非平稳的,限制了平稳时间序列技术在实际生产生活中的应用。因此,对非平稳时间序列预测的研究变得重要和有价值[2~4]。
在过去的几十年,神经网络(NN)凭借其非参数,数据驱动和任何线性和非线性函数的通用逼近的理论特性,引起了时间序列领域的研究人员的极大关注[5]。随着大量研究人员证明了基于神经网络的预测系统的优越性[6],越来越多的研究已经开始在神经网络的基础上设计时间序列预测模型[6~11]。然而,对前馈神经网络(FNNs)参数的训练将耗费大量时间并导致不同参数层之间的依赖性。基于梯度下降的方法[12]作为迭代训练参数的常用方法,通常非常耗时,并且当应用于大多数前馈神经网路时,容易使网络陷入局部最小值。近几年,黄广斌等提出了一种新的FNNs学习框架,称为极限学习机(ELM)[13]。ELM是在单隐藏层前馈神经网络(SLFNs)的基础上专门开发的。在ELM中,连接输入层和隐藏层的权重以及隐藏层的偏差值在学习之前随机生成,并且在学习过程中保持固定。同时,连接隐藏层和输出层的权重通过分析计算得到。与传统的FNNs相比,ELM具有一些重要且有意义的特征[14]:1)效率高,即ELM的学习速度极快;2)稳健性,即,在大多数情况下,ELM具有比基于梯度下降的学习(例如反向传播(BP))更好的泛化性能;3)最优性,即传统的基于梯度下降的学习算法可能面临陷入局部最优,不正确的学习率和过度拟合等问题,ELM将直接得到最优解而不会遇到这些问题。
本文的主要贡献在于将核密度估计应用于集成系统的动态剪枝和增量学习,提出了一种新的混合时间序列预测算法,称之为DEPK&ILK。算法融合了动态集成剪枝(DEP),增量学习(IL)和核密度估计(KDE)。DEPK&ILK算法分为三个子过程:1)集成系统生成(Overproduction);2)动态集成剪枝(DEP);3)增量学习(IL)。第一个子过程用于生成集成系统的基学习器池。本算法中,基学习器为核方 法 的 在 线 序 列 极 限 学 习 机(OS-ELMK)[15]。OS-ELMK是在ELM的基础上不断改进发展而来的。ELMK[16]在ELM的基础上加入核方法,使ELM具有更好的学习性能。OS-ELMK则是ELMK的在线学习形式。将OS-ELMK作为基学习器,可以随着新数据的到来不断更新原有的参数,这一特性在时间序列预测问题上具有重要意义:时间序列的样本随着时间顺序先后进入模型,并且时间序列的输出值服从的概率分布往往随着时间的变化而变化,模型需要不断的更新才能适应新数据的预测,在第三部分的增量学习中,将会用到OS-ELMK的在线学习特性。算法的第二个子过程为动态集成剪枝(DEP),称之为DEPK。在此过程中,算法将利用核密度估计(KDE)[17]来进行集成系统的动态剪枝。核密度估计在统计学中是一种非参数估计,用来对未知分布进行估计。对于每一个待预测的样本,所有的基学习器对此样本进行预测得到一个预测输出向量,然后利用核密度估计得到集成系统对此样本的预测输出概率密度图。接着对每一个基学习器,若该学习器对样本的预测值在概率密度图上对应的概率越大,则该学习器越有机会用来预测样本的输出,最终得到剪枝后的集成系统,最后利用该集成系统对样本进行预测。算法的第三个子过程为增量学习(IL),称之为ILK。对于一个待预测的样本,算法要衡量该样本是否需要进行增量学习。首先算法定义了一个动态选择集(XDSEL),XDSEL用来得到待预测样本的Kp个最近邻样本,写为XRECO(The Region of Competence)。然后对每一个在XRECO中的样本,集成系统都能产生一个预测输出向量。同样的,用该向量可以得到该样本对应的核密度估计。若该样本的真实值在核密度估计上位于小概率区间(用一个随机阈值F衡量),表明集成系统没有足够的能力来预测该样本,则将它并入集合XINCL(该集合用来最终更新集成系统)中。得到最终的集合XINCL后,用该集合去更新集成系统,即对于每一个基学习器,都将XINCL并入它们的采样集中并更新参数。
2 基于KDE的动态集成和增量学习算法DEPK&ILK
2.1 核密度估计(KDE)
核密度估计用于估计未知的概率密度函数,属于Rosenblatt和Emanuel Parzen提出的非参数测试方法之一[17]。对于一组数据{ }x1,x2,…,xn,核密度估计通过以下公式得到。
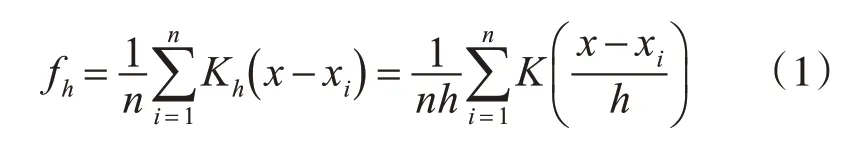
其中,h>0是平滑参数,称为带宽。Kh(x)=为缩放函数。为核函数(非负、积分为1,符合概率密度性质,并且均值为0)。核函数有多种形式。由于高斯内核方便的数学性质,本算法中,令K(x)=φ(x),φ(x)为标准正态概率密度函数。
2.2 基于KDE的动态集成剪枝算法DEPK
对于一个待预测样本(x,t),首先得到一个预测输出向量:
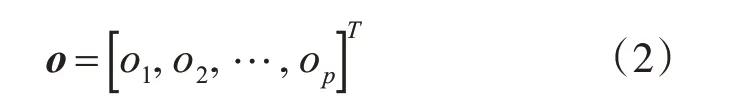
p为集成系统中基学习器的数量。该向量o表示集成系统对待预测样本的预测输出向量。得到预测输出向量后,计算预测输出的核密度估计。
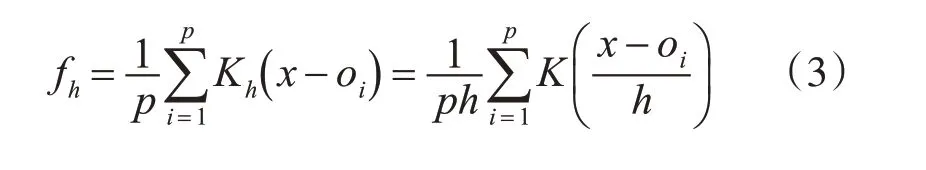
动态集成剪枝算法DEPK的算法步骤如下:
1)令fh,max=max(fh);
2)对每一个基学习器li,i=1,2,…,p
(1)在区间[0,fh,max]上随机产生一个值r;
(2)若r≤fh(oi),则将li并入剪枝集L′。
3)用得到的剪枝集L′去预测样本的输出值。
2.3 基于KDE的增量学习算法ILK
本算法中,首先我们定义动态选择集XDSEL,此集合用来产生Kp个待预测样本(x,t)的最近邻样本集合XRECO(利用K-NN算法得到),用XRECO集合来近似的代表(x,t),并利用XRECO去实施增量学习算法。基于KDE的增量学习算法ILK的算法步骤如下。
1)随机产生一个阈值F;
2)对每一个属于XRECO的样本(xk,tk),k=1,2,…,Kp
(1)计算该样本在集成系统上的KDEfh,k;
3)所有的基学习器都用集合XINCL去更新参数。
3 实验和分析
3.1 实验设置
为验证提出的算法的性能,用三个数据集:1)国际航空旅客数(IAP);2)IBM股票闭市价格(ICS);3)每月闭市时道琼斯工业指数(MCD)作为时间序列实验数据集。
在利用数据集进行预测之前,首先算法将数据集进行归一化。归一化过程可以用下面的方程表示:
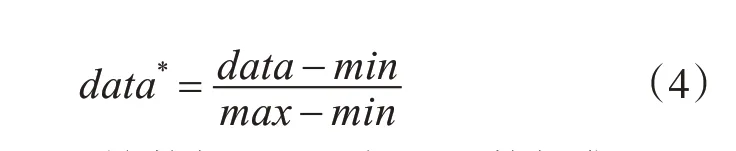
其中data表示原始数据,min表示原数据集上的最小值,max表示原数据集上的最大值,d at a*表示归一化后的数据。归一化过程将所有的数据归一化到[0 ,1]之间。
时间序列预测需要定义时间窗大小,本算法中我们定义时间窗大小为20。定义了时间窗大小后,就可以产生时间序列的数据集。本算法定义最后10%的数据为测试集,用来衡量最终算法的性能。随机取50%的样本为训练集,用来产生基学习器的采样集。再随机取20%的样本作为验证集,用来训练参数。取剩下的20%的样本为动态选择集XDSEL,产生样本的k近邻集合。
对算法的性能评价,我们选择均方根误差(RMSE)和平均绝对误差(MAE)来衡量。
3.2 国际航空旅客数(IAP)
国际航空旅客数(IAP)数据集按月记录了从1949年1月~1960年12月,国际航空旅客数,具有144个数据点。图1为该数据集的折线图。可以看到该数据集表现出强烈的规律性。整体上呈现上升趋势,同时又有周期性的升降。表1和表2为提出的算法与当前流行的几种算法比较的实验结果,由于其余算法不需要用到动态选择集,因此它们的训练集占了样本总量的70%。从结果可以看出,提出的算法无论是RMSE还是MAE,都取得了良好的实验结果。
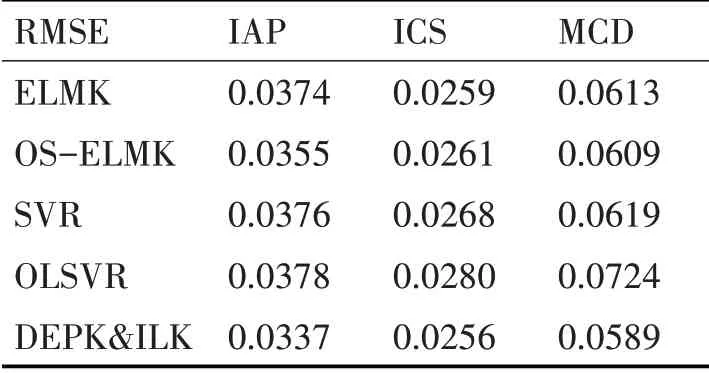
表1 各算法在三个数据集上的RMSE表现
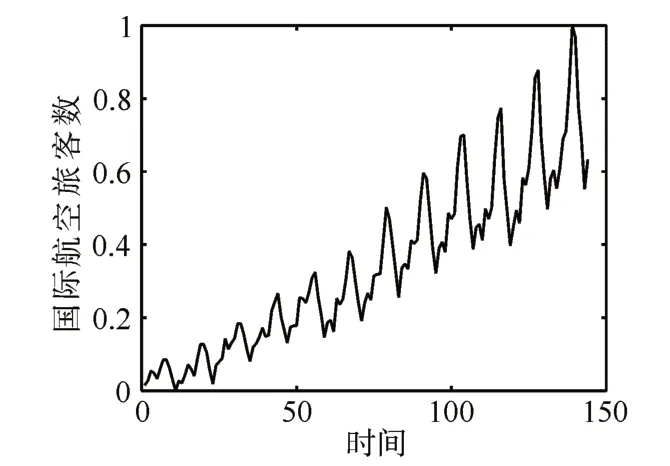
图1 国际航空旅客数折线图
3.3 IBM股票闭市价格(ICS)
该数据集记录了从1961年5月17日到1962年11月2日每天IBM股票闭市价格,具有369个数据点。图2为该数据集的折线图。宏观上看,该数据集并没有表现出强烈的规律性,原因是股票价格与多种因素有关。从表中结果看出,所有的算法在性能表现上差距不大。尤其是ELMK,OS-SVR和提出的算法性能接近,说明提出的算法不能在所有的数据集上都有优异的表现,这也符合机器学习中“没有免费午餐”定理。
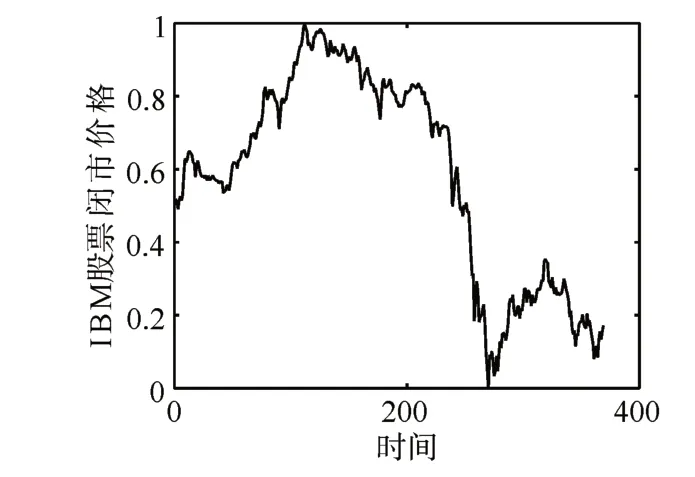
图2 IBM股票闭市价格折线图
3.4 每月闭市时道琼斯工业指数(MCD)
该数据集按月记录了从1968年8月到1992年10月闭市时的道琼斯工业指数,具有291个数据点。图3为该数据集的折线图。从图中看出,此数据集上下波动剧烈,两个波峰之间存在一个周期,但周期性并不明显。从表1和表2的实验结果看出,提出的算法获得了优异的表现,在此数据集上有较低的RMSE和MAE。
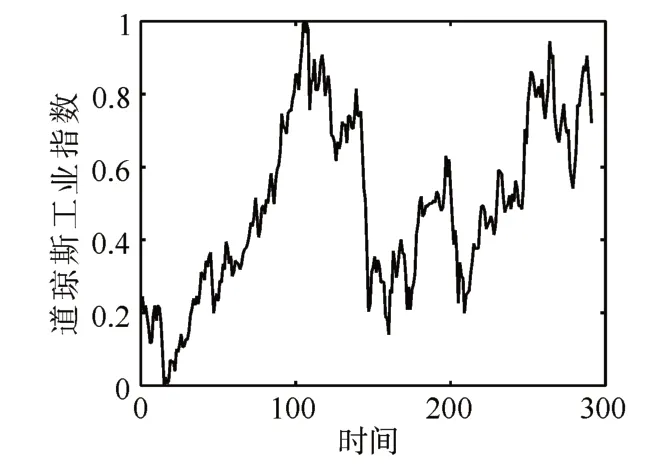
图3 每月闭市时道琼斯工业指数折线图
4 结语
本文提出了一种基于核密度估计的动态集成剪枝和增量学习算法DEPK&ILK。通过在三个数据集上与其他算法的对比实验,提出的算法具有不错的预测效果。提出的算法在数据集有较明显的规律性时对比其他算法有很大的性能提升。但在处理规律性不明显的数据集时,与其他算法在性能表现上无法拉开较大差距,如何在规律性不强的数据集上也获得良好的性能是下一步的研究重点。
