基于梯度追踪的结构化剪枝算法
2022-09-28季繁繁袁晓彤
王 珏,季繁繁,袁晓彤
(南京信息工程大学江苏省大数据分析技术重点实验室,江苏 南京 210044)
1 引言
现今,卷积神经网络(CNN)[1-3]在计算机视觉、自然语言处理、语音识别等深度学习的各个领域中迅速发展,而且表现出其优越性能。通常情况下,神经网络的层数越深、结构越宽,模型的性能也就越好。所以,CNN的大量可学习的参数使得网络能够拥有强大的表达能力。
尽管深度卷积神经网络取得了巨大成功,但CNN却存在过参数化的问题。当深度模型在硬件资源受限的环境(比如嵌入式传感器、无人机、移动设备等)中实际工作时,会出现以下三个问题:运行时的内存过多;可训练参数过多;计算代价过大。例如,在对分辨率为224×224的图像进行分类任务时,ResNet-152[4]占用了不少于200MB的存储空间,具有6020万个参数,需要23千兆的浮点运算次数(FLOPs),这会导致CNN计算代价过大[5]。以上三个问题限制了深度CNN的实际部署。
为了有效缓解上述的问题,研究人员提出了一些新的技术来加速和压缩深度CNN,包括低秩分解[6-7],量化[8-9],知识蒸馏[10]和网络剪枝[5,11-12]等。他们在追求高精度的同时,能够降低过参数化网络的计算代价以及存储需求。
滤波器剪枝能够剪除原始网络中的冗余卷积核,从而获得小网络,有效降低模型的运算量和存储量。作为模型压缩技术,滤波器剪枝有以下几个优势:首先,它可以应用于CNN的任何任务中,比如目标检测,人脸识别和语义分割等。其次,滤波器剪枝可以在显著减少FLOPs、加快推理速度的同时,不会损坏网络结构。因此,可以利用其它模型压缩技术(例如,知识蒸馏[10]、量化[8-9])进一步压缩剪枝后的模型。此外,现有的深度学习库可以支持滤波器剪枝,而不需要专用硬件和专用软件。
一些代表性工作[5,12]可以通过计算网络卷积层中的滤波器Lp范数的值,来衡量相应滤波器的重要性。这种情况下,上述方法对滤波器的参数范数值排序,删除对应于小范数的不重要的滤波器,得到了较窄的卷积神经网络。
然而,这些剪枝准则仅仅关注模型参数本身的信息(零阶信息),却忽略了其梯度信息(一阶信息)对模型性能的影响,可能会剪去重要的滤波器。即使一些滤波器参数权值很小,但其参数变化对剪枝结果将产生很大的影响,这些梯度大的滤波器是不应该被剪去的。模型的梯度信息对卷积神经网络来说是十分重要的。在神经网络中,前向传递输入信号,反向传播根据误差来调整各种参数的值,即运用链式求导的思想。而且,CNN参数优化的重要算法是根据梯度决定搜索方向的策略。因此,网络的参数信息和梯度信息可以作为滤波器重要性的评判指标。
为了解决上述剪枝方法的缺陷,根据梯度追踪算法(GraSP)[13]的思路,本文提出了一种新的滤波器级的剪枝方法。本文将在优化器步骤中实现所提方法,并且在所有卷积层中同时进行剪枝操作。具体地来说,本文方法首先计算滤波器梯度的L1范数值,并对它们进行排序,然后,选择对应最大梯度值的滤波器索引。随后,本文算法将该索引和上一次迭代中得到的对应最大权值的滤波器索引联合,生成了一个包含参数信息和梯度信息的并集。除了参数信息,梯度信息也是衡量滤波器重要性的依据。然后,在该并集上利用随机梯度下降的动量法(SGDM)[14]更新参数。在每次迭代结束时,计算滤波器权重的L1范数,对它们排序,选择保留最大范数的滤波器,然后设置小滤波器为零。该剪枝方法允许已经归零的滤波器在往后的迭代中继续训练。本文方法将继续迭代直到模型收敛。最后,重建网络,从而获得了剪枝后的小网络。
本文的主要贡献如下所述:
1)提出了一种改进的结构化剪枝方法来压缩模型。与传统的剪枝方法相比,采用梯度追踪算法,创新地使用模型的梯度信息和参数信息来评判滤波器的重要性;
2)与硬剪枝方法[12,15-16]相比,本文方法从头开始训练,不需要使用预训练的模型。因此,不需要剪枝后的微调步骤,省略微调时间;
3)将结构化剪枝算法运用到ResNet模型上,并在基准数据集上进行实验。结果证明,本文方法能够在不影响的模型性能情况下,减少网络参数量和运算量,使得深度卷积神经网络能在硬件资源受限的环境下部署。
2 网络剪枝算法
网络剪枝是模型压缩的重要技术之一。它可以在神经网络模型的精度损失忽略不计的情况下,剪去网络的冗余参数,达到减少过参数化模型的大小和运算量(例如FLOPs)的目的。一般来说,剪枝算法可以分为两类,即非结构化剪枝和结构化剪枝。
2.1 非结构化剪枝
LeCun等[17]最先开创性地提出了OBD的方法,利用参数的二阶导数,来衡量且去除不重要的神经元。但是,以上的剪枝方法并不能应用在深度神经网络(DNN)上。Han等[11,18]提出一种剪枝方法,在预训练网络中剪去那些参数权重低于预定义阈值的连接,然后重新训练以恢复稀疏模型的准确性。该方法可以在深度神经网络中缩小模型尺寸。然而,如果剪枝失误,则无法恢复连接。为了解决以上问题,Guo等[19]提出了一种动态网络剪枝技术,该方法可以利用剪枝和接合这两个操作以动态地恢复剪枝后的重要连接,显著地减少了训练迭代的次数。Jin等[20]在目标函数上添加L0范数的约束,使得模型更加稀疏。它保留了最大权值的参数,然后重新激活所有的连接。该方法是利用剪枝策略来提升模型精度。
非结构化剪枝主要对模型参数剪枝,但是不能充分利用现有的BLAS库。在实际应用中,剪枝后的连接是不规则的,所以非结构化剪枝在推理时的加速并不明显,而且需要专用库(如cuSPARSE)和专用的硬件平台。
2.2 结构化剪枝
结构化剪枝能够剪除整个冗余滤波器,以显著减少卷积神经网络的FLOPs,内存空间和运算功耗。
下面是引入可控超参数的剪枝方法:Wen等[21]提出了一个结构化稀疏学习(SSL)的剪枝方法。该方法在损失函数中引入了分组LASSO正则化,来将一些滤波器逐渐归零。Liu等[22]利用了批量归一化(BN)层的信息,在目标函数中加入BN层中的缩放因子γ,将γ的L1范数作为惩罚项,然后剪去与较小缩放因子相对应的通道。Ye等[23]针对BN运算中的缩放因子γ,采用了迭代收缩阈值算法(ISTA)来稀疏参数。
还有是按照某个度量标准来衡量某些滤波器是否重要的剪枝方法:Li等[12]在预训练模型上,对每个滤波器计算卷积核权重的绝对值之和,对其排序,然后剪去其中不重要的滤波器。此方法是基于L1范数来判断滤波器的重要性。然而,被剪去的滤波器无法在训练过程中继续更新参数,从而限制了网络模型的表达能力。针对这一问题,He等[5]提出了一种软剪枝(SFP)的方法。该方法剪去L2范数值较小的滤波器,并且从头开始一边剪枝一边训练。已经剪去的滤波器能够继续参与训练,从而节省了微调步骤的时间。但是,当使用基于范数的剪枝准则时,应该满足以下两个条件:范数标准差要大;最小范数接近于零。然而,这两个条件并不总是成立。因此,He等[24]提出了一个基于滤波器几何中位数(FPGM)的剪枝准则。该方法选择与同一层中其它滤波器的欧氏距离之和最小的滤波器,然后将其剪去,从而可以剪去冗余的滤波器。Lin等[25]提出了基于高秩特征图的滤波器剪枝方法(HRank)。该方法计算每个滤波器的输出特征图的平均秩,将其排序,然后对平均秩比较小的相应滤波器进行剪枝。
还有通过重建误差来确定哪些滤波器需要剪除的方法:Luo等[16]提出了一个ThiNet框架。该框架将通道选择问题转化为优化问题的形式,并且在预训练模型上计算相应的下一层统计信息。它将最小化剪枝前模型和剪枝后模型之间的输出特征图上的重建误差。He等[15]将通道选择问题转化为最小二乘法的LASSO回归问题。
2.3 探讨
上述剪枝算法仅仅使用参数信息,所以容易忽略权值很小、梯度却很大的滤波器。而本文方法既使用模型的参数信息,又使用其梯度信息,能有效减少神经网络中的冗余参数。本文方法先在当前优化器中选取梯度值较大的滤波器,联合幅值较大的滤波器,从而得到一个滤波器索引的并集。然后,在该并集上使用随机梯度下降法更新参数,最后,剪去权值较小的滤波器。本文还使用不同的CNN架构进行大量剪枝实验,证明了所提方法的有效性与优越性。
3 梯度追踪的网络剪枝方法
本节介绍了利用梯度追踪算法进行结构化剪枝的方法。首先,简单介绍用于解决稀疏约束优化问题的梯度追踪算法(GraSP)。然后,针对压缩深度卷积神经网络的问题,本文提出了采用GraSP的结构化剪枝方法。
3.1 机器学习的梯度追踪算法
本文所提出的算法受到梯度追踪算法(GraSP)[13]的启发,利用GraSP的思想对CNN进行结构化剪枝。GraSP算法是一种用于近似求解压缩感知[26]的稀疏约束优化问题的方案。
在3.1节中,x∈d表示一个向量。表示x的稀疏估计值。表示向量x的L0范数(即向量x的非零项个数)。supp(x)表示向量x的支撑集(即x的非零项索引)。A∪B表示集合A和集合B的并集。T表示集合T的补集。bk表示向量b的最大k项(按幅值大小)。
为了最小化目标函数f(x),GraSP算法考虑以下稀疏约束的优化问题

(1)

算法1.梯度追踪算法。
输入:f(·)与k。
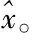
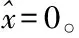
repeat

选择z中2k个最大值:Z=supp(z2k);
在该并集上最小化:b=arg minf(x) s.t.x|T=0;
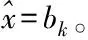
until 参数收敛。

3.2 梯度追踪的结构化剪枝算法
结构化剪枝可以有效地压缩加速网络,而且不会破坏网络模型结构。
如3.1节所述,GraSP[13]将梯度最大的信号与幅值最大的信号联合,从而解决压缩感知的稀疏约束优化问题。而本文算法将GraSP的思路创新地应用到CNN结构化剪枝中。与基于参数信息的剪枝算法[5,12]相比,本文算法使用CNN的梯度信息和参数信息来评判滤波器的重要性,剪去被判为不重要的滤波器。这有助于提升结构化剪枝的效果。
在CNN模型中,令i作为卷积层索引。网络参数则表示为{Wi∈Ni+1×Ni×K×K,1≤i≤L},其中,Wi表示第i个卷积层中的参数权重矩阵。Ni表示第i层的输入通道数,Ni+1表示第i层的输出通道数。K×K表示卷积核的大小。L表示网络中卷积层个数。剪枝率Pi表示第i个卷积层中剪去的滤波器的比例。Wi,j∈Ni×K×K表示第i个卷积层的第j个滤波器。nonzero(x)表示x中非零元素的位置(索引)。topk(x)表示x中k个最大项索引。
本文定义Lp范数如下所示

(2)
其中,Ni是第i个卷积层中的输入通道数。梯度追踪的结构化剪枝方法根据计算滤波器的L1范数,以此评估滤波器的重要性。本文通过Ni+1(1-Pi)来计算k,本文方法在所有卷积层中使用相同的剪枝率Pi。

图1 梯度追踪的结构化剪枝方法的框架图
图1清晰地概述了如何将GraSP的原理推广到结构化剪枝的流程框架。在图1中,k表示某个卷积层中剪枝后剩余的滤波器数目。大的方框表示某卷积层中的滤波器空间。在滤波器空间中,黄色框表示k个最大L1范数的滤波器,绿色框表示k个最大梯度的滤波器,白色框表示其余的滤波器,虚线框表示滤波器设置为零。在某个卷积层中,W表示参数权重矩阵,g表示梯度矩阵。本文方法选择k个梯度最大的滤波器,再将其索引与在上一次迭代中得到的滤波器支撑集联合成一个并集。然后,本文算法在该并集上更新参数。在每次迭代结束时,该算法选择权值最大的滤波器,最后剪去小滤波器。
算法2详细地描述了梯度追踪的结构化剪枝算法。本文所提的方法将从头开始训练CNN,在所有卷积层中同时进行剪枝操作。
算法2.梯度追踪的结构化剪枝算法。
输入:训练数据X,剪枝率Pi,学习率η,CNN模型参数W={Wi,1≤i≤L},卷积层的层数L。
输出:剪枝后模型,和它的参数W*。
随机初始化网络参数。
for each step=0 to stepmaxdo
计算当前梯度:g=∇f(Wstep);
for each i=0 to L do
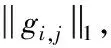



end for
end for
重建剪枝后的模型,最终得到一个小网络W*。
首先,随机初始化模型参数,本文方法在优化器步骤中迭代地进行剪枝过程。
在第step次迭代中,f(Wstep)是当前的损失函数。该算法通过反向传播计算当前梯度g
g=∇f(Wstep)
(3)
然后,计算gi,j的L1范数,对其进行排序,在向量gi中选择k个梯度最大范数值的滤波器索引,如下式(4)所示。其中,gi,j表示在第i层中第j个滤波器对应的梯度。
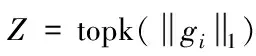
(4)

之后,将式(4)中的索引Z与当前参数的权值Wstep的支撑集联合,从而获得一个并集T,如下所示

(5)



(6)


本文算法将一直迭代,直到模型参数收敛。最后,该算法重建剪枝后的网络,生成小模型。
综上所述,本文方法使用梯度学习,考虑了模型的参数信息和梯度信息的联合影响,从而能在剪枝后有效保留模型的重要信息。
4 实验结果与分析
为了验证本文所提算法的有效性,本文在三个标准数据集(即MNIST[27],CIFAR-10[28]和CIFAR-100[28])上,使用梯度追踪的结构化剪枝方法,对几种常见的CNNs进行剪枝实验,并将该算法与一些当前已经提出的剪枝技术进行比较。本文使用所提出的剪枝方法在MNIST上对LeNet-5[27]模型、在CIFAR-10和CIFAR-100对ResNet[4]进行剪枝实验,从而压缩神经网络。本文的实验使用Pytorch[29]深度学习框架,在型号为NVIDIA GeForce GTX 1080Ti的GPU上运行程序。本文算法在优化器步骤中迭代地执行剪枝操作,在所有卷积层中同时进行滤波器剪枝。为了进行比较,实验关注剪枝率、精度变化以及FLOPs。使用Top-1准确率来衡量基线模型和剪枝后模型的性能。剪枝率是剪枝后的网络与原始网络在参数量上相比减少的百分比。FLOPs是每秒浮点运算次数,FLOPs减少表示网络运算速度得到了加速。同样地,本文将所有剪枝算法的最好的实验结果用粗体表示。
在4.1节和4.2节中,本文介绍了三个图像分类的标准数据集和实验设置。然后在4.3节、4.4节和4.5节中,本文在三个标准数据集上进行结构化剪枝实验,将本文算法的结果与其它剪枝算法进行比较,验证了本文算法的性能。在4.6节中的消融实验研究了不同的剪枝策略以及不同Lp标准对剪枝实验的影响。4.7节证明了本文方法也可以应用于非结构化剪枝。
4.1 数据集
MNIST[27]是一个手写数字的通用数据集,其中包含了60,000个训练集样本和10,000个测试集样本。
CIFAR-10[28]是一个用于识别目标的小型数据集,包含了60,000张分辨率为32×32的彩色图像。它分为10个类别,包含了50,000训练图像和10,000测试图像。CIFAR-100[28]与CIFAR-10数据集类似。它有100个类别,每个类有600张图片。
4.2 实验设置
首先,本文在数据集MNIST上对LeNet-5模型进行实验。LeNet-5[27]是一种典型的CNN模型,它由两个卷积层和两个全连接层组成,具有431,000个可学习参数。对于MNIST实验,本文使用SGDM[14]算法,其动量系数β设置为0.9,权重衰减为0.0005。本文算法从头开始训练200个epoch,批量数据样本数为64。实验初始学习率为0.01。在epoch为60、120和160的时候,学习率η乘以0.2。
在CIFAR-10和CIFAR-100的实验中,本文对ResNet-20、32、56和110模型进行剪枝。SGDM[14]所使用的动量系数β为0.9,权重衰减为0.0005。本文使用梯度追踪的结构化剪枝方法从头开始训练所有模型,一共训练250个epoch,批量数据样本数为128。在第1、40、120、160和200个epoch时,学习率η将分别设为0.1、0.02、0.004、0.0008、0.0002。
特别地,对于CIFAR-10实验,本文方法将与以下方法进行定量比较:滤波器剪枝(L1-pruning-A,L1-pruning-B)[12]、Channel-pruning[15]、More is Less(LCCL)[30]、软剪枝(SFP)[5]、HRank[25]、FPGM[24]。其中,Li等[12]认为,ResNet模型的一些特定的卷积层对剪枝十分敏感,比如ResNet-56的第20、38和54层,或者ResNet-110的第36、38和74层。因此,它们跳过上述的卷积层,修剪其它层的10%的滤波器,这就是L1-pruning-A[12]。而Li等提出的L1-pruning-B[12]在不同阶段使用不同的剪枝率。在ResNet-56中,L1-pruning-B跳过更多的卷积层(16,18,20,34,38,54),同时第一阶段每个卷积层的剪枝率为60%,第二阶段的剪枝率为30%,第三阶段剪枝率为10%。在ResNet-110中,L1-pruning-B跳过第36、38和74层,第一阶段剪枝率为50%,第二阶段剪枝率为40%,第三阶段剪枝率为30%。FPGM-only[24]表示只使用基于滤波器几何中位数(FPGM)的剪枝准则,那么,FPGM-mix[24]就将FPGM同基于范数的剪枝准则相结合。
4.3 数据集MNIST的剪枝实验结果

表1 在MNIST数据集上本文方法对LeNet-5剪枝的实验结果
本文算法在MNIST数据集上对LeNet-5模型中的两个卷积层进行结构化剪枝。实验中使用的剪枝率为10%、20%、30%、40%、50%、60%、70%和80%。表1表示了在MNIST数据集上LeNet-5模型的结构化剪枝结果。实验结果表明,在剪去两个卷积层的50%的滤波器的情况下,本文方法Top-1准确率仅仅降低了0.12%。此外,本文方法可以在保持分类准确率的情况下,甚至可以剪去80%的滤波器。
因此,本文通过在MNIST上的实验初步证明了该算法的实用性和有效性,验证了GraSP的原理可以应用在CNNs上,同时使用梯度信息和参数信息的方法能够有效地进行结构化剪枝。在以下的4.4节中,将在更深的卷积神经网络模型上(例如ResNet)上进一步实现本文方法,并将该剪枝算法与其它剪枝方法进行比较。
4.4 数据集CIFAR-10的剪枝实验结果
对于在CIFAR-10上的实验,本文算法对ResNet-20、32、56和110模型按照五个不同的剪枝率进行剪枝操作。
表2中表示了在CIFAR-10上的实验结果。该实验将本文算法与4.2节列出的对比方法进行比较。对比算法的结果都在相应论文中有所体现。
例如,ResNet-56模型的剪枝实验中,当具有微调步骤的HRank[25]剪去50%的FLOPs时,剪枝后结果比基准精度减少了0.09%;在剪枝后的FLOPs减少了52.63%的情况下,具有微调步骤的FPGM-mix[24]方法的准确率下降了0.33%;而本文方法没有微调步骤,在FLOPs减少量为52.63%的情况下,其准确率仅仅下降了0.04%。从实验结果来看,本文的方法能有效地对残差网络进行剪枝,而且不需要微调步骤,能够节省训练时间。
在ResNet-110的实验中,当具有微调步骤的L1-pruning-B[12]剪去38.60%的FLOPs时,其Top-1准确率为93.30%;而LCCL[30]在剪去34.21%的FLOPs时,获得了93.44%的精度;当没有微调步骤的本文方法剪去40.78%的FLOPs时,其准确率为94.18%,比起原始模型提高了0.01%。因此,上述结果表明,本文算法使用了基于梯度和参数联合的剪枝准则,从而提供了比其它剪枝算法更为出色的性能,能够在追求高精度和模型压缩之间取得了更好的平衡。

表2 在CIFAR-10数据集上对ResNet剪枝的比较结果
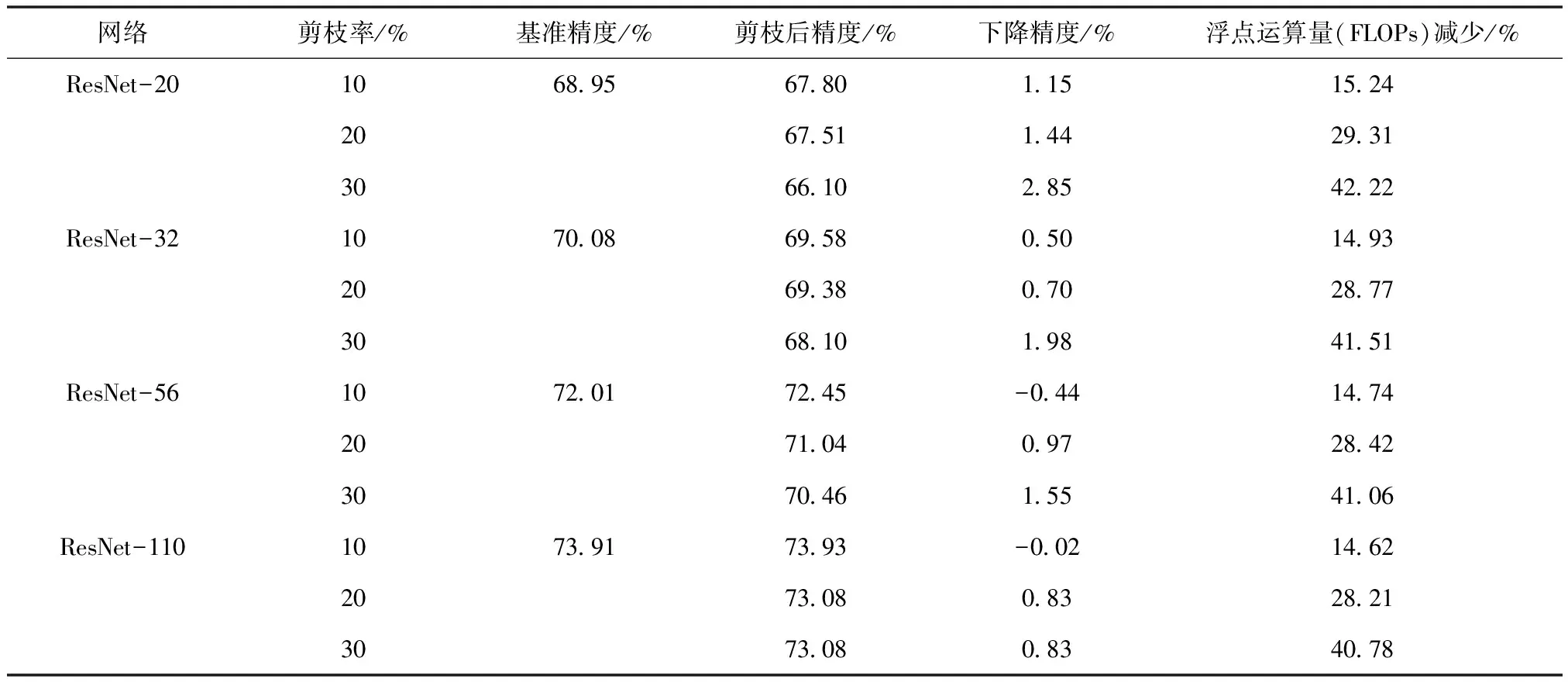
表3 在CIFAR-100数据集上利用本文方法对ResNet模型用不同剪枝率进行滤波器剪枝
4.5 数据集CIFAR-100的剪枝实验结果
本节在CIFAR-100数据集上对ResNet-20、32、56和110模型使用本文算法进行结构化剪枝实验。如表3所述,在CIFAR-100对ResNet-56剪枝的实验中,本文算法在剪去14.74%的FLOPs时,获得了72.45%的准确率,甚至比剪枝前提高了0.44%。实验结果说明了本文算法能够有效缓解模型过拟合,提高模型精度。
在ResNet-110剪枝的实验中,当剪去40.78%的FLOPs时,本文算法可以获得73.08%的Top-1准确率,比剪枝前的基准精度仅仅降低了0.83%。
综上所述,本节通过在CIFAR-100数据集的剪枝实验,证明了本文方法有助于确定在某一卷积层中保留哪些滤波器。
4.6 消融实验
为了研究本文方法中不同要素对剪枝结果的影响,本文对ResNet-56在CIFAR-10数据集上的结构化剪枝实验进行消融研究。
4.6.1 剪枝方法的选择
首先,本文研究基于参数信息和梯度信息的策略对剪枝结果的影响。本文在CIFAR-10数据集上对ResNet-56模型进行消融实验。该实验增加了两个剪枝策略与本文方法比较:①保留梯度的范数值大的滤波器,即只使用梯度信息的剪枝准则;②保留参数的范数值大的滤波器,即只使用参数信息的剪枝准则。
表4总结了不同剪枝方法的选择对实验结果的影响。原始模型的基准精度为93.43%。表4中剪枝率的设置与表2的ResNet-56部分相同。在使用CIFAR-10数据集进行剪枝的实验中,当剪去40%的参数时,FLOPs减少了52.63%,只使用梯度信息的剪枝方法的准确率为92.59%,证明了梯度信息可以作为评判滤波器重要性的标准。只使用参数信息的剪枝方法的准确率为93.09%,而把两个信息结合的本文方法的Top-1准确率为93.39%。与只利用参数信息的方法和只利用梯度信息的剪枝方法相比,本文算法的性能更为优越。因此可以从该实验看出,把参数信息和梯度信息结合起来,能更好地剪去冗余的滤波器。
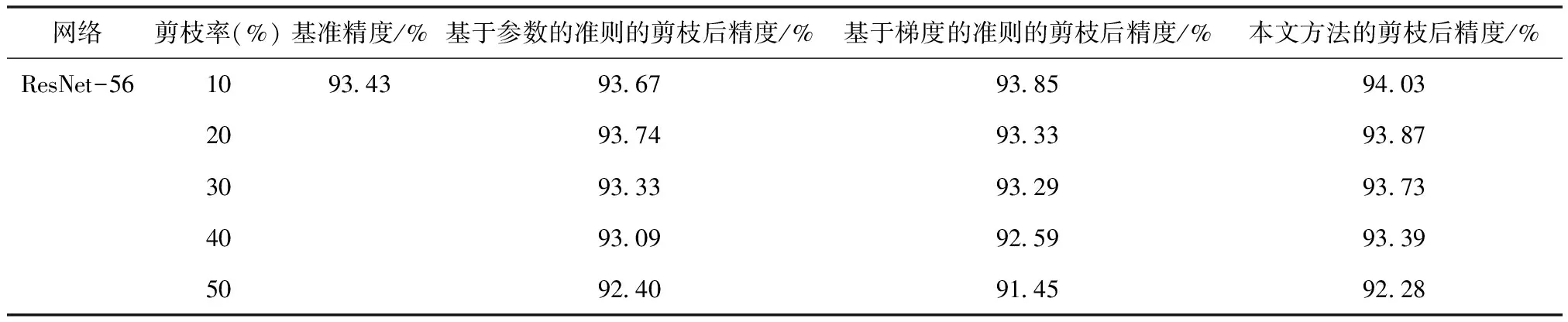
表4 在CIFAR-10数据集上对ResNet-56模型使用不同剪枝准则的实验结果
4.6.2 Lp范数的选择
为了研究不同Lp范数计算对估计滤波器重要性的影响,本文在CIFAR-10数据集上对ResNet-56模型进行剪枝实验。在此,本文使用L1范数的剪枝方法和使用L2范数的剪枝方法进行对比。
表5将L1范数与L2范数这种评估滤波器重要性的剪枝标准进行比较。对于在CIFAR-10数据集上修剪ResNet-56的实验,当剪枝率为40%时,FLOPs减少了52.63%,L2范数标准的准确率为93.04%,L1范数的准确率为93.39%。可以看出,使用L1范数比使用L2范数更为优越。所以,本文方法是使用L1范数来评估滤波器的重要性,然后剪去L1范数小的滤波器。

表5 在CIFAR-10数据集上对ResNet-56模型使用不同范数约束的实验结果
4.7 本文算法在非结构化剪枝的应用
最后,本文所提出的算法也能够应用于非结构化剪枝。
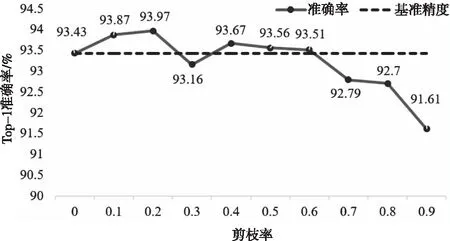
图2 在CIFAR-10数据集上的ResNet-56不同剪枝率的非结构化剪枝结果
图2表示了在CIFAR-10数据集上不同剪枝率对ResNet-56模型进行的非结构化剪枝实验结果。图中的基准精度为稠密网络的基准精度。x轴剪枝率为0.1时,网络的剪枝率为10%。对于该剪枝实验,当剪枝率为20%,本文方法能够得到93.97%的准确率,甚至比基准精度提升了0.54%。而且,当剪枝率为10%、20%、40%、50%以及60%时,剪枝后网络的精度超过了基准精度,本文方法能使CNN的性能有所提升。当卷积层上的非结构化剪枝率为80%,本文方法能够得到92.70%的Top-1准确率,与基准精度相比仅仅下降了0.73%。
因此,可以从实验结果看出,本文方法能够应用在非结构化剪枝中。当剪枝率非常高时,所提方法可以保持网络性能。
5 结语
1)本文提出了一种新的剪枝算法,它利用梯度追踪算法对CNN进行滤波器剪枝。该剪枝算法使用了CNN的一阶信息和零阶信息。其主要思路是:在每次迭代开始时,计算参数梯度的范数值,将梯度最大的滤波器索引与上一次迭代时保留的权值最大的滤波器索引结合,形成并集;然后在该并集上使用梯度下降法更新参数;在每次迭代结束时,通过计算每个滤波器的范数值,选择且保留权值最大的滤波器;以上步骤将一直迭代至收敛;最后,获得压缩后的模型。
2)在基准数据集上的几个剪枝实验表明,该算法能够在模型精度几乎不变的情况下,使用比较高的剪枝率对卷积神经网络进行压缩,从而有助于CNN的实际部署工作。例如,在CIFAR-10数据集上修剪ResNet-56的实验中,所提算法在不进行微调的情况下,减少52.63%的FLOPs,而准确率仅仅降低0.04%。所提方法的性能明显高于当前方法。
3)实验表明,本文也可以将梯度追踪算法应用在神经网络的非结构化剪枝中。
在往后的工作中,将考虑使用其它的复杂数据集进行进一步研究。同时,将尝试与其它网络压缩方法结合,完善该算法。
