基于确定性策略梯度算法的机械臂控制模型构建及仿真
2021-09-22贾红涛胡文娟
贾红涛 胡文娟
摘 要:为更好的实现对工业制造领域中机械臂的控制,结合当前的深度学习算法,提出一种改进奖励函数的DDPG机械臂控制方法。在该方法中,通过引入多奖励参数等方式,增强机械臂控制的灵活性,提高目标抓取的准确率。最后通过参数设置和DDPG网络模型构建,对改进方案进行验证。结果表明,该改进方式在目标抓取方面更具有稳定性。
关键词:DDPG算法;机械臂控制;仿真;奖励参数
中图分类号:TM359.9 文献标识码:A 文章编号:1001-5922(2021)09-0151-04
Construction and Simulation of Manipulator Control Model Based on Deterministic Strategy Gradient Algorithm
Jia Hongtao, Hu Wenjuan
(Shangluo Vocational and Technical College, Shangluo 726000, China)
Abstract:In order to better control the manipulator in the field of industrial manufacturing, combined with the current deep learning algorithm, a DDPG manipulator control method with improved reward function is proposed. In this method, multi reward parameters are introduced to enhance the flexibility of manipulator control and improve the accuracy of target grasping. Finally, through parameter setting and DDPG network model construction, the improved scheme is verified. The results show that the improved method is more stable in target capturing.
Key words:DDPG algorithm; manipulator control; simulation; reward parameters
機械臂在工业制造领域发挥重要作用,早期的机械臂控制方法采用的是基于任务的精确数学模型,这种控制方法下的机械臂的自适应性不理想,只能满足特定工作条件和指定任务目标下的应用需求,而无法根据任务或缓解的变化而做出调整,从而实现更好地控制效果。在最近几年间,深度强化学习(Deep Reforcement Learning,DRL)实现了快速发展,并逐步推广到机器人控制、人工智能博弈等领域,其中的一个重要突破就是机械臂控制开始引用DRL技术。应用于机械臂控制领域的DRL技术主要是确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),该算法在发挥强适应性控制效果的同时,也暴露出诸多弊端,比如学习效率低、不稳定、调参难、难复现等。针对该问题,文章提出DDPG算法以提高机械臂控制中目标点到达以及目标抓取任务中的学习效率。
1 深度确定性策略梯度算法
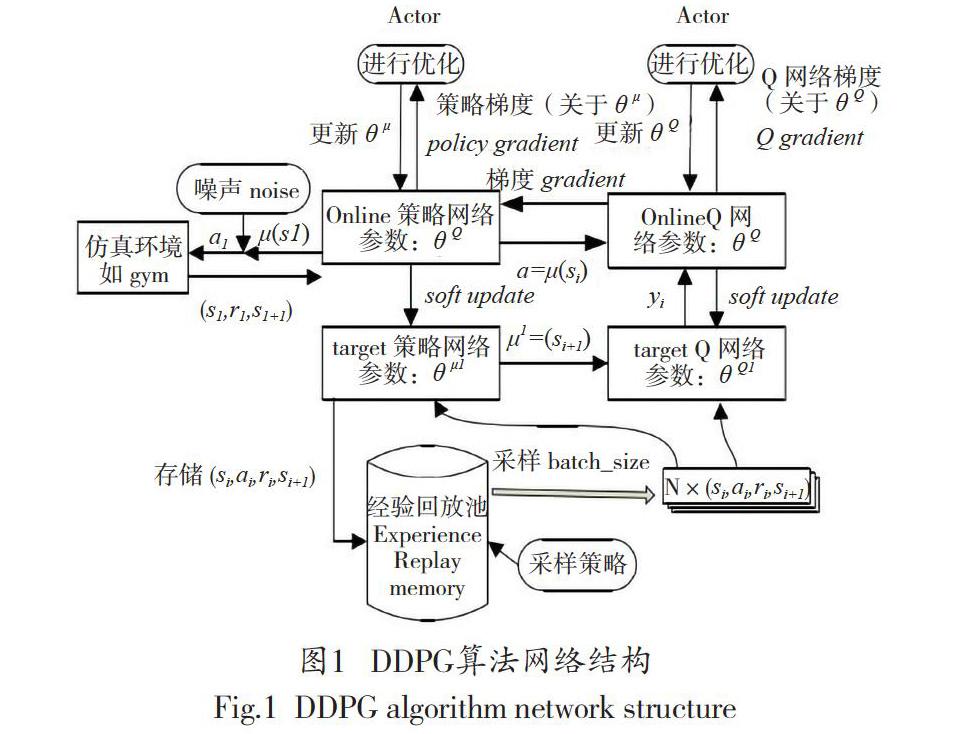
运用DQN拓展Q-Learning的方法,Lillicrap等进一步改进了确定性策略梯度算法,创建了DDPG算法。DDPG算法是强化学习领域的重要发展成果,它的前身是最初的策略梯度算法(Policy Gradient,PG)以及其后的确定性策略梯度算法(Deterministic Policy Gradient,DPG)。DDPG整体结构如图1所示。
2 实验机械臂设计
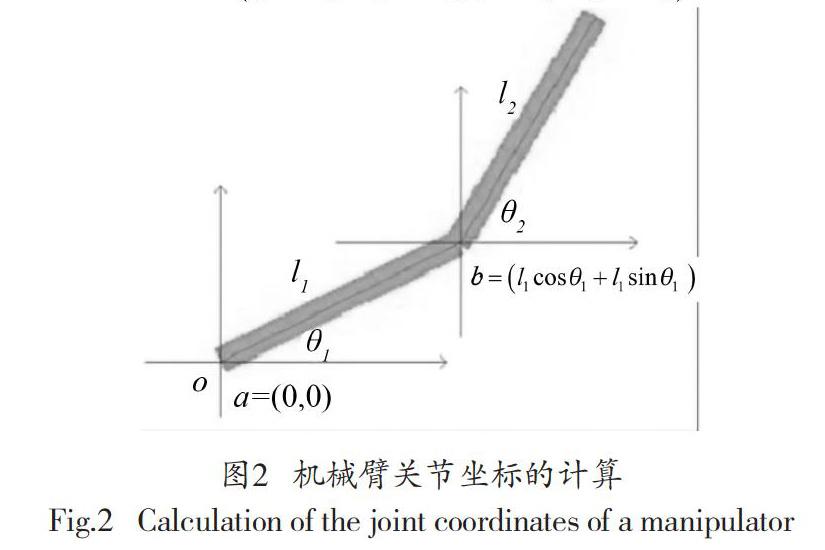
在二维平面上,机械臂关节坐标位置和机械臂关节旋转角度的关系可用图2表示。
图2中,o表示坐标原点或仿真机械臂的根节点。l1的一侧端点坐标是a=(0,0),也就是位o点之上,l2末端坐标是,l1与l2的焦点b的坐标是。同理,可计算出关节点a、b和c的相对位置,以及目标区域中心点T。
3 基于改进DDPG的机械臂控制设计
3.1 输入状态信息设计
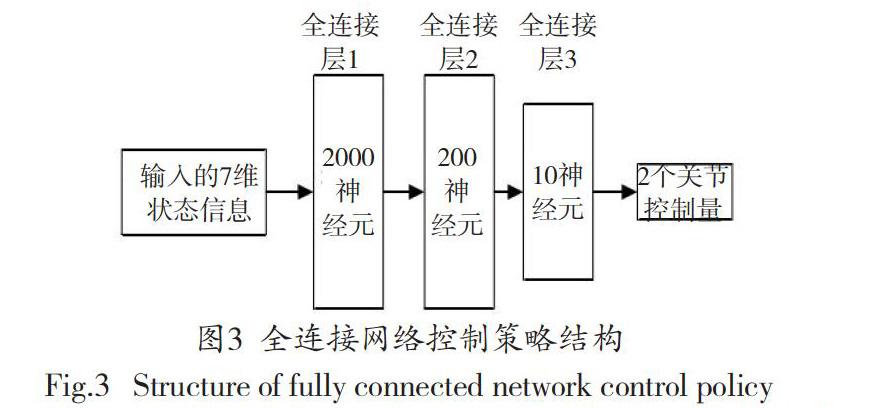
考虑到在二维机械臂仿真环境中的状态信息并不充分,因此选用三层全连接网络进行数据特征提取即可满足应用需求。具体控制策略如图3所示。
通过上述的策略,可获取2段机械臂l1、l2的关节角度信息、。
设定机械臂l1、l2的长度均为100,通过上式(1)获取与环境相关的状态信息,这些状态信息也是算法的状态输入。
式(2)中,d1-x,d2-x分别是机械臂关节b、c的横坐标距离;d1-y,d2-y表示目标中心点T的纵坐标距离;d3-x,d3-y分别是目标中心点T与仿真环境中心点的横坐标距离、纵坐标距离;goal表示布尔值,当机械臂末端在目标中心点T范围内部,布尔值等于1,否则等于0。通过式(2)可获取算法输入的7维状态信息。
3.2 输出控制动作设计
完成以上网络控制策略后,机械臂的2个关节动作控制量可表示为式(3)。
其中,a表示动作输出控制量w1、w2,它是由转动角度变量共同构成的,其单位是弧度。其中,w1表示机械臂l1根关节在该次动作中所需转动的角度,w2表示机械臂l2与机械臂l1连接关节在该次动作值所需转动的角度。转动角度变量w1、w2的取值区间是[-1,1],设定这一角度区间是为了避免出现机械臂转动突变的情况,也是防范控制异常的常规办法。
在完成关节旋转动作以后a=[w1、w2],机械臂的关节角度从变化成,即输入7维状态信息,输出2维的关节转动控制量。
3.3 原始奖励函数改进
设r为二维仿真机械臂奖励函数,奖励r包括r1与r2两部分组成。
式(4)中,r1表示目标区域中心点与机械臂末端的距离奖励函数,;r2表示稀疏奖励函数,即机械臂末端在目标区域内环境反馈值为1的单步奖励;r=r1+r2表示DDPG算法的原始奖励函数。
研究认为,传统的单一奖励函数设置无法对机械臂动作的优劣程度做出准确评定,也无法通过训练建立理想的算法模型。优化后的奖励函数能够避免机械臂的无效探索,还能够促进强化学习算法走向收敛,对此,可以组合应用分布奖励、稀疏奖励、形式化奖励等不同的奖励方法。举例来说,选定上式(4)作为机械臂的奖励函数,在算法控制下,机械臂会进行转圈甩动,其末端会在某一瞬间抵达目标块位置,然后继续转圈甩动偏离目标点,说明该算法只能实现机械臂转动至目标点,却不能使机械臂停留在目标点。根据式(4)的弊端,文章提出了多种奖励策略相结合的奖励函数,即增加r3以改进该奖励策略。
式(5)中,d、d`分别表示机械臂末端与目标点在这一时刻及下一时刻的距离。在上式(6)中,奖励函数包含了r1、r2、r3三部分。其中,r1表示机械臂末端与目标点之间关于距离的惩罚性奖励函数,二者的间距越大,r1值越大,表示惩罚越严重,反则反之。
3.4 整体机械臂抓取控制策略设计
结合以上输入、输出,以及对奖励函数的改进,将DDPG的网络结构设计为如图4所示。
DDPG包含策略网络和价值网络,它们的学习率均是10-3,奖励折扣率y=0.9,回放记忆单元存放数据量为30000,单次提取的数据batch_size=32。根据上述设计的网络结构看出,首先从save、R、S以及S_中调取出经验回放池内的数据,应用Actor网络和Critic网络进行对其训练。然后,应用依据策略梯度和TD残差更新策略网路和价值评价网络的权重,实现参数优化。
4 实验验证
4.1 参数设置
设训练集总数为2000,每集最大步数为300,目标区域的大小为40×40。若目标域连续停留50步,即可判定控制机械臂已经抵达目标点并处于稳定状态,随即终止该轮训练。
4.2 实验结果
4.2.1 不同奖励函数下的奖励变化趋势
reward_trend表示平均奖励随训练集数的变化趋势。同时为对比该算法的优势,将上述改进的奖励函数与传统的A3C奖励函数进行对比。根据实验,得到图5的结果。
根据图5所示,A3C算法有效利用了cpu的多核性能,可同时对多个智能体进行训练,因此提高了计算的效率。此外,该算法还可以信息共享的方式更新结构参数,进而提高训练速度。通过对比上述两种奖励函数下的收敛速度发现,本研究提出的改进DDPG算法波动性的平均奖励上升速度更快,波动性最小,说明该算法拥有更好的收敛性,只需有效的集数就可以实现收敛上升。
4.2.2 训练效果对比
通过对比A3C算法与改进的DDPG算法在最后100集中的训练效果,得到图6的对比结果。
由图6分析,A3C算法平均每集所用步数是171.30,改進DDPG算法的平均步数是111.45。依据上图6(a),每10集进行一轮统计,发现改进DDPG算法的整体步数普遍少于A3C算法,而且相对步数的波动性更小。依据上6(b),在100集内最终达成探索任务的,A3C算法只有77%,而改进DDPG算法增加至87%。综上可知,改进DDPG算法在准确性、稳定性上都优于A3C算法,整体表现更优。
5 结语
通过改进的DDPG算法与传统的主流算法相比,在机械臂的连续控制效果方面,无论是在准确性,还是在稳定性方面,都具有明显的优势。说明文章改进的奖励函数方式对提高机械臂的稳定性具有非常积极的作用和价值。
参考文献
[1]李广源,史海波,孙杳如. 基于层级深度强化学习的间歇控制算法[J].现代计算机(专业版),2018(35):3-7.
[2]多南讯,吕强,林辉灿,等.迈进高维连续空间:深度强化学习在机器人领域中的应用[J].机器人,2019,41(02):276-288.
[3]刘乃军,鲁涛,蔡莹皓,等.机器人操作技能学习方法综述[J].自动化学报,2019,45(03):458-470.
[4]柯丰恺,周唯倜,赵大兴.优化深度确定性策略梯度算法[J].计算机工程与应用,2019,55(07):151-156+233.
[5]解永春,王勇,陈奥,李林峰.基于学习的空间机器人在轨服务操作技术[J].空间控制技术与应用,2019,45(04):25-37.
[6]卜令正.基于深度强化学习的机械臂控制研究[D].徐州:中国矿业大学,2019.
[7]王斐,齐欢,周星群,等.基于多源信息融合的协作机器人演示编程及优化方法[J].机器人,2018,40(04):551-559.
[8]周庆锋,王思淳,李德鑫,等.基于DDPG的风电场动态参数智能校核知识学习模型[J/OL].中国电力:1-8[2020-09-18].
[9]张耀中,许佳林,姚康佳,等.基于DDPG算法的无人机集群追击任务研究[J/OL].航空学报:1-13[2020-09-18].
[10]张斌,何明,陈希亮,等.改进DDPG算法在自动驾驶中的应用[J].计算机工程与应用,2019,55(10):264-270.
