基于改进型SVM的城市污水处理过程异常数据清洗方法
2021-09-14韩红桂鲁树武伍小龙乔俊飞
韩红桂, 鲁树武, 伍小龙, 乔俊飞
(1.北京工业大学信息学部, 北京 100124; 2.北京工业大学计算智能与智能系统北京市重点实验室, 北京 100124)
城市污水处理是减少水环境污染、实现城市污水资源化的一种有效途径[1-3]. 城市污水处理过程主要包括格栅、初沉池、生化反应池、二沉池等过程[4-5]. 为了实现出水水质达标,城市污水处理过程需要根据实时状态数据、出水水质数据以及工况环境数据等信息,调节过程可操作变量,保持污水处理过程稳定达标运行[6-7]. 因此,城市污水处理过程数据的准确、实时采集和传输不仅是城市污水处理系统的重要环节,也是运行过程精确建模与闭环控制的重要保障[8]. 然而,由于城市污水处理运行过程存在运行环境复杂、过程干扰大等特点,导致运行过程易产生噪声数据和缺失数据等现象[9-11]. 例如,城市污水处理过程年记录数据包含了1%~2%的异常数据;在恶劣天气情况下,严重偏离真实值的数据甚至达到数据总量的10%~20%. 这些异常数据难以为城市污水处理过程状态估计和性能分析提供可靠的信息依据[12-16].
城市污水处理运行过程最常见的数据异常现象有2类,分别是数据噪声和数据缺失. 为了减少数据噪声的影响,刘鹏宇等[17]提出一种基于中值滤波的降噪方法,该方法通过对数据进行快速排序来获取数据中值,并对超过阈值数据进行滤波处理来达到去除噪声的效果. 然而,由于大量数据进行比较排序导致数据去噪时间较长. 冯波等[18]提出一种基于卡尔曼滤波的数据噪声抑制方法,该方法通过设计一组并行卡尔曼滤波器,采用最小均方根误差和最大后验估计的方法来估计和复原原始数据,实现数据的快速去噪. 但由于卡尔曼滤波方法难以根据工况变化准确复原数据,导致该方法易出现剔除正常数据现象. 为了准确剔除噪声数据,一些学者提出了基于距离计算的降噪方法. 例如,刘松华等[19]提出一种基于K最近邻(K-nearest neighbor, KNN)的数据降噪方法,该方法通过计算待测数据与K个近邻的距离来确定数据是否离群并清除离群数据,污水处理过程数据去噪结果显示该方法能够有效剔除数据噪声. Yang等[20]提出了一种基于模糊C均值聚类的噪声数据检测方法,通过计算数据到聚类中心的距离分离出噪声数据,仿真实验结果表明该方法的去噪精度得到了显著提升. 虽然基于距离的方法能够展现较好的去噪效果,但该方法剔除噪声数据后造成了数据空缺,结合部分检测仪表故障,数据无法及时获取,导致数据缺失现象严重.
为了解决数据缺失的问题,国内外学者提出数据插值的方法来补偿缺失数据. 例如,Lowe等[21]提出相似度学习的最近邻插值方法来填充缺失数据,该方法通过对缺失数据周围的样本点进行搜索,寻找到最近的样本点,并将该样本点作为插入数据进行数据补偿. 实验结果表明,该方法具有结构简单、计算量小、处理速度快的优点. 但污水处理过程数据具有动态时变性,缺失数据的真实值与其临近数据存在显著差异. 为此,Pan等[22]设计出一种基于线性插值的数据补偿方法,克服了最近邻插值方法数据出现直接替代的情况. 但是该方法依赖于数据节点的数目和多项式的迭代计算次数,当多个节点数据缺失时,插值精度较差,并且在使用节点过多时,插值区域两端点处发生剧烈波动,造成数据插值误差. 为了进一步提高数据插值精度,陆志芳等[23]引入一种基于前馈神经网络预测梯度的非线性插值方法,该方法首先对缺失数据特征进行预测,然后运用一维有向插值对缺失数据进行补偿;同时,Wang等[24]提出一种基于反向传播(back propagation,BP)神经网络的非线性插值方法,将其应用于污水处理过程缺失数据的补偿中,结果表明,这类方法性能稳定,具有很强的自适应能力,能够实现对缺失数据的补偿. 然而,由于这类方法的神经网络权值采用梯度下降更新方法,导致其收敛速度慢,容易过早陷入局部极小值,难以快速获取最优补偿值. 近年来,基于支持向量机(support vector machine, SVM)的方法因具有强非线性映射能力和快速收敛性等优势,在城市污水处理过程噪声和缺失数据清洗中获得了广泛应用[25-26]. Chen等[27]提出一种基于SVM的缺失数据补偿方法,将该方法应用于城市污水数据处理中,通过分析缺失数据的相关变量和训练SVM模型实现对缺失数据的预测补偿. 然而,该方法运用静态SVM模型对缺失数据进行补偿,无法实现模型参数跟随城市污水处理过程时变工况动态调整,导致在工况数据发生剧烈变化时补偿值与实测值之间存在较大误差.
为了解决上述问题,本文提出一种基于改进型支持向量机(improved support vector machine, ISVM)的城市污水处理过程数据清洗方法. 首先,对污水处理数据进行噪声和缺失值分析,设计一种基于密度估计的方法对噪声数据进行检测和剔除,获得产生异常数据的时刻值;其次,建立了一种基于ISVM的缺失数据补偿模型,预测缺失数据的真实值,实现对缺失数据的有效补偿;最后,运用粒子群优化(particle swarm optimization,PSO)算法动态更新ISVM模型参数,获得最优的ISVM参数组合,提高了缺失数据的补偿精度. 实际污水处理过程的应用效果表明,基于ISVM的城市污水处理过程异常数据清洗方法能够实现对噪声数据的剔除和缺失数据的补偿,提高了数据的质量.
1 数据采集与去噪
1.1 城市污水处理过程数据采集
城市污水处理过程数据的采集主要基于运行过程的传感器,将实时数据传送到采集仪表,如温度仪表、pH检测仪表和氨氮浓度分析仪表等;数据采集仪再通过局域网络将实时数据发送到控制柜和中央控制室的上位机中;最后运用上位机组态软件将实时数据进行画面显示和远程传输,为城市污水处理过程状态估计和性能分析提供可靠的信息依据. 城市污水数据的主要采集位置包括厌氧区、缺氧区、好氧区和沉淀池4个生化反应区. 数据采集时,各个变量设有不同的采集位置,部分变量设置多个采集点,例如:氧化还原电位(oxidation-reduction potential, ORP)设有厌氧末端和缺氧前端以及二沉池前端3个采集位置;酸碱度pH设有二沉池前端和二沉池末端2个采集位置.
具体可采集的变量位置和污水变量如下. 进水端:总磷(total phosphorus, TP)、总氮(total nitrogen, TN)、悬浮物(suspended solids, SS)、化学需氧量(chemical oxygen demand, COD);厌氧末端:ORP;缺氧前端:ORP;好氧区:溶解氧(dissolved oxygen, DO)、总可溶性固体(total dissolved solids, TSS);二沉池前端:ORP、pH、温度T;二沉池末端:TP、TN、pH.
然而,在城市污水处理过程中由于污泥质量分数一般处于较高水平,以及进水量波动、水质波动、温度变化、酸碱液腐蚀等因素会使传感器探头受污染和损坏,导致检测数据偏离真实值严重. 此外,现场数据传输局域网系统也易受电磁干扰,使得污水数据获取过程中会出现部分噪声和数据缺失的情况,进而影响城市污水处理过程状态估计和运行系统性能分析的准确性,因此,需要对城市污水异常数据进行降噪和补偿,提高采集污水数据的质量.
1.2 数据去噪
数据采集过程中出现的数据噪声会导致模型预测控制精度下降,进而增加加药能耗,降低出水水质. 因此,首先要对噪声数据进行检测,获得产生噪声数据的时刻值,然后对相应的噪声数据进行剔除.
基于密度估计的噪声数据检测方法,首先根据采集的城市污水数据样本,计算每一组数据的密度,然后依据密度阈值,将小于阈值的数据点判断为数据噪声,具体检测过程如下.
对于整个污水处理过程中的样本数据,设置q维空间中的p个数据点为X1,X2, …,Xp,每个数据点为Xi=[xi1,xi2, …,xiq],其中i=1, 2, …,p,数据点Xi的密度函数定义为
(1)
式中:Θi为样本点密度大小;αk(k=1, 2, …,q)为k维空间的密度半径且为正数,其值越大则该点影响范围越大,致使密度点越多,其值越小致使密度点越少,文中根据实际污水数据的空间分布情况确定其大小;α=[α1,α2, …,αq]定义了检测数据点的一个邻域.
按照式(1)计算所有城市污水数据点的密度大小,并将小于密度阈值Θ′的数据判断为噪声数据并进行剔除,密度阈值Θ′定义为
Θ′=ηΘmax
(2)
式中η为密度系数,密度系数值越小,则噪声点的数据周围样本分布越少,反之数据样本分布越多.
2 ISVM数据补偿模型
2.1 数据归一化
由于采集的原始数据具有不同的量纲,需要对城市污水数据进行归一化处理,文中采用0均值归一化方法,对数据进行压缩和中心化处理,具体表达式为
(3)

2.2 特征变量选取
为了去除与待补偿数据无关的变量,降低ISVM数据补偿模型的计算复杂度,设计一种基于主成分分析(principal component analysis, PCA)的筛选方法,筛选得到影响待补偿数据精度的关键变量,具体步骤为:
1) 根据式(3)获得归一化处理后的标准污水数据,求得标准化矩阵Z,Z=(zij)p×q,以及与Z对应的协方差矩阵V,V=(vjd)q×q,d=1, 2,…,q,vjd为待补偿污水数据和相关变量之间的相关系数,vjd表示为
(4)
2) 特征方程为|λI-V|=0,通过求解特征方程得到各特征值为λδ(δ=1, 2, …,q),并按由大到小的顺序对各特征值进行排序.其中,I为与协方差矩阵V相对应的单位矩阵.
3) 求出与各特征值λδ相对应的特征向量eδ(δ=1, 2, …,q).
4) 计算各个相关变量与待补偿污水数据的相关性大小μj和累计贡献率G(l),分别为
(5)
(6)

图1 城市污水数据采集与清洗架构Fig.1 Data collection and cleaning schematic of municipal wastewater
然后,选取累计贡献率G(l)较大的前l个变量作为待补偿数据的关键特征变量.
使用式(3)~(6)分别对城市污水处理过程中的14种变量进行相关性分析,获得与待补偿数据具有强相关性的关键特征变量.
2.3 ISVM污水数据补偿模型设计
为了实现对城市污水缺失数据的补偿,设计一种基于ISVM的缺失数据补偿模型.模型架构图如图1所示.设定训练集为Ω={(Xi,yi)|i=1, 2, 3, …,n},Xi∈Rn,yi∈R,其中,xi为n维的样本输入数据,yi为相应的补偿输出数据.然后,将输入的城市污水向量X经过非线性变换φ:X→φ(X),Rn→O,映射到高维空间O,再在高维特征空间通过线性函数yi=w′·Xi+b进行回归,获得缺失数据的补偿值.其中b为阈值,w′为权值向量.
为了避免ISVM数据补偿模型出现过拟合,提高模型泛化能力,降低经验误差,设计模型优化目标为
(7)
约束条件为
(8)

式(7)的目标优化过程为凸二次规划问题,因此,采用Lagrange函数求解,即

(9)
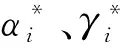
(10)
为了避免维数过高带来的计算复杂度,文中采用径向基核函数
K(Xi,yi)=exp [-γ‖(Xi-yi)‖2]
(11)
(12)
得到ISVM的回归函数为
(13)
2.4 粒子群算法优化ISVM参数
为了提高数据补偿的精度,文中采用粒子群优化算法在H维空间中搜索最优的SVM参数对g、C,并通过适应度函数对解的性能进行评价.具体数学描述如下.
粒子群优化ISVM模型参数的过程中,每个粒子代表H维解空间的一个点,设置某个粒子的当前位置为mi=(mi1,mi2, …,mih)、当前飞行速度为vi=(vi1,vi2,…,vih)和当前寻找到的最优位置为pg=(pg1,pg2, …,pgh),并将mi、vi、pg分别表示为向量形式.每个粒子都具有经过目标函数评价计算得到的个体适应度值,通过个体最优值和群体最优值来调整粒子飞行速度,进而调整自身位置向最优点靠拢.粒子调整自身速度和位置的公式分别为
(14)
(15)

为了提高算法的收敛速度,设置w随迭代次数增加而减小,w更新公式为
w=wmin+(Dmax-D)×(wmax-wmin)/Dmax
(16)
式中:wmin为PSO中的最小权值;wmax为最大权值;Dmax为最大迭代次数;D为当前迭代次数.
由于r1和r2为分布在[0, 1]的随机数,不具有遍历特性,所以通过
ri(k+1)=4.0ri(k)[1-ri(k)]
(17)
对粒子群优化算法中r1和r2的值进行选择以提高PSO的全局收敛性.式中ri(k)∈(0, 1),i=1, 2.
在粒子群优化算法中,种群大小的选择对搜索空间解的性能具有重要影响.当种群数量过大时,会使算法求解时间较长,难以满足城市污水处理过程对实时性的要求;当种群数量选取过小时,虽然运算速度较快,但会导致算法过早收敛,多样性较差,难以满足数据补偿精度的要求.为此将粒子种群数量设置为20进行迭代计算,即自身维数的5倍.同时设置迭代次数为200次,即适应度值达到基本稳定.
判断粒子性能的适应度函数设为
(18)

PSO算法优化ISVM模型参数g、C的过程中,每个粒子的位置和速度由二维参数g、C决定,适应度函数设置为能够直接反映ISVM回归性能好坏的均方根误差(root mean squared error,RMSE).PSO优化ISVM参数g、C的流程如图2所示,具体步骤如下.
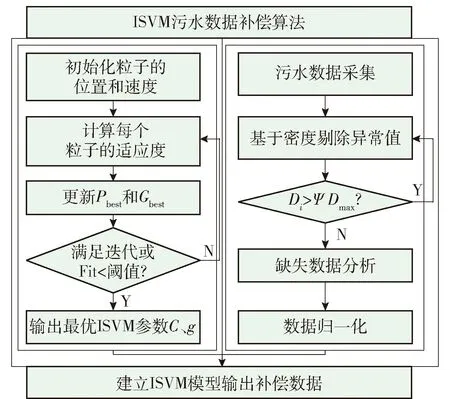
图2 ISVM污水数据补偿算法Fig.2 ISVM sewage data compensation algorithm
步骤1首先,初始化粒子群优化算法中的所有参数,设置种群数量a=20,最大权重wmax=0.8和最小权重wmin=0.1,算法最大迭代次数Dmax=200,加速因子c1为1.5,c2为1.7.同时,由于同时优化的g、C两个参数的量纲差别较大,所以在初始化粒子速度时乘以相应系数使数据大小一致.
步骤2将每个粒子的个体极值Pbest设置为粒子的当前位置,然后利用适用度函数(18)计算当前所有粒子的适应度值,并将全局最优值Gbest设置为适应度值最小的粒子对应的个体极值.
步骤3按照式(14)~(16) 更新粒子的位置、速度,生成新的种群.
步骤4运用适应度函数(18)计算所有粒子的适应值,适应度值越小,则位置越优.
步骤5对粒子的当前极值和个体极值进行比较,保留适应度值较小的粒子作为个体极值,更新Pbest.
步骤6删除适应度值最小的粒子,并根据式(15)产生新的粒子.
步骤7比较每个粒子的个体极值Pbest和全局极值Gbest,当个体极值优于全局极值,则更新Gbest,否则保存原来的Gbest.
步骤8判断终止条件,当达到最大迭代次数或者所得解不再变化时终止,否则返回步骤3继续更新粒子.
3 仿真实验与分析
3.1 实验设计
为了验证文中基于ISVM的城市污水处理过程异常数据清洗方法的有效性,采用2019年北京市某污水处理厂真实数据进行实验,并对实验结果进行分析. 同时,为了证明该方法的精确性,将该方法与基于BP神经网络方法、线性插值方法、最近邻插值方法和卡尔曼滤波方法的数据清洗效果进行了实验对比.
本次实验共有570组污水样本数据,首先对污水处理过程中关键9种数据进行异常和缺失值分析. 通过分析对异常和缺失值变化较大的DO质量浓度数据进行预测补偿. 将370组正常数据样本分为两部分,随机选取220组数据作为模型训练样本,150组数据作为测试样本. 模型输入为PCA法筛选得到的关键特征变量:缺氧前端ORP、进水SS、进水COD、进水TP. 模型输出为DO质量浓度. 其中ISVM模型参数C、g通过PSO算法进行参数调优. 将基于BP神经网络的数据清洗模型的网络结构设定为9-10-1,采用非线性的Sigmoid函数作为传输函数,学习算法为最小二乘法,设定学习率为0.1,训练步数是1 000步.
根据仿真结果分析模型精度,比较二者的数据清洗结果. 然后,随机选择50组污水样本,分别采用基于BP神经网络的数据清洗方法、最近邻插值方法、线性插值方法和卡尔曼滤波方法对污水数据清洗效果进行实验,并与基于ISVM的数据清洗方法进行比较,通过RMSE对清洗效果进行对比,计算公式为
(19)
3.2 实验结果与分析
图3、4为污水处理厂2019年真实污水数据的曲线图,共采集、分析9种污水数据,包括好氧前端DO、好氧末端TSS、进水TP、出水pH、温度T、进水SS、进水COD、进水氨氮和缺氧前端ORP. 通过分析,污水数据DO质量浓度存在较大的数据噪声和缺失.

图3 污水多个参数曲线1Fig.3 Multiple parameter curve 1 of sewage
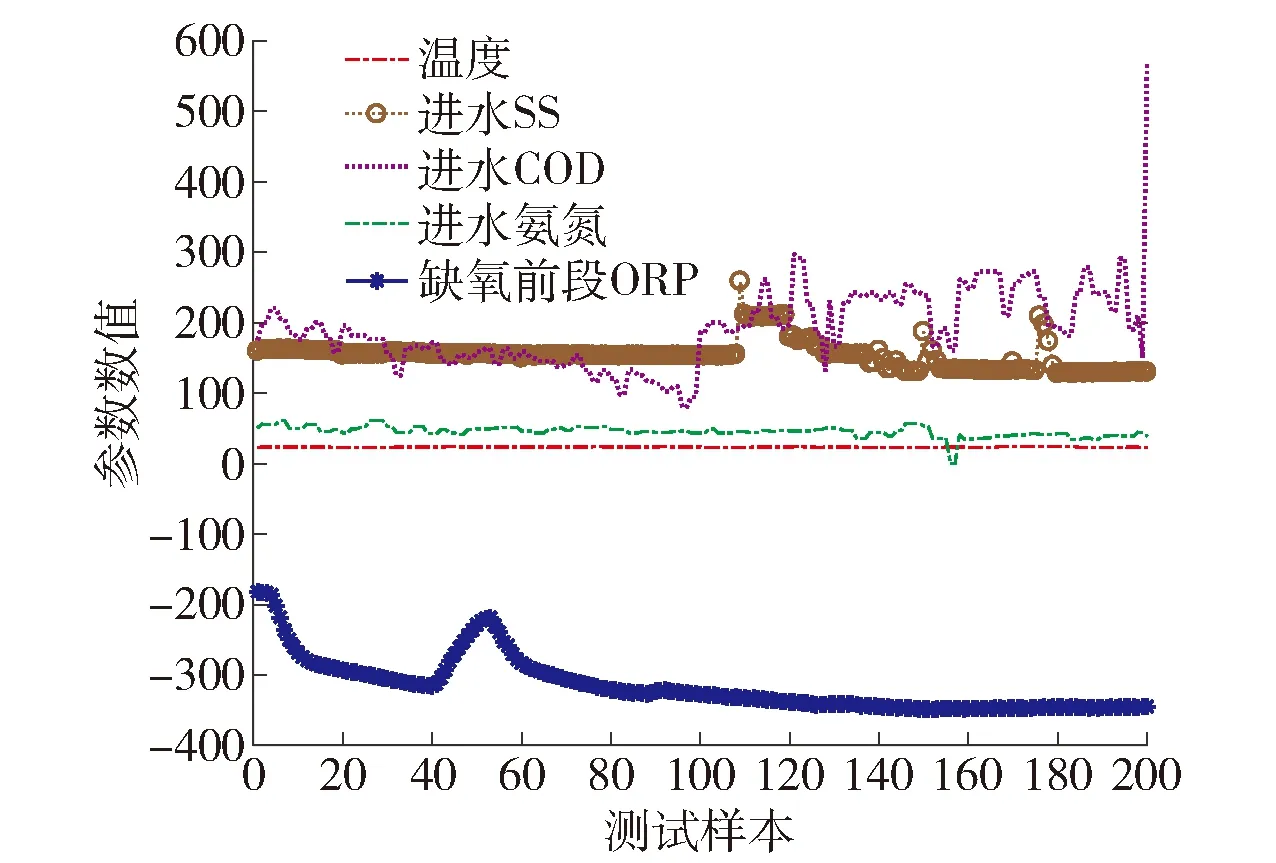
图4 污水多个参数曲线2Fig.4 Multiple parameter curve 2 of sewage
图5、6分别为基于密度聚类算法和基于K-means聚类算法的城市污水数据异常情况分析图. 从图5可以看出,pH数据集中分布在7.98~8.07,符合数据正常区间;DO质量浓度数据分布在0~1.6 mg/L,数据波动较大,存在离群点和噪声点数据,并且部分数据缺失或采样点为“0”值,采用密度聚类算法可以精确地识别噪声点和离群点. 从图6中可以看出,采集数据的分布情况、存在缺失值和“0”值的异常点,但识别噪声点和小聚类簇结果较差.

图5 基于密度的数据异常分析Fig.5 Density-based abnormal data analysis
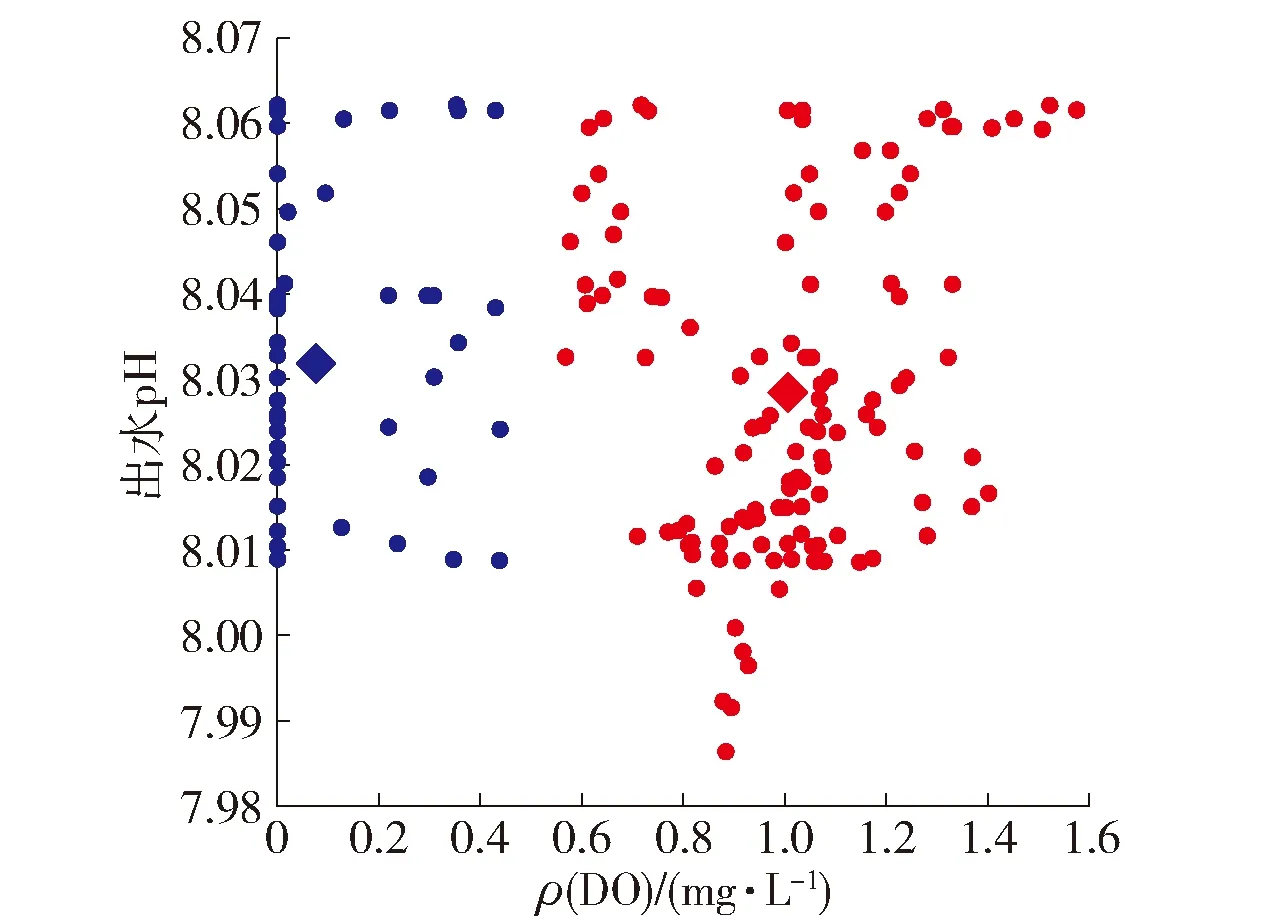
图6 基于K-means的数据异常分析Fig.6 Abnormal data analysis based on K-means
图7为城市污水数据的相关性分析结果,图像颜色为0~1的相关性大小. 从图中可以看出,部分城市污水变量具有较大相关性,如好氧末端TSS与温度T、进水TP、进水COD,好氧前端DO与进水SS、缺氧前端ORP、进水COD具有较大相关性. 基于ISVM的污水数据清洗方法对于城市污水处理过程中采样数据存在噪声和数据缺失的情况能够根据城市污水数据相关性的特点进行噪声数据的剔除和缺失数据补偿.

图7 城市污水数据相关性分析结果Fig.7 Correlation analysis results of municipal sewage data
图8、9分别给出基于ISVM的污水数据清洗方法和基于BP神经网络的污水数据清洗方法的清洗效果对比和清洗误差对比,图7为PSO算法优化ISVM模型参数后的数据清洗结果. 从图8、9可以看出,相比于BP神经网络方法,基于ISVM的污水数据清洗方法得到的补偿数据和实际值相差较小,预测曲线能够较好地拟合目标曲线值. 结果表明,基于ISVM的城市污水数据清洗方法能够通过非线性映射在高维空间进行回归,得到待补偿污水数据(如DO的质量浓度)与采集特征变量之间的关系,比基于BP神经网络的数据清洗方法具有更好的缺失数据补偿精度,可以获得更加精准的数据清洗效果. 同时运用PSO算法优化ISVM模型参数,从图10可以看出,经过参数调优后的模型具有更精确的数据清洗能力,误差稳定在可接受范围内.
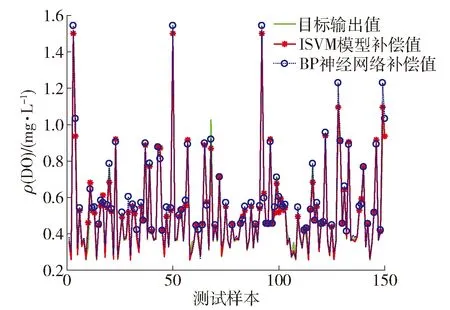
图8 污水异常数据清洗的清洗效果Fig.8 Cleaning effect of sewage abnormal data cleaning

图9 污水异常数据清洗的误差对比Fig.9 Error comparison of sewage abnormal data cleaning
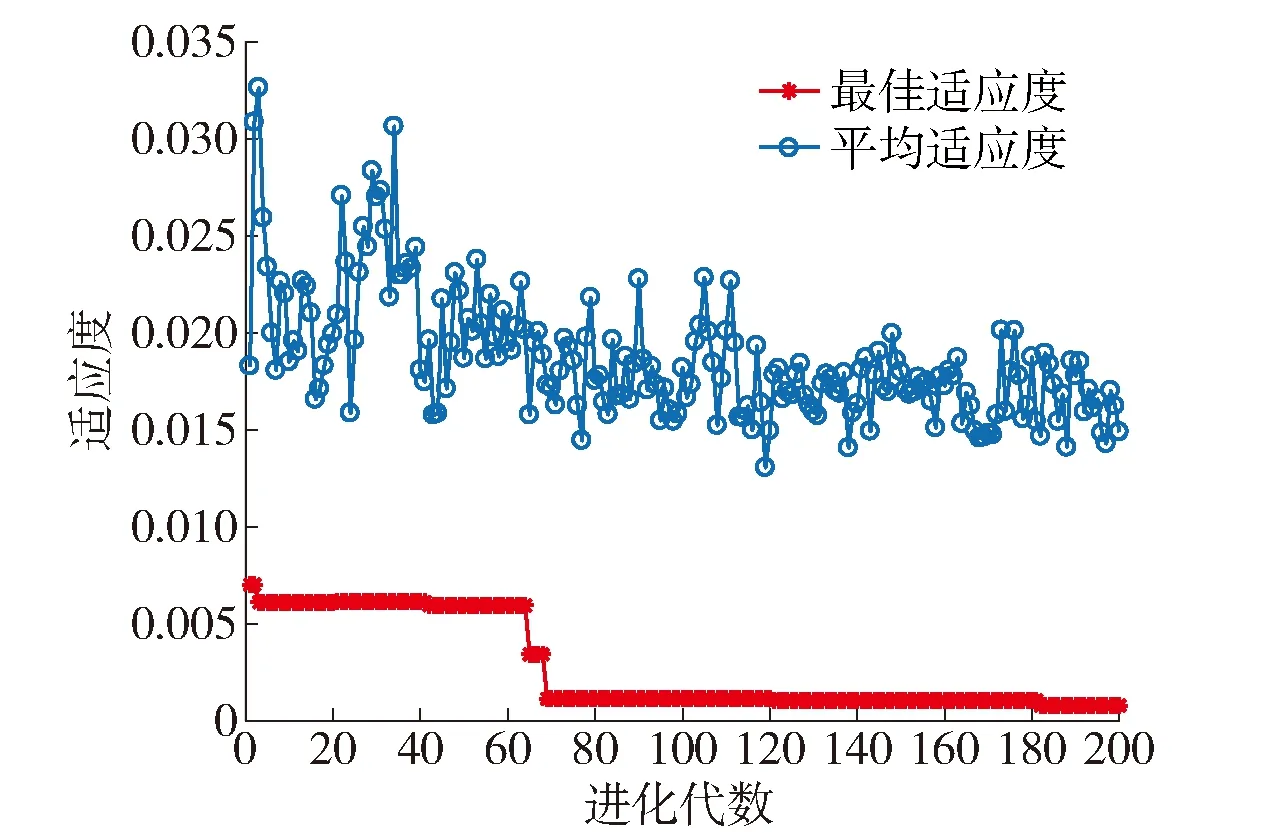
图10 PSO算法优化ISVM后适应度曲线Fig.10 ISVM fitness curve optimized by PSO
表1给出了支持向量机模型参数C、g调优前后的数据清洗结果比较,可以看出,以PSO优化后的C、g作为ISVM数据清洗模型参数可以获得更高的数据补偿精度,提高数据质量,能够满足污水处理系统建模与闭环控制过程中对数据可靠性和精确性的要求.

表1 ISVM参数优化前后的清洗性能比较
表2给出了基于ISVM的污水数据清洗方法与基于BP神经网络的污水数据清洗方法、最邻近插值方法、线性插值方法和卡尔曼滤波方法的均方根误差对比.

表2 不同数据清洗方法的时间和误差对比
从表2可以看出,在数据清洗过程中,相比于BP神经网络方法、最近邻插值方法、线性插值方法、卡尔曼滤波方法的清洗结果,基于ISVM的方法具有更小的均方根误差. 其结果表明,文中基于ISVM的城市污水处理过程异常数据清洗方法能够实现对缺失数据的补偿,满足系统对数据可靠性和实时性的要求.
通过与不同的数据清洗方法的对比,基于ISVM的城市污水异常数据清洗方法的准确性和实时性得到了验证. 综合以上分析,基于ISVM的城市污水异常数据清洗方法能够实现对污水噪声数据的剔除和缺失数据的补偿,提高数据的质量.
4 结论
1) 采用基于密度估计的方法检测出污水处理过程中的噪声数据,实现了对污水噪声数据的剔除.
2) 与BP神经网络的数据清洗方法、最近邻插值方法、线性插值方法和卡尔曼滤波方法相比,基于ISVM的城市污水异常数据清洗方法具有更高的补偿精度,提高了数据质量.
3) 利用PSO算法对ISVM数据清洗模型参数进行优化,提高了模型对缺失数据补偿的精度,在城市污水处理过程中能够满足数据实际应用的需要.
