基于Faster-RCNN的昆虫小目标检测研究
2021-09-06易星
易 星
(沈阳化工大学信息工程学院,辽宁沈阳 110142)
目标检测是计算机视觉中较为热门的研究方向,主要包含相关的目标定位和识别.目标检测准确来说是在复杂背景的图像中找到目标并进行边框标注以及识别出目标的类别[1].检测效果对图像的语义理解和目标重识别有直接影响,当前目标检测已经广泛应用于医学图像分析及检测和监控系统中,因此展开目标检测研究对科技的发展有重要意义.
小目标检测[2]是目标检测中的一类分支,相比于常规图像的检测,小目标检测所需的技术和算法更严格.所谓小目标就是图像中占比像素更少,提供的特征信息也相对较少,通常只有几十个像素,如图1(a)为小目标数据集,图1(b)为检测结果,本次实验数据所包含的都是昆虫标本图像,所以研究小目标检测是非常有意义的,尤其对目前安防、交通、救援等方面[3]有重要的应用价值.
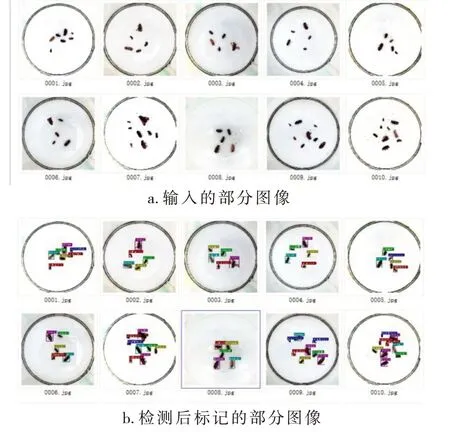
图1 昆虫标本图像
Krizhevsky等人[4]提出AlexNet是在2012年,利用ImageNet 在图像分类上取得了突破性成果,在这之后,很多从事计算机视觉任务的研究者利用深度学习和卷积神经网络来进行目标检测、图像分割等任务,并取得了不错的效果.相较于传统的目标检测方法,深度学习的检测方法具有更高的检测精度以及特征提取充分等优点.因此,深度学习方法被科研工作者应用于各个领域.当前大多数的视觉任务基本都是围绕CNN 来开展的.但是,深度学习在小目标任务检测上所达到的效果远不如常规目标检测.本文所述方法针对小目标检测,使得检测效果有一定提高.小目标检测主要有以下两个难点:
(1)目标在信息量较为复杂的情况下占比较小,所反映的信息是有限的、甚至达不到检测效果,这就使得常规目标检测的算法很难用于小目标检测.在小目标检测任务中,只有特定算法才能达到特定效果,不适用于所有的检测任务,通用性不强.
(2)从小目标检测任务中来看,对图像目标的标记[5]是一个难题,在作为训练数据时出现误差对整体结果的影响很大;与此同时,数据标记需要耗费的人力、物力资源和时间成本都较大,使得所讨论的数据集较小.
针对上述的问题,本文提出了基于卷积神经网络为基础的小目标多尺度的Faster-RCNN 检测算法[6].该算法在结构上有相应的改变,主要是将高层和低层特征多尺度的提取特征,通过可视化技术对模型进行分析后,使得针对小目标检测所提出的方法能较好地解决本文所提出的问题.
1 相关工作
在2014年,Felzenszwalb等人[7]提出了可变形部件模型(deformable part model,DPM),随后在目标检测领域应用了该模型,达到了很好的效果.引入深度学习方法后,DPM的检测效果相比于深度学习来说效果不够显著,因此,深度学习成为目前经常被使用的方法,尤其是在目标检测领域成为绝大多数研究者热衷的一个研究领域和方向.区域卷积神经网络(Regions with Convolutional Neural Network,RCNN)系列[8]的方法在进行目标检测时效果也非常显著.Girshick 等人[9]提出的RCNN 结合了候选区域生成和深度学习两方面的分类方法,RCNN 先对候选区域进行分割,再通过卷积神经网络将区域内的特征充分提取,之后进行分类器回归操作,但是由于候选区域难以避免的重叠部分导致该方法效率较低.在何恺明等人[10]提出空间金字塔池化网络定义和Sermanet等人[11]提出目标定位方法后,Girshick等人[12]提出了以RCNN 为基础的Fast-RCNN,随之再将目标区域池化(region of interest pooling,ROI pooling)也引入其中,有利于图像特征的归一化,得到目标的特征图是尺寸大小相同的.这有利于避免重复卷积特征.该方法在精度和速度上都明显优于RCNN.Fast-RCNN 之后,任少卿等人[13]再一次提出了Faster-RCNN 算法.这种方法的原理是利用锚点(anchor)方式生成候选区域,并将候选区域生成工作也交由网络来完成,速度和精度相较于Fast-RCNN 有进一步提升.在此之后Redmen 等人[14]提出了比Faster-RCNN 更快的目标检测方法YOLO(you only look once).YOLO 是将目标检测当作回归问题处理,不需要候选区域生成,仅需划分回归目标边界框和将所属类别定义准确.因此,YOLO 方法具有更快的检测速度,但是同样在小物体检测方面效果不明显,这两类方法在常规目标检测方面都有不错的检测效果.然而,在非常规的目标检测、尤其是小目标检测中,这些方法便不适用.实际上,达不到预期目标的主要原因是在深度学习提取小目标信息时,目标特征表示不出更多的有效信息,导致检测方法对物体进行检测时达不到要求.Takeki 等人[15]提出的小目标检测方法结合了图像语义分割内容,这种方法是把全卷积网络、卷积神经网络和支持向量机(support vector machine,SVM)[16]结合在一起,只适用于图像信息较为简单的场景中,检测仅限于天空下的小鸟这样的任务.由此可见,虽然科研人员在小目标检测上花费了很多功夫,但是都不达到理想的效果,不具有通用性.
2 多尺度Faster-RCNN检测算法
2.1 多尺度检测
在卷积神经网络中,通常低层特征能更好地将图像纹理[17]和边缘信息反映出来,高层特征更多的是倾向于对图像的语义信息反映,会对图像中比较细节的信息忽略,在目标非常小的时候,图像中能得到的特征信息是有限的,因此需要低层特征去对细节信息进行提取和识别小目标.为此,在图像信息进行重构[18]方面使用的是梯度上升法提取小目标的特征.如图2所示.

图2 实验中所采用的昆虫标本图像
通常的Faster-RCNN 特征信息目标区域池化由最后一个卷积层完成的,显然这种方法不适用于小目标检测.高层特征对小物体检测会因为特征提取不充分产生较大的问题,通过学习SSD 算法[19]之后利用了多尺度检测,这就使得我们的特征提取不单单是采用最后一层特征,而是从多个尺度来进行卷积网络提取.具体流程如图3所示:输入图片首先在CNN 中实现特征提取,将各个层提取的特征送入RPN 生成候选区域[20],对于不同尺寸的候选区域信息,所需的anchor box 尺寸也是不同,越低层的特征所选择需求的候选区域会占比更小.在得到生成的候选区域和feature map的映射之后通过ROI pooling 来将特征归一化,送入分类器中,通过这种方式来充分对小目标的特征信息进行提取,从而实现小目标检测.
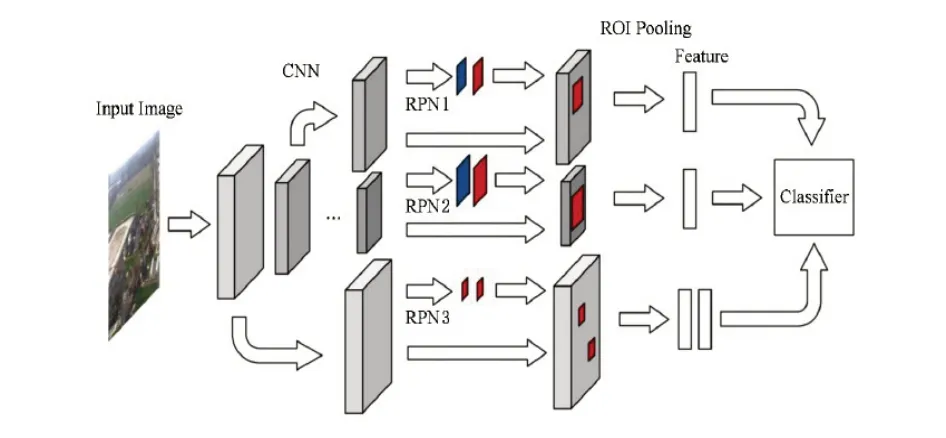
图3 RPN特征提取流程图
2.2 训练数据变换
网络结构的改进解决了小目标检测的瓶颈,针对小目标检测中训练的样本标记较难并且样本不易获取,因此训练的数据集较少.我们以昆虫为主要的图像进行目标特征提取,如图4 所示.训练、验证和测试的图像中昆虫分布是不规则的,因此,数据的分布可能存在一些差异.图4(1)为部分训练图像,图4(2)为验证图像,图4(3)为小目标检测的部分测试图像.

图4 训练数据中各个阶段中所用的昆虫标本图像
我们采用T-SNE[21]的方法将图像进行特征降维以此验证高分辨率(high resolution,HR)和低分辨率(low resolution,LR)目标在分布上存在差别,采用的特征网络是FPN,用低分辨率图像来训练模型,再用目标高分辨率图像测试[22].对ROI pooling 层后得到的大小相同的特征同样用TSNE方法进行降维.实验结果显示两者确实存在很大差异.
3 实 验
3.1 实验设置及效果
实验采用的数据集主要采用标本数据集,检测的小目标为昆虫.为了试验精度和准确性,昆虫标本采用实验室培养基下的标本.图像数据集共有217 张,采用的是ResNet50 作为backbone 选择,使用FPN 网络作为特征网络进行实验,选择COCO 作为预训练模型.因为检测目标是昆虫,所以,图像尺寸统一固定在最短输入尺寸是800、最长输入尺寸是1333;在训练参数设置方面,为了能更精确地得到训练模型,迭代轮数增加到了12,学习率设置为0.00250000,warm up步数设置为84,学习率衰减轮数为[8,12],warm up的初始学习率是在0.00083333.模型训练loss收敛情况如图5 所示.图中展示了随着迭代次数的增加,loss的收敛情况以及loss_rpn的变化等情况.可以看出,模型都在迭代1000 次时趋于收敛,随着loss的降低,训练的模型也达到了较高水平.
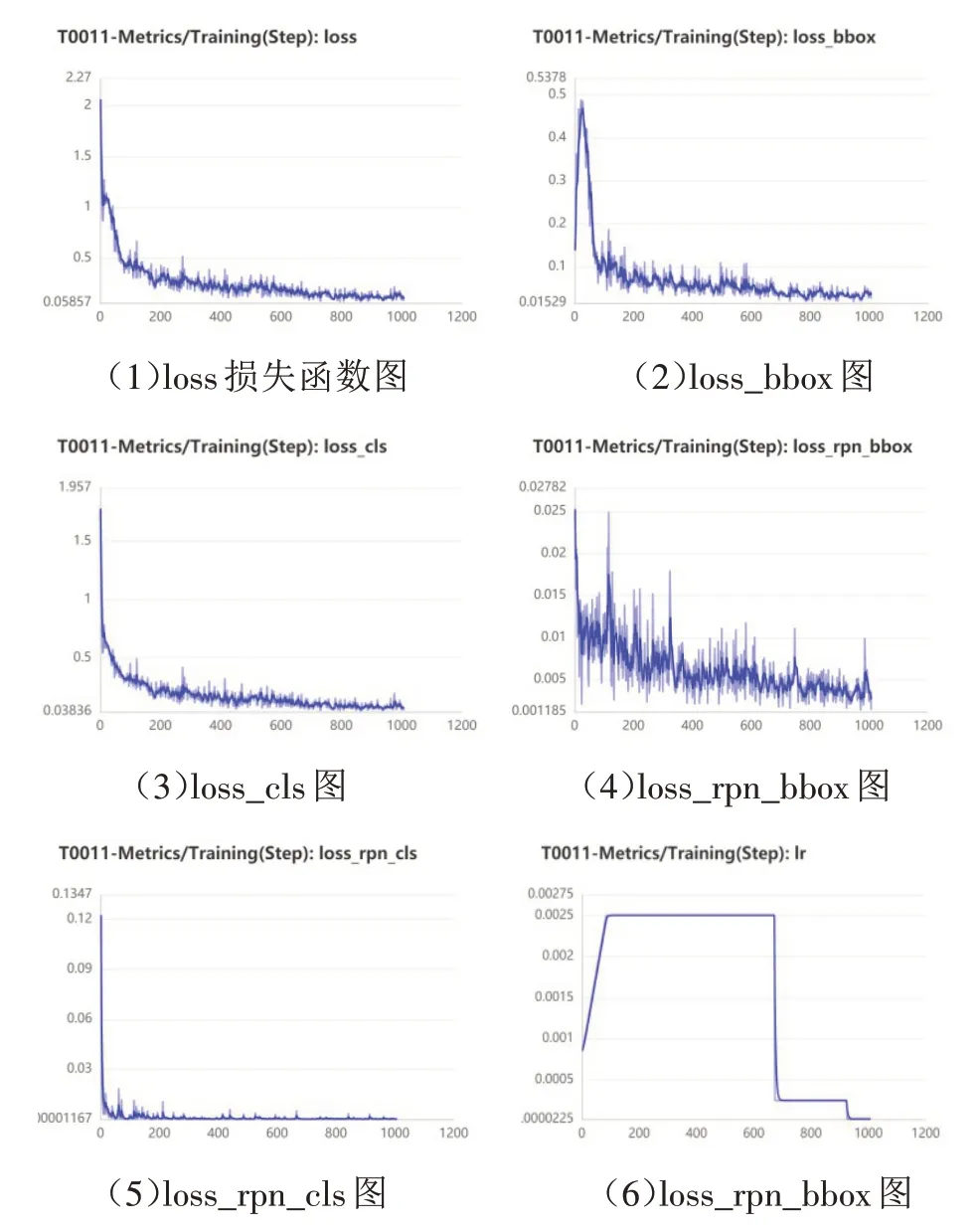
图5 模拟训练中loss收敛情况
3.2 实验结果
将目标低分辨率数据集划分成3 部分,昆虫类别为6类,169 张用于训练数据集模型,24 张用于验证数据集,24 张用于测试数据集,数据集图片如图6 所示.

图6 训练数据集部分
检测出来并进行标记的图片如图7所示.

图7 检测出来后数据集部分
在FPN特征网络下所得的检测结果如下表1所示.
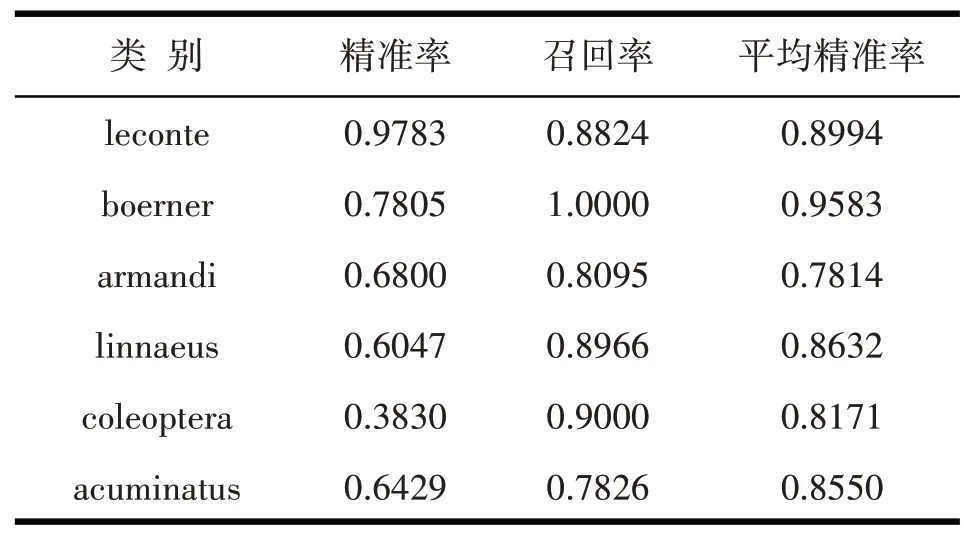
表1 各类别目标检测精度及召回率
从表1中可以得出两个结论:
(1)高层特征与低层特征相互弥补和使用多尺度检测的方法,对小目标的检测精度都有较为明显的提升,这说明结合深度网络的低层和高层特征进行多尺度检测的方法在一定程度上确实可行.
(2)检测时需要高分辨率和低分辨率相互结合来进行训练模型,这样的检测效果可以达到更好.仅使用高分辨率图像作为训练数据的模型检测效果不佳,仅使用低分辨率图像作为训练数据的模型检测效果相对较好,因此采用折中的方法可以达到理想的效果.将24张测试图像的平均检测时间作为评估计算复杂度[23]的指标,在FPN 特征网络下所得的检测结果如图8所示.

图8 检测后图像的标记和分类
第1 列表示模型使用的网络结构,之后每一列第1 行表示采用哪一层的特征进行检测,表示采用全部三个特征.VGG的conv1_2,conv2_2,conv5_3分别简写为conv1,conv2,conv5.
从图9(1)(2)中可以得出两个结论:
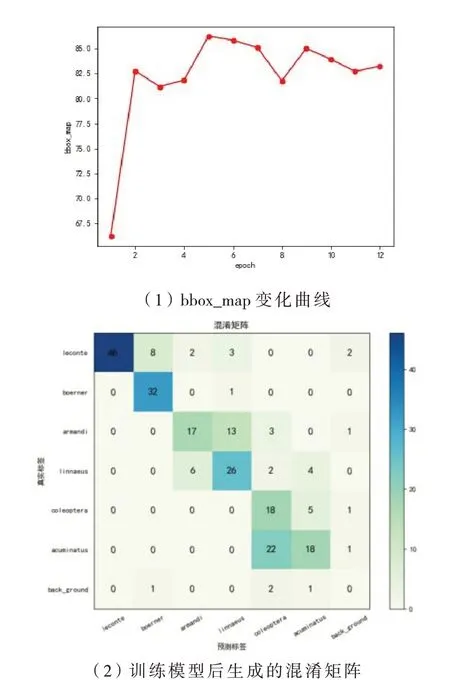
图9 数据集模型训练中相关参考数据
(1)在只利用一个特征检测时,利用高层特征的平均检测时间相对较少,这说明大的低层特征是适用于小目标检测的,但会带来较高的计算开销.
(2)实时性较低的任务检测可以通过多个特征增加计算开销在可接受的范围内进行.
从图9还可以看出:
(1)通过下采样的方法训练高精度的目标检测模型是可行的并且效果很好,这说明下采样的方式可以减轻目标高分辨率图像和目标低分辨率图像数据差异带来的影响.
(2)最大池化在这样一个问题信息量有限,特征以及像素点不多的背景下一般比平均池化效果要好.
(3)结合采样变换前后的目标高分辨率图像和低分辨率图像所训练出的模型检测精度偏高,这表示对目标高分辨率图像进行采样变换对目标高分辨率图像和目标低分辨率图像数据差异确实有一定影响甚至改善的效果.在小目标检测数据难以标记、缺少训练数据的情况下,为了提升检测精度,可以对训练的数据量稍微增加.
4 总结与展望
目标检测在计算机视觉领域是相对较为热门的,也深受科研人员的关注,但是当前常规目标检测的方法应用在小物体上的检测效果不太明显.当前科研人员所研究出来检测小目标的方法通用性太差,往往只能检测单一小物体.因此,本文对小物体检测进行了小目标检测初步研究,以卷积神经网络为起点以及对Faster-RCNN 进行有效的改进后,引入多尺度检测,将高层与低层特征相互弥补的方式对小目标进行多尺度检测,进而得出物体检测结果.依照这样方式所改变的针对性较强的算法,相较于原先Faster-RCNN 算法在检测精度上有明显的变化.由于计算机硬件方面的问题,本文所采用的数据集较小,训练出来的模型精度相较于专业图像检测设备检测出来的精度和准确度有很大差距,未来将从以下两个方面进行相关研究:
(1)尝试于其他的方法进行改进应用于小目标检测,在改进的硬件基础上对算法优化调整,进一步提升检测精度.
(2)信息表达是小目标检测目前主要面临的问题和瓶颈,其次诸如像素分类问题也是当前的难点,我们可以基于上述情况尝试其他领域的研究包括图像分割、遥感分割等.
