正则化参数自动优选的RAKSVD方法在地震弱信号去噪中的应用
2021-08-09乐友喜杨杰飞陈艺都吴佳伟
乐友喜, 杨杰飞, 陈艺都, 吴佳伟, 杨 涛
(1.中国石油大学(华东)地球科学与技术学院,山东青岛 266580; 2.黄河勘测规划设计研究院有限公司,河南郑州 450003)
随着勘探技术的快速发展,勘探目标转向了复杂的隐蔽油气藏,对于深部的复杂地质构造,地震波在介质中经过较长距离的传播、散射以及介质非弹性造成的能量衰减,使得深层反射信号相对较弱,弱信号常淹没在背景噪声中[1-2]。常用的地震弱信号识别方法包括基于奇异值分解(SVD)的方法[3]、基于非线性动力系统的混沌理论[4]、基于经验模式分解(EMD)的Hilbert-Huang变换[5]、基于独立分量分析(ICA)的盲源分离(BSS)技术[6]以及基于高阶统计量识别[7]等。Aharon[8]提出了KSVD(K均值奇异值分解)算法,韩文功等[9]提出的SVD分解方法可以较好地进行弱信号的识别和去噪。但KSVD算法需要多次进行SVD分解,效率较慢。Rubinstein等[10]在KSVD的基础上提出了AKSVD(approximate KSVD)算法,提高了效率,但其效果不甚理想。Irofti 等[11]将正则化引入AKSVD的字典学习,Dumitrescud等[12]在KSVD基础上引入了正则化,完善了RAKSVD(正则化近似KSVD)方法,该方法既提高了计算效率,又可使分解效果基本不受影响。但其中的正则化参数都是人为给定的固定值,显然在SVD迭代分解时,误差项缩小,而系数误差项扩大,这是不准确的。笔者对正则化参数对迭代结果的影响进行研究,通过L曲线进行正则化参数的自动优选,形成基于正则化参数自动优选的RAKSVD去噪方法。
1 RAKSVD方法基本原理
1.1 KSVD算法
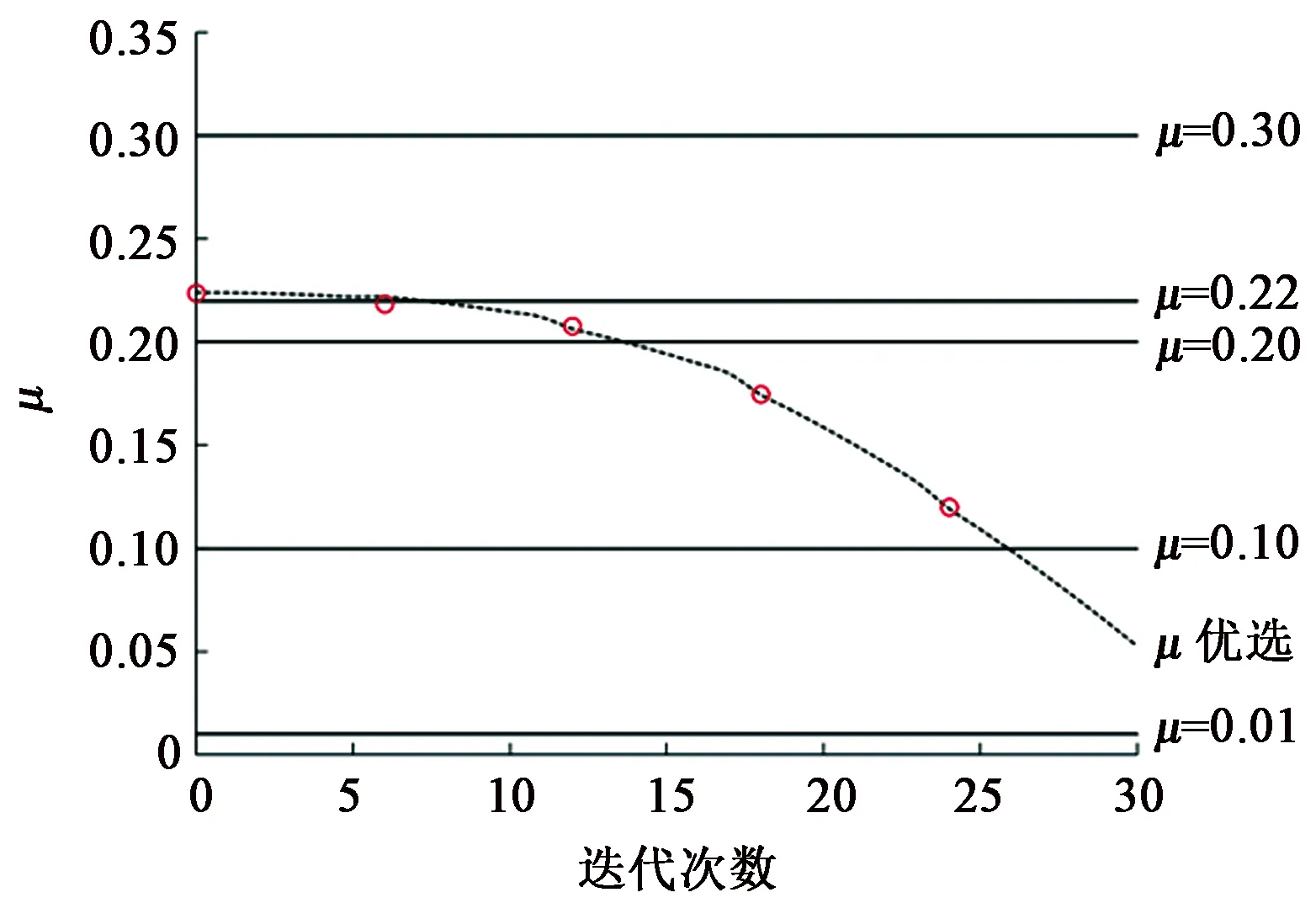
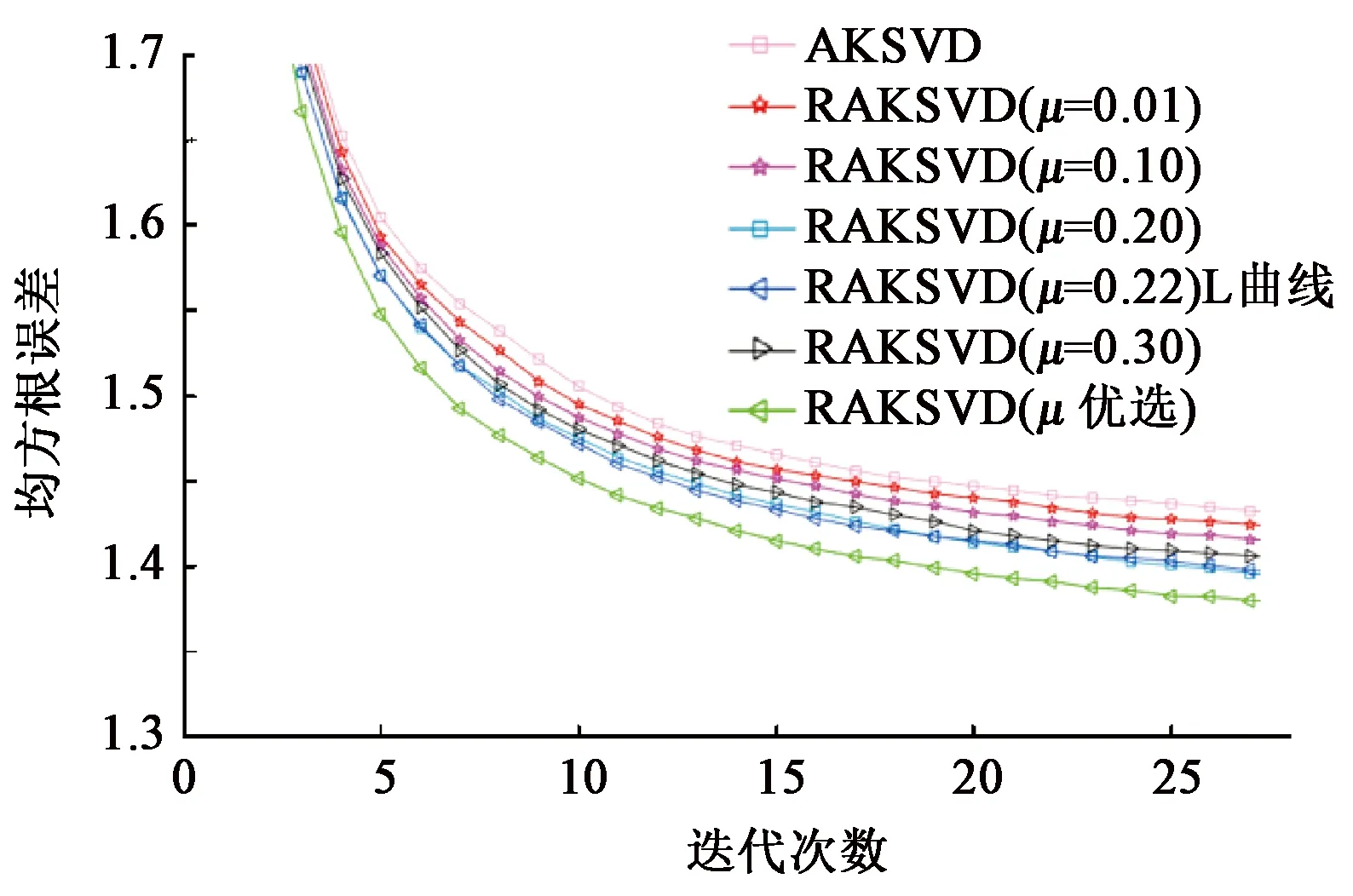
信号可以通过字典进行稀疏表示,但初始化固定字典并不能保证已知信号的稀疏程度,从而不能准确表达信号,为了使稀疏分解更准确,通过KSVD构建字典,使已知低维信号都可以进行较为准确地稀疏表示。KSVD算法是通过训练信号对初始化字典进行逐列更新,用来寻找一个最佳字典的过程。假定训练的信号为Y∈Rm×n,其中m为信号的行数;n为信号的列数。每列对应一个训练样本,对于给定的冗余字典D∈Rm×p,其中p为字典的列数且m (1) 先固定字典D,用正交匹配追踪(OMP)算法对每一个样本做稀疏表示,获取稀疏分解系数矩阵。然后进行字典更新,KSVD对字典原子逐列进行。 (2)计算残差: (2) 式中,Ek代表剩余残差。 (3) 式中,U为左奇异矩阵;V为右奇异矩阵;Λ为奇异值合集;r为非零奇异值的个数;ui为左奇异矩阵的第i列;σi为第i个奇异值;νi为右奇异矩阵的第i列。 (4)原子和稀疏系数应更新为 xk=σ1ν1,dk=u1. (4) 由于KSVD算法分解效率较慢,而且每次更新一列都要SVD分解,导致算法较慢,实际应用不大。对此,Rubinstein等[10]提出了一种近似KSVD(AKSVD)算法。AKSVD算法的原子和相关系数分别按如下公式更新: (5) (6) AKSVD算法相对于KSVD算法,明显提高了计算效率,但由于近似使SVD分解结果产生了一定的误差,因而影响了分解效果。针对这一问题,Irofti等[11]提出了正则化近似KSVD(RAKSVD)算法,通过引入正则化参数对学习模型进行优化,建立岭估计模型,解决稀疏分解中的病态问题,从而使SVD分解结果的误差得到很大程度上的控制,提高了稀疏分解效果。 地震信号的稀疏分解是一个典型的病态问题,而正则化方法一直是解决病态问题的一种有效方法。正则化字典模型问题可转化为 (7) 式中,μ>0为正则化参数;第一项用来衡量样本的预测值和真实值之间的误差,第二项通过对参数加一个系数来调整其权值。 (8) 根据式(8),从KSVD算法的正则化[11]可以得出,正则化约束后的更新原子方法和原算法一致,而正则化参数是应用到稀疏系数的更新,使系数变为1/(1+μ)倍,通过给稀疏系数一个权值,每次通过这个权值影响后续的原子更新,最终完成字典的更新。所以RAKSVD的原子和稀疏系数更新为 (9) (10) 正则化参数μ对正则化效果有较大的影响,而在前人的研究文献中,μ一般取为常数,这样虽对模型进行了正则化处理,却得不到最优结果。因此正则化参数的自动优选是极其重要的。 为了求得L-corner的参数值,通常引入曲率,曲率最大时则对应此处的值,曲率表达式一般为 (11) 其中 式中,με为ε次迭代所对应的正则化参数变量;ε为迭代次数;δ为相应的曲率函数;η′、ρ′为一阶导数;η″、ρ″为二阶导数。 对于RAKSVD的正则化参数选取,理想的效果应为每次循环都会利用L曲线法求取μ值,但L曲线计算需要先对字典D进行奇异值分解,影响分解效率,所以需要进一步改进算法,将整个过程插入若干个控制节点,对于RAKSVD每一次更新字典时的正则化参数估算值经数值拟合得到: (12) 式中,u为分段优选正则化参数的控制节点序号;μu、Su为调节系数(μu、Su>0);μ1为通过L曲线求取的第一次迭代的μ值;S1为给定的初始值。 调节系数Su和μu通过梯度下降法求得,对应的损失函数为 (13) (14) (15) 设计弱信号的褶积模型(图1(a)),该模型共有3层,上层为强轴,中间层为倾斜层,由上到下逐渐变弱,并与上下两层斜交,下层为弱信号,共25道,每道300个采样点,其中雷克子波主频为25 Hz,模型中存在严重高斯白噪声(图1(b)),峰值信噪比为1.2 dB,用来进行字典训练。 图1 褶积噪音模型 本次实验硬件环境(i5-8250U, 1.6 GHz,8 GB)算法均在MATLAB2016a中实现,用RMSE代表均方根误差,其中字典大小为64×64,将地震体分成8×8的块,对加噪模型进行处理。迭代次数为30,为了求取准确,循环10次求平均值,图2是经优选得到的每次迭代所对应的正则化参数取值结果,其中μ为无量纲参数,图中5个圆点代表了根据L曲线优化得到的控制节点处的μ值,从第二个控制点开始对调节系数μu、Su进行修正,直到最大迭代次数结束。不同正则化参数所对应的均方根误差(RMSE)随迭代次数的变化关系如图3所示。 图2 正则化参数与迭代次数的关系 由图3可以看出,当训练字典在25次迭代后RMSE基本趋于稳定,分别对RAKSVD的正则化参数μ在0~0.3之间取固定值进行了测试:当μ为0时,训练误差最差,RMSE为1.440,随着μ增大,RMSE逐渐下降;当μ取0.2时,RMSE降为1.403,第一次迭代通过L曲线计算得到的μ为0.22。 但若μ取固定值0.22时,其分解效果并没有比0.2好,RMSE增大到1.405,且当μ为0.3时误差变得更大,说明整个迭代过程中较合适的μ在0.1~0.22,μ过大或过小分解效果都不好,当使用正则化参数计算公式(12)每次迭代更新μ进行字典训练时,就形成了正则化参数自动优选的RAKSVD方法(μ自动优选),可以避免μ取固定值不准确所带来的误差,从而实现了每次迭代自动选取μ值的目的,此时RMSE为1.344,达到了最优稀疏分解效果。 图3 不同正则化参数取值的误差对比 一般来讲,地震资料数据量较大,首先将其分割成若干个较小且大小相等的地震子块,在对实际地震资料去噪处理时,从整体稀疏分解问题上考虑,在式(7)中加入一个约束项,目标函数转变为如下优化问题: (16) 式中,λ为拉格朗日参数;N为重构信号;Y为输入信号,即含噪的地震剖面;D为需要更新的字典;i、j为分块矩阵的编号;Lij为选取Y的位置矩阵;Xij为相应的分块系数矩阵。 式(16)中第一部分是一个约束项,促使含噪信号与稀疏去噪后的信号能够尽可能地趋近;第二部分是正则化,目的在于解决模型稀疏分解的病态问题;第三部分确保每个地震子块经稀疏分解后都有很好的稀疏性。 实现步骤如下: (1)假设初始值。N=Y,D0设定为冗余DCT字典; (2)迭代循环。 a) 稀疏编码阶段通过正交匹配追踪(OMP)算法求取每个子块在字典下的稀疏分解系数,然后问题转化为 b)利用L曲线求出μ1,对该次迭代进行正则化字典与系数更新。 c)按照公式(12)更新正则化系数,更换字典D中原子,求出Xij。 d)达到最大迭代次数停止循环。 (3)去噪后地震数据的重构。 前面已经通过正则项更新了字典,求解了正则化参数,故可以固定正则项,使问题简化为 在已经更新完毕的学习字典下,应用稀疏算法对每个子块求解相应的表示系数Xij,利用公式进行地震数据重构,得到去噪后的结果。公式为 式中,I为单位矩阵。 图1(b)中存在较强的高斯白噪声,强轴虽能明显看到,但弱轴淹没在噪声中不易识别,图4为不同的正则化参数对去噪效果图。同时,将本方法与KSVD算法和AKSVD算法进行对比。表1为不同方法去噪效果和运行时间,RAKSVD方法指的是参数自动优选的RAKSVD方法。 从图4中可看到:对于低信噪比弱地震信号,当μ为0时(此时为AKSVD算法),去噪结果虽能保留弱信号,但去噪效果较差,残余很多毛刺,此时峰值信噪比为12.03 dB;如果RAKSVD算法中正则化参数取固定值,当μ取0.2时,去噪效果明显提高,此时峰值信噪比为12.76 dB;如果根据正则化参数自动优选取值时,随着每次迭代,其值是相应调整的,此时峰值信噪比为13.49 dB,能够达到最佳去噪效果,说明正则化参数自动优选的RAKSVD方法能提高弱信号的去噪效果和识别能力。 图4 RAKSVD算法不同正则化参数去噪结果 从表1可以看出:AKSVD相较KSVD,其计算时间缩减了67%,去噪效果有所下降;正则化参数自动优选的RAKSVD方法,其计算时间与AKSVD差不多,但去噪效果明显提升。在实际应用中,选用本文中提出的正则化参数自动优选的RAKSVD去噪方法,去噪后既能保证地震弱信号不发生畸变,达到较好的去噪效果,同时计算效率还可得到明显提升。 表1 不同方法的去噪效果和运行时间对比 为了进一步测试本文的去噪方法,将其应用于实际资料的去噪处理。图5为实际地震剖面,从图5中可以看出随机噪声对弱同相轴的影响较大,强轴之间的弱信号同相轴不清晰、不连续或错断。 图5 实际地震剖面 为了消除随机噪声的影响,分别采用KSVD、AKSVD以及不同正则化参数的RAKSVD方法对图5进行了去噪处理,图6为不同方法去噪后的地震剖面,表2为不同方法的去噪效果和运行时间,其中RAKSVD方法指的是参数自动优选的RAKSVD方法。 从图6可以看出,正则化参数的选取对去噪效果存在着重要影响,其中μ为0时去噪效果最差,峰值信噪比为10.658 dB;一旦加入正则项,去噪效果就会有所提升。如果正则化参数取固定值,当μ取0.1时,峰值信噪比为12.064 dB,能够取得较好的去噪效果;而当μ分别取0.3和0.01时,去噪效果不如μ取0.1,说明能够达到最佳去噪效果的正则化参数μ介于0.01~0.3,采用正则化参数自动优选的RAKSVD方法,可避免由于μ取固定值不准确对去噪效果的影响,每次迭代自动选取μ值,迭代结束后峰值信噪比提升到12.823 dB,达到了最佳去噪效果。 从表2可以看出,AKSVD方法相较KSVD方法,其计算效率得到了明显提升,但去噪效果下降明显,此时峰值信噪比为10.658 dB;RAKSVD方法在提升计算效率的同时,还提升了去噪效果。对比图6绿色方框中的强信号和青色方框中的弱信号的去噪结果可以看出,KSVD方法会产生过度去噪问题,对强轴的影响不是很大,但弱信号发生了明显的畸变,因此该方法对弱地震信号产生较大影响;AKSVD方法去噪后的峰值信噪比相比于KSVD方法有所降低,因此总体去噪效果不如KSVD方法,但能够保留弱信号特征,这是因为AKSVD使用了所有奇异值分量;正则化参数自动优选的RAKSVD去噪方法在达到最佳去噪效果的同时,能够使弱信号产生畸变的程度降到最低,从而有利于对弱信号的提取和识别。 图6 实际地震剖面去噪结果对比 表2 不同方法的去噪效果和运行时间对比 在对低信噪比地震弱信号进行去噪处理时,KSVD方法有其独特的优势,但含噪信号存在病态问题,对于弱信号容易产生去噪过度问题,且计算效率较差;AKSVD通过修改更新的原子和相关参数,极大地提高了计算效率,但其去噪效果有所下降;将正则化方法引入到AKSVD之后,其去噪效果有明显提升,但正则化参数的选取对去噪效果存在着重要影响,通过L曲线拟合自动优化选取正则化参数,能显著提高弱地震信号的去噪效果。在实际应用中可采用正则化参数自动优选的RAKSVD方法,不仅能使强反射信号达到较好的去噪效果,而且加强了对弱信号的保护,去噪后地震弱信号基本不发生畸变,从而较好地解决了传统去噪方法中弱信号保真度不高、容易发生畸变的问题,在地震弱信号的提取和识别中具有广阔的应用前景。





1.2 AKSVD算法


1.3 RAKSVD算法


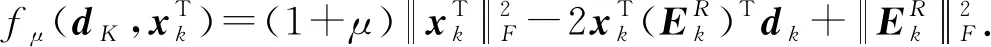

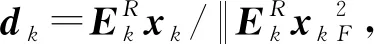

2 RAKSVD算法的正则化参数自动优选
2.1 方法原理

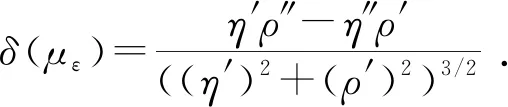






2.2 稀疏分解效果对比

3 正则化参数自动优选的RAKSVD去噪方法



4 弱信号模型测试


5 实际资料处理



6 结束语
