基于改进CenterNet的车辆识别方法
2021-08-09黄跃珍王乃洲梁添才赵清利
黄跃珍 王乃洲 梁添才 赵清利
(1.国防科技大学 计算机学院,湖南 长沙 410022;2.广州无线电集团有限公司,广东 广州 510663;3.深圳市信义科技有限公司,广东 深圳 518067;4.华南理工大学 电子与信息学院,广东 广州510640;5.华南理工大学 自动化科学与工程学院,广东 广州 510640)
随着城市化进程的不断推进,城市人口数量、城市机动车保有量迅速增加,为城市公共安全带来了极大的压力。为有效打击违法、违规行为,保障城市安全,城市重点路段、场所等建设有智能监控系统[1- 2],以实现对行人、机动车、非机动车等目标进行有效的监管。车辆识别成为智能监控系统的重要功能之一。车辆识别是对图像中的车辆目标检测其位置并识别目标的类型。在实际应用中,由于背景杂乱、光照条件、车辆变形、部分遮挡和运动模糊等因素,车辆类型的识别准确率不高。为提高准确率,国内外学者进行了大量研究。
传统的车辆识别方法主要通过图像的边缘特征、颜色特征、尺度不变特征变换(SIFT)和方向梯度直方图(HOG)特征等对车辆目标进行识别。Aarthi等[3]使用图像的颜色特征变换和Baye-sian分类器来标记车辆位置并进行分类识别。Matos等[4]通过图像边缘特征和主成分分析法对车辆图像进行分类。这两种方法计算时间短,能够快速提取图像的轮廓特征,但在车辆尺度变化大、部分遮挡、光照变化等情况下,其性能下降剧烈,不能对车辆进行正确识别。Iqbal等[5]结合Sobel特征和SIFT特征对车辆进行识别,但特征维度高,计算量大。Arróspide等[6]利用HOG提取车型特征,但计算成本高并且特征表达能力一般。针对传统方法检测识别性能较低的问题,深度学习逐渐成为车辆检测识别的主流算法。Yao等[7]对图像进行先验测量,得到车辆定位后,采用卷积神经网络(CNN)对车辆进行分类识别;Huo等[8]提出了基于区域的多任务CNN网络模型,用于识别车辆类型、朝向和光照条件。传统的CNN算法需要预设车辆位置,不利于实时的车辆识别。由于区域卷积神经网络(RCNN)[9- 11]系列算法在目标识别上取得重大突破,研究人员开始将这些算法应用到车辆检测识别中。Tang等[12]提出了超区域候选网络(HRPN),可以改善Faster-RCNN对小目标车辆的识别效果;Wang等[13]为解决车辆遮挡和变形问题,将对抗学习引入车辆检测识别,可生成困难样本(车辆严重遮挡和变形的样本),提高了Fast RCNN的识别效果;针对ROI池会破坏小目标的结构,Hu等[14]设计SINet,提高了对不同大小的车辆目标的识别效果和速度。RCNN系列算法属于两阶段方法,该类方法目标识别精度高,但速度慢,无法在边缘设备中实现目标实时识别。为提高车辆检测识别的速度,人们引入了一阶段方法。如文献[15- 16]将YOLO系列算法[17- 19]应用到车辆检测识别;Cao等[20]对SSD[21]网络进行改进,设计了级联模块和元素相加模块进行特征融合,提高了车辆识别精度,但检测速度有所下降。该类基于YOLO或SSD的算法需要预先设定一组特定宽高比的候选框,因而也称为基于候选框的算法。在基于候选框的算法中,候选框的设计很难兼顾到数量较少的极小或极大目标,因而在实际应用中,容易造成此类目标漏检。针对上述问题,基于不用候选框[22- 26]的一阶段目标识别方法成为当前的研究热点。如Yu等[27]结合HRNet[28]和CenterNet[24]对车辆进行检测识别。
针对现有不用候选框的目标检测算法在车辆识别应用中出现过多的负样本等不足,本文提出了基于改进CenterNet的车辆识别方法,并通过Vehicle车辆车型识别数据集、BDD100K数据集和Pascal VOC公开数据集验证该方法的有效性与优越性。
1 改进的CenterNet
实时性和准确性是车辆识别的关键因素。由于CenterNet网络是基于不用候选框的一阶段目标识别模型,推理速度较快,本文基于CenterNet网络,对其进行改进,以提高该网络在车辆识别中的准确性。
1.1 改进的CenterNet网络框架
如图1所示,改进的CenterNet网络主要包括主干网络、瓶颈模块和输出网络。在主干网络中,因ResNet18模型参数较少,故本文选用其作为基础网络。在瓶颈模块部分,本文提出了两种特征融合方式(单尺度自适应空间特征融合和逐层自适应特征融合)对网络的多级特征进行融合,以提高网络的识别性能。在输出网络部分,网络分别对识别物中心点预测其分类类别、边框长宽以及中心点的偏置,无需使用模型先验框,直接回归出预测物体的所有信息。

图1 改进的CenterNet网络的结构
1.2 基于特征融合的CenterNet网络
CenterNet网络使用的是采样率较小的主干模型,如DLA[29]和Hourglass[23]。该模型在使用主流的网络结构(如ResNet[30]、Inception[31]、MobileNet[32])时仅采用了多个可变形卷积和反卷积上采样的原始图像的1/4尺寸进行预测,并没有实现多级特征的重复利用。为此,本文提出使用单尺度自适应空间特征融合模块和逐层自适应特征融合模块分别融合多级特征,以提升模型的识别效果。
1.2.1 单尺度自适应空间特征融合
自适应空间特征融合(ASFF)是Liu等[33]在YOLOv3基础上提出的用于融合不同级别的特征。如图2所示,ASFF模块先将不同尺度大小的特征重采样到目标尺寸(上采样采用插值或者反卷积,下采样则是采用池化),然后分别在3个不同的目标尺度下对3个不同级别的输出特征图进行融合,得到3个特征图进行预测。
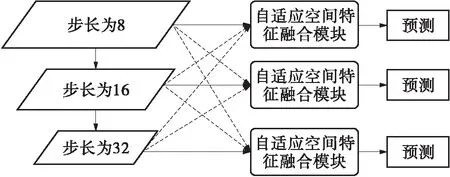
图2 ASFF模块的结构
由图1和图2可以看出,ASFF模块与CenterNet网络存在不匹配的问题,ASFF面向多尺度预测,而CenterNet网络为保留其可以不使用非极大值抑制[34](NMS)的特性,只能是单尺度的。因此,本文提出了单尺度自适应空间特征融合(SASFF)模块,用于对网络的多级特征进行融合,如图3所示。

图3 SASFF模块的结构
本文提出的单尺度自适应空间特征融合利用自适应特征融合(AFF)模块对网络的多级特征进行融合。区别于传统的特征进行直接上采样后相加[35]或者串级[19],AFF模块首先通过卷积和上采样,将不同级别下的特征调整成同样大小的特征,之后按照其空间位置赋予不同的权重进行融合,其表达式为
(1)

(2)

本文提出的SASFF模块不仅将网络的多级特征进行融合,同时让不同级别的特征的权重能自适应学习,有效地提高了识别效果。
1.2.2 自适应逐层特征融合
为进一步提升模型的实时性,本文进一步提出了逐层自适应特征融合(AHFF)模块。如图4所示,与SASFF一次性融合所有的输入特征不同,AHFF逐层地将不同尺度下的特征通过AFF模块进行融合。该模块的优点在于:逐层的特征融合能够允许特征由深层的抽象特征逐渐过渡到浅层的具象化特征;逐层的特征融合避免了SASFF在不同尺度下的重复上下采样造成的计算速度下降问题。
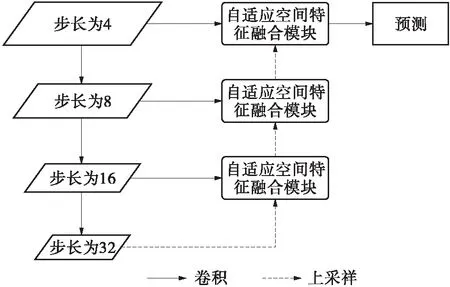
图4 AHFF模块结构
1.3 损失函数
基于关键点目标识别的损失可以分为热力图损失和边框回归损失。热力图损失用于对特征图进行密集预测目标类别,同时根据热力图的峰值获取对应的类别的中心点位置。边框回归损失则从中心位置预测目标的边框,因此边框的预测在很大程度上依赖于中心位置的准确性。
在边框回归损失中,原始CenterNet网络分别对预测框的宽高和偏移采用误差损失函数。原始CenterNet网络假设宽高与偏移是相互独立的优化问题,而实际上边框的优化是相互联系的。此外,目标边框的大小也会对损失造成影响,即在相同预测框与真实框的交并比(IoU)的情况下,大目标往往取得更大的损失,使优化倾向于大目标。
考虑到上述问题,本文边框回归损失采用带间距的交并比(DIoU) 损失[36],其表达式为
(3)
式中,d为预测框与真实框的中心之间的距离,c为预测框与真实框矩形闭包的对角线长度。IoU的表达式为
(4)
其中,B和Bgt分别为预测框和真实框。由式(3)与图5可以看出:IoU可以同时约束预测框位置与长宽的回归,并且对目标边框的大小不敏感;当预测框与真实框不重叠(即IoU为0)时,d2/c2则为损失函数提供了优化方向。
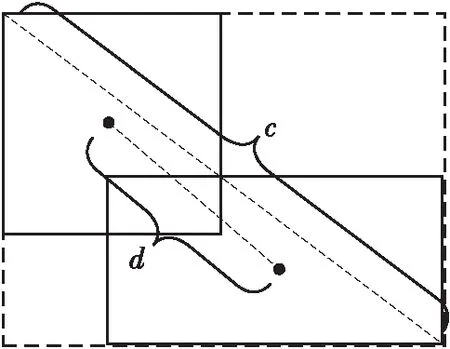
图5 预测框与真实框的DIoU损失
考虑到中心位置的重要性,文中采用中心损失[22]的变体公式作为热力图损失,其表达式为
(5)

(6)

该损失函数仅采用目标的中心点作为正类,而其他位置均设为负类,着重于中心点位置的优化。由式(5)可知,损失中的绝大部分均为负类,导致正负类采样极度不均衡。因此,在训练过程中只使用中心点半径以内的点作为训练样本,同时对负样本赋予不同的权重。模型在推理过程中可避免使用NMS。热力图损失的特殊设置使目标中心点以外的点只有较小的置信度,而且模型仅在一个尺度上预测,因此采用大小为3×3的最大池化层筛选出热力图的峰值,并以峰值作为识别目标的中心点。
因此,本文提出的改进CenterNet结合了热力图损失和边框回归损失,所采用的损失函数为
L=Lk+LDIoU
(7)
2 实验
2.1 数据集
实验中使用的数据集为Vehicle车辆车型识别数据集、自动驾驶BDD100K数据集[37]和目标检测Pascal VOC[38]数据集。Vehicle车型识别数据集来源于马路、岔口等地的摄像机采集的实际数据,部分数据如图6所示。Vehicle数据集共有10个类别的检测目标,包括前向巴士、前向轿车、前向小货车、前向面包车、前向货车、后向巴士、后向轿车、后向小货车、后向面包车和后向货车,其类别分别用1到10表示,如图7所示。在Vehicle数据集中,训练集数据为25 884幅图像,测试集数据为6 473幅图像。BDD100K数据集是一个大规模、多样化的驾驶视频数据集,包括10个检测类别,分别为人、公交车、骑行人、交通标志、交通灯、卡车、摩托车、火车、自行车和汽车,训练集数据为7万幅图像,验证集为1万幅图像。Pascal VOC数据集共分为20类,分别为飞机、自行车、小鸟、船只、水杯、公交车、汽车、猫、椅子、奶牛、餐桌、狗、马、摩托车、人、盆栽、绵羊、沙发、火车和电视,训练集数据为16 551幅图像,测试集为6 452 幅图像。在Vehicle数据集上采用的评价指标为平均精度均值(mAP)、预测框与真实框交并比为0.50时的平均精度(AP50)和预测框与真实框交并比为0.75时的平均精度(AP75),在BDD100K和Pascal VOC数据集上使用的评价指标为AP50。采用相同的网络模型对不同的数据集分别进行训练和测试。

图6 Vehicle数据集样例
2.2 网络参数设置
本文中模型训练与测试均在Ubuntu16.04环境下,使用的4张显卡型号为NVIDIA GTX 1080Ti,采用Python3.7和Pytorch1.2.0框架进行训练。网络训练参数如下:图像输入尺寸为512×512,初始学习率为5×10-4,总训练次数为140,在训练次数为90和120时,学习率分别下降为5×10-5和5×10-6,训练时的批量大小为64,优化算法采用Adam算法,β1为0.9,β2为0.999。在测试时,设置批量大小为1,不使用图像翻转和图像多尺度等技巧。

图7 Vehicle数据集各类别图例
2.3 实验结果与分析
在Vehicle数据集上不同模型的车型检测结果如表1所示,所有对比模型在训练阶段输入的图像尺寸均为512×512。从表中可知:当采用ResNet18-CenterNet模型时,在Vehicle数据集上车型识别的mAP为0.685;当采用SASFF模块时,其mAP较原始的CenterNet(ResNet18-CenterNet)模型提高了0.4个百分点,SASFF模块将网络不同尺度的特征图进行特征融合,故mAP略有提升;当采用DIoU损失替换原始的CenterNet模型的损失函数时,ResNet18-CenterNet-DIoU网络在车辆识别上的mAP为0.694,较ResNet18-CenterNet模型提高了0.9个百分点,证明DIoU 损失能有效改善车型识别的效果;当同时结合DIoU损失和特征融合方法时,使用SASFF和AHFF特征融合模块的网络在Vehicle数据集的mAP分别为0.701和0.704,分别提升了1.6和1.9个百分点。对于基于候选框的模型YOLOv4和YOLOv5,其mAP分别为0.706和0.711,略高于本文提出的模型精度,表明本文提出的模型在车辆检测识别中的效果接近于YOLOv4和YOLOv5模型,且本文模型的大小均低于这两个模型的大小。相较于YOLOv4-tiny和EfficientDet-D0,本文模型能提取更多的特征,在准确率上有明显的优势。
对模型进行推理时,本文采用TensorRT6 FP32模式。在推理显存上,原始ResNet18-CenterNet模型以及ResNet18-CenterNet-DIoU模型的推理显存为561MB,这表明使用DIoU损失能保持推理显存。当使用特征融合的方法时,SASFF-CenterNet-DIoU和AHFF-CenterNet-DIoU模型的推理显存分别为633和563 MB,表明SASFF-CenterNet-DIoU的计算量明显提高,而AHFF-CenterNet-DIoU所占用的内存仅提升2 MB,计算资源消耗少。本文模型的推理显存均低于YOLOv4和YOLOv5模型。

表1 不同模型在Vehicle数据集上的检测结果
由表1还可以知道:原始ResNet18-CenterNet模型以及ResNet18-CenterNet-DIoU模型的推理时间均为5.51 ms,这表明使用DIoU 损失能在保持推理显存和推理速度的同时提高了识别精度;当使用特征融合的方法时,模型的识别精度有明显的提高,但在推理速度方面有所下降,SASFF-CenterNet-DIoU和AHFF-CenterNet-DIoU的推理时间分别为9.18和6.69 ms;本文模型的推理时间均低于YOLOv4和YOLOv5模型,EfficientDet-D0的推理时间为12.32 ms,实时车辆检测识别的速度较慢;YOLOv4-tiny的推理速度最快,但在识别准确率上有所欠缺;本文模型不仅在车辆检测识别上有较高的准确率,同时推理速度快,具有良好的车辆实时识别性能。
在Vehicle数据集上各模型的训练损失对比如图8所示。可以看到:随着训练次数的提高,ResNet18-CenterNet和ResNet18-CenterNet-DIoU模型的训练损失随之下降,ResNet18-CenterNet-DIoU模型的训练损失下降的速度快于ResNet18-CenterNet模型,且在模型稳定时,ResNet18-CenterNet-DIoU模型的训练损失低于ResNet18-CenterNet模型;当使用特征融合SASFF和AHFF时,在模型平稳时,使用特征融合SASFF和AHFF模块的模型的训练损失均为最小,在进行推理时的mAP也相对较高。

图8 4个模型的训练损失
图9展示了SASFF-CenterNet-DIoU和AHFF-CenterNet模型的车辆检测效果。可以看到,实测的车辆图像均能达到预期的检测效果。
采用本文改进的方法在BDD100K自动驾驶数据集和VOC数据集进行实验,结果如表2所示。在BDD100K数据集中,原始ResNet18-CenterNet模型的AP50为0.384,加入DIoU 损失后,模型的AP50提高了0.1个百分点。使用了特征融合模块SASFF、AHFF后,模型的AP50均为0.436,比原始ResNet18-CenterNet模型提高了5.2个百分点。在Pascal VOC数据集上,加入DIoU损失和AHFF模块后,AHFF-CenterNet-DIoU模型的AP50为0.742,较ResNet18-CenterNet模型提升了2.5个百分点。这表明,同时采用本文提出的特征融合方式和DIoU损失方式,能有效地提高目标检测的效果。在BDD100K和VOC数据集上,YOLOv4和YOLOv5的检测准确率均高于本文模型,原因在于:本文模型主要解决马路、岔口等场景下的车辆识别问题,这些车辆大部分为大目标,而在BDD100K和VOC数据集上存在很多小目标,本文模型不能较好地检测识别小目标;本文模型采用ResNet18作为主干网络,相对于CSPNet网络深度不够,检测出来的目标不够充分。由于YOLOv4-tiny和EfficientDet-D0模型的深度较浅,不能提取更多的特征,故其目标检测准确率相对较低。在推理时间上,各模型在Vehicle、BDD100K和VOC数据集上的结果基本一致,本文模型在保持较高的识别精度下推理速度也相对较快。

(a)SASFF-CenterNet-DIoU模型

(b)AHFF-CenterNet-DIoU模型

表2 不同模型在不同数据集上的检测结果
3 结论
为提高车辆识别的精度,本文提出了基于改进的CenterNet的车辆识别方法。首先,针对CenterNet仅使用网络的最后一层特征,没有对网络输出的多级特征重复利用的问题,本文提出了使用单尺度自适应空间特征融合的方法来改进CenterNet,以实现对网络的多级特征进行融合,有效地提高车辆识别的精度。由于单尺度自适应空间特征融合方式在增加模型大小的同时降低了推理速度,本文提出了逐层自适应特征融合的方法,有效地改善了模型大小和推理时间,同时提高了车辆检测识别精度。在损失函数上,本文丢弃CenterNet预测框的长宽损失和偏移损失,使用DIoU损失和热力图损失为模型的损失函数,可以提高模型的收敛速度和识别精度。在BDD100K和Pascal VOC数据集上的检测结果表明,本文提出的改进CenterNet能明显提升车辆的识别精度。今后将尝试从其他方面对车辆识别进行研究,以寻求更大的突破。
