基于改进YOLOv3的自然交通路况检测研究
2021-08-06吴新淼赵一洲程廷豪
吴新淼,赵一洲,程廷豪
(四川大学电子信息学院,成都610065)
0 引言
目标检测是计算机视觉研究领域中的一个重要的研究分支[1],它是目标跟踪和行为识别的基础实现环节。随着无人驾驶这一概念火爆的提出,车辆的目标检测就成为了当前的热点研究话题,其目标是通过车载摄像头将录取到的实时路况的视频信息进行分帧拆分成一幅幅图片,然后通过目标检测算法,对图片进行分析,从不同复杂程度的背景中返回车辆交通分析中所需要的目标的空间位置和物体类别,从而针对不同的交通情况进行自动紧急刹车或者转弯。
近几年,深度学习逐渐走入我们的视野中,当前的目标检测模型大多是基于two-stage和one-stage分类的。其中基于two-stage的算法模型有R-CNN[2]、SPP-Net[3]、Fast R-CNN[4]和Faster R-CNN[5],这些算法都是需要先生成候选区域,然后在候选区域里面进行特征的提取,然后将特征图送入分类器中进行类别的判定和边框回归。而基于one-stage的算法模型有YOLOv3[6]和SSD[7],这些算法通过回归,解决了目标框定位问题,输入图片进网络中直接输出图片中物体的类别跟位置。相对于two-stage的目标检测方法,one-stage的方法具有检测速度更快的优势,但是其检测精度却没有two-stage好,但是YOLOv3算法很好地平衡了检测速度跟精度的问题,可以满足交通路况的实时检测。故本文选择YOLOv3作为目标检测算法对交通路况进行研究。
1 YOLOv3介绍
1.1 网络训练流程
YOLOv3算法是将输入的图片经过一定比例的宽高缩放之后,将其输入到特征提取网络DarkNet53进行卷积,经过卷积后将得到的特征图尺度划分为大小一致的网格,每个网格设置3个瞄点框,每个瞄点框用来预测一个边界框。YOLOv3的网络预测过程如图1所示。

图1 YOLOv3框架图
在进行特征提取的过程中受到FPN[8]的思想启发,低层特征图的分辨率高,有利于提取小的目标,高层特征图的语义信息丰富,有利于提取大目标,通过融合这些不同层的特征图可以达到在满足大目标检测的同时兼顾小目标的检测。在YOLOv3中设置了13×13、26×26、52×52这三个层次的特征进行目标的检测,其中13×13负责检测大尺寸目标,26×26和52×52负责检测中、小尺度目标,并且将其中的13×13和26×26的特征图分别进行一次上采样跟前期同尺度的特征图进行融合,将融合的结果来进行预测。
如果经过特征提取后的图片中的某一物体的中心在网格中,那么这个网格就负责预测这个物体,则该网格中的三个瞄点框都会输出三类参数。第一类参数为坐标参数,其中tx,ty,tw,th代表预测框中心坐标跟宽高,第二类参数为预测框的置信度c,第三类参数为物体的类别概率数组p。其中为了方便计算过程中的网络的收敛,本文需要对坐标参数进行一个变换,变换公式如图2所示。

图2 预测框示意图
其中pw和ph为本文通过K-means[9]算法得出的瞄点框的宽和高,cx和cy为网络负责预测物体的网格的左上点在整张图中的坐标,其中sigmoid函数的作用是将原先输出的预测框的中心坐标进行一个非线性归一化变换,将中心坐标偏移压缩到[0,1]之间,可以确保将要检查的物体中心处于执行预测的网络单元格中间,防止出现物体中心偏移出要检测的网络单元格。其中的bx,by,bw,bh为最终预测的框中心坐标和宽高。而置信度c则是当前输出的预测框中有物体的概率pr(object)和该预测框框跟真实框的交并比(IOU)的乘积。其具体公式如下:
(1)
其中cij表示的时第i个网格的第j个预测框的置信度,置信度是用来在训练过程中挑选出我们需要训练的最优box。最后将图片中某一物体的所有预测框进行NMS[10](非极大值抑制),就是获取属于某一类别的所有预测框的概率p,然后获取其中概率最大的框,计算剩下的框跟概率最大的框的IOU,然后将IOU大与我们设定的阈值的框给删掉,在剩下的框中重复进行上面的操作,最后就可以得到一个最符合当前目标的预测框。
1.2 DarkNet-53
YOLOv3中间的特征提取网络为5组重复使用的残差卷积单元,每个卷积单元里面为一个1×1和3×3的卷积层,每个卷积后面都会跟一个BN层和一个LeakyReLU层,其中1×1的卷积层通过固定输出的通道数可以降低参数的数量,3×3的卷积核可以满足卷积单元的输出跟输入维度一致,通过交替使用这样的残差卷积单元可以在保证有效提取特征的前提下减少训练的参数,达到减少训练时间和计算量的目的。在交替使用残差卷积单元的时候就是采用ResNet[11]思想,采用跳层的方法,将残差卷积单元的输入层跟输出层进行相加,这样一来就可以解决网络层度太深导致的梯度爆炸跟梯度消失问题。其中DarkNet-53的网络结构图如图3所示。
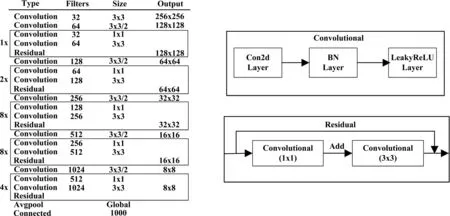
图3 DarkNet-53网络结构
2 改进型YOLOv3介绍
2.1 加入高斯模型
传统的YOLOv3中每个预测框都会输出三类参数,分别为目标的坐标信息、目标是否存在的置信度和目标属于某个特定类别的置信度。其中坐标信息tx,ty,tw,th代表预测框的坐标值,就是用预测出的框的位置来逼近真实框,其中目标是否存在跟目标是否属于某个类别都是用概率来表示的,概率值跟1的逼近程度代表着YOLOv3进行预测的可靠性大小,越靠近1,代表我们的预测值越可靠。但是我们输出的坐标值就是单纯的数字信息,并不是概率值,不能预测当前框的可靠性,受到高斯函数的钟形启发,本文用高斯模型对输出的坐标信息进行建模。其中高斯模型为:
(2)
其中μ代表着函数分布的均值,σ2代表着方差,函数在μ处取得最高值,但是当μ相同的时候σ2越大,均值处的取值就会越低。将这个思想融入到预测框的坐标中去,将输出的预测框的坐标数字代表高斯模型中的均值,将坐标的方差值来估计坐标信息的可靠性,这样一来可以在确定定位精度的前提下通过降低方差值来提升预测坐标值的可靠性,随之而来的就是由传统的YOLOv3的坐标输出值将会由4个变为8个,其具体代表式如下:
(3)


图4 融合高斯模型参数示意图
在对输出框的坐标值进行修改之后,本文也需要对原先的坐标损失函数进行修改,在预测框的坐标都满足均值为μ方差为σ2的高斯分布之后,本文摒弃了传统的均方误差[12]的(MSE)作为坐标定位损失函数,而是使用了负对数似然损失(Negative Log Likelihood Loss)[13]作为重建的定位损失函数。其具体定义如下:
(4)
(5)
(6)

2.2 D-IOU边界回归损失函数
目标检测中最后输出的是一个带有边框的物体检测图形,而物体边框的形成是需要在训练中不断的对边框损失函数进行一个收敛,这个过程也就是边框回归过程。YOLOv3中是采用预测框跟真实框的交并比IOU(Intersection Over Union)作为边框定位损失函数,其中IOU定义如下:
(7)
Dis(box,centroid)=1-IOU(box,centroid)
(8)
其中boxpred是目标的预测框,boxtruth是目标的真实框,IOU是真实框跟预测框面积之间的交并比。但是当采用IOU作为度量和损失的定义会存在一些问题,例如当预测框跟真实框的IOU为0的时候,这个时候定位损失函数就不会进行收敛,无法对预测框的偏移进行优化。针对于两框不相交的情况,本文将预测框跟真实框之间的中心距离也添加到进去,采用了一种新的定位损失函数D-IOU,如公式(10):
(9)
其中c为同时覆盖预测框和目标框的最小矩形的对象线距离,d=ρ2(b,bgt)代表了预测框跟真实框的中心的欧氏距离。如图5所示。

图5 DIOU示意图
采用D-IOU[14]可以有效解决当预测跟真实框不相交时出现的损失函数不能收敛的情况,并且在一开始收敛的时候直接将预测框跟真实框之间的中心距离考虑进去,从而可以更快更有效更稳定地收敛。
3 实验结果与分析
3.1 数据集介绍
在BDD100K数据集中,包含10万张道路目标边界框图片(训练集7万、测试集2万、验证集1万),大小为1280×720 ,数据库涵盖了不同的天气条件,包括晴天、阴天和雨天,以及白天和晚上的不同时段,图片的注释信息中包含了:类别标签、大小(起始坐标、结束坐标、宽度和高度)、遮挡和交通灯等信息。数据集中的真实目标框共有10个类别,总共约有184万个定位框。分别为:Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider。
3.2 实验环境及参数介绍

表1 实验环境配置表
在进行实验的时候,本文batch设置为64,subdivision为32,decay为权重衰减正则项,为了防止在训练过程中出现过拟合,故在每次训练完之后将学习到的参数进行0.5的比例降低。learning_rate为学习率,代表着权重的更新速度,在进行梯度下降的过程中,该值就决定着梯度下降的步伐,如果设置太大了,就有可能会直接越过最优解,如果设置太小了,就会导致下降的速度很慢,也就是我们收敛的时间会很长。本文中实验设置总共跑10000个epoch,刚开始训练的时候我们的学习率可以设置大一些为0.001,等实验进行到8000和9000个epoch的时候学习率设置为以前的1/10。
其中本文实验的评价指标为AP和mAP,在计算AP的时候需要先计算精准率P和召回率R,其中他们的定义如下:
(10)
(11)
Tp为真正例,即预测为正样本实际为正样本。Fp为假正例,预测为负实际为正。FN为假负例,预测为负实际为正。则P为预测为正实际为正占预测为正的比例,可以视作是模型找出来的数据正确的能力。R是预测为正实际为正占总体样本的比例,可以视作是模型在数据集中检测出目标类型数据的能力,通常情况下用P-R曲线来显示目标网络在精准率和召回率之间的平衡,对于数据集中的每一个物体类别的平均准确率AP就是该类别的P-R曲线下方的面积,而mAP就是指所有类的平均准确率的均值。其中AP和mAP的计算公式如下所示:

(12)
(13)
3.3 实验结果对比分析
由于不同的数据集里面物体的分布跟形状不一样,本文使用了K-means算法重新计算锚点框的尺寸,合适的瞄点框的大小可以有效地加快边框的回归,更新的预定义锚点框的值分别如表2所示。
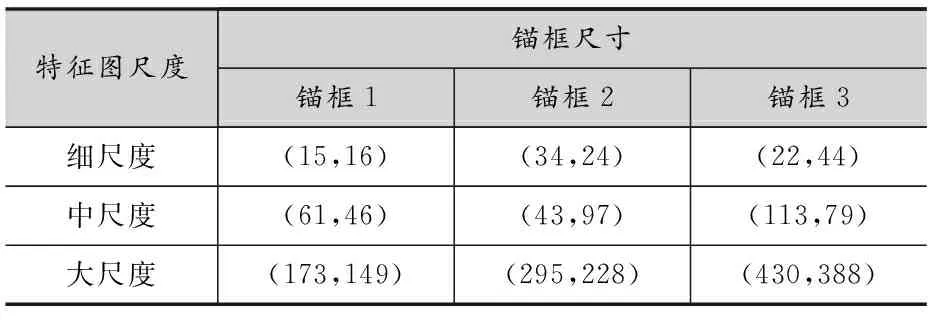
表2 锚点框分配表
共9个预测锚点框,因为有三个不同尺寸的特征图,所以每个中心点可预测三个不同尺度的预测框。对比于YOLOv3原始设计的先验锚框尺寸与本文通过K-means得到的尺寸进行比较如下图所示:

图6 新旧锚点框尺寸比较
将YOLOv3、Gaussian-YOLOv3、DIOU-YOLOv3、Gaussian-DIOU-YOLOv3算法分别应用新的锚点框之后在BDD100k数据集上进行训练跟测试,其中最后的实验结果如表3。

表3 实验结果对比表
可以看出在融合了D-IOU和高斯模型之后,GD-YOLOv3相对与原始的YOLOv3,mAP提升了4.42%,虽然FPS由69降低为63,但是还是能够满足实时检测的需求。
由图7的(a)、(b)对比可以看出,引入D-IOU后目标图片中检测到的物体相对与原始的YOLOv3变多了,但是存在一些错误的物体识别,例如将交通灯识别为交通标识。对比(a)、(c)可以看出,加入预测框的不确定性之后,就能够正确地检测到交通灯了,但是却漏检了一些物体,最后从(d)可以发现融合了高斯模型跟D-IOU之后,模型能够有效地检测出小的交通灯,并且可以检测出一些原本检测不出来的车跟行人。从表4可以看出,改进后的算法模型相对与原始的模型,FP值有很大幅度的降低,这表明模型误检的概率在降低,并且TP的提升证明模型可以对更多的正样本进行检测。

图7 实验结果对比图
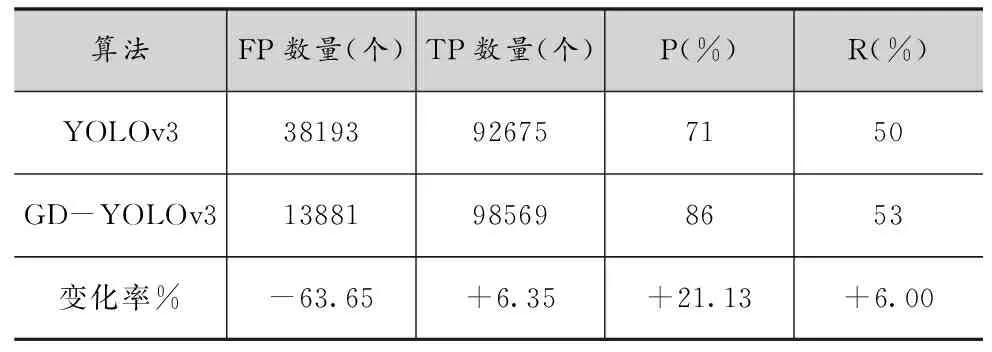
表4 模型数值评价表
4 结语
本文在针对复杂路况情况下传统的YOLOv3算法检测交通物体预测框定位的精度不足问题,提出了一种改进型YOLOv3模型,首先通过K-means算法计算出适应于BDD100k的先验锚框,接着在YOLOv3的预测层加入对预测框的不确定性回归并且重新改进了新的损失函数,然后将改进后的算法添加新的锚点框进行训练,实验结果表明引入预测框的不确定性回归后,训练出来的模型可以有效降低对物体的定位误差,新定位损失函数引入预测框跟真实框之间的中心距离,在加快预测框跟真实框之间的收敛的同时也解决了当二者交并比为0情况下不收敛的问题。经过对比可以发现改进后的算法可以检测出原始算法检测不到的物体,并且框的定位更加的准确,适合复杂场景下的自然交通路况检测。
由于本文的改进方法都是针对于预测框的定位精度提升,而没有对交通物体类别检测精度的改进。后续的研究中,本文将从如何提升物体类别的精度出发,从主干网络入手,在提升网络的特征提取能力的前提之下减少网络的参数量,进一步提升模型的检测能力。
