基于深度学习的威胁情报信息抽取研究
2021-08-06孙天放
孙天放
(四川大学网络空间安全学院,成都610065)
0 引言
近年来,网络攻击在数量和复杂度上都呈现了迅速增长的趋势。信息系统越来越多地暴露于各种安全威胁之下,这些威胁需要网络安全从业人员的持续关注,为了更有效地促进安全信息共享,2013年,Gartner提出了威胁情报(Threat Intelligence,TI)的概念[1],“威胁情报是基于证据的知识,包括场景、机制、指标、含义和可操作的建议,这些知识是关于现存的、或者即将出现的、针对资产的威胁或危险,可为主体响应相关威胁或危险提供决策信息。”由此可知,威胁情报包含了关于当前或即将到来的网络安全威胁的各种详细信息,这可以帮助企业或组织实施针对网络安全威胁的主动网络防御。目前,只有少数安全公司提供标准化结构化的威胁情报,安全人员和机构很难获取大量的威胁信息,CleanMX[2]和PhishTanks[3]等社区虽然在其平台上发布了充足的威胁情报,但仅包含恶意URL、IP等少量威胁信息,无法应用于网络安全态势感知系统或其他防御机制。从开源的互联网文章或报告中有效抽取威胁情报信息,并将其转换为标准化、结构化的形式,对网络安全研究有着非常重要的意义与实际应用价值。威胁情报信息抽取的两个主要任务是命名实体识别(Named Entity Recognition,NER)和关系抽取(Relationship Extraction,RE)。命名实体识别是许多任务的基础方法,广泛应用于信息抽取、语义分析、信息检索、知识图谱等多个领域。实体包含通用性实体,如地名、人名,也可以是针对特定领域的专业性实体,如漏洞、攻击技巧、恶意软件等网络安全领域的实体名称。目前,主流的网络分析工具都依赖于特征工程识别实体,专业性实体需要针对性的特征进行识别,图1是一段网络威胁情报描述,其中标注了威胁情报领域的一些实体。而关系抽取的目的是从非结构化的文本中抽取相关实体的关系,并将这些关系表示为具有“主语,谓语,宾语”的固定形式的三元组。例如,在图1的威胁情报描述中,可以提取三元组(APT40,make_use_of,AIRBREAK),和相应的关系类型(Group,MakeUseOf,Software)。

图1 威胁情报中的实体及其关系示例
过去的研究表明,现有的模型无法很好地抽取与网络安全相关的实体及其关系[4]。虽然传统的基于统计的信息抽取方法在通用领域可以取得较好的效果,但是该方法严重依赖特征工程,给在网络安全领域的应用带来了一些局限性。首先,该方法很大程度上依赖于该领域人员的经验,并且需要漫长的试错与训练过程;其次,特征工程的维护与更新需要耗费大量的人力物力,特别是在网络安全这种高活跃度的领域。近年来,神经网络得到了广泛应用,这种模型可以自主学习非线性的特征组合,以避免进行耗时费力的特征工程。其中,递归神经网络(Recurrent Neural Network,RNN)在自然语言处理(Natural Language Processing,NLP)领域取得了良好的效果[5]。而在实践中,长短时记忆神经网络(Long Short-Term Memory neural network,LSTM)作为RNN的变体,已经成为使用深度学习方法进行文本处理的重要手段,该模型解决了RNN的长期依赖性学习的问题。
本文的主要贡献是评估了LSTM模型在威胁情报领域中进行信息抽取任务的能力,并提出了基于神经网络模型的威胁情报信息抽取方法(Threat Intelligence Information Extraction based on deep learning,TIIE)。在命名实体识别任务中,比较了基于LSTM的模型和基于特征工程的条件随机场(Conditional Random Fields,CRF)模型在威胁情报领域的表现,在关系抽取任务中,比较了基于最短依赖路径(Shortest Dependency Path,SDP)的LSTM模型和基于序列和树结构的LSTM模型的表现。
1 相关研究工作
在网络安全领域,提取威胁情报实体及其关系的方法多种多样。Joshi等人[6]提出了从异构数据源中识别实体和相关概念的方法,使用最大熵模型(Maximum Entropy Model,MEM),并在标记好的语料库中训练该模型,训练语料库经过复杂的人工标注,包含约5万个标签,其模型实现的准确率为0.799,F1得分为0.75。为了自动构建训练语料库,Bridges等人[7]利用国家漏洞数据库中的数据结构设计了自动标注文本的算法,用更灵活的特征工程构建工具,创建了一个包含大约750000个标注标签的语料库,并使用感知机算法,该算法已经被证明比最大似然估计方法效果更好。与Joshi等人的工作相比,Bridges等人的训练语料库更大,其实现的准确率为0.963,F1得分为0.965。但是,他们的语料库不像Joshi等人的语料库那么多样化,这在一定程度上也影响了实验结果。Mulwad等人[8]使用了一种支持向量机(Support Vector Machine,SVM)分类器将威胁情报信息与不相关的内容进行区分,分类器使用计算机安全分类法来标注网络安全领域的实体,使用平均精度作为模型性能的衡量标准,最终达到了0.8的平均准确率。Jones等人[9]提出了一个基于bootstrapping算法的识别方法,只需要很少的输入数据,包括很少的关系样本及其类型,就可以从文本中提取安全实体及其之间的关系,该模型在其语料库上的测试精度为0.82。
在最近的研究中,神经网络开始逐渐替代传统统计机器学习方法,深度学习解决了传统机器学习方法的许多缺点[10]。一方面,基于神经网络模型的方法可以自动学习特征,这大大减少了网络安全领域中的人工成本和时间成本。此外,在各个领域的研究结果都表明,神经网络学习的特征在准确性方面优于人工生成的特征。另一方面,RNN已经被证明具有较长的记忆能力,可以处理可变长度的输入,这给自然语言处理任务的效果带来了极大改善。LSTM则进一步提高了RNN的性能,并支持在任意远程依赖之间进行学习,通过适当的大语料库注释,可以为传统机器学习方法提供一个可行的替代方案。
2 威胁情报信息抽取方法
威胁情报信息抽取包括命名实体识别和关系抽取两个子任务,本文提出的TIIE方法以LSTM神经网络模型为基础,包含了基于LSTM-CRF模型的命名实体识别方法和基于LSTM-SDP的关系抽取方法。一方面,本文将Lample等人[11]提出的深度学习模型应用于威胁情报命名实体识别领域。该方法是LSTM、CRF和词嵌入方法的组合,该方法实验用的语料库带有网络安全领域的命名实体标注,数据集中每一个单词都带有实体类别标签。对于关系抽取任务,本文根据威胁情报文本特点,优化了Yan Xu等人[12]提出的基于最短依赖路径的LSTM模型,这种神经结构利用了一个句子中两个实体之间的最短依赖路径,保留了关系分类所需的相关信息,并消除了句子中不重要的单词。
2.1 长短时记忆神经网络模型
LSTM是一种经典的递归神经网络模型,它能够检测和学习输入数据序列中的模式,其中,数据序列可以是时间序列、自然语言文本,也可以是语音、基因组等。递归神经网络可以将当前输入(例如,文本中的当前单词)与上一个输入(例如,文本中的前一个单词)中学到的知识结合起来,然而RNN虽然在短序列中表现良好,但当处理的序列变得过长时,它会遇到梯度下降甚至消失的问题,当模型参数数量变多时,训练RNN的难度显著提高。
LSTM模型则可以解决长期依赖学习的问题,它引入了内存单元的概念,如图2所示,它在内存中随时间保持长期依赖状态。LSTM结构单元由一个Sigmoid神经网络层和一个点阵乘法运算组成,LSTM单元内的门(gate)选择性地让信息通过。其中,i代表输入门,f代表忘记门,o代表输出门,σ代表Sigmoid神经网络层,W和b分别代表权重和Sigmoid层的常数,C代表神经细胞状态。LSTM单元的运算过程如下:

图2 LSTM神经网络单元结构图
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(wo[ht-1,xt]+bo)
(5)
ht=ot·tanh(Ct)
(6)
2.2 基于LSTM-CRF的命名实体识别方法
本节主要介绍了基于LSTM-CRF模型的命名实体识别方法,该方法的体系结构如图3所示。

图3 长短时记忆-条件随机场模型结构图
该方法包括三层结构。第一层是底部的输入层,输入单词序列w1,w2,… ,wt,word2vec神经网络会将每个单词转换为对应的向量xt,得到的词向量序列x1,x2,… ,xn则被送入下一层,即双向LSTM层。双向LSTM层对输入的向量进行训练,并将输出传递给最后一层,即CRF算法层。在CRF算法层产生神经网络的最终输出,预测单词对应的概率最高的实体类别标签。
该方法的双向LSTM层由两部分组成,正向LSTM从序列起点开始读取输入并向后移动,反向LSTM从序列的末尾开始读取输入并向前移动。正向LSTM基于当前词语t计算其左侧的文本信息lht,反向LSTM基于当前词语t计算其右侧的文本信息rht,最后,结合左右两侧的文本信息得到输出结果,即ht=[lht;rht]。多项研究表明,双向LSTM结构在命名实体识别任务中被证实有效。
2.3 基于LSTM-SDP的关系抽取方法
基于最短依赖路径的长短时记忆神经网络模型的体系结构如图4所示。首先,使用Stanford解析器对句子进行解析,并生成依赖树。其次,抽取最短依赖路径作为神经网络模型的输入。除了最短依赖路径信息以外,四种其他类型的信息也被向量化后传入模型,包括命名实体、实体关系、POS标签和WordNet上位词。

图4 长短时记忆-最短依赖路径模型结构图
两个实体的共同节点将最短依赖路径分离为左子路径和右子路径。这两条子路径分别由两个RNN进行处理。在每个RNN中,LSTM单元用于信息传递,从这两个子路径传递的信息被传入最大池化层,如图4b。池化层连接后会传最上方的隐藏层,最后输出结果,如图4a。
3 实验验证
本文对所提出方法的有效性进行实验验证。本实验所使用的数据集为SCU-iGroup整理的Attack-Technique-Dataset数据集[13],其中包含55篇网络安全事件相关的报告。在命名实体识别任务中,训练LSTM-CRF模型来识别威胁情报领域最常见的7个实体标签,如表1所示,然后在相同的语料库中训练广泛应用的CRFSuite模型[14]。本文将语料库分成两个子集,80%作为训练集,20%作为测试集,以比较两种模型的性能。同时,在关系抽取任务中,训练两个LSTM模型来抽取威胁情报领域的特定关系,如表2所示。同样将语料库分为80%的训练集和20%的测试集,并分别比较LSTM-SDP和Miwa等人[15]提出的LSTM-STS两种模型的抽取效果。

表1 威胁情报数据集实体数据统计
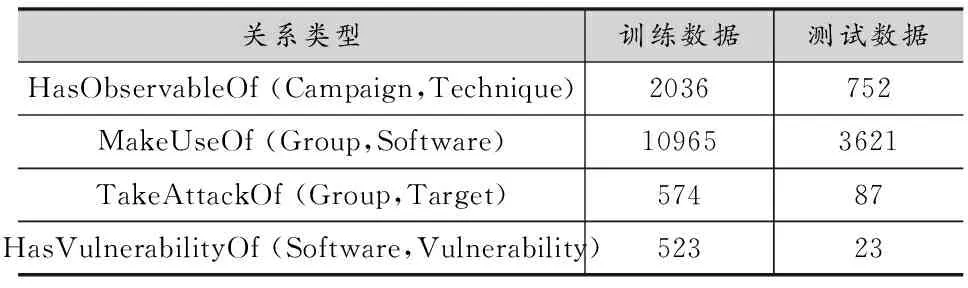
表2 威胁情报数据集关系数据统计
本实验的评估指标为准确率P、召回率R和调和平均数F1,评价指标计算方法如下:
(7)
(8)
(9)
其中,TP表示标注为阳性的样本中正确的数量,FP表示标注为阴性的样本中错误的数量,FN表示标注为阳性的样本中错误的数量。实验从语料库中留出的20%的测试数据来评估方法的有效性,将各个模型的结果按照上述评价指标进行比较,以评价每个模型的性能。
3.1 命名实体识别对比效果
我们对提出的LSTM-CRF方法和应用特征工程的CRF方法进行了评估。从SCU-iGroup整理的Attack-Technique-Dataset威胁情报数据集中选择7个最常见的网络安全实体标签进行分组,分析两种模型对于同一威胁情报数据集网络安全领域的相对性能,标注的实体类型包括Vulnerability、Technique、Software、Group、Campaign、Target和Motivation。两个模型在命名实体识别任务中的表现性能结果如表3所示。

表3 LSTM-CRF与CRF对比结果
从结果可知,根据准确率、召回率和F-1值各方面的性能指标来看,LSTM-CRF方法的结果要优于基于特征工程的CRF方法。每种方法对各个网络安全命名实体标签的识别结果如表4所示。

表4 LSTM-CRF与CRF对7种实体类型的抽取对比结果
3.2 关系抽取对比效果
本文对LSTM-SDP和LSTM-STS两种模型的关系抽取效果进行对比,对比结果如表5所示。

表5 LSTM-SDP和LSTM-STS对比结果
从结果可知,基于最短依赖路径的LSTM模型在准确率,召回率和F-1值各方面表现都优于基于序列和树结构的LSTM模型。
4 结语
本文提出了基于神经网络的威胁情报信息抽取方法,并通过实验验证了所提出方法的实现效果。实验结果表明,与传统的基于统计的方法相比,TIIE在命名实体识别和关系抽取领域的效果都有了显著提高。传统方法需要进行大量的特征工程,耗时费力,且训练得到的模型只针对特定领域,难以在其他领域复用,而基于深度学习的方法减少了对特征工程的需求,预处理和训练成本更低,具有一定的应用价值。在将来的研究工作中,可以继续研究语料库自动标注算法,并提高神经网络模型精度,实现威胁情报信息的自动化抽取方法,供网络安全从业人员使用。
