基于震源聚类方法确定川滇交界东部地区微震的空间分布特征
2021-07-14石永祥蒋一然宁杰远李春来
石永祥,蒋一然,宁杰远,2*,李春来
(1.北京大学地球与空间科学学院,北京 100871;2.河北红山地球物理国家野外科学观测研究站,河北 邢台 050040;3.中国地震局地球物理研究所,北京 100081)
0 引言
近年来,以机器学习与人工智能为基础的地震自动拾取技术发展很快,可以从连续波形记录中检测到大量微震,具有了形成较为完备微震目录的能力[1-4]。理论上,大部分的微震应该分布在断层面上,通过观察微震的分布就可以获得该地区的断层空间结构。但是,微震目录具有微震数目庞大、信号质量参差不齐的特点。同时,一个地区各种断层结构产生的微震在空间上会混杂在一起,难以通过人工分割开属于不同断层的微震序列。
机器学习方法在处理这类大数据的问题上具有天然优势,可以在一定程度上规避掉一些噪声的影响,提高分选效率。由于获得的微震目录是无标签样本,不能采取SVM、CNN 等目前流行的监督类机器学习方法,只能采用非监督学习方法。作为典型的非监督方法,基于空间距离的K-Means 聚类方法可以自动分离不同空间位置的地震,因而被用于研究地震的空间分布,并划分地震活动带[5-6]。
真实的微震序列大都发生在断层面上。因而,同一个断层产生的微震序列是面状分布,而不是球形分布。此时,K-Means 方法无法有效地分开同一地区不同断层产生的地震序列。非断层区域的地震密度一般较低,不同断层产生的微震之间会存在低密度区。当微震定位足够精确时,可以通过微震低密度区来分割不同断层,从而刻画出这个地区的断层空间分布。
本文使用一种基于密度聚类的方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)进行微震的聚类分析。在初始的微震目录中,由于台站密度有差异,不同区域的平均微震密度差别很大,难以通过一个标准来分离出不同断层的微震序列。因此,对微震目录进行初次聚类,首先获得较小范围内微震分布。之后,对分离后的小区域内的微震再次聚类,从而获得该区域微震的精细分布。为了更加精确地区分不同断层产生的地震,在再次聚类时尝试在聚类中加入波形的相关信息。在二次聚类之后,得到的微震分布会更加符合当地的断层分布,能够从一些类中发现可能的断层结构。
1 DBSCAN 聚类方法
DBSCAN 方法[7-8]是一种经典的密度聚类方法。该方法使用2 个控制参量来决定这个属性:半径ϵ和最小样本数目MinPts。;1 所示。DBSCAN 会对样本中的每一个样本进行遍历,当一个样本半径ϵ内存在MinPts个样本点时,这个样本点被认为处于稠密区域,满足稠密条件。这个点与半径ϵ内所有的点组成一个样本点集合S,之后在这个集合S 内寻找所有同样满足稠密条件的样本点,并将它们的集合包含在S 内并不断循环,直到S“边缘”的所有样本点都无法满足稠密条件,从而认为S 中的所有点组成同一个类。这种聚类方法不需要迭代,所需要的运算时间与运算量都较小,能够满足对数万样本点的快速聚类需求。

表1 DBSCAN 方法流程伪代码
DBSCAN 方法中没有K-Means 中的中心点的概念,只需要度量任意两点之间的距离即可。此处在初次使用震源位置信息聚类时,使用的距离度量只包含了位置信息:
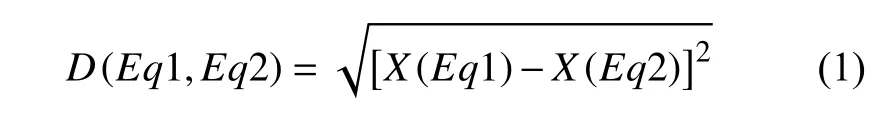
其中:Eq1 与Eq2 代表不同的地震;X为定位得到的震源位置,单位为km。在二次聚类时,距离度量加入了不同事件在同一台站的波形的信息:
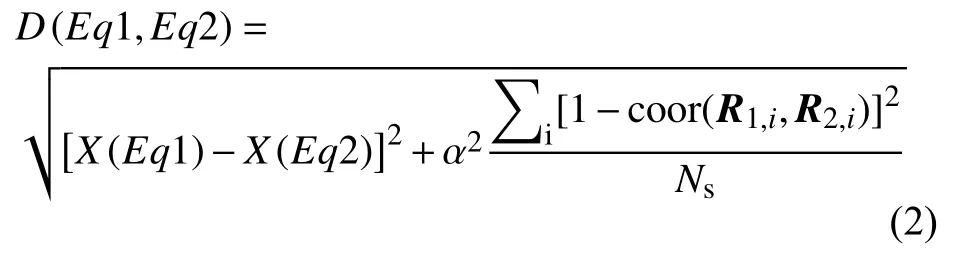
式中:R1,i为i号台站对事件1的记录;R2,i是i号台站对事件2 的记录;coor(R1,i,R2,i)是2个记录之间的点乘,也即零移互相关函数,取值归一化到[0,1],用于计算2 个记录之间的差别;NS是台站数目;这里的 α权重在不同小区域会有所变化,以适应不同区域地震与台站密度的差异。
2 聚类结果与分析
本文所用微震目录是利用APP 方法[4]、从川滇地震台网连续数据中获取到P 波与S 波的到时之后,使用IASP91 地球模型对地震位置进行定位得到的结果[9]。本文选用这个目录中60 000 个地震记录进行分析,先使用地震的三维位置信息进行粗略的聚类,之后再对几个大类加入波形信息后进行更加细致的分析。
2.1 使用位置信息的初次聚类
在第一次聚类中,DBSCAN 方法的2 个控制参量被设置为半径ϵ=10 km和MinPts=20,生成了震事件,微震分布与当地的断层走向有一定关系。88 个类(包括一个包含9 778 个事件的“噪点”类),结果如图1 所示。在图1 中,不同的类使用不同的颜色标注,K=-1 对应黑色的点为噪点,彩色的是有效类,并按照数目排序。聚类的结果中包含最多地震的类是在(26.5°N,102.8°E)附近(图1 粉色椭圆内),包含了23 575 个地震。这是因为这个区域加入了一个密集台阵的数据,所以记录到的微震较多。在图2a 中展示了这一类的微震分布,同时在图2b 与图2c 中展示了AA′与BB′两个切线上微震的深度分布,范围为线两侧10 km。第二类(图1 绿色椭圆)对应在龙门山断层(32°N,104°E)附近NESW 走向的微震序列,包含了8 856 个地震,与该地区主要的断层走向相符(图3)。第三类在(28°N,101.3°E)附近(图1 浅蓝色椭圆),包含了2 231 个地
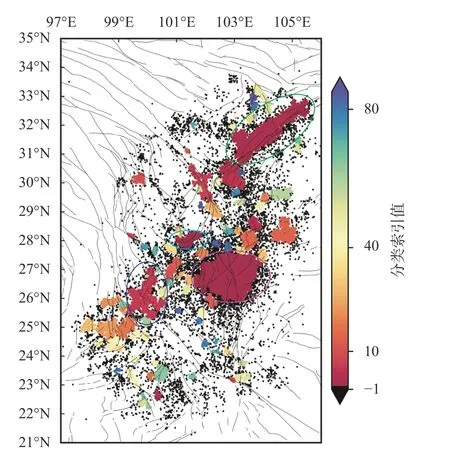
图1 利用位置信息进行初次聚类分析的结果
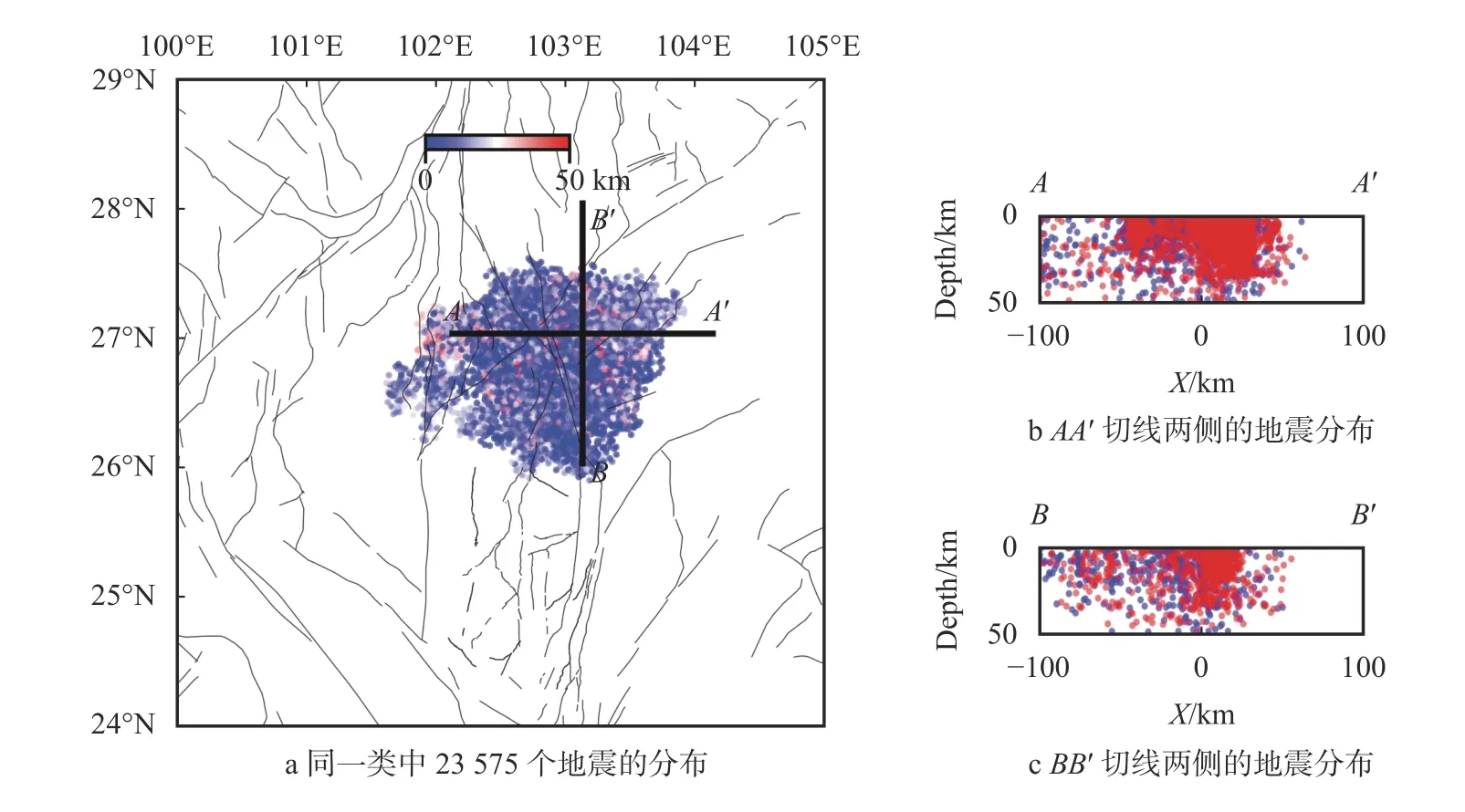
图2 初次聚类分析后微震最多的类
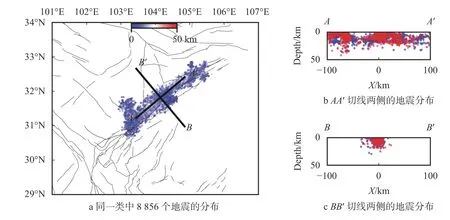
图3 初次聚类分析后龙门山附近一类
图1 结果中分离了9 778 个噪点类微震,分布见图4。噪点类几乎均匀分布在所有的地区,没有明显规律可循。噪点类的成因较多,可能与微震目录中的误识别或者定位过程中由于信号较弱导致的偏差有关。噪点类可以使用更低的稠密性条件进行进一步的聚类,从中抽取出更多的信息,但是总体利用价值不是很大。而对于图1 中的第一类和第二类,由于区域较广,同时地震密度大,无法从这次聚类的结果中直接观察到断层的信息,需要进一步聚类分析。类似地,对于(26.3°N,100°E)附近的一系列类(图1 深蓝色椭圆内),可以采用同样的二次聚类方法从中抽取出更加精确的微震聚类信息,从而反映出更精细的断层位置。本文将以第一类与第二类的二次聚类结果为例进行研究。
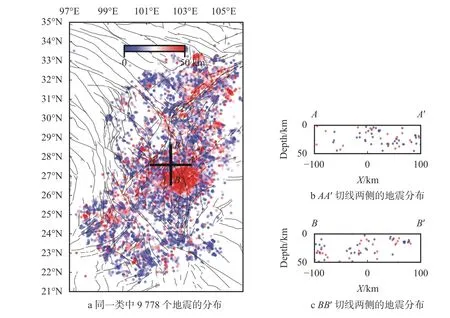
图4 初次聚类分析后噪点类
2.2 包含P 波和S 波互相关信息的二次聚类
在二次聚类分析中,先考虑对初次聚类中数目最大、微震最为密集的第一类(图2)进行分析。为了增强不同地震事件的区分度,除了考虑对应的位置信息外,还加入了不同事件之间波形的互相关信息。由于是微震,密集台阵中只有少数台站可以记录到,而不同台站记录的不同事件的波形,有差异较大的方位角与距离,无法比较,故加入限制条件。只有当2 个事件相距10 km 以内,且有相同台站记录到这2 个事件的时候,才将互相关的信息加入到2 个事件的“距离”度量上,这样就可以最大限度地避免台站与事件之间的距离与方位角因素的影响。用公式表示为:
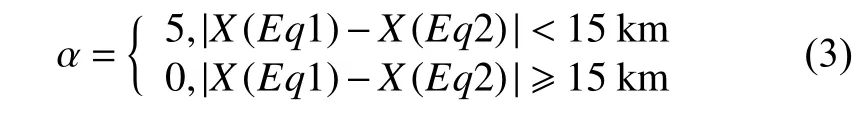
由于这一类包含的地震事件太多,所以没有使用地震记录的全波形做互相关,而是只使用P 波和S 波前后2 s 的记录做零移互相关,以节省运算时间,提高运算效率。互相关函数选择所有同时记录到这2 个事件的台站,在相同台站上对不同事件的P 波与S 波做互相关,之后叠加所有台站互相关值,从而更好地衡量波形之间的相似度。
考虑到这次研究的区域变小,地震数目也下降,故选择聚类参数半径ϵ=5 km 和MinPts=10,结果如图5 所示。DBSCAN 方法一共生成了55 个类,其中黑色点是噪点类。聚类结果的第一类(图5绿色椭圆)包含了13 236 个地震(图6)。从图6 可以发现,第一类在南端有很清晰的沿断层走向的微震分布,并在(26.3°N,103°E)处发生了转弯。这与当地的构造联系密切,预示着这个区域可能存在一个不在本文采用的断层数据集内的断层。在图5 中粉色椭圆对应的一类中,也可以看到一个类似的地震事件分布,展示了较为清晰的倾角与走向(图7)。
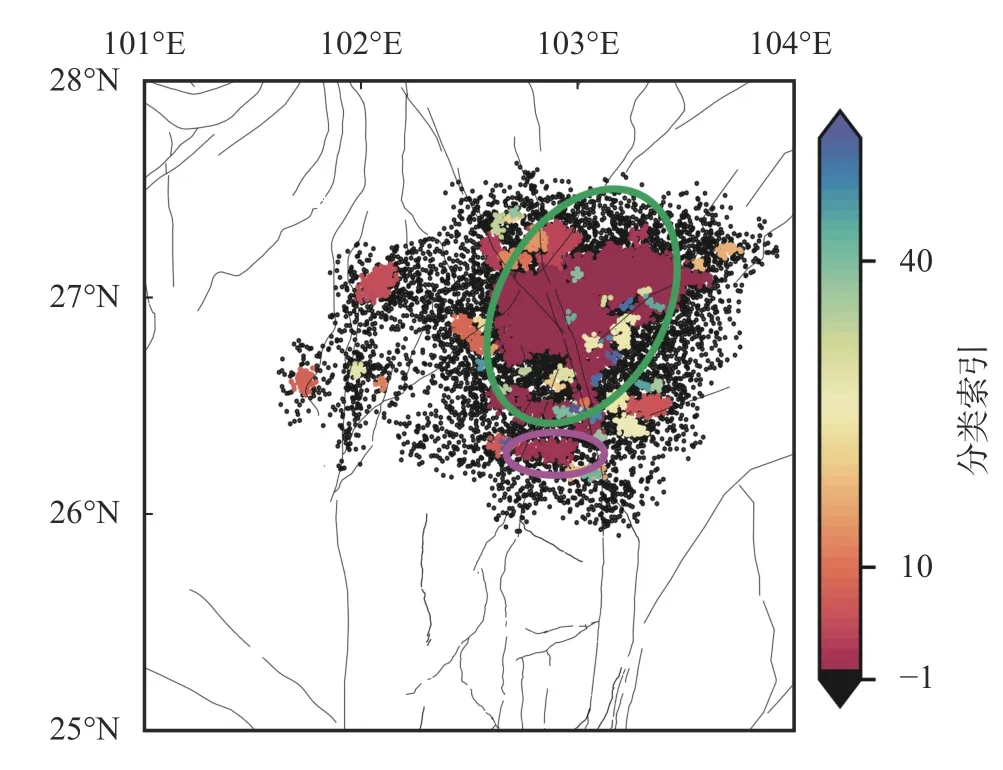
图5 加入P 波和S 波互相关信息后二次聚类的结果
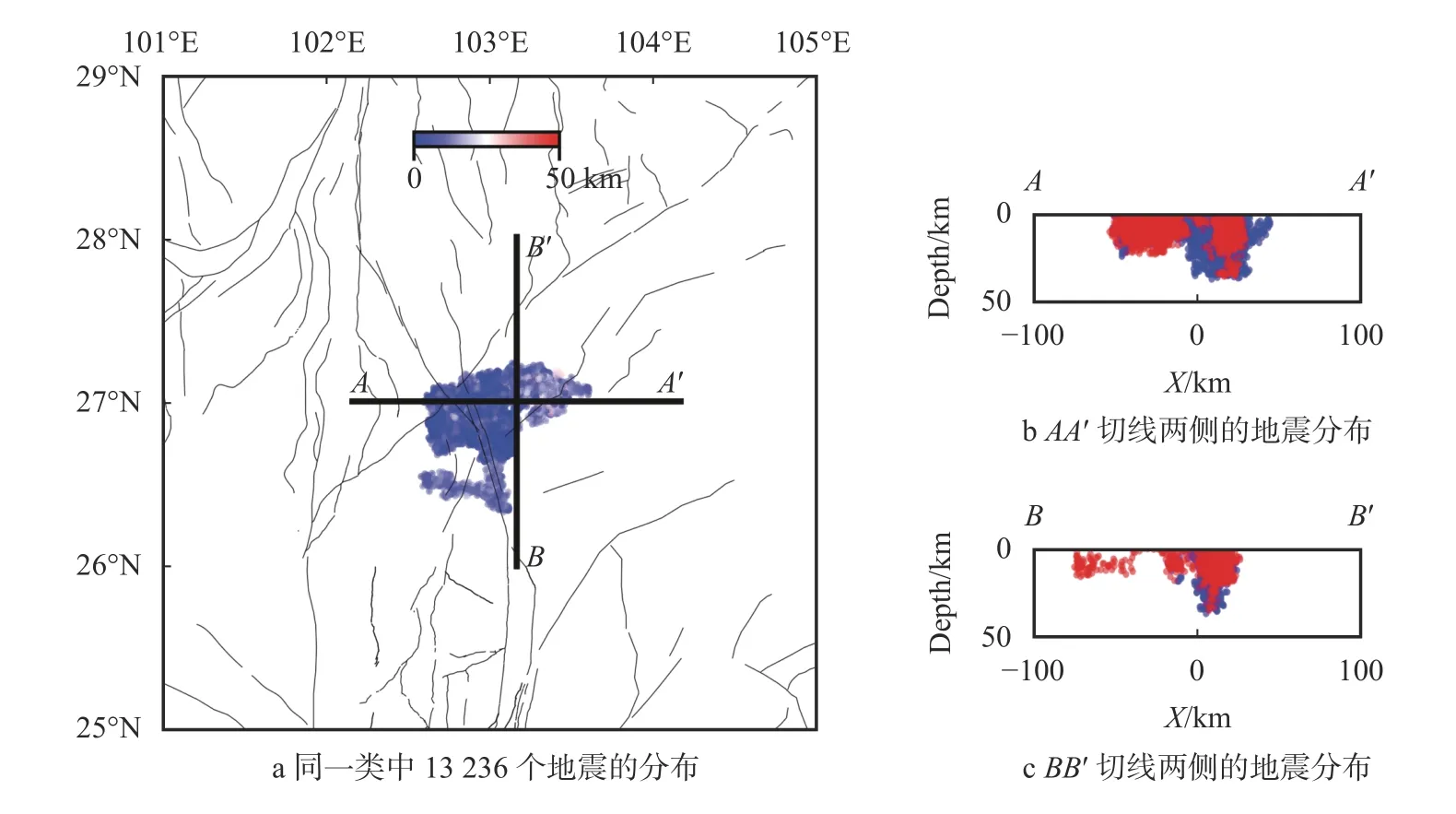
图6 二次聚类(图5)中绿色椭圆对应的类
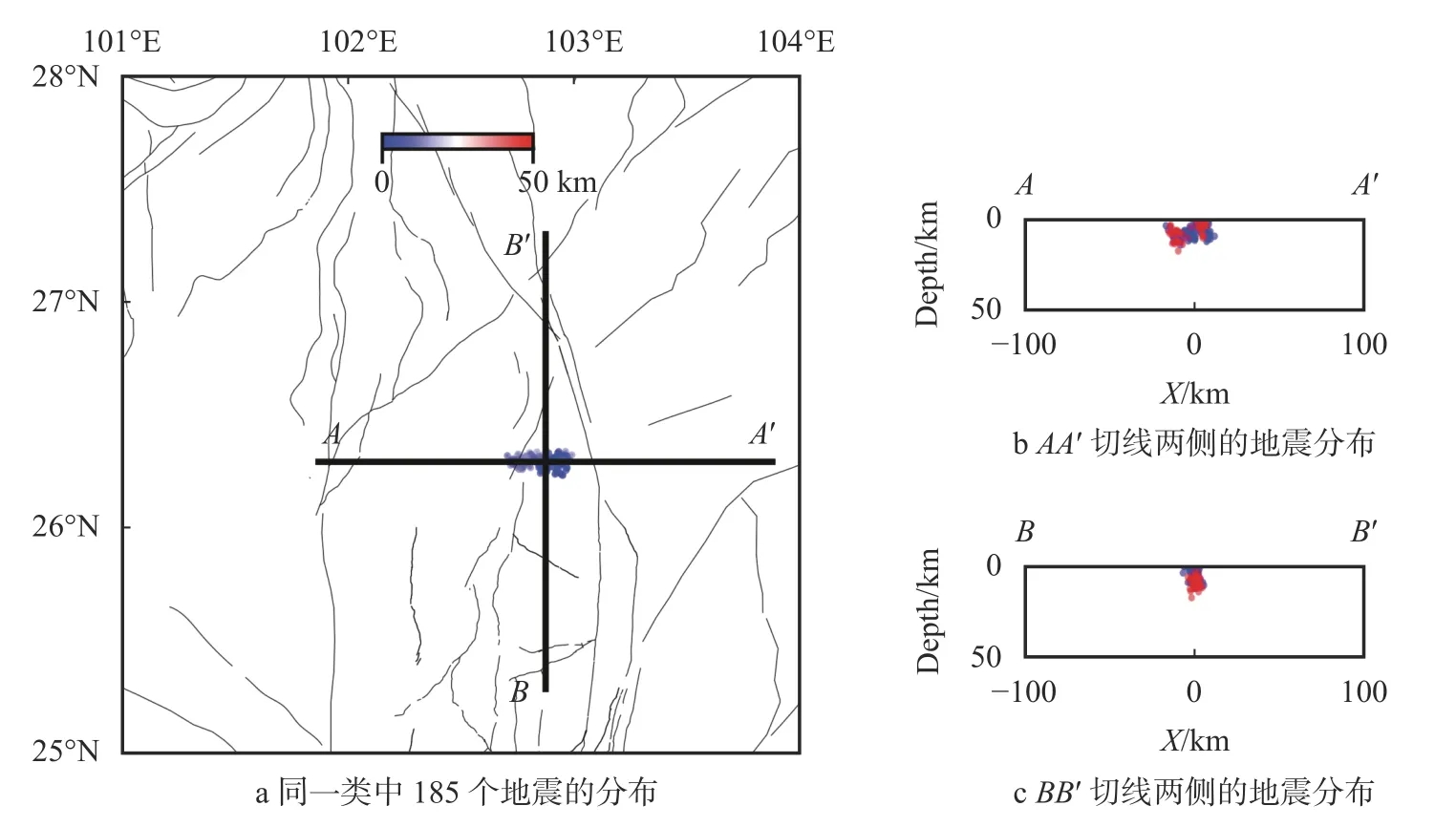
图7 二次聚类(图5)中的粉色椭圆对应的类
从本次分析可以发现,二次聚类的结果相对于没有聚类的结果,明显带有了更多的断层信息,因而仍需对数目较多的类进行第三次聚类,进一步分析断层信息。
2.3 包含全波形互相关信息的二次聚类
对图1 中在龙门山附近区域的第二类(图4)进行二次聚类分析。与图3 中的第一类不同,这个类只包含8 856 个地震,互相关所需要的运算量较少。因而采用P 波到达前10 s 到S 波后10 s 的波形进行零移互相关,之后将互相关值加入到事件之间的距离度量上,设定
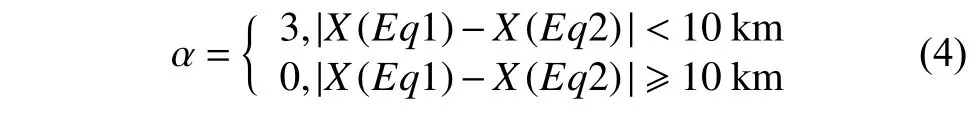
聚类参数设置为ϵ=5 km和MinPts=10,DBSCAN 对龙门山地震序列附近再次聚类的结果,生成了18 个地震类(图8)。其中数目最多的第一类(图9)包含4 947 个地震。与第一次聚类得到的结果(图4)相比,此时微震沿断层分布的特征更加清晰。第一类的分布对应着龙门山断裂的一段,南端的NW 向翘起则对应此处的NW 向分支断层。
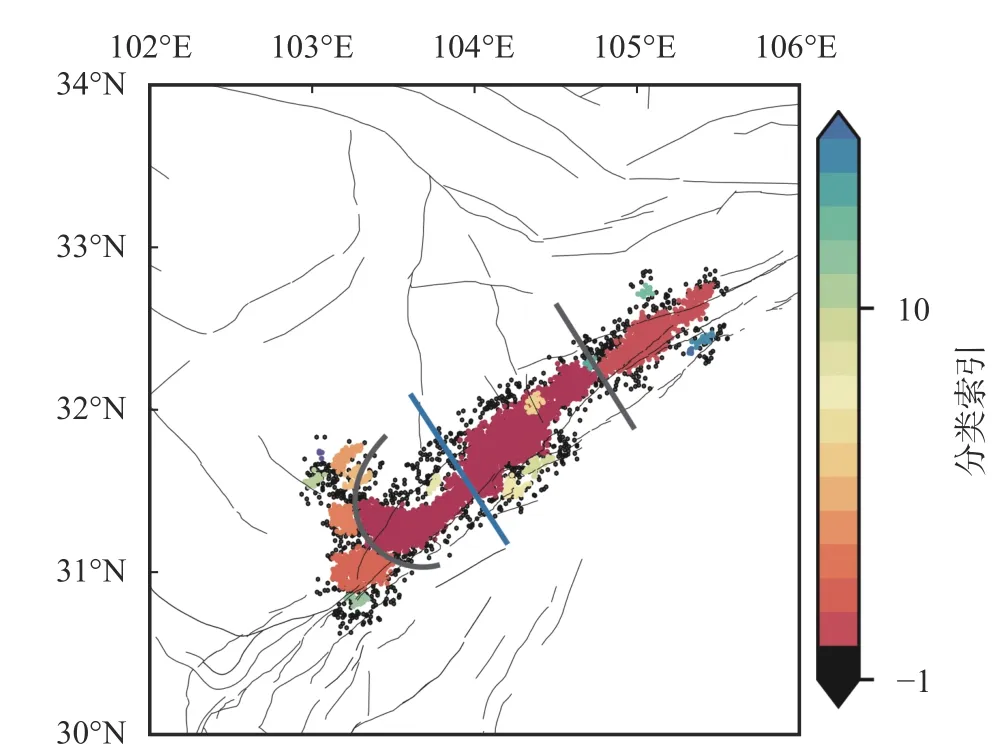
图8 龙门山断层附近一类二次聚类的结果
进一步分析聚类结果。从图9 事件的深度以及在经度与纬度上限的分布中可以看到,在(31.6°N,103.8°E)附近地震震源深度大多大于10 km,浅层地震很少,而两端存在着大量的浅源地震,形成了明显的地震空区。这种分布特征与“5·12”汶川地震余震的空区分布十分相似[10],两端大量的浅源地震主要与龙门山断裂在两端发展出的大量不同走向的分支断层有关(如该类南端的NW 向分支)。而中间分支断层较少,地震主要发生在龙门山主断裂上,震源的位置较深,形成了这个地震空区。同时,图8 分类结果中龙门山断裂的北端(104.8°E 以东)被划分成了单独的一类,这可能是因为北端处于断裂带的末端,发震结构、活动性与主断裂不相同,因而被分离出。整个分段结果与Tian et al.[11]的研究结果形成了很好的对应关系,从地震空间分布特征的角度验证了Tian et al.关于震源机制解分区分布的结果。尤其是清晰地从地震空间分布的角度验证了关于存在两种逆断层地震及其空间分布的结果,并从地震空间分布的角度表明了第二类逆断层地震的活动范围,证实了Tian et al.关于现存断层释放应力场不同分量的结论。
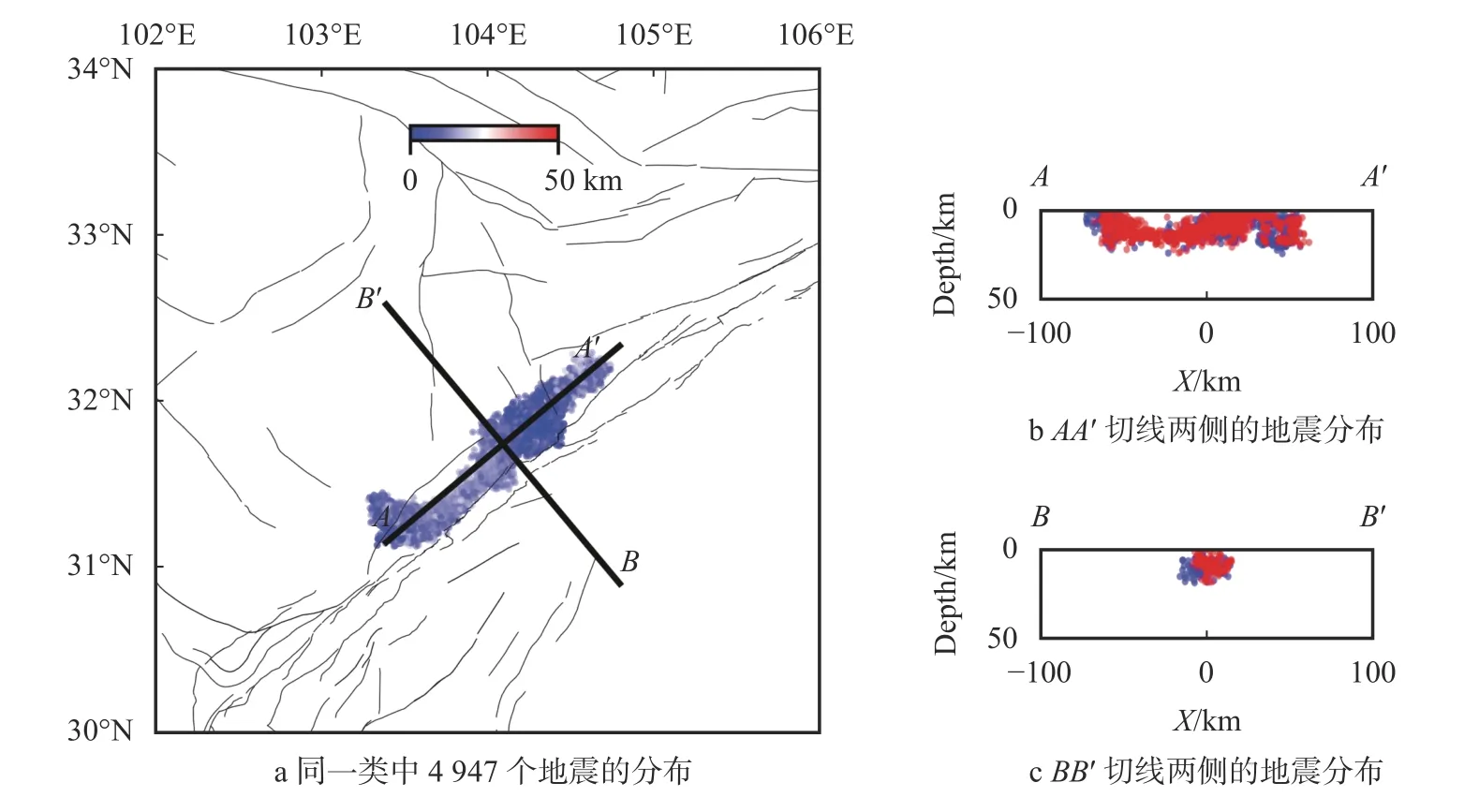
图9 龙门山断层附近二次聚类后的第一类
在聚类结果中,还在断裂带的南端分离出了一些其他的类,反映了当地复杂的断层分支的存在。原可以进一步分离出其中多个断层,但是受限于定位的精度与地震数目,进一步的聚类存在困难。
3 结论
通过使用基于密度的聚类方法分析了自动拾取技术获得的川滇地区微震目录,并进一步地利用空间位置信息分离出了不同地震活动带内的微震序列。对于使用APP 方法定位出的60 000 个地震,先使用位置信息进行初步聚类,之后再对数目较多的类调整聚类参数后进行二次聚类;二次聚类中同时加入波形互相关信息,以加强不同断层类之间地震事件的区分度。一次聚类的结果大概展示了该地区微震分布的区域性,但是受到台站密度等多方面的影响,并不能给出相对清晰的断层结构。对一次聚类结果进行二次聚类,则更好地展示出了地震序列沿断层的分布,并给出了一些断层所对应的地震序列。
同时,二次聚类后依然存在一些包含大量微震的类可以进一步分离。但是想要获得更可靠的结果,需要扫描更长时间的连续记录,获得更多的微震序列。并且,也可以使用Tomo-DD 等反演方法得到精确的地下结构对地震进行定位,从而获取更加精确的地震分布信息,提高聚类方法结果的精确度与可靠程度。
初步结果表明,基于密度的聚类方法具有推广价值。
致谢中国地震局地震预测研究所为本研究提供地震波形数据;研究工作得到北京大学高性能计算校级公共平台支持;感谢参与讨论并给出建议的温景充、鲍铁钊、伍晗与殷常阳同学。
