基于深度学习和台阵策略的震相自动拾取方法APP++及其在川滇地区的应用
2021-07-14蒋一然宁杰远李春来
蒋一然,宁杰远,2*,李春来
(1.北京大学地球与空间科学学院,北京 100871;2.河北红山地球物理国家野外科学观测研究站,河北 邢台 054000;3.中国地震局地球物理研究所,北京 100081)
0 引言
近年来,深度学习方法在地震学领域的广泛应用,如地震检测与震相拾取[1-4]、信号的插值与降噪[5-6]、地下结构反演[7]等方面取得了很好的结果。特别是在地震检测与震相拾取方面,基于深度学习的方法已经能够达到甚至超过人工拾取的精度,而且在一致性、效率等方面有显著优势。在图像识别领域发展起来的U-net[8]深度学习网络是目前深度学习震相拾取方法效果最好的网络结构之一[1,3-4],其收缩路径允许网络提取更多、更复杂的特征,提高分类的准确率,带直连的扩展路径则有助于网络对检测目标进行更精确的定位。同时U-net 网络模型具有良好的泛化能力,使得在一个区域训练得到的震相拾取模型在另一个区域也可以获得较好的效果[4],极大地降低了该方法的迁移成本。U-net++[9]是在U-net 基础上发展起来的网络结构,包括了多重收缩和扩展路径,使得网络具有更高的连接密度,能够更好地学习不同尺度的特征,以对不同尺度的对象进行检测。本文在刘芳等[4]设计的PP 模型基础上,使用U-net++改进原有网络结构,提出了APP++震相拾取模型,达到了更好的单台地震体波震相检测水平。
尽管使用单台波形检测的准确率已经达到很高水平,但由于局部噪声的影响,会产生很多误识别结果。将高精度的单台检测和台阵策略相结合,则可以有效地降低误识别的比例[4,10],使得自动拾取算法应用在实际数据中具有实用性。刘芳等[4]将蒋一然等[10]提出的台阵策略与深度学习震相拾取模型结合,提出了APP 方法。本文进一步将PP++单台震相拾取方法与台阵策略结合起来,并提出了适用于台阵数据的地震检测与震相拾取方法APP++。
最后,将APP++方法运用到川滇地区的固定台网和流动台阵中,检测了该区域2014—2019 年间的地震并拾取了其体波到时。拾取结果显示,在川滇地区地震空间分布和断层有明显的相关性。
1 APP++震相拾取方法
1.1 PP++深度学习震相的拾取模型
U-net++[9]是在U-net 基础上发展起来的一种密接神经网络模型,在相同深度的情况下,U-net++具有更高的连接密度,能够提取更多尺度的特征,在部分图像识别任务上表现出更强的性能。设计的模型网络结构如图1 所示,以40 s 长度波形、50 Hz采样率的三分量波形为输入,通过7 层的网络结构,输出与输入波形具有相同长度、从一个通道输出的预测结果。模型具有多个层次的扩展路径,在一个扩展路径单元,对更深层单元的输入进行反卷积和激活,并将结果和同一层中前一个单元的输出拼接起来作为该单元的输出。这样设计的网络中,较浅层次的网络获取较小尺度范围内的特征;较深层次的扩展网络收缩路径,把较浅层次的扩展网络的输出作为输入,可以更加综合地获取对象的不同尺度图像,提高网络判断的准确率和精确度。
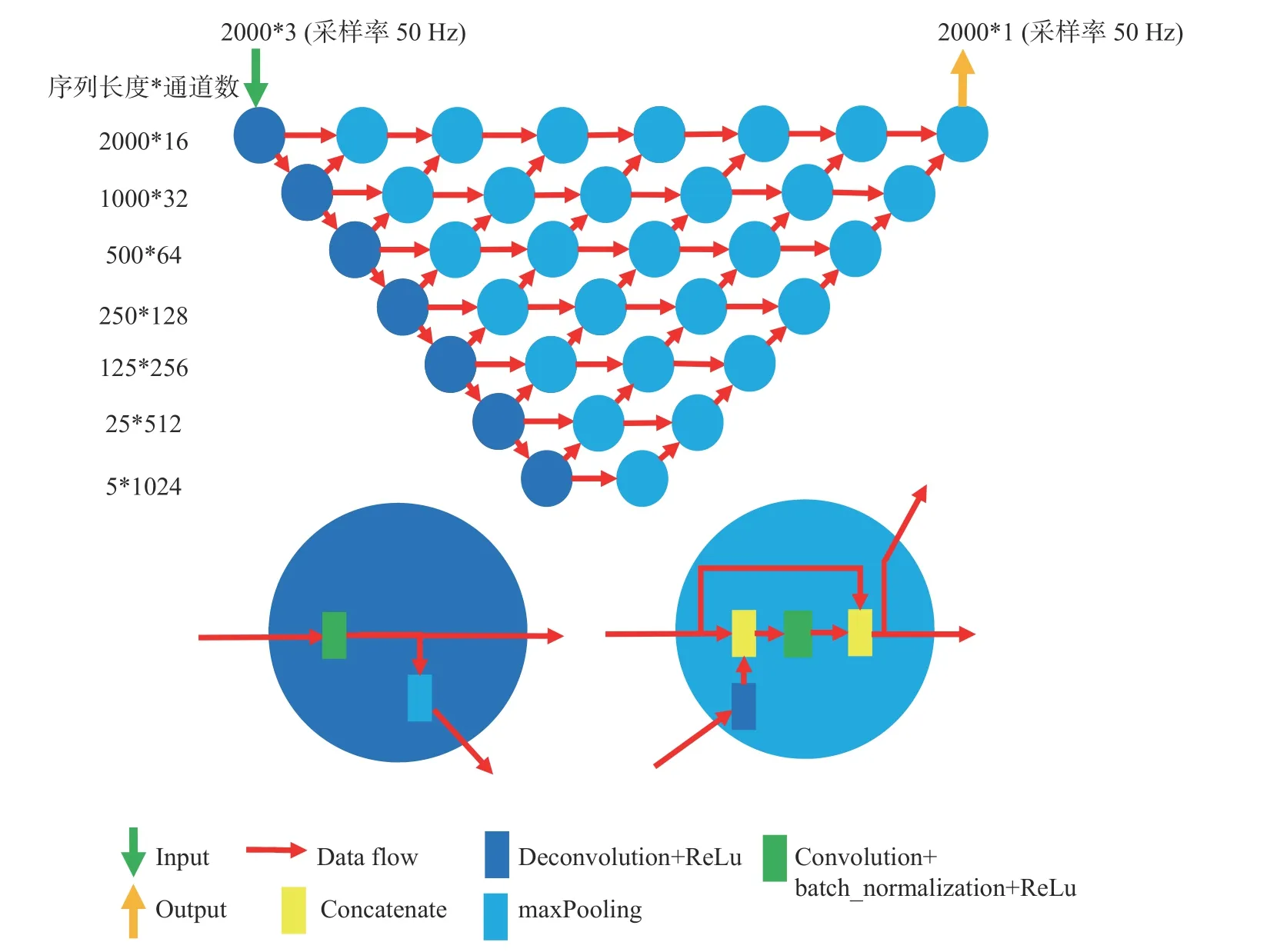
图1 PP++震相拾取模型
U-net++是在医学图像识别领域发展起来的,识别的对象相对于整个图像而言只占一小部分,使得较浅层次的模型也能在小尺度上对对象进行识别。因此,U-net++可以在多个扩展路径上都输出判别结果,用于优化参数。这样,使得具体的几个层次的输出都能拟合上目标输出,从而增加了模型的约束,避免模型过拟合。考虑到震相拾取问题需要根据地震波到达之前的噪声水平、整段波形的偏振变化等信息才能做出准确判断,涉及到的尺度和整个时间窗相当,浅层路径无法有效提取这些信息[4],所以只关注最深层次的拓展路径输出结果,而不对其他浅层输出结果做约束。
相比于使用一个模型同时拾取P 波和S 波,使用相同网络结构、但参数不同的两个模型分别拾取P 波和S 波时可以避免不同震相拾取结果间的相互干扰,从而获得更高的拾取准确率和精确度[4]。基于这种考虑,PP++模型直接输出的时间序列y(x)只有一个通道,大于0 表示属于P 波(S 波),否则为噪声或其他震相,这里x表示作为模型输入的波形三分量。在直接输出后加入Sigmoid 函激活层,将直接输出y(x)映射到(0,1)之间,表示对象为P 波(S 波)概率q(x)的大小[4,11],大于0.5 则视为P 波(S 波),否则视为噪声或其他震相。
和PhaseNet、APP 等U-net 型震相拾取方法类似[1,4],将震相到时转换为高斯概率分布形式的时间序列p(x),震相到时作为高斯分布的中心(图2~3)。高斯概率函数的形态应与震相拾取的精度匹配,这里使用了高精度的样本集Hi-net 和STEAD[12-14],因此设置P 波和S 波的高斯函数标准差分别为0.08 s和0.12 s。
为了保证样本集中震相部分和噪声部分的均衡,设置和刘芳等[4]相同的带权重的交叉熵损失函数F(x)
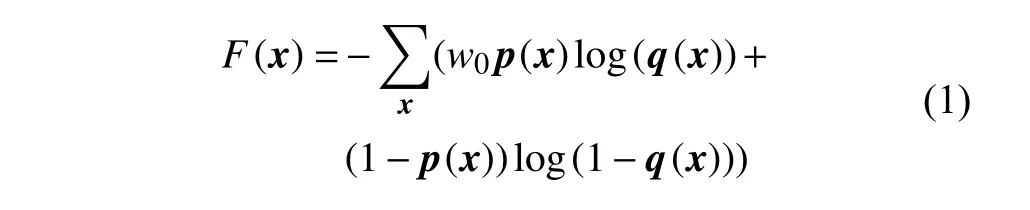
经过试验,设置w0为24。
使用Hi-net 台网的目录、波形数据和STEAD地震波形、到时数据集共118 万条作为训练的样本集。为尽可能地模拟对连续波形进行扫描的情形,对于样本集中波形随机选取时间窗,使得震相随机地分布于选取的时间窗内(图2~3)。
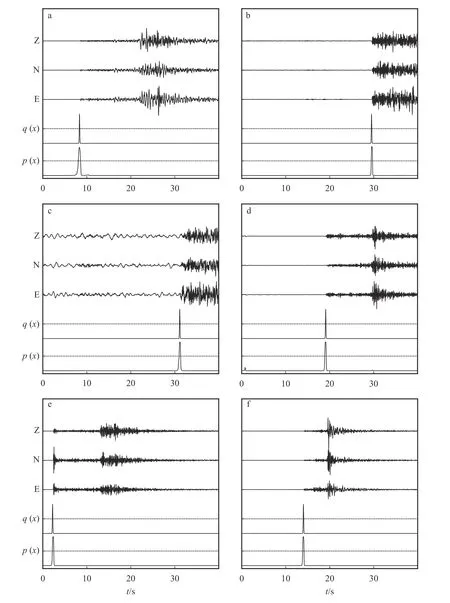
图2 随机选取的样本波形
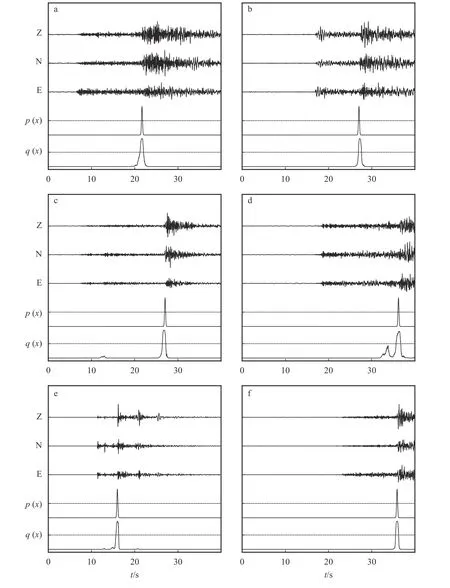
图3 随机选取的样本波形
1.2 PP++模型的训练和测试
选取样本集中的1 104 914 条记录作为训练集,30 000 条样本作为验证集,50 000 条样本作为测试集。训练过程中,每轮在训练集中随机选取5 000条样本,并根据损失函数使用验证集对每轮生成的模型进行评估;当模型在验证集上的损失函数超过50 轮迭代后仍然没有降低时,则停止迭代,选取损失函数最小的模型作为最终的模型;利用最终得到的模型在测试集上进行评价。
评价标准首先包括Zhu 等[1]和刘芳等[4]使用的评价参数:准确率(P)、召回率(R)、综合正确率(F1)、误差均值(mean)、误差均值(std)。准确率(P)、召回率(R)、综合正确率(F1)的表达式如下:
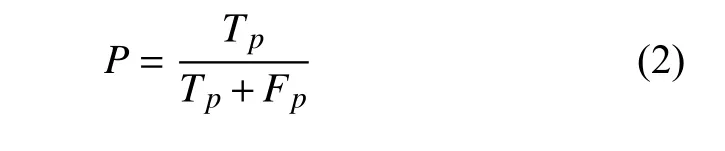
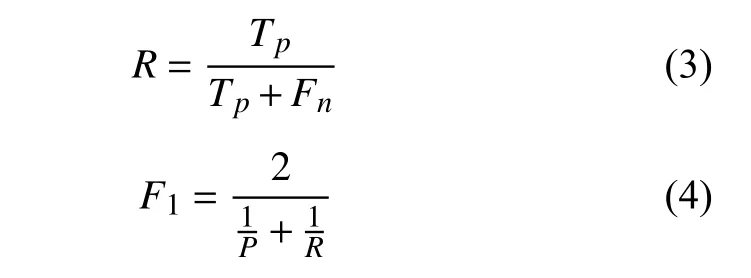
式中:当模型预测概率>0.5、且与人工标注误差在0.5 s 以内,视为正确的正预测,计入Tp;当模型预测概率>0.5、但与人工标注误差>0.5 s,视为错误的正预测,计入Fp;当模型预测概率始终<0.5、但该段时间内确有人工标注震相时,视为错误的负预测,计入Fn;F表示准确率和召回率的调和平均。具体地讲,准确率反映的是,当模型给出正预测时正确拾取震相的比例;召回率反映的是,对于人工标注的震相,模型能够准确拾取的比例。一般来讲,设置高的标准,可以获得更好的准确率,但是召回率会下降;设置低的标准,则会提高召回率,但准确率下降。故需要将两者结合起来看,才能够更为合理地评价模型。较为通常的做法就是引入一个综合正确率,即对准确率和召回率取调和平均。
同时,还需要衡量模型在连续数据上误识别比例的高低。震相拾取方法的应用场景中最为困难的是对连续数据的扫描。在实际数据中存在很多局部噪声,而且仪器异常干扰也会引起仪器的误识别。另外,在实际波形资料中,大部分时间的记录是不存在震相的噪声,即使模型对于噪声只有很低的误识别率,也容易产生大量的误识别结果。需要通过大量的噪声数据来对模型进行测试,从而衡量模型的抗干扰能力。如果在直接被人工标注过震相的连续数据中把未有人工标注的片段作为噪声数据,则其中会遗漏很多小能量的震相,从而无法反映真实的误识别比例。即使人工检视过的噪声资料也存在同样的问题,未看到明显震相的记录中可能也包含被噪声能量掩盖的小能量震相,而APP++震相拾取模型在这个时候则能体现其优越性。本文采取人工生成的方式,来避免缺乏噪声测试样本的问题。随机生成标准差为1 的三分量连续波形共100 天,每天的连续波形中随机在一些时间点加入300个大幅值的突变。使用模型扫描生成的数据,统计输出大于0.5 的次数作为误识别次数,并计算平均每天误识别的次数,记为M(单位为count per day,CPD)。当然,人工生成的噪声数据的分布和实际记录不完全一致,所以与在实际数据中的误识别比例会存在差异。因此,主要的关注点为将不同模型在人工噪声上误识别比例的相对大小用于评价不同模型的抗干扰能力的相对高低。
由于Hi-net 和STEAD 两个样本集来自不同的地区,故分开统计两个测试集。为比较PP++模型与PP 模型的效果差异,同时也采用相同的设置对PP 模型进行测试。值得注意的是,PP++模型具有更高的连接密度,在同样尺寸设置下会比PP 模型拥有更多的训练参数。为避免训练参数的数量影响对网络结构的评价,增加了PP 模型的规模(74 720 001个参数),使得其与PP++模型(77 885 201 个参数)相当。
表1 是两个模型的测试结果。PP++和PP 在前五项指标上差别不大,主要的差别体现在第六项日均误识别次数。在使用两个数据集一起训练的时候,识别P 波的PP 模型与识别P 波和S 波的PP++模型的日均误识别次数都在一次以内,而对于识别S 波的PP 模型则达到了15。由此表明,使用U-net模型训练的S 波拾取模型可能在数据质量较差的时候受到很强的干扰从而产生较多的误识别比例。而U-net++则可以较好地避免这种情况,即PP++模型相对于PP 模型更有优势。比较两个数据集的测试结果,尤其是对S 波的拾取上,STEAD 样本集上效果在大多数时候更好,可能是因为STEAD 样本集中的样本震中距更小,震相更为简单。
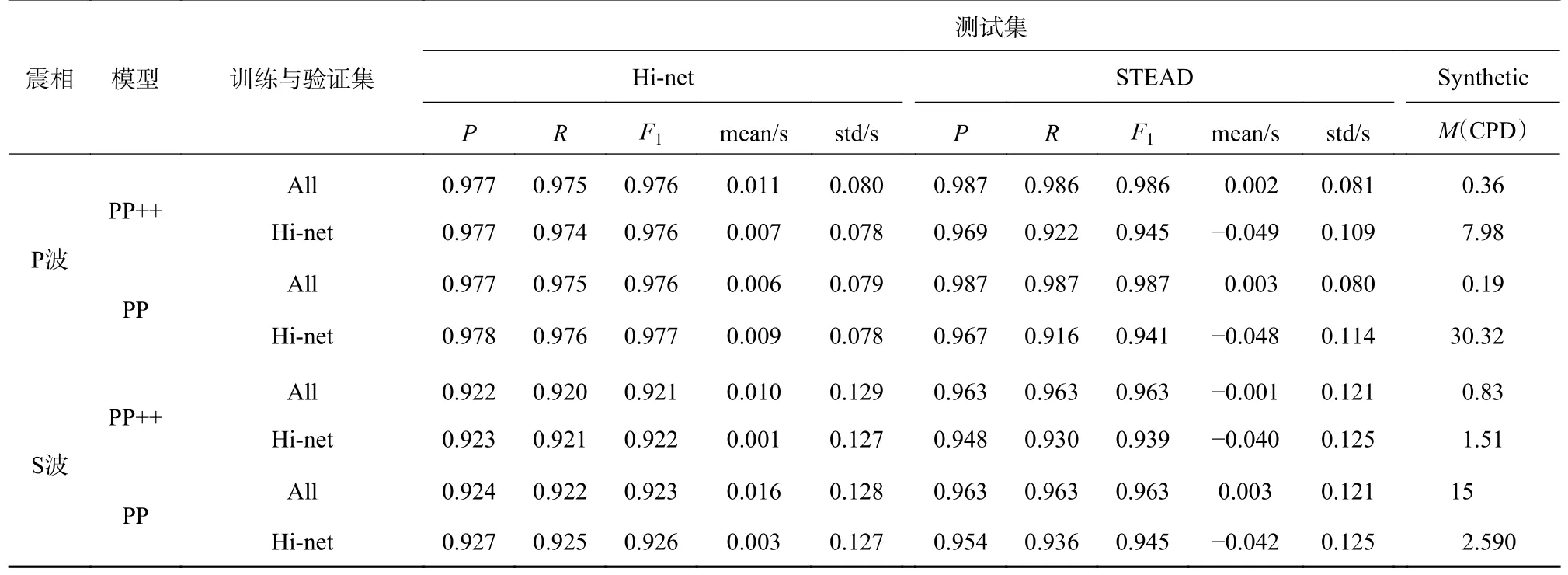
表1 PP++和PP 模型测试结果
图4 展示的是PP++模型拾取震相到时的误差分布。P 波和S 波在两个样本集的误差都很小,而且具有很好的对称性,反映出PP++模型具有很好的拾取效果。
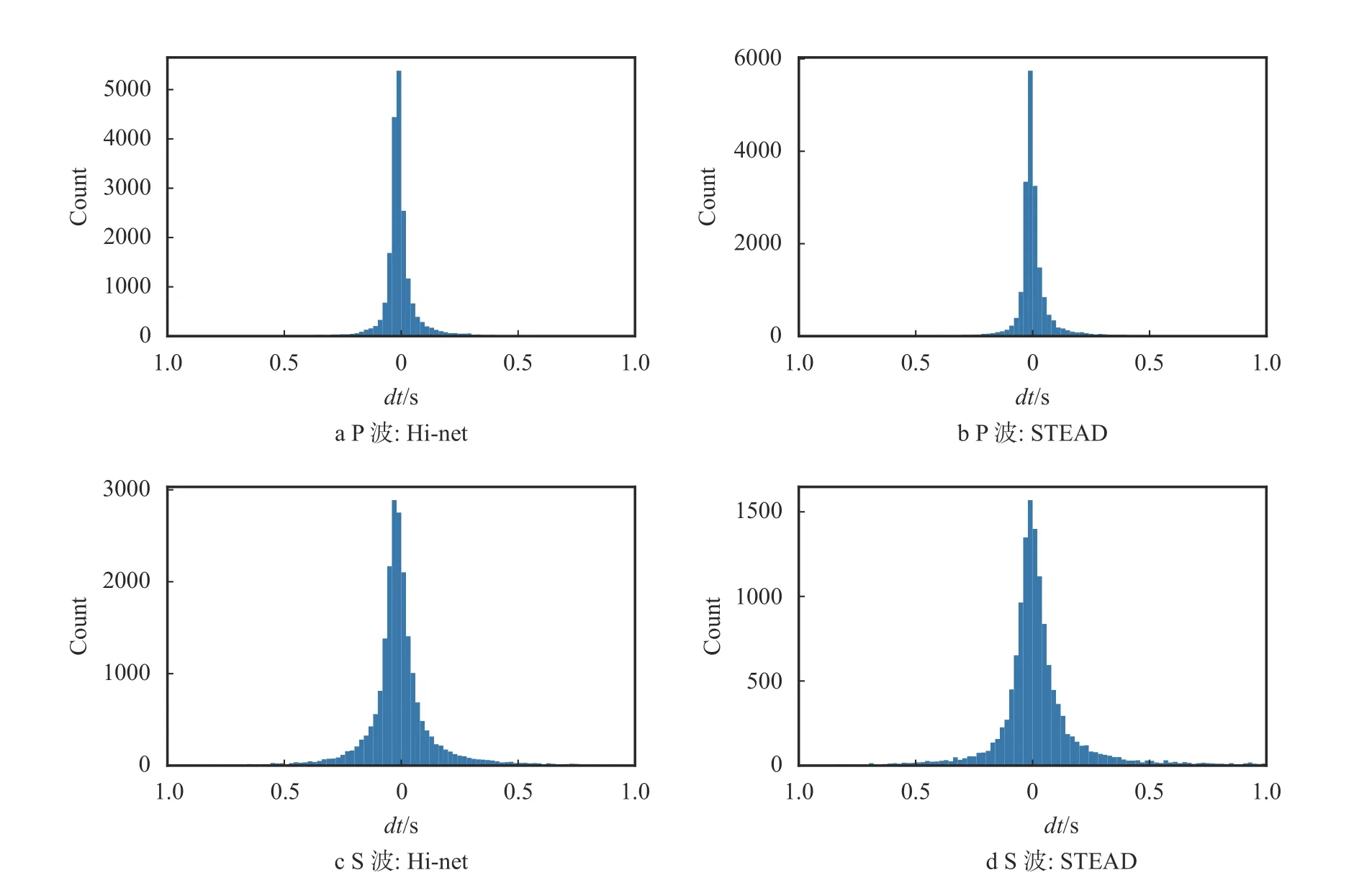
图4 PP++方法拾取震相的误差分布图
1.3 APP++模型的泛化能力
高质量的样本集往往来自运行时间较长、数据处理流程成熟的固定台网。这类固定台网多数积累了大量的地震目录和震相到时数据,对于自动拾取算法的需求反而不迫切。而缺乏样本积累的新建固定台网和流动台网则比较迫切地需要高质量的自动拾取。如果使用一个台网的高质量样本集试验出来的模型能够在缺乏样本集积累的台网数据上应用,则可以很好地解决这个问题,同时也可以减少迁移到新数据上使用的成本,这就要求模型具有一定的泛化能力。U-net[8]这类端对端的深度学习模型,就具有较强的泛化能力,不容易发生过拟合。刘芳等[4]的研究也表明,U-net 类的震相模型具有一定的跨区泛化能力,且使用具有较好拾取质量的异地样本集甚至可以获得比使用稍低质量的本地样本集更好的拾取效果。本文所使用样本的Hi-net 主要来自日本及其周边区域的台站,而STEAD包含的台站基本覆盖了全球大部分区域。为了验证模型的泛化能力,使用Hi-net 训练和验证模型,并使用STEAD 对模型的效果进行测试(表1)。结果显示,PP 模型和PP++模型具有良好的泛化能力,仅使用日本周边地区的地震进行训练也能在全球化的STEAD 样本集中显示出很好的拾取效果。单独使用Hi-net 样本集训练的时候,识别P 波的PP 模型、识别P 波的PP++模型和识别S 波的PP++模型,日均误识别率都显著提高。识别P 波的PP++模型的日均误识别率低于识别P 波的PP 模型,识别S 波的PP 模型,日均误识别率有所下降,但仍高于同等情况下识别S 波的PP++模型。总体上看,在使用小规模样本集的情况下,PP++模型的误识别率更低。识别S 波的PP 模型在小样本集上误识别率的下降也说明,PP 模型的误识别率可能受样本集影响很大,不够稳定。因此,PP++模型在扫描连续数据时将具有更好的可靠性。
1.4 APP++模型:PP++与台阵策略结合
尽管单台的拾取精度已经很好,但是在扫描长时间的记录波形数据时,仍然会出现部分误识别。将单台的拾取方法和台阵策略结合,利用多台拾取结果间的时空关系,可以排除大多数局部噪音造成的误识别[10]。本文采用和刘芳等[4]相同的方法,将PP++模型与蒋一然等[10]的台阵策略结合,形成了台阵下的震相拾取方法APP++。
2 在川滇地区的应用
川滇地区位于青藏高原东南缘,构造运动活跃,是研究青藏高原隆起相关的物质运移等问题的重要研究场所,同时该地区具有很强的地震活动性,对该区域的研究有助于推进地震预测和预警研究的发展。因此,将使用Hi-net 和STEAD 样本集得到PP++模型和APP++方法应用到川滇地区的固定台网和流动台阵中的167 个台站(位置移动过的台站视为不同台站)上。通过扫描2014—2019 年共6 年的连续波形,找到73 291 个地震、537 554 个P 波记录、471 459 个S 波记录(图5)。图6 是APP++方法拾取到的4 个地震事件波形随震中距的分布及拾取到的震相到时,拾取结果和实际波形吻合较好,表明该方法能够用于对该区域地震的震相拾取。
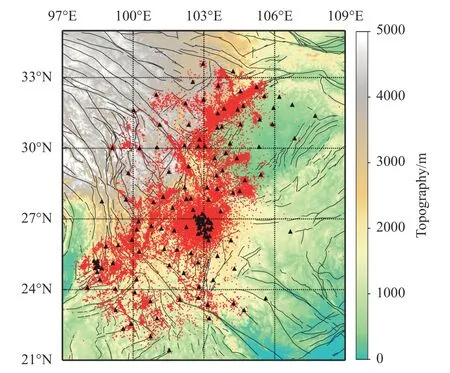
图5 台站及震中分布图
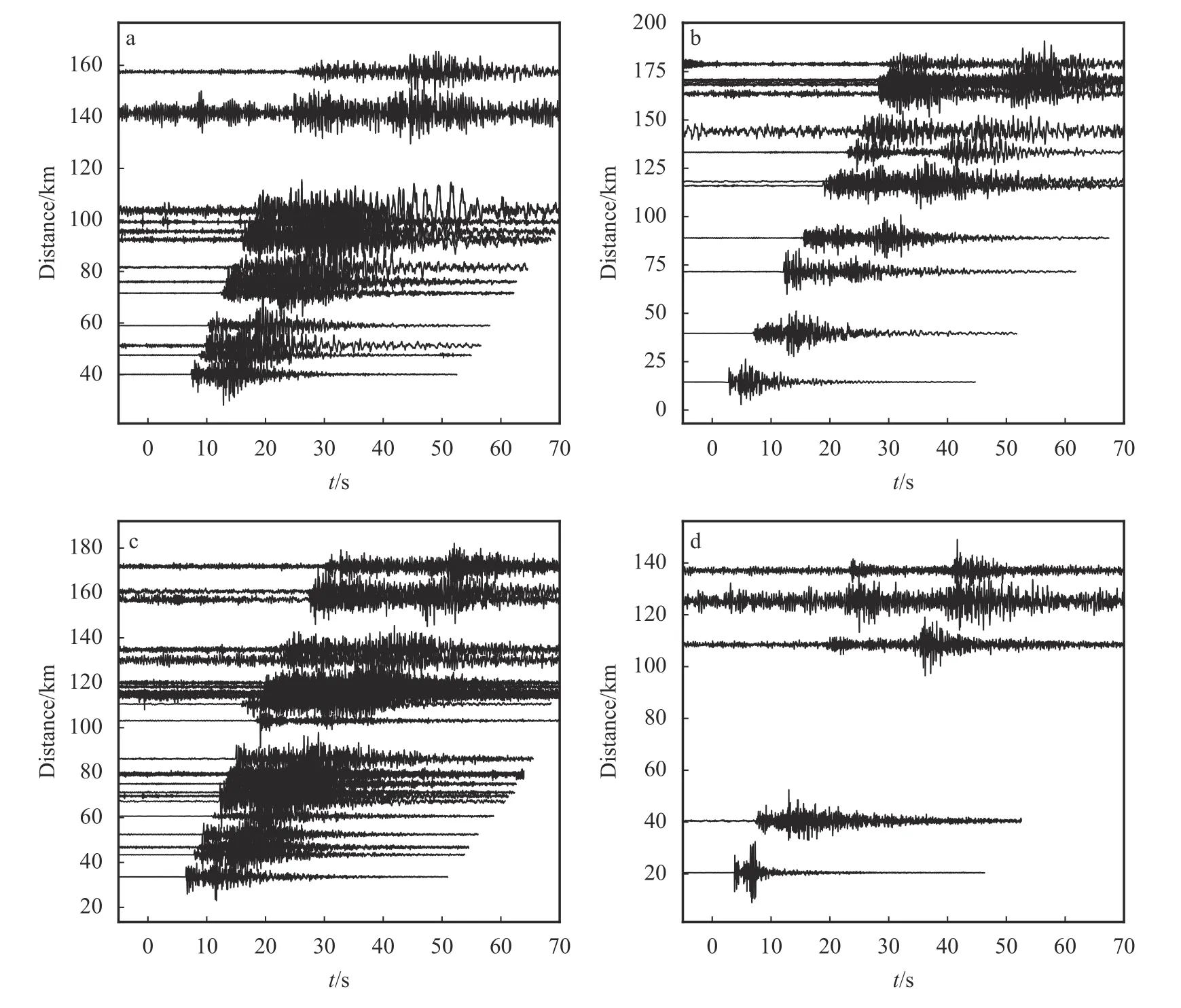
图6 APP++方法检测到的4 个地震及其到时
3 拾取结果分析
图5 展示的地震分布和当地的断层分布对应较好,后续研究中对这些地震进行精定位将有助于细致刻画该区域的断层结构。受台站分布密度的影响,在台站密集的区域,检测到地震多一些,台站稀疏的区域则检测到的地震相对较少。
图7a 是地震数目的平均日变化(UTC+8)。图中显示,在夜间、中午、傍晚时间记录到的地震数目明显更多,这可能是因为在这些时间段正好是睡觉、吃饭的时间段,人类活动较少,环境噪声水平降低,同等台阵密度下记录到的地震变多。图7b 是不同震级的累计地震数量分布图,符合G-R关系[15],相应的完备震级应在1.5~2.0 级之间。由于研究使用台阵的台间距在40 km 左右,以单台判断为主的深度学习方法受信噪比限制无法再对更低的震级进行完备的检测,如使用弱模板识别[16]等方法则有可能进一步提高地震检测能力。
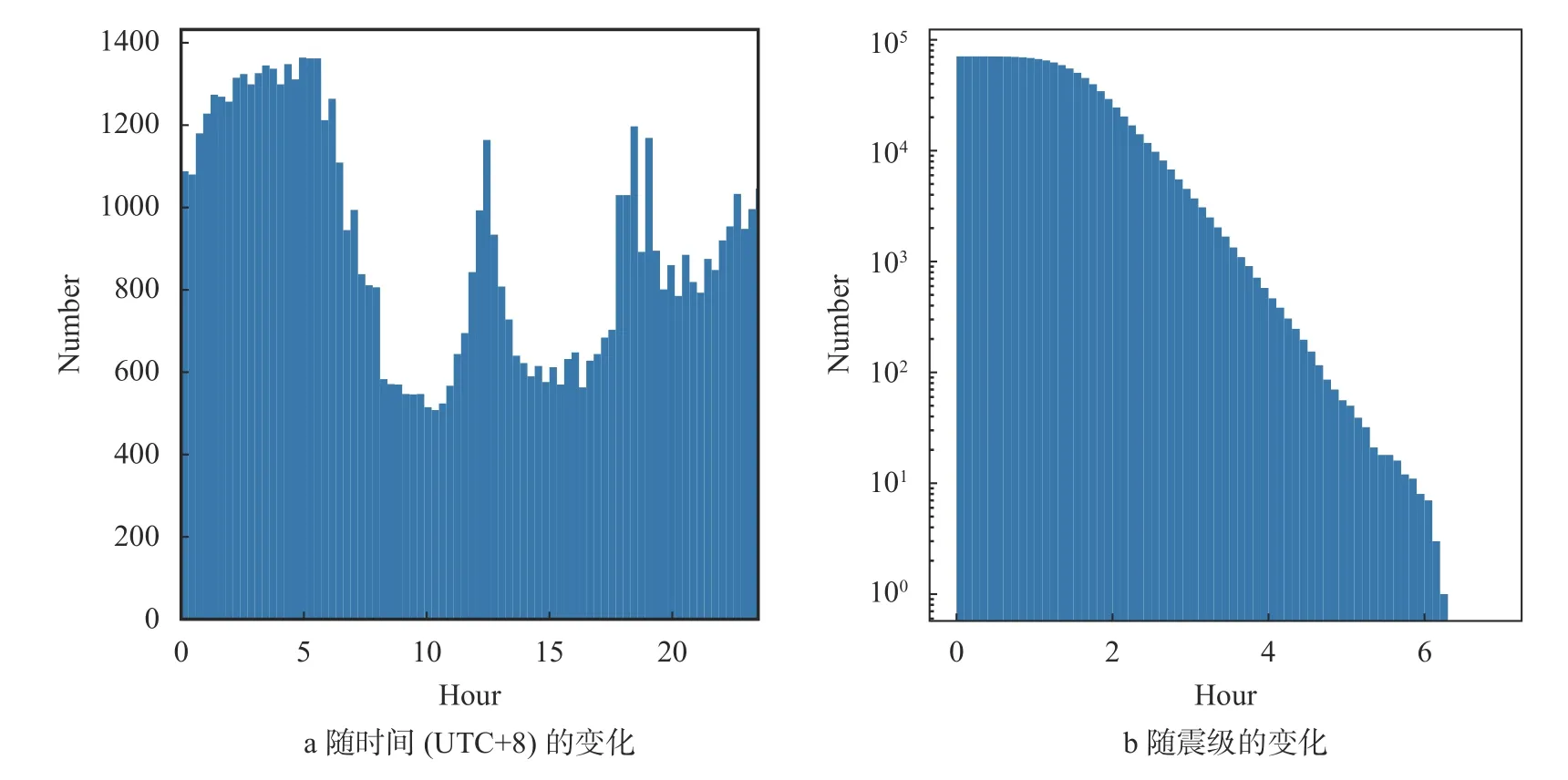
图7 地震频度分布
发震频率随震级变化的趋势可以用b值来描述,是研究地震活动性的重要指标。前人的研究结果表明,b值与当地的岩石状态、断层形态等相关[17-19]。本文采用MAXC[20-21]方法对研究区域内的b值和完备震级Mc进行了估计(中心点附近120 km,至少包含180 个地震记录)(图8)。在龙门山断裂带上b值较附近区域偏低,但对于整个研究区域而言处于平均水平,这与前人的研究较为一致[22-23]。研究区域的北部和南部的低b值可能反映该地区较高的应力水平,而东部的低b值则与该地区的页岩气开采有关。完备震级(图8b)的空间分布和台站密度有很好的一致性,在被高密度的流动台网加密的小江断裂带附近,完备震级达到了1.5 级以下。
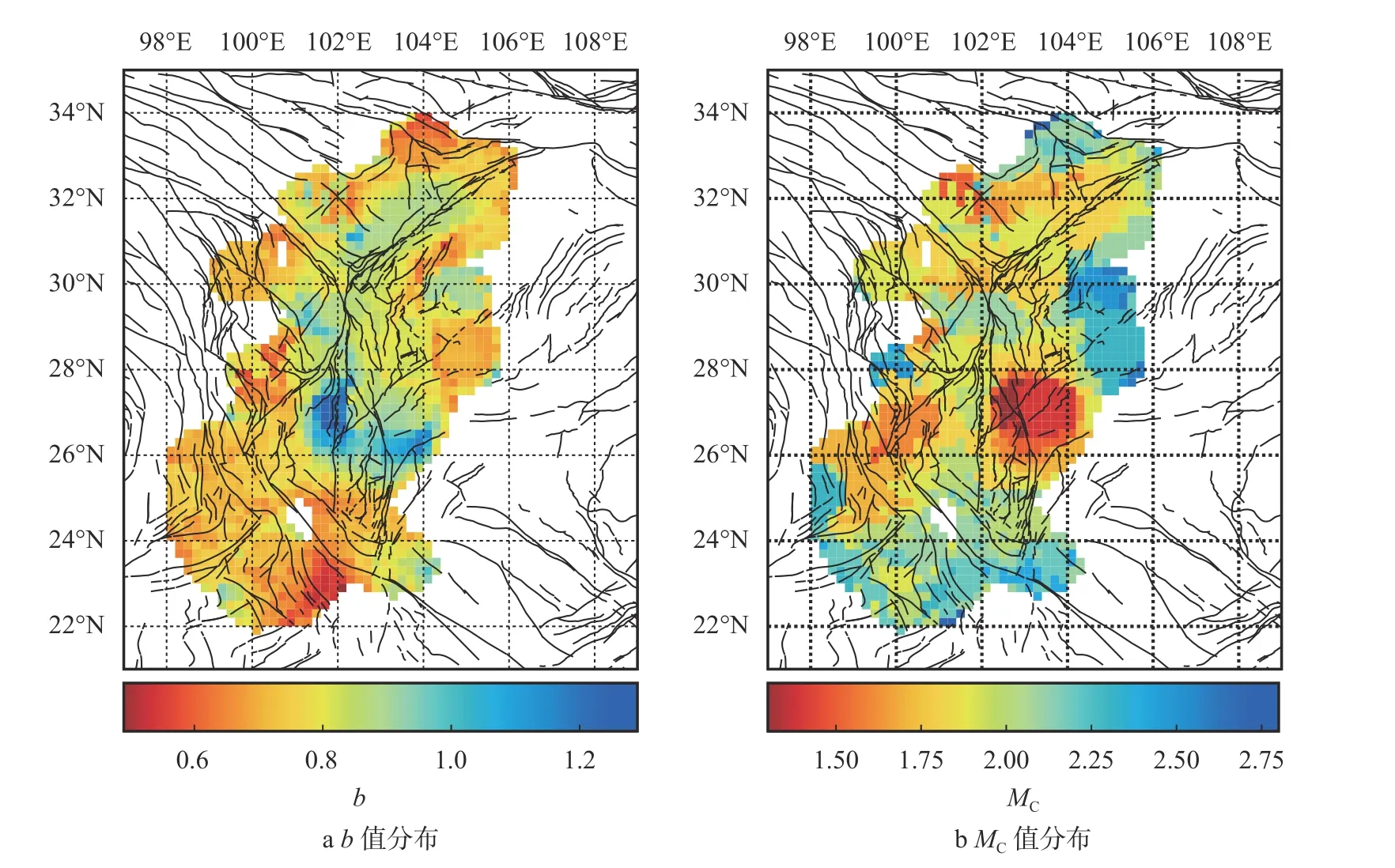
图8 b 值和完备震级MC 分布图
4 结论
1)在APP 方法的基础上,利用U-net++改进了原有的深度学习网络,能够更好地避免噪声的干扰,并在测试中显示出一定程度的跨区域泛化能力。
2)进一步将海量数据训练得到的网络用于对川滇地区地震的扫描,检测出了大量的地震并拾取了其体波到时。分析发现:①拾取到的地震的空间分布和当地的断层有很好的一致性;②检测地震数量随时间的日变化反映了当地噪音水平对地震检测能力的影响;③地震发震频率随震级的变化满足G-R关系。
3)对研究区域内不同地点的b值做出了估计,b值的变化能够大致反映对应区域的应力状态变化情况。
致谢中国地震局地震预测研究所为本研究提供地震波形数据;本研究工作得到北京大学高性能计算校级公共平台支持。
