基于多任务模型的深度预测算法研究
2021-07-12殷雪峰张肇轩尹宝才
姚 翰,殷雪峰,李 童,张肇轩,杨 鑫,尹宝才
基于多任务模型的深度预测算法研究
姚 翰,殷雪峰,李 童,张肇轩,杨 鑫,尹宝才
(大连理工大学计算机科学与技术学院,辽宁 大连 116024)
图像的深度值预测是计算机视觉和机器人领域中的一个热门的研究课题。深度图的构建是三维重建的重要前提,传统方法主要依靠确定固定点深度进行人工标注或是根据相机的位置变化来进行双目定位预测深度,但这类方法一方面费时费力,另一方面也受到相机位置、定位方式、分布概率性等因素的限制,准确率很难得到保证,从而导致预测的深度图难以完成后续三维重建等工作。通过引入基于多任务模块的深度学习方法,可以有效解决这一问题。针对场景图像提出一种基于多任务模型的单目图像深度预测网络,能同时训练学习深度预测、语义分割、表面向量估计3个任务,包括共有特征提取模块和多任务特征融合模块,能在提取共有特征的同时保证各个特征的独立性,提升各个任务的结构性的同时保证深度预测的准确性。
计算机视觉;单目深度预测;多任务模型;语义分割;表面向量估计
“近大远小”是人们在自然界中对距离远近把控的奥秘,大自然中的生物经过不断进化已形成了优秀的视觉系统,能轻松地识别视野中各物体与自身之间的距离,以完成各种交互任务。在计算机视觉领域,2D图像的场景深度估计已然成为一个重点的研究方向,深度作为2.5D的因素,是连接2D图像和3D立体模型的重要桥梁,可以说,深度是二维向三维过渡的关键,更是对场景结构理解复现的重点,可以用于人体姿态预测、自动驾驶汽车、场景理解、3D重建和语义分割等多个方面。然而,目前的深度预测算法提取出的语义信息很难准确地反应深度信息在结构上的信息,物体与物体、物体与背景之间的结构性很难体现,且易受光照、阴影影响,而与之对应的语义分割任务则会提取物体间的不同,更能反映物体间的结构性信息。所以本文基于深度预测、语义分割、表面向量预测3个任务的共通性,设计了新的神经网络模型,提取更可靠的特征,使深度预测的结果更有结构性。实验表明,通过与深度预测有关的任务一同预测,可以利用两者间相关的信息相互促进以提高效果,从而达到较好的效果。
1 国内外研究现状
1.1 单目图像深度预测
在机器学习出现之前,一种是传统方法,即使用人工的手工标注方法,通过对类似图片的手工标注深度定位,再对场景提出合理的几何假设,在概率模型的基础上分析各部分的深度值;另一种方法则是SAXENA等[1-2]使用马尔可夫条件随机场(Markov random filed,MRF),将深度图正则化,再将平面上像素通过平面系数和条件随机场来预测对应的深度值,由于在公式中添加了约束相邻像素的部分,使得该方法可以分析图像中的局部特征和全局特征来推测其深度信息。
随着深度学习方法在计算机图形学领域的广泛使用,LAINA等[3]基于全卷积网络(fully convolutional networks,FCN)来进行单目深度估计,并通过加深网络结构来促进效果的提升,且FCN不限制分辨率大小,所以不需要进行图像后处理。一方面使用不限制分辨率大小且同时优化效率的新的Encoder-Decoder方法;另一方面使用逆Huber Loss函数进行优化处理,可以使深度分布更合理。CAO等[4]将深度预测问题作为精细的语义分割处理。首先离散化图像中的深度值,之后训练一个残差网络来估计各个像素对应的分类。通过其相应的概率分布来使用条件随机场(conditional random field,CRF)进行处理优化。GARG等[5]首次实现无监督的单目深度预测,使用立体图像但不需要深度值数据。利用左目图像、右目图像和深度图像的关系,先输入左目RGB图像来预测一个模糊的深度图像,再通过深度图像和原图像恢复出右目图像,计算右目图像与真值之间的损失来优化网络。ZORAN等[6]则对图像中的相对深度关系更感兴趣,利用双目系统中的点匹配关系来估计深度值,以达到无监督或弱监督的目的。该算法首先利用双目图像中点与点的对应关系,将2个预测的深度图像进行插值优化,以获得更准确的深度。CASSER等[7]提出一种更有效的方法,即通过对移动目标进行建模,产生更高质量的深度估计效果,另利用一种无缝的在线优化方法,使训练效果更好,提升预测的鲁棒性,并且可在不同数据集中进行转移。
虽然卷积神经网络(convolutional neural networks,CNN)在深度预测任务中能达到良好的效果,但还是存在一些问题,首先深度预测使用的网络结构多是用来解决语义分割问题,虽然能达到较好的准确率,但很难表达深度图像所具有的结构性。另外,深度图像数据集存在的数量较少且有噪点问题也影响预测的鲁棒性。
1.2 深度预测与多任务
深度预测的研究离不开语义分割的方式方法,相似的特征提取方式使得深度预测可以与语义分割等其他任务一同训练,因此既能提取出各个任务的相同特征,又能利用各任务的相互关系来进行彼此促进,旨在执行任务交互的特征融合或参数共享。融合或共享方式可以利用任务之间的相关信息。最近,针对此类任务的几种联合任务学习方法已显示出一个有前途的方向,即通过利用与任务相关的信息相互促进来提高预测。EIGEN和FERGUS[8]提出了深度预测可以和语义分割与表面向量预测等任务一同使用一个网络来进行训练。MOUSAVIAN等[9]提出的模型将深度值预测和语义分割2个任务一同训练,先将2个任务在第一阶段一起训练,在第二阶段再使用损失函数分别收敛训练以调整整个网络形成优化,之后将CNN与CRF结合进来,利用语义标签和深度值的信息来优化结果。WANG等[10]同样结合CRF与CNN构建模型,提出一种框架可以将深度与多种其他视觉信息结合起来,通过推导设计好的能量函数,使得整个框架可以通过反向传播进行训练。GODARD等[11]将单一视角的深度预测、相机位姿预测、光流信息、静态场景和移动区域的语义分割4个基本的视觉问题通过几何关系进行约束,耦合在一起进行训练。ZHANG等[12]将RGB图像处理成了不同尺度的特征图,在通过解码器处理得到不同的深度信息和语义信息,经过交替的特征融合来提升精度。ZHANG等[13]提出了一种“角度模式-主动传播”(pattern-affinitive propagation,PAP)的框架,以实现同时预测深度、表面法线和语义分割任务,通过2种类型的传播,能更好地使网络适应不同任务之间的区别,每个任务的学习可以通过补充任务级别的能力来进行规范和增强。
目前多任务模型存在的问题主要是特征融合的方式仅是使用参数共享,并未将共有特征对任务的帮助和各任务之间的特点表现出来。
2 方法综述
通过与深度预测有关的任务共同预测,可以利用两者间相关的信息相互促进以提高效果,其根本原因是对相同的语义信息,网络会给与相同的参数,而共享这些参数则会使某些共有的信息更突出化,避免某一任务由于数据原因,忽略了一部分特征的提取。其中,语义分割和表面向量预测是与深度预测非常相关的2个任务,语义分割能有效地提取特征以区别不同物体,通过物体间梯度变换的特性,可以与深度预测中的物体关联,另一方面,语义分割能对不同物体进行分类,使得深度值的预测更能依赖于物体独有的梯度变化,也更能分辨与背景相似的物体间的联系。而表面向量对深度预测的影响更为直接,两者之间存在着几何关系可以互相转换,其数学关系为

为了完成这一目的,本文将通过2个模块进行网络训练,一个是共有特征提取模块,负责提取各任务的特征,并可以恢复粗糙的深度图、语义分割图、表面向量图;另一个模块是多任务特征融合模块,改模块负责将第一个模块提取到的特征进行多任务的融合,网络模型将会区分各任务共有语义特征和各任务独有的语义特征,使得最后恢复的图像更具有结构性。
图1为整个算法的流程和2个模块的信息,整体网络的输入为单张的RGB图像,输出为该图像所对应的深度图像、语义分割图像、表面向量图像。网络中将共有特征提取模块和多任务特征融合模块整合成统一的结构,并在统一的训练中完成端到端的生成。

图1 基于多任务的深度预测算法流程图
3 共有特征提取模块
3.1 网络结构
共有特征提取模块由单编码器多解码器构成,目的是为了实现深度预测、语义分割、表面向量预测3个任务的共同特征提取以及第一阶段的任务分化。该模块首先通过编码器将输入的图片进行编码成一维特征,再通过3个解码器分别解码成3个任务所需的尺寸和通道,然后通过特征连接的方式结合各尺度的特征,最后可以将本模块输出的图像与数据集中的真值图像比较减少损失,更新网络参数,以保证编码器提取的是3个任务共有的特征。
如图2所示,本模块使用的网络结构是以VGG-16模型搭建的FCN为主,其能很好地在像素级别对图像进行分类,并完成语义分割的任务;在深度图预测的问题上,表现也十分出色。

图2 共有特征提取模块结构
本模块包含4部分:编码器、多维解码器、多尺度特征融合模块和细化模块。其中,编码器由4个卷积层组成,负责提取1/4,1/8,1/16和1/32多种尺度的特征。解码器采用4个上采样模块,逐步扩大编码器的最终特征,同时减少通道数量。多尺度特征融合模块使用向上采样和通道连接来集成自编码器的4种不同比例特征。与编码器相对应,将编码器的4层输出(每个具有16个通道)分别以×2,×4,×8和×16的形式上采样,以便具有与最终输出相同的大小。这种上采样以通道连接方式完成,然后通过卷积层进一步变换以获得具有64个通道的输出。多尺度特征融合模块的主要目的是将多个尺度的不同信息合并为一个,从而使编码器的下层输出保留了具有更精细空间分辨率的信息,有助于恢复由于多次下采样而丢失的细节信息。最后,细化模型用于调整图像的输出大小以及通道数,分别对应3个任务采用3个卷积层,使得输出的通道数恢复为深度图像的1通道,语义分割图像的1通道和表面向量的3通道,便于进行损失的计算和反向传播。
网络输入为320×240×3大小的RGB图像,然后将其通过编码器的4个卷积层得到4层特征,然后将此特征通过解码器,解码器由4个上采样层组成,将不同尺度的特征进行解码,完毕后,由多尺度融合模块将不同尺度的上采样输出融合在一起,最后通过细化模块中不同的反卷积层恢复出深度图像、语义分割图、表面向量图的形状,具体网络参数及各层的输出见表1。

表1 共有特征提取模块网络参数
3.2 训练过程
本模块属于单输入多输出型网络,在训练的过程中,需要网络根据数据集中RGB图像与深度图像、语义分割图、表面向量图与网络预测的对应图像之间建立损失函数,进行网络参数的更新、迭代直至损失函数收敛时,能够得到训练好的网络。
由于需要同时处理3个任务,且保证各任务之间的相关性,所以本文的损失函数分为3个部分。特征提取损失函数为
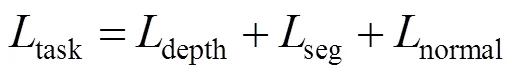
各部分损失函数的作用和目的如下:
(1) 深度图损失函数,即

该函数为1损失函数与梯度损失函数之和,其中对于每个像素点,对应的预测深度与真实深度分别为d和D,1损失函数可以约束d与D间的不同,为该损失函数的主要部分,提供了准确率的保证。
(2) 语义分割损失函数,其为交叉熵函数,是语义分割问题中常用的损失函数,常用于描述2个概率之间的距离,在本文中约束图像中物体的预测语义类别的概率,其表达式为



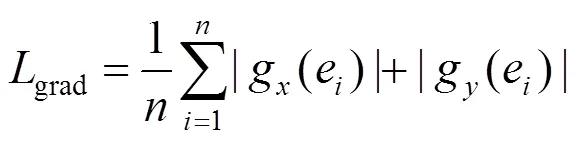
在该模块训练过程中,本文通过直接在网络的输出端得到3个任务的图像并与其对应的真值之间设计损失函数,经过梯度下降的方式进行反向传播,从而对网络的参数进行更新,当损失函数收敛时,可完成训练。在本文算法的训练过程中,设定迭代次数为100,每次处理图像数量为4,初始学习率为10–4,每经过20次迭代更新学习率为原来的十分之一,最后在经过100次迭代后得到的收敛损失函数值为0.124 5。
4 多任务特征融合模块
本模块负责处理共有特征提取模块的数据,通过本模块将共有特征更精细地进行特征融合和分化,旨在提取出各任务的具体的共同特征和分化特征,提高各任务的精度,增强各任务的结构一致性。由于共有特征提取模块仅仅是通过参数共享实现的共有特征的提取,其并不能准确的代表本文中3个任务的共通性,所以设计该模块以保证多任务特征提取的普遍性。
4.1 网络结构
多任务特征融合模块由2个部分组成,第一部分是多输入特征融合模块,负责将上一模块输出的多任务特征进行融合,所使用的网络为密集连接的U-net;第二部分为特征解码部分,与上一部分的解码器部分类似,为多输出解码器,故不详细介绍,本模块的整体网络结构如图3所示。

图3 多任务特征融合模块结构
本文在原U-net网络的基础上添加了密集连接的方法,能有效地增强多输入模式的特征提取能力,为了实现这种密集的连接模式,首先创建一个由多个流组成的编码路径,每个流都处理上一模块不同的任务的图像形式。对不同的图像形式采用单独的流的主要目的是分散原本会在早期融合的信息,从而限制了网络捕获模式之间复杂关系的学习能力。从网络结构中可以看出,3个任务先分别通过U-net的编码器进行编码,但不同点在于,在不同的卷积层传递时会产生交互,比如,任务1的图像在经过一次卷积池化操作之后,得到的池化特征会在任务2的二次池化特征进行结合,通过卷积层后又与任务3的池化特征结合。这样可以使特征在任务之间流动,保证特征的共用性。在解码器部分,将得到的共用特征先通过一个上采样操作得到一个共有上采样特征,再将此上采样特征结合之前的池化特征一起进行解码,分别将其与3种任务不同尺度的池化特征送入解码器,并与之前的各任务提取的特征进行连接并通过上采样层,恢复各任务原来的形状,再将恢复的深度图像、语义分割图、和表面向量图与数据集中的真值进行损失比较,以更新网络中参数。本模块网络结构参数见表2。

表2 U-net编码器解码器网络参数
通过此种通道连接和下采样连接结合的方式可以进一步将不同任务的特征融合,促进各任务之间的转化,该方式与共有特征提取模块中的共有特征不同,在保留原有特征的情况下更能体现不同任务之间的联系,突出多任务特征之间的融合。
4.2 训练过程
本模块属于多输入多输出型网络,在训练中,需要将输出与数据库中对应的深度图像、语义分割图、表面向量图真值之间的关系建立损失函数,并通过减小损失函数来更新网络参数,经过迭代更新到损失函数收敛,得到训练好的网络。
在训练网络时,可以将本模块与共有特征提取模块统一训练,以便形成一个端到端的神经网络,即输入为单张RGB图像,输出为与其对应的深度图像、语义分割图、表面向量图。由于3个任务与第3节相同,故采用相同的损失函数进行约束,故不详细说明。
关于该模块训练的过程,本文通过直接在网络的输出端得到3个任务的图像并与其对应的真值之间设计损失函数,经过梯度下降的方式进行反向传播,从而对网络的参数进行更新,当损失函数收敛时,可完成训练。在本文算法的训练过程中,设定迭代次数为100,每次处理图像数量为4,初始学习率为10–4,每经过20次迭代更新学习率为原来的十分之一,最后在经过100次迭代后得到的收敛损失函数值为0.115 9。
5 实验结果及评价
本文实验使用的数据集,是基于NYU Depth V2数据集[14]建立的。并使用1 449组包含RGB图像、语义分割图像、深度图像来完成训练和测试,表面向量图像由文献[8]提出的方法将深度图像转换而成,并统一将图像的大小转换为320×240,与网络的输入一致。其中,795组用于训练,654组用于测试。每组训练图像通过10像素的上下左右平移再获得4组训练集增强训练的鲁棒性,即训练集包括3 975组RGB图像、语义分割图像、深度图像和表面向量图像,测试集为654组。
本文实验的环境为Ubuntu操作系统,编程语言为Python,网络框架为Pytorch 1.0.0,显卡为GTX 2080Ti,显存为11 G。其他实验具体参数见第3.2节和第4.2节的训练方法。
实验数据与其他实验的对比,首先在深度预测方面,本文从准确率和误差率2个方面进行结果评价,本文实验各个阶段的结果见表3,其中第一项单任务表示的是按基于CNN的深度预测模型进行的预测;第二项则是按第3节中使用多任务模型中共有特征提取模块进行深度图像预测的结果;第三项则是按第4节中加入多任务特征融合模块后的深度预测评价。表格中RMS(root mean squared error)表示均方根误差,REL(average relative error)表平均相对误差。
对于误差评价而言,误差率越小表面预测效果越好;反之,准确率越高说明预测结果更好,从结果中可以看出,多任务特征提取能有效地提取出共有特征,并提升深度预测的效果,而加入多任务特征融合模块后,则更能体现出提取特征的共有性和独有性,使得预测的结果更为准确,并且其他2个任务也能达到类似的提升效果。

表3 不同条件下的深度预测评价
语义分割和表面向量的预测结果见表4,其中,语义分割预测的评价标准为交并比函数(intersection over union,IoU),其是目标区域和预测区域交集和并集的比值,在本文中会将每一类别的IoU叠加,再进行平均,即均交并比函数(mean intersection over union, mean IoU),即
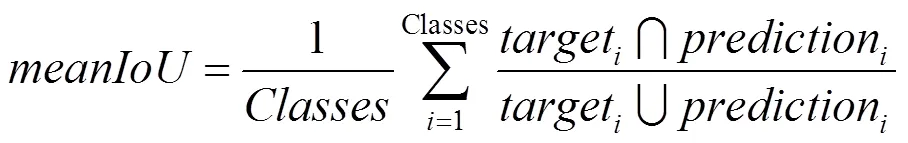
其中,Classes为图像中含有的类别个数。
另外,表面向量的评价标准为均方根误差(root mean square error,RMSE),即

从表3和表4可以看出,使用多任务模型能有效提升语义分割的准确率,降低表面向量预测的误差,进一步证明了共有特征提取模块和多任务特征融合模块不仅能有效提升深度预测的能力,还可以对语义分割和表面向量预测起到积极促进作用。

表4 不同条件下的语义分割和表面向量评价
表5为相同条件下本文算法与全卷积残差网络(fully convolutional residual networks,FCRN)[3]和DenseDepth[15]方法在深度预测方面的对比,从表中可以看出,所列举的方法无论在准确率上还是误差率上都能达到一个很好的水平。

表5 相同条件下的不同方法深度预测评价
图4~6分别为深度预测、语义分割、表面向量预测3个任务在本文实验中的部分可视化结果,其中图4包含了FRCN[3]方法,从可视化结果可以看出,本文算法基本达到各任务所需要求。

图4 深度预测可视化结果

图5 语义分割可视化结果

图6 表面向量预测可视化结果
6 总 结
本文提出了一种基于多任务模型的单目深度预测网络,通过与语义分割、表面向量预测2个任务一并训练,利用深度预测、语义分割、表面向量预测3个任务之间的相互联系来提升网络的训练效果。本文算法通过共有特征提取模块共有特征来提升深度预测结构性,再通过多任务特征融合模块来进一步区分各任务间的特征独特性和联系性,使得各个任务的预测效果能够进一步提升。实验证明,本文算法在各个模块的效果上均有提升,多任务特征提取和跨任务特征融合对网络预测深度值提供了帮助,通过对比实验也说明了本文算法的优越性。
[1] SAXENA A, CHUNG S H, NG A Y. Learning depth from single monocular images[C]//The 18th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2005: 1161-1168.
[2] SAXENA A, SUN M, NG A Y. Make3d: learning 3D scene structure from a single still image[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 31(5): 824-840.
[3] LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 4th International Conference on 3D Vision (3DV). Washington,DC: IEEE Computer Society Press, 2016: 239-248.
[4] CAO Y, WU Z F, SHEN C H. Estimating depth from monocular images as classification using deep fully convolutional residual networks[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(11): 3174-3182.
[5] GARG R, BG V K, CARNEIRO G, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue[C]//The 14th European Conference on Computer Vision. Heidelberg: Springer, 2016: 740-756.
[6] ZORAN D, ISOLA P, KRISHNAN D, et al. Learning ordinal relationships for mid-level vision[C]//2015 IEEE International Conference on Computer Vision. Washington,DC: IEEE Computer Society, 2015: 388-396.
[7] CASSER V, PIRK S, MAHJOURIAN R, et al. Depth prediction without the sensors: leveraging structure for unsupervised learning from monocular videos[C]//The 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 8001-8008.
[8] EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]//2015 IEEE International Conference on Computer Vision. Washington,DC: IEEE Computer Society, 2015: 2650-2658.
[9] MOUSAVIAN A, PIRSIAVASH H, KOŠECKÁ J. Joint semantic segmentation and depth estimation with deep convolutional networks[C]//2016 4th International Conference on 3D Vision (3DV). Washington,DC: IEEE Computer Society, 2016: 611-619.
[10] WANG P, SHEN X H, RUSSELL B, et al. Surge: surface regularized geometry estimation from a single image[C]//The 30th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2016: 172-180.
[11] GODARD C, MAC AODHA O, BROSTOW G. Digging into self-supervised monocular depth estimation[C]//2019 IEEE International Conference on Computer Vision. Washington,DC: IEEE Computer Society, 2019: 3828-3838.
[12] ZHANG Z Y, CUI Z, XU C Y, et al. Joint task-recursive learning for semantic segmentation and depth estimation[C]//The 15th European Conference on Computer Vision. Heidelberg: Springer, 2018: 235-251.
[13] ZHANG Z Y, CUI Z, XU C Y, et al. Pattern-affinitive propagation across depth, surface normal and semantic segmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 4106-4115.
[14] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images[C]//The 12th European Conference on Computer Vision. Heidelberg: Springer, 2012: 746-760.
[15] ALHASHIM I, WONKA P. High quality monocular depth estimation via transfer learning[EB/OL]. [2020-01-05]. https://arxiv.org/abs/1812.11941.
Research on depth prediction algorithm based on multi-task model
YAO Han, YIN Xue-feng, LI Tong, ZHANG Zhao-xuan, YANG Xin, YIN Bao-cai
(School of Computer Science and Technology, Dalian University of Technology, Dalian Liaoning 116024, China)
Image depth prediction is a hot research topic in the field of computer vision and robotics. The construction of depth image is an important prerequisite for 3D reconstruction. Traditional methods mainly conduct manual annotation based on the depth of a fixed point, or predict the depth based on binocular positioning according to the position of the camera. However, such methods are time-consuming and labor-intensive and restricted by factors such as camera position, positioning method, and distribution probability. As a result, the difficulty in guaranteeing high accuracy poses a challenge to subsequent tasks following the predicted depth map, such as 3D reconstruction. This problem can be effectively solved by introducing a deep learning method based on multi-task modules. For scene images, a multi-task model-based monocular-image depth-prediction network was proposed, which can simultaneously train and learn three tasks of depth prediction, semantic segmentation, and surface vector estimation. The network includes a common feature extraction module and a multi-task feature fusion module, which can ensure the independence of each feature while extracting common features, and guarantee the accuracy of depth prediction while improving the structure of each task.
computer vision; monocular depth prediction; multi-task model; semantic segmentation; surface normal estimation
TP 391
10.11996/JG.j.2095-302X.2021030446
A
2095-302X(2021)03-0446-08
2020-08-28;
2020-12-15
28 August,2020;
15 December,2020
国家自然科学基金项目(91748104,61972067,61632006,U1811463,U1908214,61751203);国家重点研发计划项目(2018AAA0102003)
National Natural Science Foundation of China (91748104, 61172007, 61632006, U1811463, U1908214, 61751203); National Key Research and Development Program (2018AAA0102003)
姚 翰(1994-),男,辽宁沈阳人,硕士研究生。主要研究方向为数字图像处理与三维重建。E-mail:yaohan@mail.dlut.edu.cn
YAO Han (1994-), male, master student. His main research interests cover digital image processing and 3D reconstruction. E-mail: yaohan@mail.dlut.edu.cn
杨 鑫(1984-),男,吉林四平人,教授,博士。主要研究方向为计算机图形学与视觉。E-mail:xinyang@mail.dlut.edu.cn
YANG Xin (1984-), male, professor, Ph.D. His main research interests cover computer graphics and vision. E-mail: xinyang@mail.dlut.edu.cn
