基于深度学习的图像本征属性预测方法综述
2021-07-12沙浩,刘越,2
沙 浩,刘 越,2
基于深度学习的图像本征属性预测方法综述
沙 浩1,刘 越1,2
(1. 北京理工大学光电学院,北京 100081;2. 北京电影学院未来影像高精尖创新中心,北京 100088)
真实世界的外观主要取决于场景内对象的几何形状、表面材质及光照的方向和强度等图像的本征属性。通过二维图像预测本征属性是计算机视觉和图形学中的经典问题,对于图像三维重建、增强现实等应用具有重要意义。然而二维图像的本征属性预测是一个高维的、不适定的逆向问题,通过传统算法无法得到理想结果。针对近年来随着深度学习在二维图像处理各个方面的应用,出现的大量利用深度学习对图像本征属性进行预测的研究成果,首先介绍了基于深度学习的图像本征属性预测算法框架,分析了以获得场景反射率和阴影图为主的本征图像预测、以获得图像中材质BRDF参数为主的本征属性预测及以获得图像光照相关信息为主的本征属性预测3个方向的国内外研究进展并总结了各自方法的优缺点,最后指出了图像本征属性预测的研究趋势和重点。
计算机视觉;计算机图形学;本征属性预测;本征图像预测;BRDF预测;光照预测;深度学习
真实世界的外观由光线作用在各个对象的几何形状之间发生反射、散射等一系列复杂交互作用所形成。在模拟真实世界进行计算机图像渲染时,需要首先将场景建模成具有材质属性的三角面片,然后通过基于光线追踪等渲染方法的渲染管线将来自光源的光线通过场景的反射、折射等一系列作用传播到成像平面上以形成二维计算机图像[1]。这些属性包括光照、几何形状、表面材质的反射率和场景的深度或法线等信息,决定着图像形成的本质,统称为图像的本征属性。为了产生新的二维图像,在计算得到图像的本征属性后首先需要对图像中的场景进行准确的三维重建[2],然后在三维空间中对场景进行处理并将处理后的场景重投影到成像平面上。通过控制图像的本征属性可以直接在二维图像中对图像外观进行三维化的更改,包括对材质进行替换、对图像进行重新光照等,因此本征属性预测在三维重建、增强现实(augmented reality, AR)/虚拟现实(virtual reality, VR)中有着广泛地应用。
根据需求的不同和实践的可行性,研究人员一般会将原始的多个本征属性参数进行简化或组合,形成新的本征属性参数。近年来研究人员普遍以获得场景的反射率和阴影图、以获得图像中材质双向反射分布函数(bidirectional reflectance distribution function, BRDF)参数及以获得图像光照相关信息为主的3个方向对本征属性进行预测。理论上图像的本征属性预测旨在解决一个基于渲染方程的逆映射问题。其不仅需要估计大量的本征属性参数,还要克服二维空间映射到三维空间的高维不适定性。而在实践中,经过大量训练的三维建模美术师们通常可以依靠自己的经验完成对二维图像本征属性的估测,因此让计算机模仿人类行为,获取二维图像中的本征属性参数也并非是一项不可能的工作。
传统算法大都从图像外观的形成出发,依靠某种先验完成对其他本征属性的预测。例如文献[3]将图像中的阴影看作是本征属性的先验知识,通过优化代价函数对图像场景的形状、光照和反射率进行最大概率估计,在假定图像中物体为朗伯模型的情况下取得了不错的结果。近年来出现的深度学习算法的综合性能在图像处理的很多领域都超过了以文献[3]为代表的传统算法,尤其对于这种不适定、欠约束问题,深度学习的效果更加显著。
深度学习旨在利用数据驱动的方式通过不断迭代优化损失函数,使卷积神经网络(convolutional neural network, CNN)模型拟合到一个可以解决特定问题的状态,其独特的结构模仿了生物神经元的连接方式,因此在许多问题上表现出类似于生物的智能性。图像的本征属性预测是图像渲染的逆向过程,显式的模型不足以建立其映射关系,而CNN可以看作是一个未知的“黑盒”,对于这种难以用数学模型解释的问题有着良好的适应性,因此,越来越多的研究人员将深度学习算法应用到了图像的本征属性预测中。
1 问题建模
深度学习是一种采用CNN作为模型的机器学习算法,与其他算法相比,在学习图像表示的层次上获得了突破,因而在与图像有关的各个领域广泛使用。在图像的本征属性预测方面,深度学习方法大多将单张或多张图像输入CNN,然后输出图像本征属性的预测值,通过计算预测值和真实值之间的损失函数,不断迭代优化网络参数,使特定模型达到可以完成对所需本征属性进行预测的状态[4]。深度学习算法主要包含网络结构、损失函数、数据集3个核心模块,对于不同的任务,这3个模块会有所不同。
应用在图像本征属性预测中代表性的网络结构主要有VGG-16[5]、深度残差网络[6]和Unet[7]等。文献[8]利用VGG变体网络,第一次实现了基于CNN的单幅图像深度预测。虽然深度预测[9]更多是作为计算机视觉的一大独立问题,但深度信息本质上代表了场景的几何参数,同属于图像的本征属性,因此深度预测也属于图像的本征属性预测。文献[10]利用深度残差网络进行迁移学习,预测出的单目图像深度信息在精度上超越了之前利用其他CNN进行预测的算法。结构上相互对称的Unet网络如图1所示,其对输入图像的计算过程类似于图像正逆渲染,因而基于此结构的网络在图像的本征属性预测上有着更为广泛地使用。
深度学习的损失函数与所完成的任务有关,在分类问题中,常用softmax等分类器结合交叉熵损失进行误差计算。而对于像素级的任务,常常使用L1,L2损失对预测图像和真实图像各个位置上的像素值进行误差计算。在图像本征属性的预测任务中,对于均匀一致的本征属性参数,通常可以将其看作一个范围值,进而转化为不同范围的分类问题[11-12],所以常常采用交叉熵损失计算误差。然而更多情况下,图像的本征属性参数并不会全局均匀且一致,因此更多将其视为一个像素级的图像到图像的任务。在大多数图像的本征属性预测中,还会引入重建损失[13-17]旨在将预测到的图像本征属性参数重投影并渲染生成新的图像,进而计算重建图像与原始输入图像之间的像素级误差。重建损失可以自动平衡每个参数在损失函数中所占的比重,让网络的收敛更符合渲染的物理性。
数据集的质量和数量在深度学习任务中起到了决定性的作用。真实数据集的制作一般采用众包的手段,通过人工注释和测量的方式产生数据集中的真实值标签。文献[18]利用Kinect深度摄像机对室内场景的深度进行测量,生成一个对应着场景深度和场景分割标签图的NYU depth v2数据集。然而在图像的本征属性预测任务中,获取真实场景的真实本征属性十分困难,难以应用生成真实标签数据集的传统方法。文献[19]通过众包的方式让用户对场景中的反射率进行判断,从而生成一个带有稀疏注释的本征属性数据集,但是其标签密度太小,训练出的网络可信度太差。图2所示的MIT intrinsic[20]数据集虽然测量了包含阴影、漫反射率和镜面反射分量的16个真实物体的本征属性参数,但是其规模远远不能满足图像本征属性预测任务的训练需要,因此许多工作常常将其用作测试集来衡量算法的性能。文献[21]利用大型的真实感游戏合成了像素级别的带有语义标签的数据集,该策略不仅减少了传统数据集制作上的困难,同时也提高了语义分割模型在真实图像预测任务中的精度,证明了合成数据集的可用性。随着真实感渲染技术的发展,渲染出照片级别的合成图像已经成为可能,研究人员可以程序化地控制本征属性参数进而合成不同的图像,这样不仅得到了可靠的数据集,还大大减轻了人力负担,因此在图像本征属性预测中,一般都会采用合成数据集对网络进行训练。
2 以获得场景的反射率和阴影图为主的本征图像预测
文献[22]提出图像亮度的不连续性主要是由反射率变化造成的,而图像的其他起伏变化来源于场景中阴影的改变。文献[23]提出对于一张彩色场景图像,可以将其简单地分解为对应场景中不同位置均匀漫反射率的反射率图和对应光照作用于场景几何结构后的阴影灰度图的逐像素乘积,即
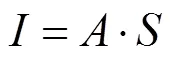
之后,国内外研究人员开始开展针对彩色图像的本征图像预测研究工作。文献[24]利用CNN将单张图像分解为反射率图和阴影图,在精度、泛化性等方面都优于文献[25]和[26]等基于深度图辅助的传统算法。作者利用文献[8]提出的多尺度深度预测网络的变体,通过计算和的损失函数之和迭代优化模型。由于真实反射率和阴影的强度不是绝对的,不能施加标准L2误差对网络进行约束,所以其使用了尺度不变性L2误差[8]为
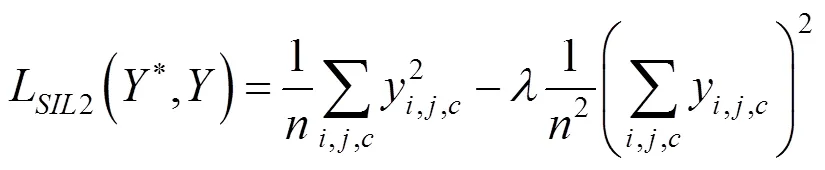
其中,和为图像的像素坐标位置;为RGB通道索引;为要计算的像素数目。为尺度误差不变的平衡项,其值为0时,损失函数变为简单的最小平方差;其值为1时,损失函数变为尺度不变误差。文献[24]使用通过游戏的合成的MPI Sintel 数据集(图3)和MIT intrinsic数据集对网络进行联合训练,虽然成功分解出了和,但其数据集的质量和网络的简单结构还是限制了模型的泛化性能和精度。为此文献[27]在直接预测本征图像网络的基础上,并行地添加了一个输入边缘轮廓图像、输出反射率指导图的指导网络,再将基础网络预测得到的反射率图与指导图像输入区域滤波器,从而得到最终的反射率图。文献[27]还为不同类型的数据集设置了不同的网络框架,将合成数据集与IIW真实数据 集[19](图3)同时加入网络进行联合训练,进而改进预测结果。文献[13]将IIW数据集加入网络训练过程的同时,也为此任务制作了一个基于物理渲染的大规模场景本征图像的CGI数据集(图3)。文献[13]在采用尺度不变L2误差损失函数的基础上,利用稀疏注释数据集的约束设置了对阴影、反射率的平滑损失和基于原始图像重建损失,结果表明高质量数据集的加入大大改善了模型的质量,不同数据集的联合训练和其他损失的约束也一定程度上提升了模型的表现。
合成高质量的数据集需要耗费大量的时间和资源,为了减轻对大规模数据集的依赖,文献[28]提出一个结合了预测与重渲染的CNN网络框架,通过2个编码器到解码器结构的网络分别进行本征图像的预测和图像的重渲染,并利用自增强的训练策略让网络在预测本征图像的同时生成新的数据对,进而对整体网络进行半监督训练。文献[29]提出一个组合2个可以共享参数的双流并行CNN架构,通过输入2张不同照度的彩色图像,将训练模式从半监督进一步改进为无监督,让网络可以在没有本征图像真实值的情况下完成训练,最终预测出本征图像。无监督的训练模式不需要真实值的对应标签,因而可以摆脱合成数据集对训练的约束,但真实图像包含的光照、几何、材质变化更复杂,对本征图像的预测难度更高。文献[30]将同一场景的多张不同真实图像作为输入,对网络进行无监督训练。其引入法线图和全局光照代替阴影与反射率进行渲染生成重建图像,计算重建损失,还通过多图像生成的深度图与反射率对图像进行交叉投影从而计算交叉投影损失。该方法不仅恢复出了传统的本征图像,还引入了全局光照,因而可以开发出如重光照一样的新应用。由于该方法引入的光照只包含全局光照,应用于户外图像时重建误差较小,但对包含丰富局部光照变化的室内图像有着明显的限制。为此,文献[31]在预测全局光照和法线图之后对其进行渲染生成阴影,再将阴影加入第二个网络进行局部光照的细化预测,最后再将细化后的法线和光照进行重渲染,进而生成阴影图,加强了其在局部范围内的精细度。文献[32]则在文献[31]的基础上将局部光照和全局光照进行集成,并将预测法线的网络特征添加至本征图像预测中,在阴影的平滑度和反射率的精细度上均比文献[13]和[31]中的算法要好(图4)。

图3 本征图像分解常用数据集示例(红色框选中区域代表RGB输入图像)
上述基于朗伯模型的本征图像预测算法忽略了镜面反射等真实场景中的复杂外观效果,所以其使用范围十分受限。为此文献[33]改进了本征图像分解的表达形式,为其增加了镜面反射图,即
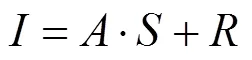
其选择了ShapeNet[34]数据库中具有镜面反射的特定类别模型,利用Mitsuba[35]渲染器进行图像合成,创建了一个增添了镜面反射图的基于非朗伯模型物体的本征图像数据集。在网络结构方面,文献[33]为每个本征图像提供了共享的编码器和独立的解码器,但鉴于不同的本征属性参数互相关联,其在网络的后半部分还添加了交织的连接以便不同的解码器共享参数。该方法的模型在预测精度和泛化性上表现良好,但是遇到具有高频镜面反射的物体时,预测出的反射率和阴影图可能会出现伪影。尽管当前基于深度学习的方法在定量结果的比较中表现出优异的性能,但基于物理的传统算法在很大程度上仍然有着重要的意义。文献[36]基于文献[22]中的假设,将传统算法和深度学习相结合,在输入原始图像的基础上添加梯度图预测其反射率与阴影的梯度图,接着将反射率与阴影的梯度图与原始输入图像相结合对CNN进行训练,进而预测出细节更丰富的本征图像。
图3展示了本征图像分解常用数据集示例,其中IIW数据集包含5 000多张真实RGB图像和人为相对反射率判断图;MPI Sintel数据集包含13 000多张合成的RGB图像和相对应的反射率图、深度图、光流图;CGI数据集包含25 000多张合成的RGB图像和对应的反射率图;SAW数据集[37]包含了5 200多张阴影变换的3类注释图像。综合来看,数据集对本征图像分解的影响最大,而损失函数及其他训练策略的添加会不同程度地提升网络的性能。表1对上述本征图像分解的算法在几方面进行了比较,观察不同数据集上的表现来看,网络在相同数据集下训练和测试时,结果会比跨数据集测试要好很多,进一步表明现有数据集之间的差异性较大,网络不能在某一数据集上训练出良好的泛化性,这种情况在跨越合成数据集和真实数据集时尤为明显。有些算法在预测时还会添加其他方法,进而增加对网络训练的约束,提升网络的性能,如文献[27]中将预测后的本征图像输入区域滤波器进行平滑,获得了表1内最好的量化结果。引入其他信息进行交叉预测、采用自监督的训练模式也在一定程度上增加了可用数据集的范围和模型的泛化性。目前的本征图像假设较为简单,考虑非朗伯模型假设的算法也大多停留在单个物体图像的预测中,因而当遇到模型假设外的外观效果时,往往会预测出一些错误的本征图像。

图4 真实图像中不同算法的本征图像分解效果对比,绿色框选中的是图像放大后的细节特征((a)输入图像;(b)文献[13];(c)文献[31];(d)文献[32])

表1 本征图像分解代表性算法比较
注:WHDR和MSE的数值越低,代表算法性能越好
3 以获得图像中材质BRDF参数为主的本征属性预测
图形学中一般用BRDF[40]对材质表面进行建模,因此图像中材质的BRDF参数代表其本征属性。材质外观越复杂,表示其BRDF的形式就越繁琐[41-44],参数就越多。因此在传统中,材质BRDF参数的预测需要借助复杂的机械工具完成[45-46],相比之下,基于图像的材质BRDF参数预测极大地节约了成本。在基于图像的BRDF参数预测算法中,基于CNN的算法在轻量性和准确性权衡后的综合性能上往往领先于其他算法[47-48],因此成为当下BRDF预测的研究热点。
在获取图像中材质的BRDF参数时,研究人员通常会将光照加以限制,并将平行成像平面的平面材质图像作为输入,进而简化预测难度。文献[14]在U-net的网络结构基础上添加了一个为捕获和传播全局信息而定制的并行网络层,并基于Cook-Torrance模型[42]将BRDF模型参数设为法线、漫反射率、粗糙度和镜面反射率,制作了大型数据集(图5),实现了对手持闪光灯照明平面的单张材质图片BRDF的预测。同时提出的全局网络层让每一对信息交换在每个像素之间形成非线性依赖关系,通过在不同区域之间重复传输局部信息可以很好地减轻一些局部高频信息所造成的伪影。文献[15]则将一张开闪光灯手机拍摄的平面图像与反映像素亮度的灰度图作为输入,并在BRDF预测CNN的基础上加入一个将材质分类结果用作权重的分类器,对不同材质的BRDF预测进行平均,最后再利用动态条件随机场(dynamic conditional randomness field, DCRF)依次对预测出的本征属性图像进行优化,得到最终的BRDF参数图。虽然基于单张平面材质图像的BRDF预测非常便捷,但是单张图像不能展现完整材质的信息,一些重要的物质效果常常会被忽略。因此,文献[49]利用最大池化层将文献[14]中的网络输入从单张扩展为多张图像(图5),利用来自多张不同光照条件和视角图像中更完整的局部信息和全局信息,使预测结果的细节更丰富,伪影更少。文献[16]利用文献[14]中的网络首先将输入图像分解为BRDF参数图,然后再将其输入所提出的自动编码器CNN和重渲染框架进行级联优化,与以往的直接优化方法不同,该方法在本质上优化了自动编码器中关于参数的潜在向量,相较于文献[14]和[15],在BRDF输出的精细度和重建质量上都有了明显地提升。具体来说,文献[15]相对文献[14]法线预测更加细致,但粗糙度和镜面反射图的预测会出现错误,而文献[16]相对上述2种方法,预测出的各个分量都有所提升;文献[49]相较于文献[14]和[15]预测结果的局部细节更清晰,伪影更少(图6)。

图5 文献[14]中的网络结构和数据集(左)及文献[15]和[16]、文献[49]中改进后的多输入网络结构(右)
上述方法多以高质量、大规模的数据集为基础,但是生成带有对应BRDF参数标注的数据集往往会耗费大量的资源与时间。为此文献[17]制作了包含小规模的带有对应BRDF参数图标签和大规模只包含材质照片的数据集,并提出“自增强”的弱监督训练模式,让网络可以在训练过程中生成数据集以减少对标记数据集规模依赖的同时预测出高精度的BRDF参数图。但是自增强策略需要少量的标记数据为网络提供一个良好的潜在空间,且标记数据和未标记数据的分布也对网络性能产生了巨大影响,所以文献[50]在文献[17]的基础上,首先利用神经纹理合成算法[51]和随机生成的方式从未标记图像中构造BRDF参数图,然后再用自增强策略对网络进行训练。该方法在不需要标记数据集的同时,其网络性能方面也超越了文献[17]中的“自增强”算法。上述方法所预测的平面材质外观并不会随视角产生变化,但现实中的许多材质表面却不是这样(如金属拉丝、天鹅绒等)。为此文献[12]制作了一个各向异性的材质平面数据集(图8),并将包含30°和90°拍摄的2组做了单应化处理的图像输入一个组合嵌套型CNN,恢复出了包含各向异性性质、折射率以及反射多色性等新的本征属性。

图6 文献[14–16]和文献[49]对相同数据的预测结果
基于平面材质的BRDF预测简化了渲染方程中光照与几何结构的复杂积分,也降低了预测难度,而预测图像中三维物体的BRDF更具有挑战性。文献[11]设计了2个轻量级的网络可以从多张场景图和深度图的输入中获取场景中三维物体的7参数BRDF。文献[52]利用级联式的CNN依次训练其不同的BRDF参数,最终可以从包含三维物体的单张图像中预测出基于非朗伯模型的BRDF参数,且网络模型同样可以实时对场景中的物体材质进行提取,但当遇到复杂材质和彩色照明场景时,会出现错误。文献[53]提出了组合2个CNN的无监督网络框架,可以从点光源照亮拍摄的多张二维图像中预测出三维物体的表面法线和其BRDF。该方法针对特定场景特定训练,不需要数据集的支持,降低了数据生成的成本,但需要为每个不同的对象训练不同的网络,因此在实时性上有着很大的限制。为了计算出更精确的重建损失,文献[54]提出了一个模拟全局光照渲染的CNN和一个用于预测环境光照明的CNN,通过二者组合合成最终的重建图像。作者采用级联式的网络架构,为次级网络输入来自上一阶段输出的图像、BRDF、光照预测及渲染损失,通过依次训练级联网络恢复单张RGB图像中三维物体的BRDF参数和法线。基于图像的BRDF参数预测意义在于可以便捷地重建出图像中物体的三维特征,但良好的预测结果往往伴随着大型的网络和复杂的输入,因此如何将其融入应用是研究人员的一大难题。文献[55]利用多个轻量级的网络以级联的方式在合成数据集上训练,通过输入一张闪光灯照亮和一张未照亮的图像并引入融合卷积层合并2张图像中的信息,完成对其BRDF、光照、深度及法线的粗预测。在粗预测后作者将粗预测后的重建图像与原始图像的差值和粗预测结果共同输入第二级精炼网络以细化预测结果,所采用的任务分离和阶段式预测方法不但可以获得更好的结果,还能更便捷地部署到应用中,有着很强的实用性。
BRDF参数预测难度随预测目标的复杂度逐步上升,上述方法预测出的最复杂场景也仅包含一个三维物体,为此文献[56]制作了一个包含BRDF、光照、法线和深度的大型场景数据集(图7),以完成多任务联合预测。该网络采用多层级联的方式,通过多网络的逐步预测与精炼最终得到了所需的预测图像。这一工作相较之前基于场景的本征图像预测更细致,但较之前基于单个物体的BRDF预测更复杂,可以获得更好的效果,同时为以后的研究工作提供了方向。
BRDF参数预测的不同主要是与数据集有关,图7展示了BRDF参数预测中代表性的数据集,从中可以看出不同数据集有不同的侧重点,材质的微观信息越复杂,其几何信息就越简单。但是总体来看,数据集的制作在同时向微观和几何信息复杂度的方向发展。表2比较了BRDF参数预测的代表性算法,整体来看数据集决定了网络的预测结果,当缺乏数据集时可以利用无监督或自监督策略训练网络。许多算法通过引入多张输入图像为网络提供更完整的外观信息,进而改善预测结果。许多算法还通过引入几何信息和光照信息以及联合交叉预测的方式提升预测结果。虽然利用CNN预测BRDF参数有了一定进展,但现有的算法还存在一些共通的问题有待解决:在遇到某些特殊效果或是高频信息时,图像中材质BRDF参数的预测会出现较大错误(如图6右图反射率预测出现的伪影),同时基于CNN的方法预测出的大多数BRDF参数形式也较为简单,对真实材质的重建效果表现欠佳。相较于平面材质的BRDF预测,获取图像中三维物体和场景的BRDF参数更为困难,因此预测得到的BRDF模型更简单,精度也略差。

图7 不同类别BRDF参数预测数据集示例,其中红色框内是数据集的输入RGB图像,紧随其后的是对应的BRDF参数标签

表2 BRDF参数预测代表算法比较
4 以获得图像光照相关信息为主的本征属性预测
作为图像本征属性的一部分,光照的位置、方向、强度、数目和色彩等因素都极大地影响了图像的外观。分离并替换原始光照可以为图像带来三维化的效果,在AR中加入光照渲染后的虚拟物体也会更加真实,因此对光照信息的预测一直以来都是研究人员非常重视的问题。
已有的光照预测算法大多依赖于几何线索[57]的提取或是图像先验信息[58-59]的输入,随着深度学习在图像本征属性分解上的应用,研究人员对光照相关信息进行了不同程度的解耦与预测。文献[60]首先利用低动态范围(low dynamic range, LDR)数据集对CNN进行训练完成对光照方向的预测,然后利用高动态范围(high dynamic range, HDR)数据集对之前预训练的CNN进行迁移学习完成对光照强度的预测,从而预测出室内环境光照的HDR图像。而文献[61]则利用CNN完成了对户外HDR环境光照图像的预测。并基于户外光照图的参数假设,预测出了输入图像中的太阳位置参数、大气条件参数和相机参数,进而利用预测参数合成相应的HDR环境光照图。如图8所示,文献[60]和[61]都利用恢复出的HDR环境光照图向二维图像插入虚拟物体,可以看出加入光照渲染后的虚拟物体更加真实,提升了AR应用的效果。相较于复杂场景图像,只包含单个物体的图像所拥有的光照信息较少,因此其预测难度更大。文献[62]首先只利用环境光照图训练一个可以将环境光照图压缩成多维潜在向量空间的“编码器到潜在空间再到解码器”结构的CNN,再将该潜在空间层和解码器层与新的编码器层相连,输入环境光照图渲染后的单个物体图和其法线图,通过添加原始环境光照图和场景图的潜在空间向量的误差损失,对新的网络进行训练,使最后的网络模型预测出单个物体图像中的室内环境光照图。文献[63]对输入图像的场景不做室内或户外的限制,作者采用3个级联的CNN,其中第一个网络首先对输入图像进行反射率颜色的预测;然后将预测结果和原始图像输入第二个网络进行光照阴影图的预测,与以往不同的是其预测了2个不同光照形成的阴影图,最后将阴影图和原始图像输入第三个CNN,使原始图像中的光照分离,形成2张在不同光照作用下的场景图,其实现了对原始输入图像光源位置的预测与解耦。文献[64]提出了一种基于CNN的人像重照明系统。人的皮肤具有的散射等复杂物理性质会导致合成数据与真实数据过于偏差,因此特为此任务设计了专用的采集设备并制作了真实的数据集。其所设计的CNN不仅可以预测出场景的光照图,还能实现人像的重照明,但是当输入图像包含硬阴影、尖锐的镜面反射或饱和像素时,预测结果仍然有着较大错误。
在对光照信息进行预测的同时,许多算法也常常会将其他本征属性一并预测出来。文献[65]利用CNN不仅将图像按照光照反射方向分为上下左右4个部分,还将单张图像的漫反射率、阴影、辐照度和镜面高光一并分解出来。文献[66]则在得到图像中材质反射贴图[67]的前提下,利用2个独立的CNN从反射贴图中预测出7个基于冯模型的材质BRDF参数和分辨率为原始图像一半的场景光照图。通过改进文献[66]中的方案,文献[68]又利用2个CNN,直接和间接地获取了输入图像中材质的反射贴图,再利用文献[66]中的CNN结构预测出了图像的场景光照信息和材质信息。文献[69]为了关注图像中一些常被忽略的复杂光照效应,通过引入直接渲染器和一个基于学习的“复杂光照残余外观”渲染器对图像进行重建进而计算重建损失,在用合成数据集对网络进行初始化预训练后,引入真实数据集对网络进行自增强训练,最后预测出场景光照图的同时,还预测出了更精细的场景的法线和反射率图。文献[70]将传统的蒙特卡洛渲染器可微分化,并将其嵌入到CNN后端,通过训练的方式逆向求解场景的光照信息和BRDF参数。该方法可以正确地估计出场景中的发光器,但当场景中不存在发光器时,可能会出现错误的预测结果。

图8 虚拟物体插入((a)文献[60]中的虚拟物体插入效果;(b)文献[61]中的虚拟物体插入效果)
光照信息除了被编码成光照图以外,还可以其他的形式表示。文献[30]利用9参数的球谐函数表示户外光照信息,通过CNN将其参数和本征图像一同恢复出来。但其采用的光照模型只能较好地表示全局光照,对于丰富的局部光照表现欠佳。为此,文献[31]在表示全局光照的基础上添加局部光照的残余项,通过阶段性的预测将全局光照信息和局部光照信息通过级联式CNN依次恢复出来,得到了更细致的光照信息。虽然文献[31]预测出的光照信息非常细致,但包含了大量的参数,为此,文献[32]将全局光照和局部光照进行集成,以一个照明矢量图的形式编码丰富的室内光照信息,以预测出本征图像为最终结果,连带地将光照矢量图预测出来,以更少的参数表示了更细致的光照。文献[56]利用各向同性球面高斯函数,以较少的参数近似了所有频率的照明。其用2个分支的网络分别预测图像的空间变化双向反射分布函数(spatially-varying bi-directional reflectance distribution function, SVBRDF)参数和光照信息,并将预测出的光照信息与SVBRDF进行重渲染输入下一相同的级联网络结构进行进一步的精炼,进而逐级恢复出场景的光照信息和SVBRDF。
图9展示了不同算法用来表示光照模式的数据集,可以看出随着表示形式趋于复杂,包含的光照细节在增加。表3比较了光照相关信息预测的代表性算法,可以看出在对不同场景进行光照预测时,因为场景的特殊性,往往要对光照进行不同形式的编码,以参数最少、表达效果最好的原则设计出最适合该场景的光照模式表示,如文献[61]利用天空光模型中的几个参数就可以预测出良好的户外光照信息,实现虚拟物体插入的重渲染应用。整体来看,利用CNN直接恢复出场景光照信息往往比较困难,其应用范围也较窄,更多的工作是将光照作为目标信息之一,连带预测出其他的目标属性。从许多算法的结果可知,联合预测图像的其他本征属性可以在几个预测目标之间相互促进,同时提高光照预测和其他本征属性预测的效果。但对光照相关信息预测仍然存在一些现实问题,比如现实中户外光照和室内光照本身存在较大差异,因而一般算法也难以同时在室内和户外光照条件下恢复出效果一样的光照信息。

图9 不同光照表示数据集示例,其中红色框选中的是输入图像,未选中的是对应光照信息标签

表3 光照相关信息预测代表算法比较
5 总结和展望
在基于深度学习的图像本征属性预测任务中,数据集、网络结构和损失函数的设计是每个算法的核心。鉴于预测对象的不同,许多工作都为各自的任务开发出了独有的数据集,且数据集的数目与质量往往决定了模型的鲁棒性和泛化性能。在网络结构方面,对于图像到图像的任务,最常采用以编码器到解码器结构为基础的变体CNN,为了缓解单个网络的预测压力,通常还会采用多网络并行或级联的方式增强整体算法的预测能力;而对于基于数字参数的本征属性预测,网络通常采用相似于分类网络的下采样结构。在损失函数方面,大多数工作都将独立参数的误差与预测参数重渲染后的重建误差相结合,根据数据集类型和所要预测对象性质的不同,会添加额外的损失来约束网络训练,使预测结果在细节上更进一步。总之,本征属性预测在任务上不是独立的,越来越多的工作将更多的本征属性加入到网络预测中,原因在于各个本征属性之间有着不可分割的关系,通过逐级或联合预测本征属性相当于为每个单独的预测任务额外提供多个先验知识,这些先验知识不仅可以降低网络预测难度,还可以提升网络预测效果。在实际中,某些本征属性可以通过物理采集等方法获得,但有些却不能,因此许多工作在训练时通过采用多个数据集联合、多个训练模式共同训练的策略来提高网络在真实图像中的表现和不同类别图像任务中的泛化能力。
从近年图像本征属性预测任务的研究状况来看,所要预测的图像复杂度逐渐增加,预测出的本征属性参数在数目增多的同时,预测精度方面也有所提高。即使这样,依然存在如下问题:数目和类型太少的训练的数据集会导致网络的泛化性能变差,当网络遇到数据集之外的图像时,结果表现往往不佳;若输入图像中存在如镜面高光等高频信息时,预测出的本征属性图往往会出现伪影;若图像中存在一些复杂的外观效果时,预测结果也会出现错误的表示;大多数任务在开始前都需要有一定的约束,如图像采集步骤往往需要在特定条件下完成;分解质量的增加意味着模型复杂程度也将增加,复杂模型的大小和计算时间限制了其实践任务中的可行性。为了解决上述问题,未来的工作中,可以制作规模更大、质量更高的数据集用来解决过拟合问题,也可以将更多不同类型的数据集加入训练,提升模型的泛化能力。可以通过输入更多图像以展现更完整的图像场景信息,进而增加网络对图像场景的理解力,减少伪影等错误信息出现的概率。为了降低网络对大规模合成数据集的依赖和真实数据集的缺乏,可以利用半监督、无监督等策略让网络在没有图像对应目标标签的情况下进行训练,提高网络在真实数据上的表现。为了让算法更好地应用到实践中去,必须对模型进行“瘦身”,在轻量性和准确性上做权衡,可以通过增加网络个数降低单个网络大小,将整体网络预测分解成子网络预测,进而提升网络模型的可部署性。也可以依靠5G的快速传输能力,将网络计算加入云平台,从而减轻对网络模型轻量化的需求[71-72]。在设计损失函数时,要谨慎选择各个独立参数的权重,要依据数据集和网络结构的不同为每个任务设置最合适的损失。传统的基于滤波器、统计特征等图像处理方法虽然不能直接解决本征图像预测问题,但通过将传统算法作为指导和约束引入CNN预测,可以大大降低网络训练的时间,提升网络的预测效果。最后在预测结果的优化方面,在使用如DCRF等传统数学模型的同时,还可考虑用CNN对预测结果的细节[73]进行优化。
虽然深度学习在图像本征属性预测中已经获得了广泛的应用,但在下述特殊的图像外观领域仍有待开拓:①具有复杂物理效应的表面外观图像上,如具有强衍射效应的材质表面外观图像、多层光传输的材质的表面外观图像等;②具有复杂光照效果的场景图像上,如彩色光照明的场景图像、具有强烈折射衍射等效应的场景图像等;③带有高频信息外观的图像上,如具有尖锐边缘信息的图像和过强镜面反射外观的图像等。在未来对具有这些特殊外观图像进行本征属性数据集的制作、新训练策略和网络结构的引入、更合理有效的损失函数及约束条件的设置有望成为基于深度学习对本征属性预测的新研究趋势和热点。
[1] GUARNERA D, GUARNERA G C, GHOSH A, et al. BRDF representation and acquisition[C]//The 37th Annual Conference of the European Association for Computer Graphics : State of the Art Reports. Goslar: Eurographics Association, 2016: 625-650.
[2] 张志林, 苗兰芳. 基于深度图像的三维场景重建系统[J]. 图学学报, 2018, 39(6): 1123-1129.
ZHANG Z L, MIAO L F. 3D scene reconstruction system based on depth image[J]. Journal of Graphics, 2018, 39(6): 1123-1129 (in Chinese).
[3] BARRON J T, MALIK J. Shape, illumination, and reflectance from shading[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 37(8): 1670-1687.
[4] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[5] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2020-08-02]. https://arxiv.org/abs/1409.1556.
[6] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press 2016: 770-778.
[7] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Heidelberg: Springer, 2015: 234-241.
[8] EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2650-2658.
[9] 毕天腾, 刘越, 翁冬冬, 等. 基于监督学习的单幅图像深度估计综述[J]. 计算机辅助设计与图形学学报, 2018, 30(8): 1383-1393.
BI T T, LIU Y, WENG D D, et al. Survey on supervised learning based depth estimation from a single image[J]. Journal of Computer-Aided Design and Computer Graphics. 2018, 30(8): 1383-1393 (in Chinese).
[10] LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 4th International Conference on 3D Vision (3DV). New York: IEEE Press, 2016: 239-248.
[11] KIM K, GU J W, TYREE S, et al. A lightweight approach for on-the-fly reflectance estimation[C]//2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 20-28.
[12] VIDAURRE R, CASAS D, GARCES E, et al. BRDF estimation of complex materials with nested learning[C]//2019 IEEE Winter Conference on Applications of Computer Vision (WACV). New York: IEEE Press, 2019: 1347-1356.
[13] LI Z Q, SNAVELY N. Cgintrinsics: better intrinsic image decomposition through physically-based rendering[C]//2018 European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 371-387.
[14] DESCHAINTRE V, AITTALA M, DURAND F, et al. Single-image SVBRDF capture with a rendering-aware deep network[J]. ACM Transactions on Graphics, 2018, 37(4): 1-15.
[15] LI Z Q, SUNKAVALLI K, CHANDRAKER M. Materials for masses: SVBRDF acquisition with a single mobile phone image[C]//2018 European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 72-87.
[16] GAO D, LI X, DONG Y, et al. Deep inverse rendering for high-resolution SVBRDF estimation from an arbitrary number of images[J]. ACM Transactions on Graphics., 2019, 38(4): 1-15.
[17] LI X, DONG Y, PEERS P, et al. Modeling surface appearance from a single photograph using self-augmented convolutional neural networks[J]. ACM Transactions on Graphics, 2017, 36(4): 1-11.
[18] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images[C]//2012 European Conference on Computer Vision. Heidelberg: Springer, 2012: 746-760.
[19] BELL S, BALA K, SNAVELY N. Intrinsic images in the wild[J]. ACM Transactions on Graphics, 2014, 33(4): 1-12.
[20] GROSSE R, JOHNSON M K, ADELSON E H, et al. Ground truth dataset and baseline evaluations for intrinsic image algorithms[C]//2009 IEEE 12th International Conference on Computer Vision. New York: IEEE Press, 2009: 2335-2342.
[21] RICHTER S R, VINEET V, ROTH S, et al. Playing for data: ground truth from computer games[C]//2016 European Conference on Computer Vision. Heidelberg: Springer, 2016: 102-118.
[22] LAND E H, MCCANN J J. Lightness and retinex theory[J]. Journal of the Optical Society of America, 1971, 61(1): 1-11.
[23] BARROW H, TENENBAUM J, HANSON A, et al. Recovering intrinsic scene characteristics[J]. Computer Vision Systems 1978, 2(3-26): 2.
[24] NARIHIRA T, MAIRE M, YU S X. Direct intrinsics: learning albedo-shading decomposition by convolutional regression[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2992-2992.
[25] LEE K J, ZHAO Q, TONG X, et al. Estimation of intrinsic image sequences from image+ depth video[C]//2012 European Conference on Computer Vision. Heidelberg: Springer, 2012: 327-340.
[26] CHEN Q F, KOLTUN V. A simple model for intrinsic image decomposition with depth cues[C]//2013 IEEE International Conference on Computer Vision. New York: IEEE Press, 2013: 241-248.
[27] FAN Q N, YANG J L, HUA G, et al. Revisiting deep intrinsic image decompositions[C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8944-8952.
[28] JANNER M, WU J J, KULKARNI T D, et al. Self-supervised intrinsic image decomposition[EB/OL]. [2020-09-08]. https://arxiv.org/abs/1711.03678.
[29] MA W C, CHU H, ZHOU B L, et al. Single image intrinsic decomposition without a single intrinsic image[C]//2018 European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 201-217.
[30] YU Y, SMITH W A P. InverseRenderNet: learning single image inverse rendering[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 3155-3164.
[31] ZHOU H, YU X, JACOBS D W. GLoSH: global-local spherical harmonics for intrinsic image decomposition[C]// 2019 IEEE International Conference on Computer Vision. New York: IEEE Press, 2019: 7820-7829.
[32] LUO J D, HUANG Z Y, LI Y J, et al. NIID-Net: adapting surface normal knowledge for intrinsic image decomposition in indoor scenes[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(12): 3434-3445.
[33] SHI J, DONG Y, SU H, et al. Learning non-lambertian object intrinsics across shapenet categories[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1685-1694.
[34] CHANG A X, FUNKHOUSER T, GUIBAS L, et al. Shapenet: an information-rich 3D model repository[EB/OL]. [2020-05-27]. https://arxiv.org/abs/1512.03012.
[35] JAKOB W. Mitsuba [EB/OL]. [2020-05-27]. https://www. mitsuba-renderer. org.
[36] BASLAMISLI A S, LE H A, GEVERS T. CNN based learning using reflection and retinex models for intrinsic image decomposition[C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6674-6683.
[37] KOVACS B, BELL S, SNAVELY N, et al. Shading annotations in the wild[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6998-7007.
[38] LI Z Q, SNAVELY N. Megadepth: learning single-view depth prediction from internet photos[C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 2041-2050.
[39] VASILJEVIC I, KOLKIN N, ZHANG S Y, et al. DIODE: a dense indoor and outdoor Depth dataset[EB/OL]. [2020-07-19]. https://arxiv.org/abs/1908.00463.
[40] NICODEMUS F E, RICHMOND J C, HSIA J J, et al. Geometrical considerations and nomenclature for reflectance[J]. NBS Monograph, 1992, 160: 4.
[41] PHONG B T. Illumination for computer generated pictures[J]. Communications of the ACM, 1975, 18(6): 311-317.
[42] COOK R L, TORRANCAE K E. A reflectance model for computer graphics[J]. ACM Transactions on Graphics, 1982, 1(1): 7-24.
[43] WARD G J. Measuring and modeling anisotropic reflection[C]//The 19th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 1992: 265-272.
[44] ASHIKMIN M, PREMOžE S, SHIRLEY P. A microfacet-based BRDF generator[C]//The 27th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 2000: 65-74.
[45] GHOSH A, ACHUTHA S, HEIDRICH W, et al. BRDF acquisition with basis illumination[C]//2007 IEEE 11th International Conference on Computer Vision. NewYork: IEEE Press, 2007: 1-8.
[46] BEN-EZRA M, WANF J P, WILBURN B, et al. An LED-only BRDF measurement device[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Presss, 2008: 1-8.
[47] DUPUY J, HEITZ E, IEHI J C, et al. Extracting microfacet-based BRDF parameters from arbitrary materials with power iterations[J]. Computer Graphics Forum, 2015, 34(4): 21-30.
[48] AITTALA M, WEYRICH T, LEHTINEN J. Two-shot SVBRDF capture for stationary materials[J]. ACM Transactions on Graphics, 2015, 34(4): 110:1-110:13.
[49] DESCHAINTRE V, AITTALA M, DURAND F, et al. Flexible SVBRDF capture with a multi‐image deep network[J]. Computer Graphics Forum, 2019, 38(4): 1-13.
[50] YE W J, LI X, DONG Y, et al. Single image surface appearance modeling with self‐augmented cnns and inexact supervision[J]. Computer Graphics Forum, 2018, 37(7): 201-211.
[51] AITTALA M, AILA T, LEHTINEN J. Reflectance modeling by neural texture synthesis[J]. ACM Transactions on Graphics, 2016, 35(4): 1-13.
[52] MEKA A, MAXIMOV M, ZOLLHOEFER M, et al. Lime: live intrinsic material estimation[C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6315-6324.
[53] TANIAI T, MAEHARA T. Neural inverse rendering for general reflectance photometric stereo[EB/OL]. [2020-06-11]. https://arxiv.org/abs/1802.10328v2.
[54] LI Z Q, XU Z X, RAMAMOORTHI R, et al. Learning to reconstruct shape and spatially-varying reflectance from a single image[J]. ACM Transactions on Graphics, 2018, 37(6): 1-11.
[55] BOSS M, JAMPANI V, KIM K, et al. Two-shot spatially-varying BRDF and shape estimation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 3982-3991.
[56] LI Z Q, SHAFIEI M, RAMAMOORTHI R, et al. Inverse rendering for complex indoor scenes: shape, spatially-varying lighting and SVBRDF from a single image[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 2475-2484.
[57] LALONDE J F, EFROS A A, NARASIMHAN S G. Estimating natural illumination from a single outdoor image[C]//2009 IEEE 12th International Conference on Computer Vision. New York: IEEE Press, 2009: 183-190.
[58] LOMBARDI S, NISHINO K. Reflectance and illumination recovery in the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(1): 129-141.
[59] LALONDE J F, MATTHEWS I. Lighting estimation in outdoor image collections[C]//2014 2nd International Conference on 3D Vision. New York: IEEE Press, 2014: 131-138.
[60] GARDNER M A, SUNKAVALLI K, YUMER E, et al. Learning to predict indoor illumination from a single image[EB/OL]. [2020-08-10]. https://arxiv.org/abs/1704. 00090v2.
[61] HOLD-GEOFFROY Y, SUNKAVALLI K, HADAP S, et al. Deep outdoor illumination estimation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 7312-7321.
[62] WEBER H, PRÉVOST D, LALONDE J F. Learning to estimate indoor lighting from 3D objects[C]//2018 International Conference on 3D Vision (3DV). New York: IEEE Press, 2018: 199-207.
[63] HUI Z, CHAKRABARTI A, SUNKAVALLI K, et al. Learning to separate multiple illuminants in a single image[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 3780-3789.
[64] SUN T C, BARRON J T, TSAI Y T, et al. Single image portrait relighting[J]. ACM Transactions on Graphics, 2019, 38(4): 79:1-79:12.
[65] INNAMORATI C, RITSCHEL T, WEVRICH T, et al. Decomposing single images for layered photo retouching[J]. Computer Graphics Forum. 2017, 36(4): 15-25.
[66] GEORGOULIS S, REMATAS K, RITSCHEL T, et al. Delight-net: decomposing reflectance maps into specular materials and natural illumination[EB/OL]. [2020-04-29]. https://arxiv.org/abs/1603.08240v1.
[67] HORN B K P, SJOBERG R W. Calculating the reflectance map[J]. Applied Optics, 1979, 18(11): 1770-1779.
[68] GEORGOULIS S, REMATAS K, RITSCHEL T, et al. Reflectance and natural illumination from single-material specular objects using deep learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(8): 1932-1947.
[69] SENGUPTA S, GU J W, KIM K, et al. Neural inverse rendering of an indoor scene from a single image[C]//2019 IEEE International Conference on Computer Vision. New York: IEEE Press, 2019: 8598-8607.
[70] AZINOVIC D, LI T M, KAPLANVAN A, et al. Inverse path tracing for joint material and lighting estimation[C]//2019 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 2447-2456.
[71] 赵子忠, 张坤. 传媒变革: 5G对媒体的基本影响[J]. 中兴通讯技术, 2019, 25(6): 48-54.
ZHAO Z Z, ZHANG K. Media revolution: the impact of 5G on the media[J]. ZTE Technology Journal, 2019, 25(6): 48-54 (in Chinese).
[72] 乔秀全, 任沛, 商彦磊. 关于增强现实技术潜在发展方向的思考[J]. 中兴通讯技术, 2017, 23(6): 37-40.
QIAO X Q, REN P, SHANG Y L. Thoughts on the potential development direction of augmented reality technology[J]. ZTE Technology Journal, 2017, 23(6): 37-40 (in Chinese).
[73] 王紫薇, 邓慧萍, 向森, 等. 基于CNN的彩色图像引导的深度图像超分辨率重建[J]. 图学学报, 2020, 41(2): 262-269.
WANG Z W, DENG H P, XIANG S, et al. Super-resolution reconstruction of depth image guided by color image based on CNN[J]. Journal of Graphics, 2020, 41(2): 262-269 (in Chinese).
Review on deep learning based prediction of image intrinsic properties
SHA Hao1, LIU Yue1,2
(1. School of Optics and Photonics, Beijing Institute of Technology, Beijing 100081, China; 2. Advanced Innovation Center for Future Visual Entertainment, Beijing Film Academy, Beijing 100088, China)
The appearance of the real world primarily depends on such intrinsic properties of images as the geometry of objects in the scene, the surface material, and the direction and intensity of illumination. Predicting these intrinsic properties from two-dimensional images is a classical problem in computer vision and graphics, and is of great importance in three-dimensional image reconstruction and augmented reality applications. However, the prediction of intrinsic properties of two-dimensional images is a high-dimensional and ill-posed inverse problem, and fails to yield the desired results with traditional algorithms. In recent years, with the application of deep learning to various aspects of two-dimensional image processing, a large number of research results have predicted the intrinsic properties of images through deep learning. The algorithm framework was proposed for deep learning-based image intrinsic property prediction. Then, the progress of domestic and international research was analyzed in three areas: intrinsic image prediction based on acquiring scene reflectance and shading map, intrinsic properties prediction based on acquiring material BRDF parameters, and intrinsic properties prediction based on acquiring illumination-related information. Finally, the advantages and disadvantages of each method were summarized, and the research trends and focuses for image intrinsic property prediction were identified.
computer vision; computer graphics; intrinsic properties prediction; intrinsic image prediction; BRDF prediction; illumination prediction; deep learning
TP 391
10.11996/JG.j.2095-302X.2021030385
A
2095-302X(2021)03-0385-13
2020-10-23;
2020-12-15
23 October,2020;
15 December,2020
国家自然科学基金项目(61960206007);广东省重点领域研发计划项目(2019B010149001);高等学校学科创新引智计划项目(B18005)
National Natural Science Foundation of China (61960206007); R & D Projects in Key Areas of Guangdong (2019B010149001); Programme of Introducing Talents of Discipline to Universities (B18005)
沙 浩(1997–),男,甘肃天水人,硕士研究生。主要研究方向为图像的本征属性预测、计算机视觉、深度学习。E-mail:sh15271201@163.com
SHA Hao (1997-), male, master student. His main research interests cover intrinsic properties prediction, computer vision and deep learning. E-mail:sh15271201@163.com
刘 越(1968–),男,吉林长春人,教授,博士。主要研究方向为增强现实、计算机视觉等。E-mail:liuyue@bit.edu.cn
LIU Yue (1968-), male, professor, Ph.D. His main research interests cover augmented reality, computer vision, etc. E-mail:liuyue@bit.edu.cn
