基于XGBoost的车身尺寸装配质量智能预测模型
2021-07-09董海,冯晔
董 海,冯 晔
(沈阳大学 1.应用技术学院;2.机械工程学院,辽宁 沈阳 110044)
多级制造系统中的车身装配精准控制是汽车行业长期研究却未能有效解决的问题之一。随着中国制造2025的到来,汽车制造业数字化车间规模逐步扩大,生产过程中分层化数据基数大、差异数据多、数据噪声与不稳定性的影响日益加剧[1]。多级制造过程(multistage manufacturing process,MMP)的复杂性对所涉及的工程领域的要求极为苛刻,包括从过程建模到过程控制。Yang[2]基于主成分分析开发了尺寸质量分析和诊断工具。Hu等[3]基于变异流理论,通过将工程结构模型与统计分析相结合,分析了多级制造汽车车身系统尺寸变化质量预测与控制问题。Song等[4]提出了基于偏最小二乘法的模型预测控制方法,为质量改进提供了一套最优工艺系数,进行了大批量制造过程的车身尺寸质量预测,并在此基础上,减少了时间和成本的浪费。赫立远[5]提出了一种调试能力指标与指数加权移动平均联合控制方法,解决车身尺寸制造质量问题。车身装配精准控制方法已有基本的理论框架,但运用于制造工程领域仍有待完善。
随着工业4.0概念和工业物联网意识的日益普及,实现车身尺寸装配系统的精准控制基础是将智能传感器网络和人工智能相结合。近年来机器学习能够较好地解决数据问题。一些学者从数据挖掘和传统机器学习方面进行了研究。朴素贝叶斯、线性回归、决策树、K近邻和支持向量机等经典分类器,已广泛应用于制造环境中的过程优化、故障检测和预测性维护[6-7]等领域。Rahman等[8]提出了一种集合分类器评估传感器数据质量的方法,提高了质量预测的准确性。Martín等[9]提出了CART决策树模型和随机森林作为电阻点超声波波形图分类的模式识别工具,且两者都可以作为有效的决策支持工具进行质量控制。
综上所述,逻辑回归算法通常适合在数据中找到主要关系,但当问题涉及检测二阶或三阶时,自变量矩阵可能很快变大[10]。与传统机器学习方法相比,XGBoost作为一种高效机器学习算法[11-12],可以自动使用处理器的多线程进行平行计算,其运算速度高效,可以在保证运算速度的基础上提升预测准确度,并且适用于解决工程领域预测问题。同时,传统机器学习方法在处理大样本源时,存在能力不足以及解决多分类问题精度较低等问题。本文针对上述情况,通过分析车身制造过程中生成的多源数据,利用XGBoost方法建立车身尺寸缺陷预测模型,挖掘各个关键质量指标因素的相关程度,提高模型性能,实现对车身尺寸装配的精准控制。
1 问题描述
1.1 车身生产过程中的尺寸偏差分析
车身由200多个冲压件组成,在近1 000个焊接装配机上组装。焊接工艺复杂多变,影响装配质量的因素也各不相同。在车身制造过程中,受冲模磨损、钣料、焊接夹具、工艺参数、焊接装配顺序变化的影响,车身制造尺寸在冲压和焊接时偏离了原始设计的标准尺寸[13]。多级制造系统中车身装配的重点是车架检查和白车身组装检查,目的是使用框架检查的数据,采用机器学习方法预测在不同的组装操作后汽车车身是否存在尺寸缺陷。简单的多级装配过程如图1所示。

图1 多级装配过程图Figure 1 Multistage assembly process being studied
该过程在框架和终点线阶段之间进行了一系列装配操作,有效地将汽车的白车身组装起来。在夹具的帮助下,工人将后挡板安装到裸露的车架上,完成后挡板的组装操作。装配操作结束,进入预检查阶段。
1.2 车身尺寸偏差数据特征分析
预测影响车身尺寸偏差的关键因素,首先应基于车身制造质量数据检测和管理平台,构建车身制造过程尺寸数据的存储和操作分析系统。然后,从储存和操作系统中选取上万个典型汽车的样本数据。专家根据最后一道工序进行间隙和测量值评估,对尺寸偏差进行辨识。从构建的存储和操作系统中选取样本数据,并基于Spearman系数构建不同特征要素之间的绝对相关性矩阵,如图2所示。

图2 基于Spearman系数的不同特征要素之间绝对相关性矩阵Figure 2 Matrix of the absolute correlations between the different features based on the Spearman coefficient
由图2可知,大多数数据特征与目标之间的相关性较低。如果数据特征与下游车身尺寸之间存在质量关系,则非线性分类器更适合当前情况。与此同时,有一些多重共线性的证据,其中某些特征之间具有高度相关性,基于数据集与汽车的车身尺寸特征相关性。对车身尺寸偏差数据进行特征分析。通过调整系统内工序、湿度、光度、温度和材料性能等变量提升产品质量,获取最优预测控制决策方案。利用机器学习方法找到参数之间的关系,对数据进行整理和改进。提出基于XGBoost建模的装配精度质量预测流程,如图3所示。

图3 基于XGBoost的装配精度质量预测Figure 3 Assembly accuracy quality prediction based on XGBoost
2 基于XGBoost建模
2.1 建模过程
XGBoost算法是一种集合方法,由几个弱学习器组合成一个强大的学习器,如式(1)所示。


其中,Ω(fk)表示第k个树模型的复杂度;n表示样本大小;T表示叶节点数决策树;ω表示叶节点的权重;γ表示对T控制范围的树形结构;α表示控制的复杂性惩罚损失函数正规化程度。目标函数中的损失函数权重过高,会降低模型的预测精度;反之,如果正则项的权重过高,所生成的模型会出现过拟合情况,难以对新的数据做出有效预测。只有平衡好二者之间的关系,控制模型复杂度,并在此基础上对参数进行求解。传统机器学习方法很难最小化式(2)~(3)中的损失函数,通过每一次迭代加入一个新函数到模型中,生成新的目标函数,如式(4)所示。

式中,I表示一片叶子上的样本集合;Ij为第j片叶子上的样本集合,式(5)可转换为

其中,估算决策树中每片叶子权重大小为

式中,s定义为叶子索引号与输入数据之间的一一对应关系;s(xi)定义为样本xi在相应树中叶子节点的索引号对应的叶子分值。树结构s如式(9)所示。

XGBoost寻找分割点的标准是最大化,目标值越小,整个树的结构越优。最终结果如式(10)所示。

2.2 模型评估
选择与问题相匹配的评估方法,能快速地发现模型选择或训练过程中出现的问题,对模型进行迭代优化。针对分类、排序、回归、序列预测等不同类型的模型泛化能力评估问题,评估指标的选择也有所不同。分类器性能指标包括误差、过拟合与欠拟合、偏差与方差分解和性能度量的运用等。本文采用有效可行的实验估计和有衡量学习器模型泛化能力的评估标准性能度量方法,对模型的泛化性能进行评估。为了说明各性能度量指标,以车身数据集为例,模型分别选择分类器算法,划分数据集,评估各性能指标。本文确定的评价指标包括z=其中,z为准确率;tp为真正例;tn为真反例;fp为假正例;fn为假反例;查全率h表示所有真实结果为正类的样本中预测结果也为正类的占比,即查准率j表示被预测为正类的样本中真实结果也为正类的占比,即查准率和查全率之间的平衡是不可取的。一般地,查准率高时,查全率偏低;查全率高时,查准率偏低。所以在类别分布不均匀的情况下,通常利用基于查准率和查全率的调和平均F1分数进行度量,
受试者工作特征ROC(receiver operating characteristic)曲线也是研究模型泛化能力的有力工具。根据模型的预测结果对样例进行排序,用来比较不同的学习器。AUC(area under curve)是指ROC曲线下的面积大小。该值能量化地反映基于ROC曲线衡量出的模型性能。在实际的数据集中经常会出现类不平衡现象,即负样本比正样本多很多或相反,伴随测试数据中的正负样本分布也不平衡,ROC曲线可以基本保持原貌,AUC会考虑阈值变动影响,实现评估模型性能的有效评估。
3 算例分析与验证
以某企业生产的车身样品为例,结合车身生产过程中的大量数据以及分析各工序影响车身质量的因素,对本文提出的基于XGBoost的车身尺寸装配质量智能预测模型进行验证。
采用极端梯度提升(extreme gradient boosting,XGBoost)、随机森林(random forest,RF)、K近邻(Knearest neighbours,KNN)、支持向量机(support vector machine,SVM)、逻辑回归(logistic regression,LG)和朴素贝叶斯(naive bayes,NB)模型进行训练,训练结果如表1所示,2个线性模型逻辑回归和朴素贝叶斯的表现比非线性分类器差,表明特征与目标之间的非线性关系更强。

表1 标准试验系统结果数据Table 1 System resulting data of standard experiment
在此基础上,对XGBoost、随机森林、K近邻和支持向量机4个非线性分类器进行5倍交叉验证测试结果对比分析,以获得更符合实际的准确度度量,并避免过度拟合训练数据。模型交叉验证训练结果中查全率、查准率、召回率、真正率、假正率、F1分数值如图4所示。
由图4可知,基线随机森林模型在所有指标上的表现更好;除了召回率(XGBoost明显优于后者)之外,XGBoost和SVM模型的表现稍差,而KNN的整体性能更差,但在MMP中要考虑性能受时间等多种因素影响。为解决这一问题,采用一种方法来监视应用模型的准确性,并在模型降至某个阈值以下时对其进行重新训练。因此,基线随机森林等模型需要花费更多时间和成本训练执行交叉验证,故基线随机森林模型并不是解决多级制造系统中的车身装配精准控制问题的最佳方案。因此,本文通过随机调整超参数对XGBoost、RF和SVM 3个模型进行了重新搜索,并根据用于交叉验证的相同评估指标在测试集上进行了比较改进。其中,假定所有省略的参数均采用其各自实践中的默认值,通过对ROC-AUC的随机搜索优化进行调整,从而得到每个模型的参数。在5次交叉验证的基础上,进行了100次迭代执行优化,改进后的参数如表2所示。

表2 调整的参数代码数据Table 2 Adjusted parameter data

图4 交叉验证的测试结果Figure 4 Test results from cross validation
对基于交叉验证的相同度量基线模型指标重新评估度量,colsample_bytree表示调整;gamma表示伽马微调;learning_rate表示学习率;max_depth表示最大深度;min_child_weight表示每个叶子节点上最小样本的个数;n_estimators表示最佳迭代次数;min_samples_split表示最小切分点;min_samples_leaf表示最小叶子节点样本数;max_features表示样本对象;其他参数也均根据交叉验证后选择了使结果最好的参数设置。新的模型调整结果如表3所示。
使用回归模型预测车身生产装配存在的质量问题。由表3可知,XGBoost模型的5个评估指标结果优于RF和SVM模型,且5个评估指标结果非常接近,特别是改进后的XGBoost、RF和SVM 3个集成模型的训练值。因此,在相同条件下,对3个模型在新的保留数据集测试。该数据集源于最后一次输入原始数据集后的3 d内从1 000辆汽车中获得的测量值,根据领域专家的评估,每个汽车样本被标记为“OK”或“NOK”产生的矩阵如图5所示。由图5可知,改进的XGBoost模型在预测样本测量值上实现了完美的汽车召回,说明XGBoost能准确地预测原始数据之外的真实汽车样本中缺陷的发生,为装配线早期尺寸偏差识别提供了重要的依据。

表3 模型调整分数结果Table 3 Tuned model results
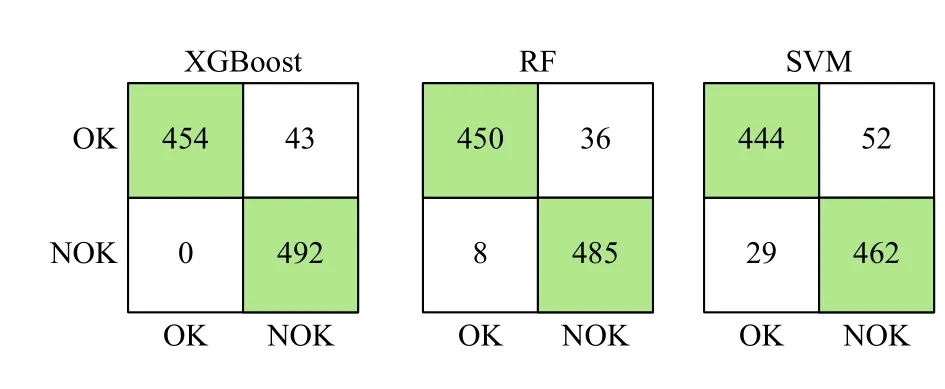
图5 预测模型混淆矩阵结果Figure 5 Prediction model confusion matrix results
4 结论
本文在传统机器学习方法分析车身生产装配预测控制的基础上,对车身制造复杂的工艺过程中各个阶段、多个维度的生产样本数据进行实时采集与数据挖掘处理,建立基于XGBoost的车身尺寸装配质量智能预测模型。挖掘数据结果和特征因素之间的联系,准确快速地预测车身装配中的异常数据。某企业车身生产装配线案例结果表明,非线性算法XGBoost的车身尺寸装配质量预测模型可以有效提高预测精度、效率及预测稳定性,有效减少车身制造过程中的浪费和维修成本。
