一种改进萤火虫算法的模糊聚类方法
2021-05-24孟学尧郭倩倩郭海儒
孟学尧,郭倩倩,郭海儒
1(河南理工大学 计算机科学与技术学院,河南 焦作 454000)2(河南理工大学 学术出版中心,河南 焦作 454000)
E-mail:guohr@hpu.edu.cn
1 引 言

萤火虫算法(Firefly Algorithm,FA)[9]具有流程清晰、参数少、易实现等优点,在计算机网络、图像处理和工程设计等领域应用广泛[10-12].Wang等[13]基于光强差异变化趋势,提出了基于光强差的FA算法,参数设置可以随时进行有针对性的自适应调整,平衡了探索与开发过程,有效地降低了早熟收敛的风险;崔家瑞等[14]基于萤火虫趋光和荧光的特性提出了两种算法,第1种基于PSO算法中的最优个体思想,提出了基于当前全局最优的萤火虫算法(FAGO);第2种结合贝叶斯估计法提出了基于贝叶斯估计的萤火虫算法(FABE).除了针对FA算法自身的改进,许多研究将FA与FCM算法相结合,首先利用FA算法优化聚类中心,避免聚类算法陷入局部最优,之后利用优化好的聚类中心进行聚类操作,提升了聚类效果.林睦纲等[15]提出了一种基于FA算法的模糊聚类方法,提高了聚类精度;朱书伟等[16]提出了基于改进多目标萤火虫算法的模糊聚类,具有较高的聚类准确率.上述FA算法结合FCM提升了聚类效果,但在初始化种群分布过程中多采用随机的方法,限制了种群的多样性,而且算法FAGO和FABE虽然考虑了“当前最优”和“信息素”的概念,但算法仍有陷入局部最优的可能.
鉴于此,本文首先利用切比雪夫(Chebyshev)混沌映射初始化种群分布,该映射将萤火虫种群均匀分布到搜索空间中,生成范围广、分布均匀、全局搜索能力强的初始种群,可提高种群的多样性和算法的求解精度;然后利用自适应步长因子代替固定步长因子,平衡迭代过程中算法的探索与开发能力;最后对最优种群个体所在位置进行高斯扰动突变机制,使算法能够继续进行搜索模式,避免陷入局部最优.将新算法运用到聚类问题中,提出一种基于改进萤火虫算法的模糊聚类方法(a fuzzy C-means clustering based on improved firefly algorithm,IFAFCM),该算法利用改进的FA算法搜索最优聚类中心并将其作为FCM算法的聚类初始值,可有效提高聚类性能.
2 相关工作
2.1 FCM算法
FCM是一种将样本数据按照各自隶属度大小进行分配的常见聚类算法.其目标函数公式如式(1)所示:
(1)
其中,n代表样本总数,其样本数据集X={x1,x2,…,xn},xj={xj1,xj2,…,xjs}表示第j个样本的s个属性;c代表聚类质心数,V={v1,v2,…,vc}表示质心集合;元素uij表示第j个样本隶属于质心i的大小,m代表模糊指数,通常取常数值2;dij为每个样本到聚类中心的欧氏距离.计算隶属度矩阵uij和质心矩阵vi如式(2)和式(3)所示.
(2)
(3)
2.2 FA算法
作为群智能优化算法,FA在全局寻优方面比粒子群算法和遗传算法等更有优势[17-19].该算法通过模拟自然界中萤火虫个体之间相互吸引和移动的过程对固定空间进行搜索和优化.萤火虫通过自身荧光素发光使得较暗的个体向比较亮的个体移动,最终所有个体都趋近于最亮的萤火虫,其所在的位置就是搜索空间中最优的位置.对于萤火虫的亮度、吸引度、位置更新公式由以下定义进行描述.
定义1.两只萤火虫的相对荧光度,公式如式(4)所示:
I=I0e-γrij
(4)
其中,I0表示在γ=0时得到的最高荧光亮度,目标函数值越优亮度越高;γ代表光强吸收系数随着两只萤火虫相隔距离越远,体现荧光被空气介质逐渐削弱的特性;rij表示萤火虫i和萤火虫j之间的距离,计算公式如式(5)所示,s表示维度.
(5)
定义2.萤火虫的吸引度,公式如式(6)所示:
(6)
其中β0表示最大吸引度,即r=0时的吸引度,γ同上.
定义3.萤火虫位置更新公式,公式如式(7)所示:
si(t+1)=si(t)+β(sj(t)-si(t))+α(rand-0.5)
(7)
其中,si、sj分别是萤火虫i和j在搜索空间的位置;t表示迭代次数;β为吸引度,α为步长因子,它的取值范围在区间[0,1]之间,这里取值为一常数;rand为随机因子,它是在区间[0,1]上的随机数.
3 IFAFCM算法
3.1 改进的萤火虫算法
3.1.1 Chebyshev映射
为了验证Chebyshev混沌映射的有效性,利用Chebyshev混沌映射方法将20个2维粒子均匀分布到用函数z形成的三维平面(如图1所示)中,并与传统随机分布粒子群的三维图(如图2所示)进行了比较,函数z的表达式如式(8)所示:
z=3×(1-x)2×e(-(y2)-(x+1)2)-10×(x/5-x3-y5)×e(-x2-y2)-1/3×e(-(x+1)2-y2),x,y∈[-4,4]
(8)

3(1-x)2exp(-(y2)-(x+1)2)-…-1/3 exp(-(x+1)2-y2)

3(1-x)2exp(-(y2)-(x+1)2)-…-1/3 exp(-(x+1)2-y2)
通过比较图1和图2可以看出,Chebyshev映射方式可将萤火虫初始种群均匀分布在搜索空间中.在相同条件下,Chebyshev映射产生的粒子能够收集到更多的信息,有效避免了粒子群易陷入局部最优的问题.与常用的混沌映射Logistic映射[20]相比,Chebyshev映射在分布范围与分布方式上更具优势.
本文采用了Chebyshev映射方式生成混沌变量,公式如式(9)所示:
xn+1=cos(karccosxn),xn∈[-1,1]
(9)
其中k为阶次,能够生成不相关且带有遍历性质的混沌序列,Chebyshev映射萤火虫种群数的步骤如下:
a)规定萤火虫种群数N,在D维空间中随机产生一个D维向量作为第1个萤火虫个体,Y=(y1,y2,…,yd)vi∈[-1,1],i∈[1,d];
b)利用公式(9)对Y的每一维进行N-1次迭代,产生出其余的N-1个萤火虫个体;
c)映射公式如式(10)所示,利用公式(10)将生成的N个萤火虫个体依次映射到解搜索空间:
xid=ld+(1+yid)×(ud-ld)/2
(10)
其中,ud、ld分别为搜索空间第d维的上、下界,yid为第i个萤火虫第d维,xid为第i个萤火虫在搜索空间中第d维坐标值.
3.1.2 自适应步长因子
萤火虫种群的寻优能力主要体现在个体的位置更新方法上.在公式(7)中,第1项表示萤火虫当前所在位置;第2项表示萤火虫的全局搜索能力;第3项表示萤火虫的局部搜索能力,其中步长因子的调整十分关键.
FA算法中参数α平衡着萤火虫种群探索与开发能力,α取值范围为[0,1].过大或过小的随机值都可能严重影响种群的搜索能力,因此设计了自适应步长机制,能够让种群在搜索过程中自主适时更换全局搜索与局部搜索两种搜索方式,提高寻找最优解的能力.控制参数α的计算公式如式(11)所示:
αt+1=αtδ, 0.5<δ<1
(11)
其中δ代表冷却系数.在迭代初期,为步长因子α赋予一个较大的取值,保证前期有较好的全局寻优能力;之后在一次次的迭代过程中α值逐渐减小,确保了较好的局部搜索能力.通过α值的调节,能够更好地平衡萤火虫算法的全局搜索能力和局部搜索能力.
3.1.3 高斯扰动机制
由于FA算法在陷入局部最优的状态时,算法本身自带的随机扰动策略在多维条件下无法跳出局部最优位置,因此一种适应性更强的扰动机制被需要.高斯扰动是一种针对局部最优问题常用的扰动策略,它对每次迭代后获得的最优个体进行高斯扰动得到新的最优个体,直到高斯扰动无法获得新的最优个体,说明算法已经达到了全局最优.
高斯扰动的基本原理是为每次迭代过程中的最优个体的位置向量添加一个小幅度的随机向量,并且这个向量要符合正态分布.其公式如式(12)所示:
(12)

在算法每一次迭代过程中,Gbest对应当代最优位置,将其进行高斯扰动,其公式如式(13)所示:
NGbest=Gbest(1+N(0,1))
(13)
向量NGbest表示高斯扰动后形成的新位置向量,之后对全局最优位置进行更新,其更新公式如式(14)所示:
(14)
综上所述,改进的萤火虫算法步骤如图3所示.

图3 改进萤火虫算法流程图Fig.3 Flow chart of improved firefly algorithm
3.1.4 所提算法验证
针对所提算法的有效性进行验证,实验中用了f(1)https://archive.ics.uci.edu/ml/index.php、f2和f3这3个测试函数在30维的基础上测试所提算法的求解精度和稳定性,具体描述信息如表1所示.其中f1和f2属于单峰函

表1 测试函数Table 1 Test function
数,目的是为了测试算法的求解精度,f3属于多峰函数,目的是为了测试算法寻找最优点的能力.将所提算法在3种测试函数中将30个粒子分别运行20次,每轮迭代500次,求出它的平均值与标准差,之后与其余5种算法FA[14]、FAGO[14]、FABE[14]、PSO[19]和GA[19]进行对比,其对比结果如表2所示,证明了所提算法在6种算法中无论是单峰函数的求解精度还是多峰函数的寻最值点都具有良好的竞争力,在与模糊聚类进行结合时能够在一定程度上解决FCM算法对初始聚类中心的敏感和易陷入局部最优的问题,能够为改进的模糊聚类算法聚类取得的成果提供充实的依据.
3.2 IFAFCM算法
结合IFA算法较强的全局寻优能力和寻优精度与FCM算法较强的局部搜索能力,设计了一种改进萤火虫算法的模糊聚类算法IFAFCM.IFAFCM聚类方法在寻优方面有明显改善,聚类性能和抗噪能力有明显的优势.

表2 6种算法在3种测试函数下的结果比较Table 2 Comparison of the results of six algorithms under three test functions
在IFAFCM算法中,将模糊聚类的目标函数代替萤火虫的亮度,目标函数值越小说明萤火虫的位置越好,亮度越高,所以目标函数与个体亮度呈反比.亮度公式如式(15)所示:
(15)
在该算法中每一只萤火虫都可看作是一个聚类中心,其位置向量为V=(v1,v2,…,vc),其中vi为第i个聚类中心.萤火虫各个生物特性在聚类过程中的对应作用关系如表3所示.

表3 萤火虫生物特性对应关系Table 3 Correspondence of firefly biological characteristics
由于利用IFA算法找到的最优聚类中心可能是近似解,因此需要将最优聚类中心作为传统FCM算法的初始聚类中心进行进一步的优化.基于IFA算法的模糊聚类方法的流程图如图4所示.
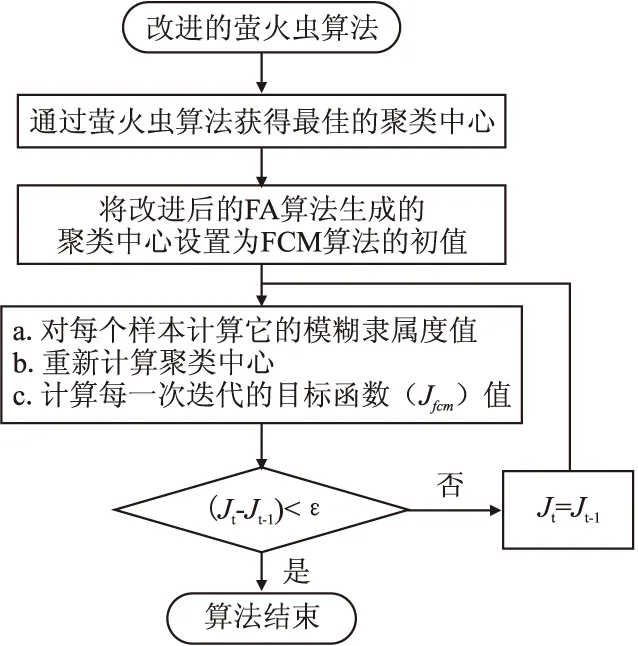
图4 IFA算法的模糊聚类方法流程图Fig.4 Flow chart of fuzzy clustering method with improved firefly algorithm
IFAFCM算法步骤如下所示:
输入:IFAFCM算法的控制参数和聚类评价指标.
输出:聚类准确率(ACC)和标准化互信息(NMI).
1.初始化种群各个参数,如N、β0、γ、α、δ、c、maxT和阈值ε;利用Chebyshev混沌映射在搜索空间均匀分布种群V1,V2,… ,VN;计算种群中每只萤火虫的亮度I(Vi).
2.比较各个萤火虫个体的亮度I(Vi),利用公式(7)和公式(11)进行萤火虫的位置更新.
3.利用公式(6)计算萤火虫之间的吸引度βij,用公式(2)计算Ui,用公式(15)更新由于位置改变而改变的亮度I(Vi).
4.对萤火虫进行排序,找出当前最优个体,记录其位置并利用公式(13)和公式(14)进行高斯扰动进行位置更新;
5.判断算法是否达到终止条件(最大迭代次数或收敛阈值),若是则输出全局最优个体,若否则转到步骤2.
6.将找到的最优点作为FCM算法的初始值进行聚类,输出ACC和NMI值.
4 实验结果与分析
4.1 实验操作平台
本实验的程序运行环境为:处理器CPU英特尔 Core i7-8750H,主频2.20GHz六核,内存8GB,操作系统:Windows 10 64位,集成开发环境为Matlab 2014a.
4.2 实验数据集
在实验过程中,采用了UCI数据库1中常用的4个数据集:鸢尾花(Iris)数据集、大肠杆菌(Ecoli)数据集、红酒(Wine)数据集和玻璃(Glass)数据集,各数据集的详细信息如表4所示.另外,在聚类过程中为了避免由于特征数值之间差异太大对聚类结果造成影响,对数据集的数值进行归一化处理,使得特征数值处在[0,1]之间.
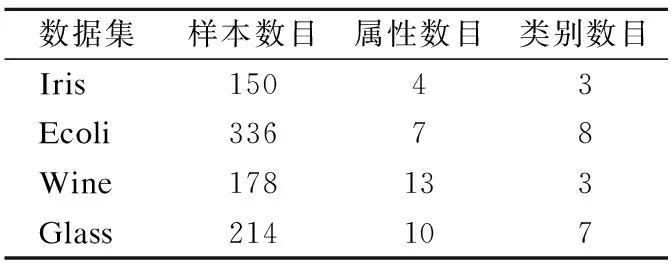
表4 实验所用数据集Table 4 Datasets used in the experiment
4.3 评价指标
在本实验中利用聚类精度(Accuracy,ACC)和标准化互信息(Normalized Mutual Information,NMI)来评价聚类性能.
聚类精度:正确分配到聚类的样本数与所有需要聚类的样本总数的比值.计算公式如式(16)所示.
(16)
其中,dk表示正确分配给第k个簇的样本数,N表示所有样本的数.
标准化互信息:是一种对称度量,能够量化两个集群分布之间共享的统计信息[21].度量公式如式(17)所示:
(17)
其中,R和Q是输入数据集的两个分区,分别包括簇I和簇J.P(i)是从数据集中随机选择的样本分配给簇Ri的概率,P(i,j)是样本同时属于簇Ri和簇Qi的概率.H(R)是与分区R中的所有概率P(i)(1≤i≤I)相关联的熵.
实验结果中准确率数值越大,说明样本正确分配到对应簇的数量越多,聚类性能越好;标准化互信息数值越大,代表簇之间划分得越准确,说明算法的聚类效果越好.
4.4 实验结果
4.4.1 聚类性能对比实验
将算法FCM、PSOFCM、FAFCM与IFAFCM算法在4个数据集上进行比较.算法参数设置分别为最大迭代次数maxT= 300,模糊指数m值为2,阈值ε为10-5,初始种群数N= 30,最大吸引度β0=1.0,步长因子α= 0.8,冷却系数δ=0.98,光吸收因子γ= 0.9,粒子加速系数c1=c2=2,r1,r2为分布于[0,1]的随机数,惯性权重系数Wmax=0.9,Wmin=0.4.将每种算法在各数据集上分别运行10次,求取平均值得到ACC和NMI,对比结果如表5所示.

表5 4种算法评价指标ACC和NMI的结果比较Table 5 Comparison of the results of evaluation indexes ACC and NMI of the four algorithms %
从表5中可以看到,IFAFCM算法在4个数据集上的ACC和NMI两个指标,均比其他3种算法有明显提高.其中FCM算法在两种评价指标中都处于最低.这是由于IFAFCM算法在初始种群分布与搜索能力上都做出了改进,使得在聚类算法中具有较优的聚类中心,提高了聚类性能.其中在Iris数据集中IFAFCM算法在ACC指标上平均提高了2%~4%,在NMI指标上平均提高了6%~10%;在Ecoli数据集中IFAFCM算法在ACC指标上平均提高了4%~10%,在NMI指标上平均提高了5%~8%;在Wine数据集中IFAFCM算法在ACC指标上平均提高了1%~2%,在NMI指标上平均提高了3%~5%;在Glass数据集中IFAFCM算法在ACC指标上平均提高了5%~11%,在NMI指标上平均提高了9%~15%.
4.4.2 抗噪能力
为了进一步体现IFAFCM算法的优越性,设计了抗噪声对比实验.在4个原数据集中加入不同比例的噪声数据,然后分别进行聚类.通过聚类得到的ACC和NMI的数据来反映噪声数据对各个算法影响程度,实验结果如图5和图6所示.从图中可以看出IFAFCM算法随着噪声比例的增加,ACC和NMI指标在4种算法中均取最大值.可见,IFAFCM算法与其他3种算法相比,具有较好的鲁棒性.

图5 4种对比算法在4个数据集上的聚类精度对比图Fig.5 Comparison graphs of clustering accuracy of four comparison algorithms on four datasets
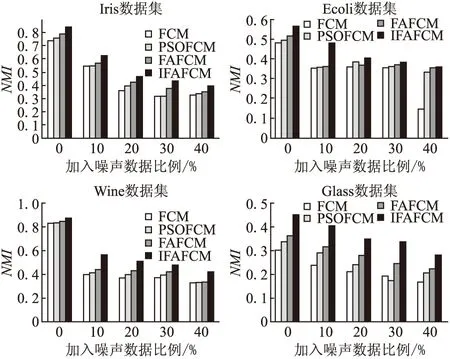
图6 4种对比算法在4个数据集上的聚类标准化互信息对比图Fig.6 Comparison graphs of clustering normalized mutual information of four comparison algorithms on four datasets
5 总 结
本文提出了一种改进萤火虫算法的模糊聚类算法IFAFCM,该算法对传统FCM初始化敏感、鲁棒性差等方面进行了改进,以提高聚类准确率.在该算法中,首先运用Chebyshev混沌映射将萤火虫种群均匀分布到搜索空间中,生成范围广、分布均匀、全局搜索能力强的初始种群;然后将步长因子转变为动态调整的方式,平衡了探索与开发过程;最后采用高斯扰动对最优个体进行变异,增强了算法跳出局部最优的能力.萤火虫算法与传统FCM算法的结合,既提供了良好的全局搜索能力,又保证了良好的局部开发能力.为了评估IFAFCM算法的聚类效果,在4个数据集上与其他3种算法进行了对比实验,实验结果表明,IFAFCM算法相较于其他3种算法,在聚类性能、抗噪能力方面均有提高.
