基于自适应变异算子的实数编码遗传算法
2021-05-20王剑楠崔英花
王剑楠,崔英花
(北京信息科技大学 信息与通信工程学院,北京 100192)
0 引言
遗传算法作为一种随机全局搜索寻优算法,在工程领域中获得了广泛的应用。实际工程中许多问题可归并成多峰函数优化问题。在问题的可行解范围内最优解附近常有多个局部极值点存在,如神经网络的结构优化以及权值优化问题,复杂系统参数及结构辨识问题[1],因此使遗传算法获得多峰函数全局最优解成为了一个重要的研究方向。但遗传算法存在固有缺陷,在解决多峰函数优化问题时,常在获得全局最优解前在某个局部极值处发生未成熟收敛,从而丧失了向上进化的能力,此时种群中的个体由于选择算子几乎全部跳入某个峰值之中,个体之间适应度高度趋同,即便某次变异使某个个体跳出该峰值,也有很大概率会因适应度值无法超过该峰值而遭到选择算子的淘汰,故而已经陷入局部极值的遗传算法很难跳出局部峰值。因此解决算法“早熟”问题的关键在于如何保持种群的多样性,使种群中总有个体存在于各个不同的“峰”之中,这样种群才有机会一直保持进化。
在遗传算法的早期操作中大多采用二进制编码,二进制编码遗传算法(binary coded genetic algorithm,BCGA)[2]中问题的可行解被编码成由0和1组成的字符串。这种算法对于可行解范围较小和对解精度要求不高的问题性能或许比较理想,但对于精度要求较高的高维问题,则会占用过多的存储空间,并在计算上产生过多的时间开销。为了克服这些缺陷,本文选择实数编码方式的遗传算法。实数编码遗传算法(real coded genetic algorithm,RCGA)[3]问题的可行解以实数形式表示。
实数编码遗传算法进化过程中的种群多样性与交叉算子和变异算子的联系密不可分。交叉算子对两个个体的基因结构进行破坏重组,对个体结构的改变比较剧烈,因此交叉操作决定了算法的全局搜索能力。在种群进化后期,从可行解全局搜索区域来看交叉算子已经锁定了某个可能存在最优解的范围,利用交叉算子搜索该区域内的细节会比较困难,这时可以利用变异算子对该区域内的“山峰”进行局部搜索。因此在种群多样性下降时应加强变异算子对基因的扰动程度。
传统的实数编码遗传算法变异算子大致分为4类:均匀变异、边界变异、高斯变异、非均匀变异(non-uniform mutation,NM)[4]。相比于前3类,非均匀变异可随进化代数调整变异元素,重点搜索原个体附近的微小区域。然而随着进化代数的增加,变异基因值越来越接近原基因值直至完全相同,不能达到维持种群进化能力的目的。
为了提高传统变异算子的性能,许多学者对其进行了改进。文献[5]提出的自适应变异尺度调整了变异元素产生的区域。Kusum和Manoj提出的幂型变异算子(power mutation,PM)[6],通过限定范围内的幂函数的密度函数为随机扰动函数,代替传统非均匀变异以进化代数为决策变量的扰动函数,相比于传统非均匀变异算子,对变异强度有所强化。文献[7]提出的基于方向的指数型变异算子 (direction-based exponential mutation operator,DEM)利用可行解的方向信息和指数函数来生成突变解,对方向信息的先验知识的运用使种群快速收敛到有效解区域。
然而上述方法存在一定的缺陷:1)任子武等提出的变异算子变异尺度依然自适应于进化代数,在种群进化后期变异强度趋于零;2)PM的变异强度带有一定的随机性,没有考虑到种群的进化状态信息,变异强度与种群进化阶段缺乏适应性;3)DEM调整变异算子时过于倾向于当前种群最优解,有一定可能导致种群早熟收敛。
自适应遗传算法[8]自Srinivas等提出以来受到了国内外学者的广泛关注。最原始的自适应遗传算法是使变异概率根据个体适应度值的大小自适应地调整,由适应度值决定个体变异的可能性的大小。王玉冰等[9]进一步对变异概率进行改进,根据刻画种群多样性的信息熵和进化代数自适应地调整变异概率,由种群进化的阶段和进化的程度控制种群中变异个体的比例。文献[10]和文献[11]继续改进了变异概率公式,设计的变异概率集成了个体适应度值和种群进化程度信息,既从微观上依据个体适应度值决定个体需要变异的概率,又根据种群宏观整体上进行调控。然而这些学者所做的改进仅仅停留在变异概率公式[12]的设计上,变异概率只决定了种群中发生变异的个体的比例,即只考虑到变异的范围,而忽视了变异的强度。
为了解决上述问题,本文集合了自适应遗传算法自适应调整变异概率的思想和变异强度对种群多样性的影响,设计了一种新的具有自适应性的强度可变的变异算子。提出了一种基于种群多样性的变异强度控制函数,以种群多样性评价标准为决策变量控制变异强度,综合了种群进化状态信息与变异强度对变异元素的影响。
1 种群多样性指标及应用
1.1 方差因子
在遗传算法迭代过程中,种群能够不断进化依赖于种群的多样性。丰富的个体是保持种群进化的动力,如何设计种群多样性评价标准是衡量种群进化状态的关键。个体本质上是由不同的基因所构成,种群中个体之间的差异本质是各个维度上的基因的差异,也就是个体结构组成上的差异。不同个体结构的差异程度可用种群基因偏离程度进行刻画。显然基因离散程度越高,个体之间结构差异越大。
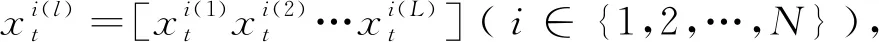
(1)
其中:
(2)
由此定义第t代种群的方差为
(3)
其中:
(4)

(5)
方差是个体结构差异的一种度量准则,仅反映了个体间基因偏离程度,还不能完全反映种群的多样性特征。为了反映个体在各个子群体中的分布情况,本文引入描述种群多样性的第二个量——熵。
1.2 种群熵因子
定义2设第t代种群有Q个子集:S1(t),S2(t),…,SQ(t) ,各个子集所包含的个体数目记为n1,n2,nQ,且对任意p,q∈{1,2,…,Q}有
(6)
其中A(t)为第t代种群的集合。则种群的熵为
(7)
式中pj(t)=nj/N,N为种群中个体的数目。由种群熵定义可知,种群中N个个体均位于不同的子集时,Q=N,种群熵最大,Emax=log(N)。当所有个体全部集中在同一个子集中时,Q=1,种群熵最小,Emin=0。种群基因类型越丰富,个体分布就越均匀,从而种群熵就越大。本文为了建立变异强度控制函数与种群熵的函数关系,用γ表示种群熵因子,γ=E(t),监测个体在各个子群体中的分布情况。
2 基于种群多样性的变异算子
本研究提出了一种新的基于种群多样性的非均匀变异算子(diversity based non-uniform mutation operator,DNM)用于实数编码遗传算法,这个新开发的算子受底数u、进化代数t、种群多样性信息s和γ等因素的影响。提出了一种新型变异强度控制函数s(t)用于变异算子,变异强度根据函数s(t)进行自适应变化。在种群可能出现未成熟收敛时,变异强度控制函数扩展了算子的可操作空间,使算法有能力跳出局部最优解。设父代染色体为x=[x1,x2,…,xk,…,xn],元素xk∈[Lk,Uk]为待变异元素,变异后的元素yk随机产生于区间Ω:
Ω={xk-s(t)(xk-Lk),xk+s(t)(Uk-xk)}
(8)
其中:
s(t)=1-u(1-sγ)t
(9)
式中:t为进化代数;u∈[0,1],本文取值为0.2。从式(9)可以看出,种群在进化早期sγ较大,s(t)≈0,此时算法处于全局搜索阶段,交叉算子发挥主要作用,变异强度可以偏小以加快搜索速度。随着种群的进化,优势个体出现并有逐渐占领种群的趋势,种群多样性逐渐下降,故而sγ减小。当sγ≈0时,s(t)≈1-u,变异空间较大增加了变异强度,赋予了个体跳出局部“山峰”的能力,提高了算法的局部搜索能力。
3 仿真
3.1 与传统非均匀变异算法的对比
传统非均匀变异操作为
s(t)=1-u(1-t/T)b
(10)
式中:t为进化代数;T为最大进化代数;b多取经验值3。为了确定加速因子在变异强度函数中的作用,t/T可以看作是一个不断以线性速率增大的变量。对于传统非均匀变异算子中的t/T,本文选择以sγ替代以监测种群多样性信息。令sγ=x,令y=1-u(1-x)bx,y∈[0,1],分别取b为2、3、4、100进行仿真实验,如图1所示。
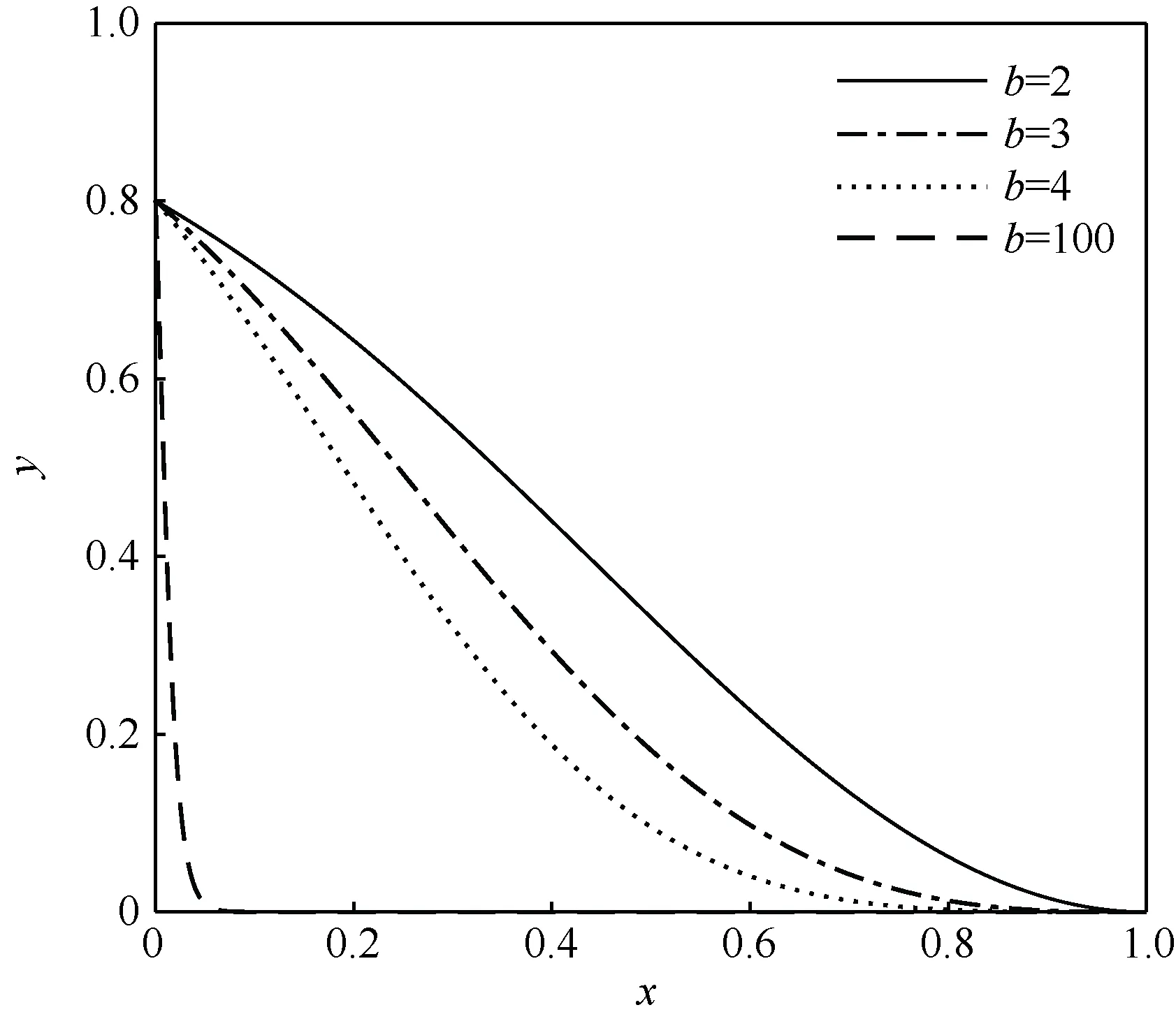
图1 加速因子对比曲线
从图1可以看出,随着b的增大,曲线越来越陡峭。在种群初期sγ趋向于1,b值过高会导致y≈0进而变异强度为0。由于进化初期依然需要一定的变异强度来积极探索种群空间,因此在种群进化初始阶段应取较小的b值保证变异算子的变异强度。随着种群的不断进化,sγ向零处收敛,此时需要增加变异强度以增强局部搜索能力,然而过大的变异强度会使算法沦为随机搜索算法且收敛速度会因此变慢。此时为了平衡变异强度与变异给算法搜索带来的随机性之间的矛盾,应适当降低变异强度。在x值相同的情况下,b值越大y越小,因此在种群进化后期宜采取较大的b值。用进化代数t代替b,可以保证在进化初期y不至于过低且在进化后期y不至于过高。
为了验证改进的非均匀变异算子的优势,对式(9)和(10)采用仿真对比。采用经典遗传算法,选择策略为轮盘赌选择法,进化代数T取100,种群规模为100,Pc为0.8,Pm为0.05。测试函数选择schaffer函数:

xi∈[-5,5];i=(1,2)
(11)
该函数有无限个局部极大点,其中只有一个全局最大点,即f(0,0)=1,在最大值周围有峰值圈脊,算法易在圈脊中某个值处停滞。
图2是分别使用两种变异算子的算法目标函数值的仿真对比。从图中可以看出,使用传统非均匀变异算子的算法在0.998附近陷入局部收敛。而对于应用DNM的算法,加速因子取t时比取b时获得更快的收敛速度。经计算DNM加速因子为b时绝对误差为3.138 6,远大于DNM加速因子为t时的绝对误差(接近于0)。同时可以看到,加速因子为b时算法似乎也收敛到最优解f(0,0)处,进化曲线显示最优值无限趋近于1,然而不能看出DNM加速因子为b时算法是否陷入局部收敛。

图2 最优解进化曲线对比
本文分别计算了3种情况下算法的最优解位置,如图3所示。从图中可以看出,DNM加速因子为b时算法收敛点根本不在最优解所在山峰,由此判断尽管DNM加速因子为b时获得较好的适应度最优值进化曲线,但仍易陷入局部最优解。

图3 最优解位置对比
为了验证本文所提算法在进化后期种群多样性有所提高且在一定程度上克服了“早熟”收敛,对比了使用不同算子的算法下经过100次进化后的种群个体分布情况,如图4所示。图中一个空心圆代表种群中的一个个体。可以看出,传统NM算子不能使算法很好地保持种群多样性;而使用DNM算子的算法则保持了一定水平的种群多样性。
3.2 与使用其他改进变异算子的算法的对比
为了验证本文所提变异算法的有效性和优越性,将其与前文所述的使用几种改进的变异算子的算法进行对比:Kusum和Manoj提出的PM和文献[7]提出的DEM。在经典遗传算法上使用3种变异算子,选择策略和其他控制参数不变。测试函数依然选择schaffer函数,3种算法的最优解随迭代次数的进化曲线如图5所示,从最优解进化曲线可以看出本文算法收敛速度高于其他两种算法。图6展示了最优解位置,从图6可以看出本文算法优化后最优解离f(0,0)更近,其他两种算法尽管最后均无限接近f(0,0),但收敛值与(0,0)不在同一个“山峰”,由此证明本文所提算法在求解精度方面也存在一定的优势。
3.3 应用DNM于自适应遗传算法
为了验证本文所提变异算子对自适应遗传算法有所改善,本文选择文献[10]提出的自适应遗传算法进行仿真。文献[10]采用轮盘赌结合最优个体保留的策略,本文采用实数编码策略,Pc1和Pc2分别为0.9和0.6,Pm1和Pm2分别为0.1和0.001。将DNM嵌入自适应遗传算法中代替原自适应遗传算法的变异算子,与原自适应遗传算法对比,最优解随进化代数曲线如图7所示。从图7可以看出,应用DNM的自适应遗传算法收敛速度和收敛精度明显好于原自适应遗传算法。

图4 种群个体分布

图5 三种算子最优解进化曲线对比

图6 三种算子最优位置对比

图7 最优解进化曲线对比
4 结束语
现有自适应遗传算法只考虑了发生变异的个体的比例,仅通过设计变异概率控制变异的范围,而忽视了变异的强度。传统非均匀变异算子对现有自适应遗传算法做出了改进,但不能很好地维持种群的多样性。本文对传统的非均匀变异算子提出了相应的改进策略。种群继续向前进化的主要依据和原动力是种群的多样性,本文从基因内部结构差异和个体分布的均匀程度为切入点设计种群多样性指标,以此指导变异强度使种群更好地完成进化。通过两组对比仿真实验,表明本文所提变异算子保持了一定的种群多样性,增强了算法的局部搜索能力。
