一种面向订单剩余完工时间预测的SOM-FWFCM特征选择算法
2021-05-19刘道元黄少华方伟光杨能俊崔世婷
刘道元 郭 宇 黄少华 方伟光 杨能俊 崔世婷
南京航空航天大学机电学院,南京,210016
0 引言
日益激烈的市场竞争和复杂多变的客户需求对制造企业缩短产品生产周期、按时交付订单提出了更高的要求,订单剩余完工时间的准确预测能够为动态的生产计划调整、生产过程优化提供合理的判别依据,对订单产品的准时完工具有重要的指导意义[1]。在当前生产方式灵活、产品种类繁多的离散制造车间中,智能传感器的大量应用为预测订单剩余完工时间提供了海量的生产数据[2],但同时也带来了“维度灾难”的问题,因此有必要设计一种合理的特征选择方法来有效地从众多特征中获取关键特征,以降低求解问题的复杂度,提高预测模型与实际生产运行规律的拟合度,保证预测的准确性。
特征选择是指从候选特征中挑选若干个具有代表性的特征组成关键特征子集,当前的主要研究方法包括封装式和过滤式特征选择算法。
封装式特征选择算法需要对每个特征子集进行学习器训练,根据学习器性能选择关键特征子集。相关学者使用量子遗传算法[3]、改进粒子群算法和禁忌搜索相结合[4]、粗糙集相对分类信息熵和粒子群算法相结合[5]的方法进行特征选择,首先对每个特征进行编码,然后根据学习器的预测结果计算适应度值,不断迭代至收敛,最后选择适应度值最高的特征子集作为关键特征子集。ZHONG等[6]使用SVM-RFE算法构建特征空间,然后使用皮尔森系数剔除特征空间中有相同意义的特征,最终从26个候选特征中选择6个特征组成最优特征子集。DY等[7]使用期望最大化算法选择特征,以特征子集的分散可分性和最大似然为评价指标,经过多次修改算法参数,选择评价最优的特征子集。上述封装式特征选择算法能得到高质量的特征子集,但每次迭代都需要训练学习器,导致计算复杂度高,不适合处理大规模数据[8]。
过滤式特征选择算法直接通过某种准则选择关键特征子集,再训练后续学习器,特征选择过程与学习器无关,在处理大规模数据方面,降低了计算复杂度,运行效率较高。朱雪初等[9]使用运行效率高、对噪声有一定容错能力的ReliefF算法进行特征选择,考虑各特征与预测目标的相关性但忽略了特征间的冗余性。基于最大相关性-最小冗余性原则,PENG等[10]和夏虎等[11]分别使用互信息和皮尔森系数计算参数间的相关性和冗余性,完成最佳特征子集的选择。为了提高关键特征子集的质量和后续学习器的精度,特征选择不仅要满足最大相关性-最小冗余性原则,还需要最大化特征间的多样性[12]。LIU等[13]通过互信息和关联系数分别衡量类间和类内距离,将标签数据作为单独一类,采用类似于凝聚层次聚类的算法确定关键特征子集。ZHOU等[14]以属性间的最大信息系数作为距离矩阵,使用K-mode算法对属性进行聚类完成特征选择。WITTEN等[15]提出稀疏聚类框架,使用稀疏K均值聚类和稀疏层次聚类算法相结合的方法完成特征选择。
在上述基于聚类的特征选择方法中,减少了特征间的冗余性,保证了特征间的多样性,但每个特征对预测目标解释能力不同,需要根据特征的解释能力来指导特征聚类。本文在特征聚类过程中引入描述特征对预测目标解释能力的特征权重,解释能力越强的特征在计算聚类中心时贡献越大,选择其为关键特征的概率越高,通过综合考虑关键特征子集的冗余性、多样性以及与目标的相关性,实现关键特征的准确选择。
本文提出了一种基于自组织映射(self-organizing map, SOM)网络-特征权重模糊C均值(feature weighted fuzzy C-means, FWFCM)聚类的过滤式特征选择算法,利用SOM网络为FWFCM算法提供初始簇中心,以避免FWFCM算法对初始聚类中心敏感、容易陷入局部最优的问题;将基于互信息的特征与目标相似度作为特征权重,使特征聚类过程具有一定的导向性,进一步改善聚类效果和提高关键特征子集质量。最后结合某航天机加工车间提供的19 428条具有1102个特征的生产数据,进行算法的实例验证和对比分析,证明了所提方法的有效性。
1 问题描述
订单剩余完工时间(order remaining completion time, ORCT)是指从当前时刻开始到订单所有零件产出的时间长度,即TORC=Tfin-Tcur,其中,Tfin表示订单所有零件产出时刻,Tcur表示当前时刻。在复杂离散制造系统中,影响订单完工时间的不确定因素很多,为便于讨论,本文考虑的制造过程遵循以下原则:①离散制造车间中有M个工位,用于生产P类不同零件,每个工位都包含一台机床、一个入缓存区和一个出缓存区;②每个零件有唯一确定的加工路线;③每个在制品在同一台机床上只加工一次;④选择入/出缓存区在制品运输/加工遵循先入先出的原则;⑤在制品准备加工时间包含在在制品加工时间内,在制品在固定两个工位之间的运输时间设为常数。
基于上述原则,订单剩余完工时间主要取决于在制品在入/出缓存区的等待时间和在制品在所有工位上的加工时间。缓存区在制品种类、数量和优先级对订单完成加工时间有着重要的影响[16]。在制品在某个工位的生产过程可以分为以下3个步骤:①在制品从上个工位运输到此工位,进入入缓存区等待加工;②在机床上完成加工;③进入出缓存区等待运输到下一个工位。
根据上述车间特点,将车间生产任务、实时生产状态以及生产统计数据三类信息作为候选特征。定义所有候选特征组成的集合为候选特征集。车间生产任务包含一个/多个订单中各类零件数量;实时生产状态包括入/出缓存区在制品队列、每台机床正在加工的在制品种类以及正在运输的在制品信息四类在制品状态信息,还包括设备状态(“加工中”“等待中”“故障中”“维修中”)和设备负载两类设备运行状态信息;生产统计数据包括机床正在加工的在制品加工时长、机床利用率及其持续加工时长、订单中各类未开工零件数。
车间各生产要素相互影响,部分数据特征相互依赖,候选特征集具有一定的冗余性。冗余特征会造成计算复杂度急剧上升、预测模型训练困难及精度下降等问题,所以提出一种基于SOM-FWFCM的特征选择算法来实现关键特征选择,减少计算复杂度,提高预测精度。
2 特征选择算法

图1 基于SOM-FWFCM算法的特征选择流程图Fig.1 Flow chart of feature selection based onSOM-FWFCM algorithm
SOM-FWFCM是一种在聚类过程中考虑特征与预测目标之间相关性的过滤式特征选择算法,摆脱了FWFCM算法需设置初始聚类中心的困扰,避免了聚类过程的盲目性,实现了高质量的关键特征选择,算法的总体流程如图1所示。首先通过互信息[17]量化特征与目标之间的关联关系程度来定义任意特征对预测目标的重要因子,即特征权重;其次将候选特征集输入SOM网络,确定FWFCM的初始聚类中心和簇数;然后不断迭代更新FWFCM的聚类中心和特征隶属度,实现导向性特征聚类;最后剔除冗余特征,得到订单剩余完工时间预测的关键特征子集。
2.1 特征权重
互信息是一个随机变量包含另一个变量的信息量的度量,能够表达任意特征与输出向量之间的相关程度[18]。两个随机变量x和变量y的互信息定义如下:
(1)
其中,l表示随机变量x或变量y的维数,x={x1,x2,…,xl},y={y1,y2,…,yl},I(x,y)表示变量x和变量y的互信息,p(xi,yj)表示x=xi且y=yj的概率,p(xi)表示x=xi的概率,p(yj)表示y=yj的概率。当变量x和变量y相互独立时,p(xi,yj)=p(xi)p(yj),互信息I(x,y)=0;变量x包含变量y信息量越多,互信息I(x,y)的值越大。
任意特征对预测目标的解释能力可以用互信息衡量,换言之,互信息可以量化任意特征对预测目标的重要程度。定义描述特征重要程度的特征权重为
(2)
其中,wi表示第i个特征的权重,I(fxi,fy)表示第j个特征fxi与预测目标fy的互信息,n表示候选数据特征集的特征数。I(fxi,fy)的值越大,对目标的解释能力越强,特征越重要,特征权重越大。
2.2 SOM-FWFCM算法
SOM网络能够自动对输入数据进行聚类,并且容易实现,但精确度不高;而模糊C均值(FCM)算法具有良好的聚类准确度,但聚类前必须确定初始聚类中心或初始隶属度。本文将SOM网络和FCM算法相结合,保证FCM算法初始聚类中心的可靠性,提高聚类结果的准确度。
SOM网络将高维特征集映射到低维空间(一般为二维),并拥有在高维空间的拓扑结构[19]。将某个特征输入SOM网络中,计算输出层获胜神经元,即该特征在低维空间中的位置,映射在同一位置的输入特征划分为同一簇。在训练网络过程中,首先确定输出层拓扑结构(a×a),初始化权向量W,设定初始学习率及迭代次数;然后计算输入特征对应的获胜神经元,根据获胜神经元确定周边兴奋神经元的空间位置,即优势领域;最后更新兴奋神经元携带的权向量,缩小权向量与输入特征集之间的距离,不断迭代直至最大迭代次数。权向量更新规则如下:
Wi,j=Wi,j+η(t)|pxi-Wi,j|
(3)
(4)

(5)
其中,Wi,j表示第i个输入神经元节点与第j个输出神经元之间的连接权重,η(t)表示第t次循环的学习率,pxi表示第i个输入神经元的输入,η0表示初始学习率,r(t)表示t次循环的优势领域半径,T表示最大迭代次数。
FCM算法[20]通过隶属度确定每个对象属于某个聚类的程度,最大化同一簇对象的相似度,同时最小化不同簇之间对象的相似度。与隶属度只能为0或1的硬聚类算法相比,FCM算法更加符合现实要求,有着更好的聚类精度。FCM算法在训练迭代过程中,仅根据特征空间分布情况进行标记,完全独立于预测目标,这导致聚类缺乏一定的导向性。特征权重搭建特征与预测目标关联的桥梁,特征权重值越大,该特征对预测目标的影响越大,被选择为特征代表的可能性越大,在聚类过程中将其加以考虑,提高关键特征选择的有效性和预测准确度。本文称引入特征权重的FCM算法为FWFCM算法。定义FWFCM算法的数学模型如下:
(6)
(7)
其中,J表示FWFCM算法的目标函数;kc表示聚类中心数;wj表示第j个特征权重;μi,j表示第j个特征属于第i个聚类中心的隶属度;m表示模糊权重,取值范围为[1,∞],通常取m=2[21],ci表示第i个聚类中心。
将上述有条件极值问题转化为无条件极值问题,构造拉格朗日函数,引入拉格朗日因子,使得目标函数取得极小值,即
(8)
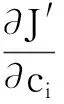
(9)
(10)
(11)
i=1,2,…,kcj=1,2,…,q
其中,λ表示拉格朗日因子,λ={λ1,λ2,…,λn},Δf表示第t次相对于上次的隶属度改变量最大值。FWFCM算法迭代过程如下:①使用式(10)~式(11)计算每个特征的权重;②根据SOM网络得到初步的聚类结果及FWFCM的初始聚类中心,并初始化隶属度矩阵;③计算每个特征的隶属度,若Δf小于预设阈值,则算法结束,否则转入步骤④;④更新kc个聚类中心,转入步骤③。
FWFCM算法迭代结束后,根据隶属度矩阵对各特征进行类别划分,选取离簇中心最近的特征为该类的特征代表,构成关键特征子集。
3 案例分析
本文以某航天机加车间的19 648条生产数据为例进行实例验证,将候选特征集输入SOM-FWFCM、FWFCM、SOM-FCM、层次聚类[13](hierarchical clustering, HC)和权重K均值(weighted K-means,WK-means)聚类五种特征选择算法中,得到关键特征子集,以关键特征子集为输入训练人工神经网络(artificial neural network, ANN)完成剩余完工时间预测,对比分析聚类性能和预测结果准确度,验证本文所提方法的有效性。
通过反复试验,选择特征选择算法性能较好的参数如下:SOM网络结构为15×15,迭代次数为100,初始学习率为0.5,FWFCM算法阈值为0.001。在聚类过程中,候选特征集属于无类别标签数据,选用Calinski-Harabaz(CH)系数和轮廓系数(silhouette coefficient, SC)度量聚类性能,计算公式如下:
(12)
(13)
(14)
(15)

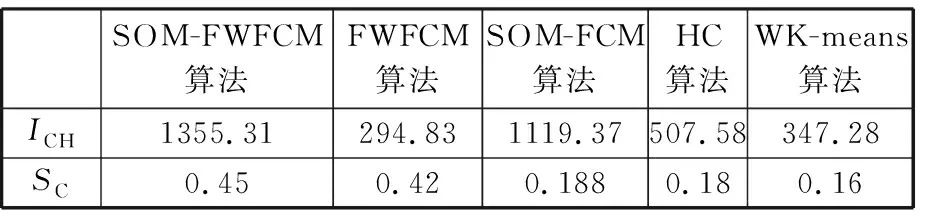
表1 不同算法的聚类结果分析
根据SOM-FWFCM算法从1102个候选特征中选择69个特征构成关键特征子集,见表2,将其输入ANN中,对比预测值与实际值的差值。若差值越小,表示预测越准确,所选特征越有效,特征选择算法越具有优越性。

表2 订单剩余完工时间预测关键特征子集
本文使用常用的均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)、平均绝对百分比误差(mean absolute percentage error, MAPE)来评价预测准确性,计算公式如下:

(16)
(17)
(18)

在ANN训练过程中,以RMSE值与L2正则项之和为损失函数,并加入Dropout层[22],改善网络的过拟合现象。如图2所示,红色线表示训练集优化过程,蓝色线表示测试集的测试过程。在网络优化过程中,模型以较快的收敛速度收敛至较小值,并且具有较强的泛化能力,即训练集预测误差和测试集预测误差接近。图3描述的是从测试集中随机挑选200个样本作为预测对象,红色线表示样本真实值,蓝色线表示对应样本的预测值。由图3可以看出,预测值与实际值的变化方向和幅度非常接近,并且预测值与实际值几乎重合。由于车间存在不确定的扰动,导致图3中极小部分预测值偏离实际值,造成预测不准确的假象,但总体而言,本文方法得到的剩余完工时间

图2 SOM-FWFCM-ANN的优化过程Fig.2 Optimization process of SOM-FWFCM-ANN

图3 SOM-FWFCM-ANN的预测结果Fig.3 Prediction results of SOM-FWFCM-ANN
预测值具有较高的准确度,能够满足现实车间生产要求。
为验证本文所提出的特征选择方法的有效性,进行以下实验:使用上述5种特征选择算法筛选得到相应的具有69、62、91、102、100个特征的关键特征子集,对不同的关键特征子集搭建ANN,预测订单剩余完工时间,5种算法分别简称为SOM-FWFCM-ANN、FWFCM-ANN、SOM-FCM-ANN、HC-ANN 、WK-means-ANN。如图4所示,分别以蓝色线、绿色线、红色线、青色线、黄色线表示这5种算法在测试集上的测试过程,HC-ANN、WK-means-ANN虽然以较快的速度收敛,但由于关键特征子集质量较差,导致推理能力欠缺,易陷入局部最优解;相对而言前三者预测精度较高,尤其在聚类过程中引入特征权重,考虑特征与目标之间的相关性,使特征选择过程具有一定的导向性,提高了关键特征子集质量以及预测精度。表3通过RMSE、MAE、MAPE三个评价指标直观地描述了5种模型与实际问题的拟合程度,可以看出SOM-FWFCM-ANN模型拟合程度最高、最准确,准确度从高到低依次是SOM-FWFCM-ANN、FWFCM-ANN、SOM-FCM-ANN、HC-ANN、WK-means-ANN。

图4 不同模型的优化过程Fig.4 Optimization process of different models

表3 不同模型的结果对比
从本实验可以得到以下结论:①SOM网络为FWFCM算法提供的初始聚类中心优于随机初始化聚类中心,提高了后者寻找最优解的能力;②在聚类过程中考虑特征权重,增加了重要特征在迭代计算过程的影响力,提高了聚类质量和特征选择的有效性;③基于SOM-FWFCM的特征选择模型能够选择反映车间运行规律的关键特征子集,减少了后续预测分析的运算复杂度,为订单剩余完工时间的精准预测提供了基础,证明了本文算法在复杂离散制造车间应用的可行性。
4 结语
本文通过分析每个候选特征的重要程度和关键特征子集的冗余性和多样性,提出了一种适用于大规模数据集的特征选择算法,即SOM-FWFCM算法。通过分析5种特征选择算法聚类结果的类内凝聚度和类间分散度、订单剩余完工时间预测值的准确度,验证了本文所提算法的有效性。在后续研究中可以使用本文所选择的关键特征进一步研究预测模型,提高预测的准确度,以及预测时发现车间生产任务不能按时完成,应采取何种调整策略来保证订单按时交付。
