采用CNN-SSD的雷达HRRP小样本目标识别方法
2021-04-30郭泽坤王鹏辉刘宏伟
郭泽坤,田 隆,韩 宁,王鹏辉,刘宏伟,陈 渤
(1.西安电子科技大学 雷达信号处理国家重点实验室,陕西 西安 710071;2.中国人民解放军32181部队,陕西 西安 710032)
雷达高分辨距离像(High Resolution Range Profile,HRRP)是由宽带雷达信号获取的目标散射中心子回波沿雷达射线投影的向量和,它包含了目标散射中心的分布信息、目标结构以及目标尺寸等重要特征[1-3]。与合成孔径雷达(SAR)等相比,雷达高分辨距离像具有稳定、易于获取和处理的特点[4]。随着宽带雷达以及雷达自动目标识别技术(RATR)的发展,雷达高分辨距离像已成为备受关注的研究热点。
雷达目标识别系统包括预处理、特征提取和分类三部分[3]。在进行目标特征提取及分类之前,通常会经过数据预处理消除原始信号的3个敏感性[2-3]。有大量研究表明,提取具有鉴别性的特征对于提高雷达高分辨距离像目标识别性能至关重要[5]。浅层统计识别模型虽然对训练样本量要求不高,但是其性能严重受限于其线性的建模方式,导致模型对数据的特征提取能力不足,这类经典的方法包括因子分析(Factor Analysis,FA)模型[6]、最大相关系数法(Maximum Correlation Coefficient,MCC)[7]以及自适应高斯分类器(Automatic Gaussian Classifier,AGC)等[8]。文献[1]提出了多任务稀疏学习的统计建模方法,通过挖掘不同任务间共享的结构信息降低了模型对数据量的需求,在雷达高分辨距离像库内小样本识别中取得了不错的性能。为了提高模型对数据的特征提取能力,得益于深度学习在模式识别中的快速发展,以深层神经网络为代表的特征提取方法也被广泛应用于雷达高分辨距离像的特征提取。针对雷达高分辨距离像小样本识别问题,文献[3]首先通过批归一化算法改进了卷积神经网络收敛慢的问题,然后对雷达高分辨距离像进行自动特征提取,再利用支持向量机(SVM)对其进行分类;文献[4]提出了一种基于迁移学习的雷达目标识别方法,该方法首先在大样本雷达高分辨距离像数据上训练得到一个初始卷积神经网络模型,再结合飞机目标识别任务调优模型参数,显著改善了模型在小样本条件下的目标识别能力。然而,这两种方法仍然是基于库内小样本识别场景,无法实现对库外非合作目标的高效泛化。文献[6]利用元学习实现了对于库内目标的库外姿态角的快速泛化;然而,该方法仍然假设测试样本的类别是训练集中见过的。
笔者提出一种基于卷积神经网络模型连续自蒸馏(Convolutional Neural Network Sequential Self-Distillation,CNN-SSD)的雷达高分辨距离像非合作(库外小样本)目标识别方法。一方面通过连续自蒸馏机制对类别间的相关性进行建模,提高了模型提取特征的泛化能力,同时利用集成学习的思想对连续自蒸馏进行改进,实验表明改进后的模型对非合作目标的特征提取的泛化能力更强;另一方面,考虑到基于梯度下降优化得到的分类器性能受观测数据量影响较大[9],采用了基于优化的具有闭式解的线性分类器对蒸馏得到的非合作目标的特征进行分类。文中主要讨论了两种满足条件的分类器,它们分别是:支持向量机(SVM)和逻辑回归(Logistic)。
1 采用CNN-SSD的雷达高分辨距离像小样本目标识别方法
1.1 定义目标识别小样本训练任务
定义小样本目标识别模型训练数据Dm={(X,y)},其中共有C类样本,X为训练集,y为标签,通过Dm进行训练,获取特征提取器。该过程为
(1)
其中,Lce为交叉熵损失函数,φ为特征提取网络参数,θ为梯度下降优化下的分类器参数。
然后,以具有闭式解的线性分类器为基学习器进行分类器训练:
(2)
其中,θlc为具有闭式解的线性分类器参数;A为基学习器,表达式为y*=fθlc(X*),下标*表示s或q;特征提取网络参数φ在该过程中保持不变。
(3)
其中,Lmeta为损失函数,m为平均类别准确率(Mean Class Accuracy,MCA)。
1.2 基于自蒸馏模型改进的神经网络
基于自蒸馏模型改进的卷积神经网络训练过程如图1所示,它分成两个子过程:基模型训练过程和子模型蒸馏提取过程。在基模型训练环节,通过雷达高分辨距离像训练数据Dm获取基模型,用于子模型的蒸馏提取;在子模型蒸馏提取环节,通过对所训练的基模型进行模型连续自蒸馏,获得G代子模型,并以最后一代(第G代)改进的神经网络模型作为特征提取器对非合作小样本目标提取特征。

图1 自蒸馏模型改进的卷积神经网络训练及测试流程
1.2.1 基模型训练
(a) Softmax函数
通过式(1)的方式训练卷积神经网络。该过程中交叉熵损失函数通过Softmax进行计算[10]:
(4)
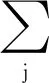
令T>1,这样会使Softmax函数曲线更加平滑,突出了不同类别之间的相关性,同时兼顾了类别之间的绝对关系保持不变[11]。因此,以新的概率分布pi为监督信息,更易学习到性能更加鲁棒的子模型。
(b) 基模型集成

(5)
其中,Φ为集成模型对样本提取的特征向量,φi表示第i个基模型的参数。

(6)
其中,Φi和Φj分别为类别i和类别j通过集成模型所提取的特征向量。
集成后的基模型参数在以后的学习中固定不变,不再更新。
1.2.2 子模型蒸馏提取

(7)

式(7)可以进一步展开成下式:
(8)
(9)
其中,φ1为需要学习的子模型参数。
在此过程中,通过学习率自适应算法Adam优化的方法最小化LKD,从而得到的子模型称为第1代子模型,该过程称之为模型知识蒸馏。将分类和模型知识蒸馏的目标联合起来,可以将第一代子模型的优化目标表示为
(10)
其中,β=1-α,表示均衡因子,用于平衡不同目标函数对模型参数学习的影响。
为了实现多代模型连续自蒸馏,进一步引入了网络自生机制[12],对第1代子模型继续进行知识蒸馏。以第1代子模型与第2代初始子模型的输出类别概率分布继续进行上述训练过程,直至第G代,得到了第G代子模型。该过程如下:
(11)
其中,φG-1和φG分别为G-1和G代模型所学参数,f(Dm,φG-1)和f(Dm,φG)分别为G-1代和G代子模型概率分布。选择第G代子模型为最终的特征提取器,用于对仅有少量观测样本的非合作目标进行特征提取。模型连续自蒸馏可以在训练数据集上模型性能不降低的前提下迭代多代进行训练,新代的子模型会在其上一代子模型的基础上引入新的自由度(由初始化带来的),因而能够快速准确地泛化到未知的新的类别中去。在实验中,笔者经验性地给出了该结论成立的边界条件。
1.3 分类器
具有闭式解的线性分类器,如支持向量机、逻辑回归以及岭回归等,对于训练样本数稀疏的场景,它们具有易于快速优化求解的特点[9]。因此,笔者采用向量机、逻辑回归对自蒸馏模型提取到的特征进行分类。
2 实验结果与分析
2.1 实验数据
为了验证所提出的基于雷达高分辨距离像的非合作目标小样本识别方法的有效性,首先通过三维制图软件构建50类飞机的3D模型;然后通过高频电磁计算软件对该50类飞机的模型进行电磁仿真,得到飞机目标的宽带电磁散射数据。对该数据进行逆傅里叶变换(IFFT),进而得到飞机模型的一维距离像(HRRP)。仿真参数如表1所示。

表1 电磁散射计算参数
对50类飞机在84°俯仰角下进行电磁计算,每类目标的每个俯仰角有3 200个雷达高分辨距离像样本,每类目标的方位角覆盖范围为10.05°~90°。图2展示了50类飞机中部分飞机的三维模型及对应的一维距离像。

图2 部分飞机目标三维模型及仿真一维距离像
为了克服雷达高分辨距离像敏感性问题,笔者参照文献[2]对所得到的一维距离像数据进行能量归一、重心对齐处理,得到预处理之后的一维距离像。注意,对于所使用的统计模型,笔者对上述处理过后的距离像再进行分帧,以克服姿态敏感性;对于基于深度模型的其他方法,笔者不进行此操作。
2.2 实验设置
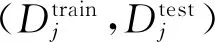
在模型结构及超参数设置方面,采用三层卷积神经网络作为基础网络模型[13]。第1层输入通道数为1,输出通道数为32,步长为9;第2层输出通道为64,步长为9;第3层输出通道为128,步长为9。最后通过全连接层,将卷积输出的特征转化为向量。另一方面,设置Softmax的温度系数T为4,并固定不变。设置式(10)~(11)中均衡因子系数α为0.4。根据1.3节的介绍,使用支持向量机和逻辑回归作为分类器,对比分析在K等于1、5和10个样本的条件下,非合作(库外)目标的识别结果。
2.3 实验结果分析
为了验证笔者所提方法(CNNSSD-SVM和CNNSSD-Logistic模型)的有效性,将其与多个基线算法进行了定量和定性的分析比较,见表2。其中,SVM是按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面[9-10]。Logistic属于对数线性模型,其本质是假设数据服从高斯分布,然后使用极大似然估计做参数估计[10]。AGC属于统计识别模型的一种,通过计算每类每帧样本的均值及方差作为模板库,对测试样本进行匹配识别[8]。CNN-FC是利用卷积神经网络提取特征并用全连接网络分类的方法,该方法在测试阶段在非合作目标上对全连接网络进行微调。CNNSSD-SVM和CNNSSD-Logistic为基模型集成之后通过连续自蒸馏迭代3次,将得到的第3代子模型作为特征提取器,通过SVM和Logistic对提取的特征进行分类的方法。
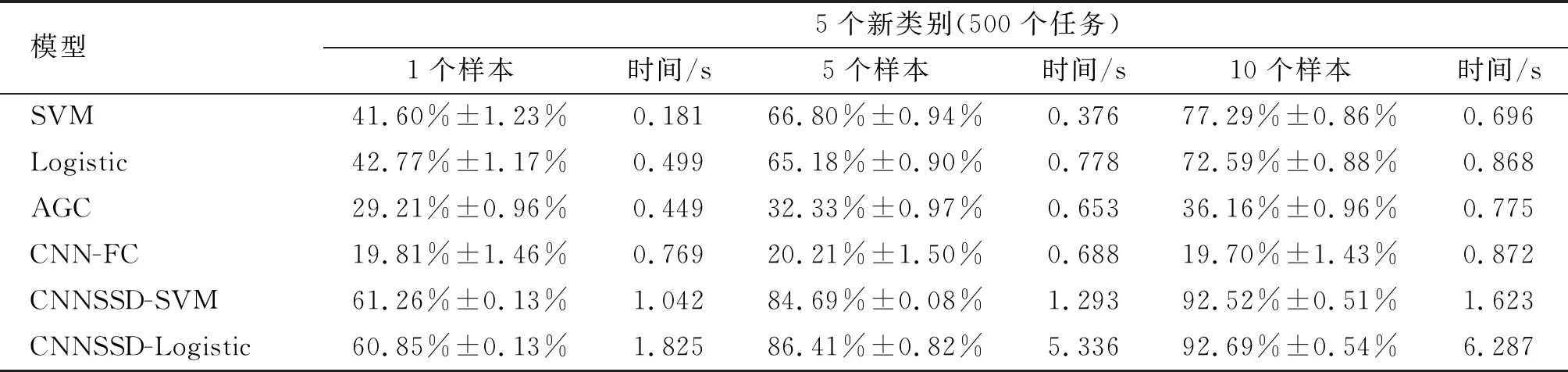
表2 小样本识别方法准确率对比
对于识别能力而言,模型对5类飞机进行识别,不训练模型进行随机猜测的识别正确率应不低于20%。如表2所示,SVM和Logistic具备对非合作目标小样本识别的能力,并且随着样本数增多,其识别能力提升明显。以SVM为例,每类10个样本时的性能较每类1个样本的性能提高超过30%;而AGC则由于样本维度远高于样本数量,导致其协方差矩阵估计较差,其性能远低于其他两种浅层的基线模型。CNN-FC这种基于非合作目标微调分类器的方法在每类样本数不超过10的情况下,其识别准确率约为20%,因此不具备识别能力,说明这类具有闭式解的线性分类器(浅层模型)在小样本非合作目标识别任务中较基于新数据微调的深度模型更鲁棒。另一方面,笔者所提出的CNNSSD-SVM和CNNSSD-Logistic方法相较于浅层模型SVM和Logistic,在1个样本的实验中准确率分别提高了19.66%和18.08%,在5个样本的实验中准确率分别提高了17.62%和21.23%,在10个样本的实验中准确率分别提高了14.43%和20.10%。由此可见,笔者所提方法相较于SVM和Logistic方法其识别准确率更高,说明连续自蒸馏有利于模型学习到更具泛化能力的关于非合作目标的特征表示。
另一方面,笔者进行了如表3所示的消融实验,验证了自蒸馏模型和连续自蒸馏模型以及分类器的选择对非合作目标小样本识别能力的影响,共对所提方法的6种变体进行了实验。其中,CNN-SVM和CNN-Logistic为卷积神经网络提取特征,分别利用SVM和Logistic对所提特征进行分类。CNNKD-SVM和CNNKD-Logistic为通过模型知识蒸馏获取特征提取器,并分别通过SVM和Logistic进行分类。CNNSSD-SVM和CNNSSD-Logistic如上所述。
如表3所示,以基于SVM分类器的3种变体为例(下面3行),在非合作目标每类带标注训练样本数为1、5和10的条件下,笔者所提方法与CNN-SVM性能相比均提高2%左右,与CNNKD-SVM相比性能也均有所提升,平均涨幅在1%左右。由此可见,笔者所提方法较CNN-SVM和CNNKD-SVM更加准确。对于基于CNN的深层模型的不同变体,从模型关于新的非合作目标的识别时间上来看,笔者所提方法耗时均小于CNNKD-SVM和CNN-SVM。由此可见,笔者所提方法更加高效。

表3 小样本识别率消融实验
最后,通过T-SNE[6]可视化方法对5个样本条件下训练好的SVM、Logistic、AGC、CNN-FC、CNNSSD-Logistic以及CNNSSD-SVM模型在相应的雷达高分辨距离像测试样本上对其预测类别分布情况进行可视化展示,从而定性地对表2得到的数值结果进行解释。可视化结果如图3所示,三角形、正方形、圆点、十字星和五角星这5种不同形状分别代表5种不同类别的非合作目标的样本点。SVM、Logistic、AGC以及CNN-FC的5类样本点分布杂乱,聚集性弱,CNNSSD-Logistic和CNNSSD-SVM的5类样本点分布整齐,聚集性强。因此,在非合作目标小样本识别问题中,笔者所提方法较其他基线方法识别能力最强。

图3 雷达高分辨距离像测试集样本TSNE分类可视化
3 结束语
为了提高模型在小样本条件下对非合作目标雷达高分辨距离像的泛化能力,笔者提出了一种卷积神经网络模型连续自蒸馏(CNNSSD)的雷达高分辨距离像小样本目标识别方法。该方法在类别多样化的完备合作目标训练集上学习一个基模型作为初始的特征提取器,随后基于模型连续自蒸馏机制得到泛化能力更高效的新的特征提取器,最后使用具有闭式解的线性分类器(SVM、Logistic)进行分类识别。基于电磁仿真数据开展了实验验证,结果证明,利用类别多样的完备合作目标训练集,所提方法可以有效地提高模型对非合作小样本目标的泛化能力,实现了对库外样本的快速有效识别。
