Designing and optimizing a parallel neural network model for predicting the solubility of diosgenin in n-alkanols
2021-04-13
School of Chemical&Environmental Engineering,Anyang Institute of Technology,Anyang 455000,China
Keywords:Solubility Diosgenin Parallel neural network model NRTL model
ABSTRACT Accurate estimation of the solubility of a chemical compound is an important issue for many industrial processes.To overcome the defects of some thermodynamic models and simple correlations,a parallel neural network(PNN)model was conceived and optimized to predict the solubility of diosgenin in seven n-alkanols(C1 –C7 ).The linear regression analysis of the parity plots indicates that the PNN model can give more accurate descriptions of the solubility of diosgenin than the ordinary neural network(ONN)model.The comparison of the average root mean square deviation (RMSD) shows that the suggested model has a slight advantage over the thermodynamic NRTL model in terms of the calculating precision.Moreover,the PNN model can reflect the effects of the temperature and the chain length of the alcohol solvent on the solution behavior of diosgenin correctly and can estimate its solubility in the n-alkanols with more carbon atoms.
1.Introduction
The solubility of a chemical compound is an important thermophysical property due to its role in many industrial processes.For instance,in the pretreatment of crude oil,a certain amount of water should be added to the hydrocarbon streams for the purpose of desalting.The removal of hydrocarbon from the waste water is necessary for the environmental protection requirements.The solubility of hydrocarbon in water is obviously an important issue for this removal process[1].Nowadays,the supercritical fluid technology,owing to its many advantages such as high transfer rates and low operating costs,have attracted more interest and been as an excellent alternative to the traditional separation methods.The knowledge of the solubility of a solute in supercritical fluid is important and should be obtained prior to the development of any extraction process using supercritical fluid[2].Moreover,the solubility of solid in liquid solvent describes its solution behavior and therefore can assist us with designing and optimizing the related industrial crystallization processes[3].
Information about the solution behavior of a chemical compound can be obtained from the experimental measurement of solubility data.However,the direct measurement often suffers from expensive experimental apparatus,demanding environmental conditions and strenuous manual labor.In view of these restrictions,many researchers have utilized the theoretical method to calculate the solubility of a chemical compound.Generally,engineers and researchers tend to select the famous thermodynamic models such as the equations of state(e.g.SRK and PR,etc.) and activity coefficient models (e.g.Wilson and NRTL,etc.) to perform the solubility modeling [3,4].These models have a sound theoretical basis and the model parameters can reflect the intermolecular interactions.However,the equations of state have not demonstrated their reliable performances in the wide ranges of temperature,pressure and compounds.Some related studies revealed that the equations of state failed to predict the solubility of highly polar systems accurately [2,5].Also,numerous equations together with arbitrary mixing rules make it difficult to select a suitable model for a particular case[6].As for the activity coefficient models,the limited flexibility of the model parameters is their great defect.Normally,a set of parameters was only valid for a particular system.The calculating precision cannot be guaranteed when the same parameters were applied to other systems[7].For example,the model can give an accurate estimation of the solubility of naphthalene in methanol based on the regression parameters of this system.However,using the same parameters,it failed to calculate the solubility of naphthalene in ethanol accurately.In addition,some simple correlations,as another option,can also be employed as the solubility calculation model.Although these correlations are convenient to use and can yield high precision for the simulated object,they have not exhibited acceptable predictive abilities especially when the experimental data are not available[1,8,9].To circumvent these problems,a more suitable model is needed.
On the other hand,artificial neural network,an artificial intelligence that partly emulates the work mechanism of the human brain,has been tried as an alternative to the traditional model for calculating the physicochemical properties of pure component and mixture [10–15].Employing the neuron nodes and connections as its basic elements,artificial neural network obtains the input–output relationships through the experimental data training.The peculiar structure and operation pattern enable it to conquer the drawbacks of the traditional method when applied to the multi-variable dependent processes[16].
Currently,the structure of neural network is still relatively simple compared with that of the complex human brain.Sometimes it cannot precisely describe the feature of the simulated object.This work aims to investigate and explore the new structure of neural network for better solubility modeling.The solutions of diosgenin in seven n-alkanols(C1–C7)were selected as the model systems to demonstrate the point of interest[17–19].Diosgenin,existing in the certain plant tissues,is mainly used as an important raw material for synthesizing the steroid hormone drugs.It has shown positive roles in treating some diseases such as diabetes and hypomnesia[20–22].Owing to the low cost and easy recovery of solvent,the use of traditional organic solvents to extract diosgenin from some plant roots is still a feasible method in industry.
The main research contents of this work are listed as follows:Firstly,the ordinary neural network(ONN)model was utilized to correlate and predict the solubility data of diosgenin,which included selecting appropriate input and output variables,categorizing the collected data and optimizing the structure of the model.Secondly,for better description of the solution behavior of diosgenin,a parallel neural network(PNN)model was designed based on the above research results.Thirdly,to demonstrate the usability of the suggested model,the accuracy comparison was performed for the ONN,PNN and the classical thermodynamic NRTL model.Finally,the effect of polymorphs on the solubility of a chemical compound and the discrepancy between the kinetic and thermodynamic solubilities were discussed.
2.Ordinary Neural Network Model
2.1.Brief introduction of neural network model
Neural network is a simple modeling method.Unlike the traditional methods often employing the mathematical/physical equations to denote the relations among the variables derived from the simulated object,it consists of the input,middle and output layers formed by a certain number of neuron nodes(Fig.1).Based on these layers,the neural network model can process the input data and product the corresponding output values.Compared with the traditional methods,it has a lower sensitivity to the effect of the number of variables due to the peculiar configuration and operation mode.

Fig.1.Neural network architecture.
As shown in Fig.1,the selected variables enter the network system from the input layer.Then these variables(ei)are endowed with the pre-set weights (wji) and fed to the middle layer.Here each neuron sums the weighted data plus a bias(bmj),and in the meanwhile,applies a transfer function(fm)to the sum:

Afterwards,these resulting values(zj)are passed to the output layer to yield the output values of the model(ok)by undergoing a similar process as given by(wkjand bokdenote the weight between the middle and output layers and the bias of the node in the output layer,respectively):

Generally,the initial output values often deviate from the desired ones,indicating that the model parameters are inappropriate and need adjustment.In the next stage,the error signals,obtained from the output and desired values,are propagated backwardly so as to adjust the model parameters(weights and bias).Then the outputs of the model can be updated based on the new parameters.This process will terminate until the obtained error was reduced to an acceptable level.
In summary,the main operating process of the neural network model includes the forward calculation(the first stage)and the error back propagation(the second stage),which train the model and teach it about the relationship between the input and output variables.Consequently,the model obtains the ability to predict the data(not necessarily from the training data sample)of the simulated object.
2.2.Selecting the input and output variables of the model
The proper input and output variables are very important to the accurate description of the solubility of diosgenin.We considered the following factors for the selection of these variables:Firstly,the input variables should have the direct correlation with the output.Secondly,the input variables should also be able to differentiate the alcohol solvents herein and reflect the effect of these solvents on the solution behavior of diosgenin.Moreover,some physical parameters of the chemical compound,such as the density and viscosity,are not recommended as the input of the model since these parameters may not be readily available.The use of them will increase the complexity of the model and therefore affect its practicability.Based on these principles,the solid–liquid equilibrium temperature(t)and three thermodynamic parameters of n-alkanol solvents including critical temperature (tc),critical pressure(pc)and acentric factor(ω)were initially selected as the input variables of the model.Here,t and tcwere integrated into the reduced temperature(tr)for simplification:

To better reflect the effect from the structure of different solvents on the solution behavior of diosgenin,the normal boil temperature(tb)of n-alkanol,which increases with the increasing carbon chain length,was also introduced as an input of the model.Here it should be noted that all the variables related to the temperature(t,tc,tb)use“°C”instead of“K”as the unit,which have adequate gradient and therefore can better accommodate the change of the solubility data with different temperatures.Finally,the parameters including tr,pc,ω and tbwere selected as independent variables while the solubility of diosgenin (s,mol·mol-1) wasinvestigated as a response.To ensure the convergence of the model,pc,tband s were handled in terms of magnitude(Table 1).

Table 1 Distribution of the collected experimental solubility data and the parameters of the solvents used in this work
2.3.Division of the collected experimental data
In order to optimize the structure of neural network and obtain a reliable solubility model of diosgenin,the rational division of the collected experimental data is necessary.In this work,the solubility data of diosgenin in seven n-alkanols(C1–C7)totaling 117 experimental data were categorized into the training(C1–C4and C7,80 data points,68%),validation (C5,19 data points,16%) and testing (C6,18 data points,16%)data sets(Table 1).Such a division guarantees the data distribution of the validation and testing sets can be incorporated into that of the training set,exhibiting a good consistency.The training and validation data sets were used to teach the model about the input–output relationships and prevent the overfitting problem.The testing data set was employed to verify the predicting ability of the model.
2.4.Determining the number of the nodes in the middle layer
The numbers of the nodes in the input and output layers correspond to those of the variables in them.However,the node number of the middle layer should be determined in the process of network training.It is crucial for the neural network model due to its close relation with several cases such as the convergence of network,calculating precision and overfitting problem.Here,the convergence of network implies the following relation was met:

where Ntrais the number of the solubility data points in the training data set.Si,caland si,expdenote the ith calculated and experimental values of solubility,respectively.
The alteration of the node number of the middle layer or SE can affect the calculating precision of the model,which was given a detailed investigation and the corresponding results were summarized in Table 2.Here,the root mean square deviation (RMSD,the lower RMSD denotes the higher precision) was used to denote the calculating precision of the model.From Table 2 it can be seen that:(1) Too few node number(=1)of the middle layer will lead to the non-convergence of the neural network model.(2)When the value of the SE is fixed,altering the node number of the middle layer can only affect the calculating precision of the validation set rather than that of the training set.On the other hand,keeping the node number of the middle layer unchanged,the precision of the training set shows a monotonically increasing trend with the decrease of the SE.However,for the validation set,a minimum value of the RMSD(bold text)was observed in every case.The precision of the validation set increases before this value.After this,it presents a declined tendency although the precision for the training set is still increased.Such a situation indicated the occurrence of the overfitting problem that can affect the generalization capacity of the model[23].To avoid this problem,the network training should terminate at this point.This method was described as“early stopping”[24].The value of the SE at this point is optimal for the corresponding topology structure.(3)The cases of more nodes in the middle layer(>10,e.g.=15,20,25)were also studied.The results reveal that these cases only make the model structure become more complicated but fail to improve its ability to describe the solubility data of diosgenin.Consequently,these cases were not studied further and also not shown in Table 2.
In order to determine the suitable number of the nodes in the middle layer,the above topology structures and their optimal SE values,together with the corresponding RMSDs of three data sets(training,validation and testing sets),were summarized in Table 3.Here,it should be noted thattwo values of the SE(0.1,0.15)were considered for the topology of{4,5,1}because their corresponding RMSDs for the validation set (0.0368,0.0363)are very close.Based on the comprehensive evaluation on the three RMSDs obtained from each topology structure,we consider{4,7,1}as the best topology structure of the ONN model(bold text)due to its highest precision for the testing set and the most balanced RMSDs for three data sets.The RMSDs for three data sets can be given by:

Table 3 Comparison of the RMSDs(training,validation and testing data sets)obtained from the different topology structures(ONN model)

Table 2 RMSDs(training and validation data sets)based on the different topology structures and system errors(ONN model)

Fig.2.Schematic illustration of the PNN model.

3.Parallel Neural Network Model
3.1.Basic concept of the parallel neural network model
Based on the research result of the ONN model,we attempt to explore a new structure of the model for possible improvement of calculating precision.Here,a PNN model was conceived and designed to achieve this goal,which was inspired by the design principle of the circuit.In the structure of the PNN model,one rectangle box represents one middle layer and the figure inside denotes the number of the neuron nodes it contains.These middle layers share common input and output layers but are independent to each other(Fig.2).The input variables were parallelly processed in every independent input-middle-output data channel,here described as a branch network,and then the output of each branch network was obtained.The operation of the branch network is almost the same as the ordinary network,namely feed-forward and error back propagation mode.Finally,the parallel model integrated the outputs of all the branch networks(sm)using its parameters(Wmand B),and the resulting output(S)is much closer to the desired one.The integration process can be performed by the multiple linear regression function in ORIGIN®(version 8.5):

3.2.Optimizing the structure of the parallel neural network model
The number of the middle layer and the node number of each middle layer need to be determined for optimizing the structure of the PNN model.We actually have made some preliminary preparation for this task while the structure of the ONN model was investigated.As shown in Table 3,these topology structures of ONN model were separated into two groups with the SE=0.1 as the dividing line.The research results indicate that employing the topology structures in the first group(the node number=2,4,5(SE=0.1),7 and 8)as the branch networks of the PNN model can enhance the calculating precisions for all three data sets.However,it does not yield the same effect if those in the second group(the node number=1,3,5(SE=0.15),6,9 and 10)were also employed.In the following work,we will demonstrate how to further optimize the structure of the PNN model based on the topology structures of ONN model in the first group.
To screen the suitable middle layers for the PNN model,the strategy of adding one new middle layer to the model at a time was adopted.The obtained topologies and corresponding RMSDs were summarized in Table 4.In the left column,the node number of the newly added middle layer increases orderly,while it presents a decreasing situation in the right column.Here,the calculating precisions of different topology structures were still represented by the values of RMSD (the lower RMSD value denotes the higher precision).From Table 4 it can be seen that:(1)As for the training set,the topology structures in the left column exhibit slightly higher precisions than those in the right column.However,for the validation and testing sets,the former precisions were obviously inferior to the latter.(2)In the right column,compared with the first and the third structures,the second one can yield thehigher calculating precision for the validation and testing data sets,although its calculating precision for the training set is slightly lower than the third structure.Based on the comprehensive evaluation on the calculating precisions of each topology structure for three data sets,we preliminarily consider{4[8,7,5],1}as the best topology structure of the PNN model(bold text).

Table 4 RMSDs(training,validation and testing data sets)based on the different topology structures(PNN model)

Table 5 Comparison of the RMSDs obtained from{4[5,7,8],1}and other possible topology structures(PNN model)
As a precaution,we also compare this structure with all the possible topologies of the PNN model in term of the calculating precision.The results were summarized in Table 5(not all the cases are listed).Based on these obtained RMSDs for three data sets,we can conclude that the topology structure of{4[8,7,5],1}gives more satisfactory calculating precision for the solubility data of diosgenin than other topologies.It was eventually determined as the best structure of the parallel model.Here,the initial and last figures in the brace are the numbers of the node in the input and output layers,respectively.Those in the bracket denote the numbers of the middle layer node in different branch networks.The corresponding model parameters were listed in Table 6.
4.Results and Discussion
4.1.Evaluating the precision of the parallel model
Firstly,the parity plot was used to assess the abilities of the ONN and PNN models to describe the solubility of diosgenin[6,25].As shown in Fig.3,each data point here is drawn by employing the calculated and experimental values as its two coordinates.Then the obtained scatter points were regressed and the three regression parameters(slope(α),intercept(β)and correlation coefficient(R2))were obtained.The ideal regression line should be diagonal line and the corresponding parame-ters are 1,0 and 1,which indicates that each calculated value exactly agrees with the experimental one.For the validation data set,we can see that the regression line of the ONN model deviates from the ideal one obviously(Fig.3b).This deviation is partly alleviated by the PNN model(Fig.4b).For the training data set,it seems that the regression line of the ONN model and the ideal one coincide completely.However,we still find a little gap between them by careful observation(Fig.3a).Fortunately,this gap can be almost eliminated by the PNN model(Fig.4a).The situation of the testing data set is similar to that of the training data set (Figs.3c and 4c).These cases can also be obtained from the analysis of the corresponding regression parameters of three data sets(Table 7).Based on these parameters,we can conclude that the PNN model further improves the calculating precision compared with the ONN model.

Table 6 Parameters of the optimized PNN model
Secondly,some thermodynamic models,as stated above,can also be utilized to estimate the solubility of solid in liquid solvent.Here,the RMSD related to the solubility data of diosgenin in each alcohol solvent was also calculated based on the PNN model,and then these RMSDs were compared with those obtained from the NRTL equation,a classical thermodynamic model employed to correlate the solubility of diosgenin[19].Table 8 listed the corresponding results.It can be seen that two models have their own advantages in terms of the calculating precision.For the short-chain alcohol solvents(C1–C3),the NRTL equation is superior to the PNN model.However,for the long-chain alcohol solvents(C4–C7),the latter can yield a higher precision than the former.But on the whole,the PNN model has a slight advantage over the NRTL equation according to the average RMSD.
Thirdly,to further assess the ability of the PNN model to represent the solubility of diosgenin,the solubility data obtained from the PNN model were also compared with the experimental values.Here,in addition to the experimental solubility data of diosgenin in seven n-alkanol solvents(C1–C7)measured by Chen et al.[17–19],those in two newly added solvents(1-octanol and 1-nonanol,C8and C9)measured by Moodley et al.[3]were also included in Fig.5.It can be seen that:(1)The solubility data obtained from the PNN model agree well with the experimental values of diosgenin in seven n-alkanol solvents(C1–C7)over the whole temperature range investigated herein.Here,we can see that the increasing carbon chain length of the alcohol strengthens its capacity to dissolve diosgenin.It can be explained that the increasing carbon chain length reduces the polarity of the solvent molecular,making it more compatible with diosgenin.From a molecular perspective,both the molecules of diosgenin and alcohol solvent contain the hydroxyl that forms the hydrogen bond.Diosgenin can be dissolved in the alcohol solvent mainly through the hydrogen bonding interactions between them.For the alcohol solvent herein,longer carbon chain has a better electron donating ability,making the oxygen atom in the hydroxyl possess more negative charges.As a result,the hydrogen bonding interactions between the molecules of diosgenin and alcohol solvent are enhanced,giving a better compatibility between them.(2) The experimental solubility data of diosgenin in 1-nonanol over the lower temperature range(T<310 K)are higher than those in 1-heptanol,showing the same trend as that exhibited by the seven n-alkanol solvents.The solubility data obtained from the PNN model can also match well with these experimental values.However,the experimental solubility data of diosgenin in 1-nonanol over the higher temperature range(T>310 K)do not show the same trend.Consequently,an obvious deviation between the experimental and calculated data occurs.As mentioned above,the experimental solubility data of diosgenin in 1-nonanol and those in seven alcohol solvents are measured by different working groups.The trends these obtained experimental data exhibit are inconsistent probably due to the discrepancies of the experimental factors such as the chemical suppliers,reagent purity,measurement equipment and methods.(3)The solubility data of diosgenin in 1-octanol is lower than the expected values.It is observed that the experimental solubility data(measured by Moodley et al.)have some overlaps with those in the 1-butanol and 1-pentanol(measured by Chen et al.).The main cause of this abnormal phenomenon is not clear yet and needs to be further studied.In such a situation,it is difficult for the PNN model to give an accurate description of the experimental solubility data of diosgenin in 1-octanol.We can see that the corresponding data calculated by the PNN model are higher than the experimental values in 1-heptanol,still conforming to the above trend.

Fig.3.Parity plots of calculated versus experimental solubility of diosgenin:(a)training data set(b)validation data set and(c)testing data set(ONN model).

Fig.4.Parity plots of calculated versus experimental solubility of diosgenin:(a)training data set(b)validation data set and(c)testing data set(PNN model).

Table 7 Linear regression parameters comparison between the ONN and PNN models
4.2.Discussing the effect of polymorphs on the solubility of a chemical compound and the discrepancy between the kinetic and thermodynamic solubilities
As we know,the solubility of a chemical compound is affected by its solid state form.The related literature indicated that the solubility of thecrystalline material is very different from that of the amorphous material[26].However,the differences between different polymorphs and pseudo-polymorphs including solvates are reduced evidently[27].The solubility of diosgenin in seven alcohols was determined by Chen et al.They observed at least two crystal forms of diosgenin including the crystal obtained from acetone and the solvate formed by diosgenin and methanol solvent.The research result revealed that the diosgenin used for solubility determination has the same crystal form as the former [28].Moreover,the solubility of diosgenin in 1-octanol and 1-nonanol was measured by Moodley et al.As mentioned above,the solubility data obtained from these two working groups exhibit an inconsistent trend in a certain temperature range.Another possible cause of this issue is the different crystal forms of diosgenin used in their respective works.
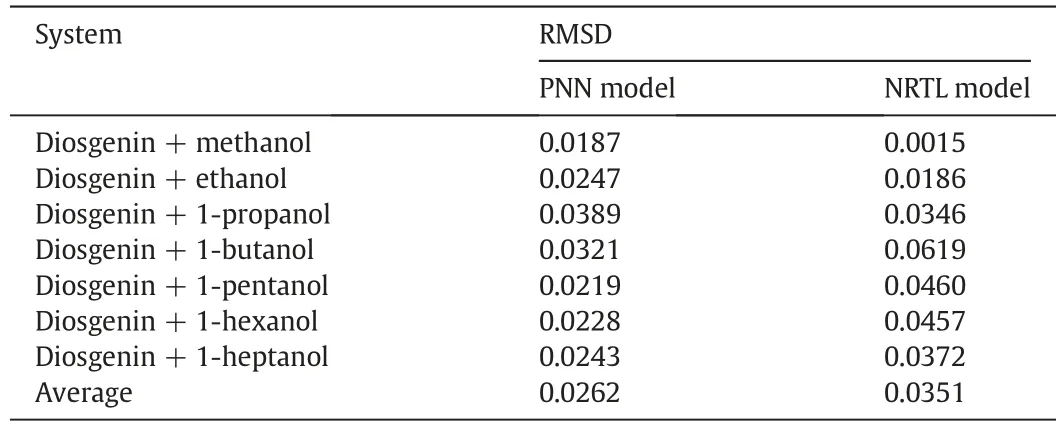
Table 8 Comparison of the RMSDs obtained from the PNN and NRTL models for each system

Fig.5.Comparison of the experimental solubility data of diosgenin in n-alkanol solvents and calculated values from the PNN model(the relative uncertainties in the solubility measurement of diosgenin are 0.03 and 0.08 for C1 –C7 and C8 –C9 solvents,respectively).
Secondly,we discuss the concepts of the kinetic and thermodynamic solubilities.Thermodynamic solubility represents a result from an equilibrium state,beyond which a change in the solid state form of dissolved compound might occur(e.g.change from amorphous to crystalline state).However,the kinetic solubility assay generally does not offer compound the sufficient time to precipitate as crystalline state.As a result,it frequently overestimates solubility compared to thermodynamic solubility[29].We recommend thermodynamic solubility for the optimization of industrial crystallization processes instead of kinetic solubility,because the latter could guide chemists in a wrong direction.
5.Conclusions
The objective of this work is to explore the new structure of neural network model to calculate the solubility of diosgenin more efficiently.Based on the research result of the ONN model,a parallel model was introduced to improve the calculating accuracy.Without the mixing rules or binary interaction parameters as required by traditional thermodynamic models,the solubility data of diosgenin can be obtained from the PNN model if the pure component properties of the alkanol solvents herein(C1–C7)are available.The suggested model can also be employed to estimate the solubility of diosgenin in the n-alkanols containing more carbon atoms due to its rational design concept.The obtained RMSDs and regression parameters of parity plot show that the PNN model has some advantages over the NRTL equation and the ONN model in terms of calculating accuracy.Moreover,it can correctly reflect the effects from the temperature and carbon chain length of alkanol on the solubility behavior of diosgenin.Despite these advantages,the neural network model has not given its model parameters any physicochemical meanings so far.It only uses the simple input–output mode to obtain the high precision and neglects in-depth study on the mechanism of the research object.In order to disclose the relations between the model parameters and the simulated object,more researches on the fundamental theory of neural network are necessary.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This work was supported by the Science and Technology Plan Project of Henan Province(No.192102310232).
Supplementary Material
Supplementary data to this article can be found online at https://doi.org/10.1016/j.cjche.2020.09.009.
杂志排行

Chinese Journal of Chemical Engineering的其它文章
- Highly interconnected macroporous MBG/PLGA scaffolds with enhanced mechanical and biological properties via green foaming strategy
- Perspectives and challenges of hydrogen storage in solid-state hydrides
- Wet flue gas desulfurization performance of 330 MW coal-fired power unit based on computational fluid dynamics region identification of flow pattern and transfer process
- EMMS-based modeling of gas–solid generalized fluidization:Towards a unified phase diagram
- Using expansion units to improve CO2 absorption for natural gas purification-A study on the hydrodynamics and mass transfer
- Simulation and experimental study on the surface morphology and energy lost of the target material under non-overlapping impact of angular particles