Metaphor Analysis Method Based on Latent Semantic Analysis
2021-04-08TAORanWEIYaping卫亚萍YANGTangfeng杨唐峰
TAO Ran(陶 然), WEI Yaping(卫亚萍), YANG Tangfeng(杨唐峰)
1 School of Computer Science and Technology, Donghua University, Shanghai 201620, China
2 College of Foreign Languages, Donghua University, Shanghai 201620, China
Abstract: Current research on metaphor analysis is generally knowledge-based and corpus-based, which calls for methods of automatic feature extraction and weight calculation. Combining natural language processing (NLP), latent semantic analysis (LSA), and Pearson correlation coefficient, this paper proposes a metaphor analysis method for extracting the content words from both literal and metaphorical corpus, calculating correlation degree, and analyzing their relationships. The value of the proposed method was demonstrated through a case study by using a corpus with keyword “飞翔(fly)”. When compared with the method of Pearson correlation coefficient, the experiment shows that the LSA can produce better results with greater significance in correlation degree. It is also found that the number of common words that appeared in both literal and metaphorical word bags decreased with the correlation degree. The case study also revealed that there are more nouns appear in literal corpus, and more adjectives and adverbs appear in metaphorical corpus. The method proposed will benefit NLP researchers to develop the required step-by-step calculation tools for accurate quantitative analysis.
Key words: latent semantic analysis (LSA); metaphor; natural language processing(NLP); pearson correlation coefficient
Introduction
Metaphor is a necessary way of thinking and cognition[1]. Richards[2]pointed out that people use metaphors so frequently in everyday life that there is one metaphor in almost every three sentences. Conceptual metaphor theory claims that metaphor is the mapping from source domain to target domain in human conceptual system[3]. For example, in “time is money”, time is the target domain, and money is the source domain. In this metaphor, time is compared to money, and the value of time is highlighted with the characteristics of money. In recent years, as one of the thorny issues in natural language processing (NLP), metaphors have gradually received widespread attention from scholars engaged in Chinese information processing research. So far, there is no widely used computing model to solve the problem of metaphor recognition and understanding, which has severely restricted the development of NLP and machine translation[4].
More than 2000 years ago, Aristotle[5]proposed that metaphor had no cognitive value and was an additional and optional modification. This view was soon dismissed as a lack of awareness of the metaphor. In the 1980s, Lakoff and Johnson[6]proposed the conceptual metaphor theory, which hold that humans always understand the world based on their own experience. The conceptual system that we use in thinking and acting every day is also constructed through metaphors.
With the rapid development of NLP and semantic analysis, significant progress has been made in the study of metaphor. Scholars pay attention to the core position of metaphor in thinking and language, and have proposed many models of metaphor computing. Fass[7]proposed a system Met*for interpreting metaphorical languages based on priority semantics. Veale and Keane[8]proposed a metaphor understanding model Sapper based on semantic knowledge. Martin[9]proposed a metaphor recognition and understanding system which was Metaphor Interpretation, Denotation, and Acquisition System (MIDAS) based on analogical reasoning. Kintsch[10]proposed a metaphor understanding system based on statistics. Mason[11]proposed a corpus based computing system for identifying and analyzing normative metaphors, CorMet, to identify and analyzed metaphors from a large number of corpora.
However, the methods based on priority semantics, semantic knowledge, analogical reasoning and corpus are all limited by the lack of language knowledge resources. The existing NLP technology is still difficult to provide relatively complete knowledge resources for these methods. Currently, there is a lack of methods in automatic feature extraction and weight calculation in metaphorical identification. Therefore, this paper proposes to adopt NLP and latent semantic analysis calculation methods, and applies them to the corpus of manually annotated literal and metaphorical sentences to extract the characteristic words and weights of the literal and metaphorical sentences.
The rest of the paper is arranged as follows. Section l summarizes the current status of metaphor research, latent semantic analysis (LSA) method, singular value decomposition (SVD) principle, and Pearson correlation coefficient calculation method. The metaphor analysis methods and analysis algorithm based on LSA are intnduced in section 2. Section 3 shows the experimental, comparison, and analysis. Section 4 is the summary and prospect.
1 Related Work
LSA is an indexing and retrieval algorithm proposed by Deerwesteretal.[12]LSA can be used to find the similarity between documents, content words, and between content words and documents. It can solve the problem of synonyms and improve the accuracy of information retrieval[13]. LSA methods are widely used in evaluation system[14], text classification[15], and other fields[16-19], but the application of LSA methods to metaphor processing problems is still rare.
LSA uses the SVD method in mathematics. The main function of SVD is to convert a relatively large and complex matrix into three small matrices, each small matrix is obtained by extracting important features of the large matrix. SVD is divided into the following steps. Firstly, an unstructured document set is replaced by anm*nword frequency document matrixA, shown as
A=[aij]m×n,
(1)
whereaijrepresents the frequency of the keywordiin the documentj. Secondly, the matrixAm×nis decomposed into three matrices
(2)
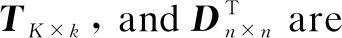
(3)
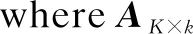
The Pearson correlation coefficient was proposed by Pearson[20]to study the linear correlation between two random variables. The calculation process of the correlation coefficient is shown as
(4)

(5)
In Eq. (5), the value of the correlation coefficientris between -1 and 1.r>0 indicates a positive correlation, andr<0 indicates a negative correlation. If |r|=1, it means that the two variables are completely linearly related, and ifr=0, it means that the two variables are uncorrelated.
2 Proposed Metaphor Calculation Method Based on LSA
2.1 Metaphor analysis method based on LSA
We designed a metaphor analysis method based on LSA in order to analyze the relationship between the content words in the literal corpus and the metaphorical corpus. This method used NLP, LSA and Pearson correlation coefficient calculation method, and the specific processing flow is shown in Fig. 1.
As shown in Fig. 1, the method has 7 steps.
Step 1 Get the literal and metaphor corpus and build a text corpus.
Step 2 Extract content words from the text corpus. Through text segmentation, part of speech (POS) tagging, stop-words filtering, the resulted corpus contains only and keep part of speech is nouns, verbs, adjectives and adverbs.
Step 3 Transform the content words corpus into a content word document matrix with the use of vector space model.
Step 4 Calculate LSA relevance matrix and get LSA content words relevance matrix.
Step 5 Calculate Pearson correlation coefficient and get Pearson content words relevance matrix.
Step 6 Extract keyword correlation words from the results of step 4 and step 5 and gain a keywords correlation words list.
Step 7 Visualize analysis and display for the content words correlation.
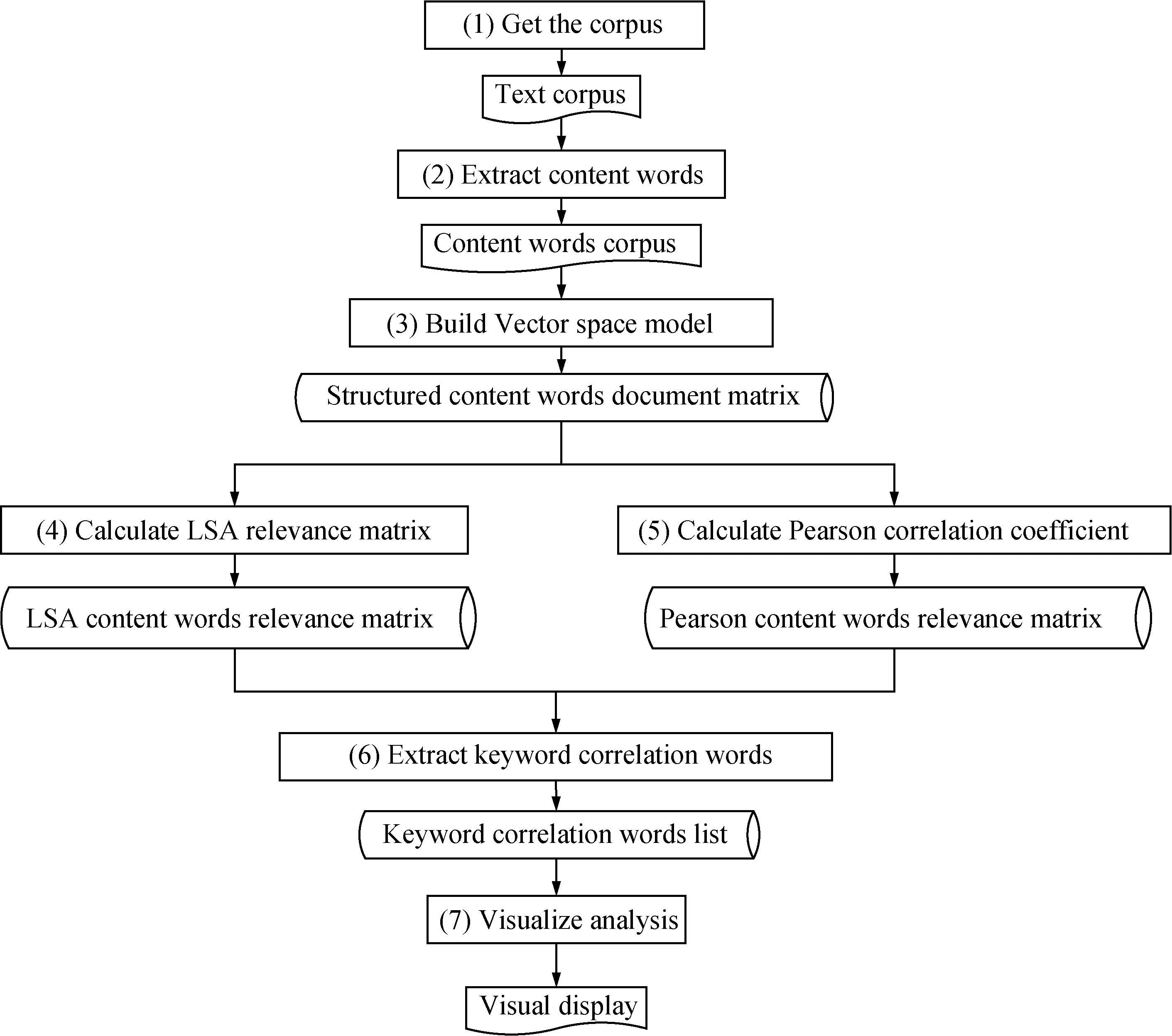
Fig. 1 Metaphor analysis method based on LSA
Because the LSA method is used to calculate the content words correlation, the next will introduce the LSA algorithm.
2.2 LSA content words correlation algorithm
The LSA calculation algorithm is shown in Fig. 2.

Fig. 2 LSA content words correlation algorithm
The aforementioned LSA calculation method input is structured content words document matrix data and the reduced dimensionK. The output is content words correlation matrixwordSim. The specific calculation process is as follows.
1) Read structured content words matrixdata, anddatais the vector space model process result in the metaphor analysis method based on LSA in Fig. 1.
2) Construct SVD on the data and get three matricesT(content words and content words correlation matrix),S(content words and documents correlation matrix), andD(documents and documents correlation matrix) before dimensionality reduction. The specific operation is realized by calling the SVD method of linalg module in Numpy library of Python language.
3) Set theKvalue in the SVD, and construct the SVD diagonal matrixSK, which is mainly realized by the eye method in the Numpy library of Python language.
4) Calculate the reduced dimensionality content words documents matrix by changing the singular value diagonal matrixSK, and generating a reduced dimensional content words documents matrixnewData. This step is mainly realized by the dot method in the Numpy library of Python language.
5) Calculate the reduced dimensionality content words and content words correlation matrix. We perform the inner product operation on the two dimensionality reduced content words document matricesnewData, and finally get a reduced dimensionality content words and content words correlation degree matrixwordSim.
3 Experiments
3.1 Preparing text corpus
The source of the corpus in this paper is from the Modern Chinese Corpus of Peking University “飞翔(fly)” is used as the keyword for query and set the display window as 40 Chinese characters to the left and right of the keyword. There are a total of 1 540 sentences in the query results. Some noise sentences were manually labeled and removed. The rest sentences were labeled as metaphorical or literal expression. The final text corpus in this paper is shown in Table 1.

Table 1 Text corpus information
Table 1 shows that text corpus in total of 1 331 sentences, which 709 sentences are literal sentences and 622 sentences are metaphorical sentences, and each sentence contains the keyword “飞翔(fly)”.
3.2 Extracting content words
In the content word extraction stage, we first used jieba tool for word segmentation and POS tagging, then used the Harbin Institute of Technology (HIT) stop-words list to remove the function words, and finally extracted the content words. As can be seen in Table 2, only content words (nouns, verbs, adjectives, and adverbs) were exacted, and the number, punctuation and other stop words were removed.

Table 2 Extracted the result of content words(section)
3.3 Building content words document matrix
The Python language and the CountVectorizer class in the sklearn package were used to construct a computer processable data structure from the extracted content words corpus. We used a fit transform function to count the content words frequency and generated the content words document matrix. The content words document matrix is a very sparse matrix, in which every row represents a document and every column represents a content word, the cross term of the row and column represents the frequency of the content word appearing in the document. Table 3 shows the size of the content words document matrices after the vector spare model has processed the literal corpus and metaphorical corpus.

Table 3 Size of the content words document matrices
Table 3 shows that the size of the content words document matrix is literal (1 234×709) and metaphorical (1 034×622).
3.4 Calculating the correlation degree of content words by Pearson
Because all entries in the corpus include “飞翔(fly)”, the word frequency of occurrence in each sentence is always 1, the Pearson correlation coefficient cannot be calculated. Therefore, we added 50 filler sentences unrelated to “飞翔(fly)”, then calculated the correlation of Pearson filler and extracted the correlation table of the content words. In addition, for the convenience of reading, we abbreviated the POS of noun, verb, adjective and adverb into the tag of n, v, a, d. The top 10 content words with the highest correlation degree were listed in Table 4.
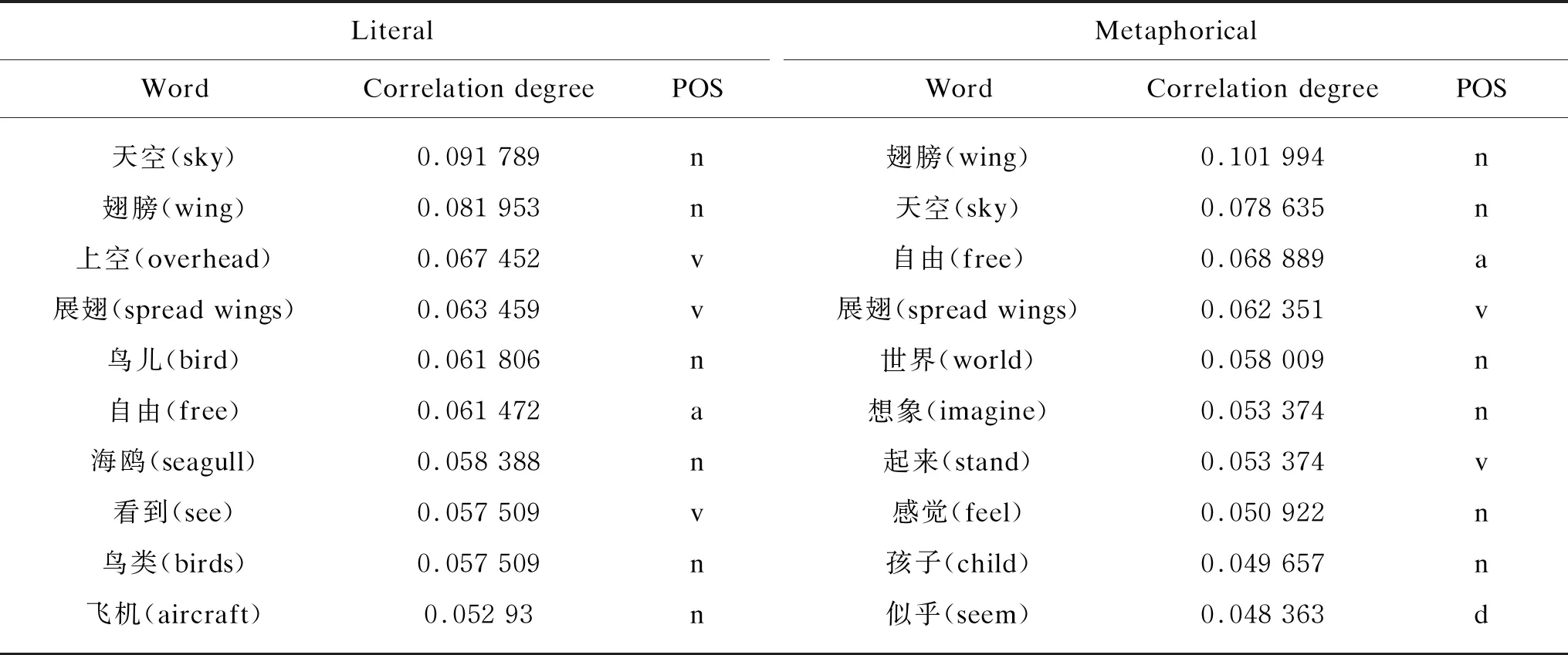
Table 4 Pearson keyword content words correlation list (top 10)
Table 4 showed the list of the correlation degree of the literal corpus and metaphorical corpus Pearson content words after adding noise. And we listed the top 10 content words with the highest correlation.
3.5 Calculating the correlation of content words by LSA
LSA was used to calculate the content words correlation. The experimental dimension K was set to 10. According to the results of LSA calculation of content word correlation, the content words correlation list of keywords was extracted, and the top 10 of LSA keyword content words correlation were listed in Table 5.
Table 5 shows the top 10 content words with higher LSA calculation correlation degree, which is very similar with the Pearson calculation results. For the literal corpus, the top 10 content words calculated by LSA and Pearson methods have the same results, but the correlation degree value is different (shown in Fig. 3). For the metaphorical corpus, had nine words were the same in the top 10 content words and the correlation degree value is also different.
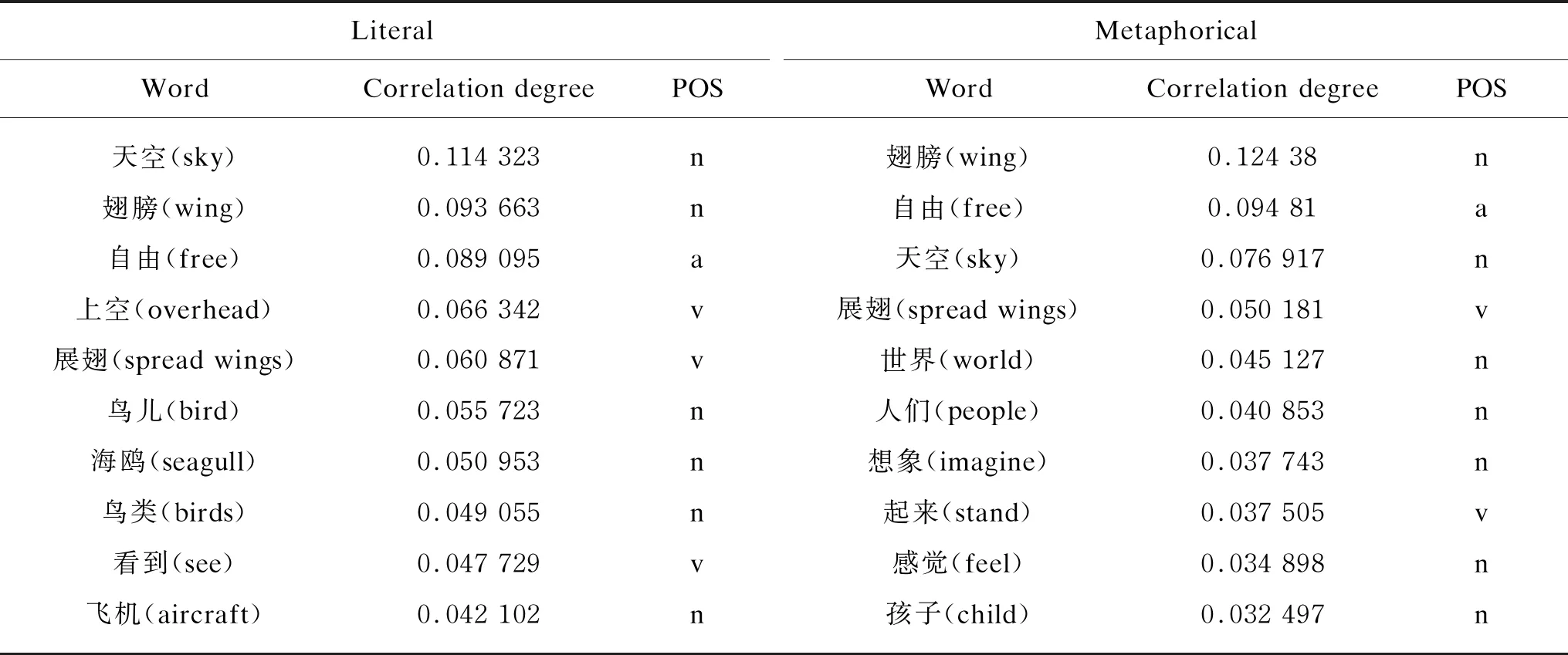
Table 5 LSA keyword content words correlation list (top 10)
It can be seen from Fig. 3 that the content word correlation calculated by LSA and Pearson shows a downward trend in the overall trend, but the LSA calculation method is more discriminative. The “天空(sky)” has the highest correlation degree with “飞翔(fly)”. And its LSA calculation result is 0.114 3 and the Pearson calculation result is 0.091 8. The “飞机(aircraft)” has the lowest correlation degree with “飞翔(fly)”. And its LSA calculation result is 0.042 1 and Pearson calculation result is 0.052 9.

Fig. 3 Top 10 content words and correlation degree of the literal corpus calculated by LSA and Pearson methods
Compared these two set of lists, it is shown that the LSA changes significantly in the correlation degree. The value of the correlation degree of closeness is high, and the value of the correlation degree of farness is low. It reveals that the LSA method is more efficient in calculating content words similarity than Pearson method.
3.6 Co-occurrence content words in literal corpus and metaphorical corpus
In order to find the pattern of the content words appearing in the literal corpus and the metaphorical corpus, co-occurrence was calculated. For the metaphorical corpus, firstly, we calculated the LSA content words correlation degree matrixwordSim. Then, we extracted the top 1 000 correlation degree content words of the “飞翔(fly)” keyword and arranged these content words in descending order of correlation degree.
Finally, the 1 000 content words were divided into 10 word bags (groups) and the co-occurring content words of each group were calculated. The same operation was done for the literal corpus. The results were shown in Fig. 4.

Fig. 4 Co-occurrences content words in literal and metaphorical corpus(section)
Figure 4 shows that among the top 100 content words (first group A) in the literal, 82 content words also appear in the metaphorical corpus, and the remaining 18 content words may be characteristic content words that distinguish between the literal corpus and metaphorical corpus.
As the correlation degree of decreases, the number of co-occurring content words in the literal corpus and metaphorical corpus also gradually decreases, which indicates that highly correlation greed content words are high frequency content words that make up the document, and they have no obvious effect on distinguishing between the literal corpus and metaphorical corpus. It also revealed that different content words are important clues to distinguish between the literal corpus and metaphorical corpus. This discovery provides in sights into directions for metaphor research.
Moreover, when the overall display declines, there are two sets of lists that had an upward trend. It indicated that the low correlation degree content words may also be high frequency content words of the literal and metaphoric corpus.
3.7 Statistics of POS
When we extracted content words from the corpus, the nouns, verbs, adjectives and adverbs were reserved. In order to clearly understand the impact of different POS on metaphorical corpus, the distribution of the four POS was visualized and analyzed as shown in Fig. 5.
Figure 5 shows that verbs and nouns appeared more frequently, accounting for more than 80% of 4 kinds of content words; adverbs and adjectives are significantly less frequent, accounting for less than 20% of all 4 kinds of content words. It shows that verbs and nouns are important components in a sentence. Adverbs and adjectives are often used to modify verbs and nouns. The results were in line with people’s conventional perception. Therefore, verbs and nouns occupy a larger proportion in both the literal corpus and metaphorical corpus.
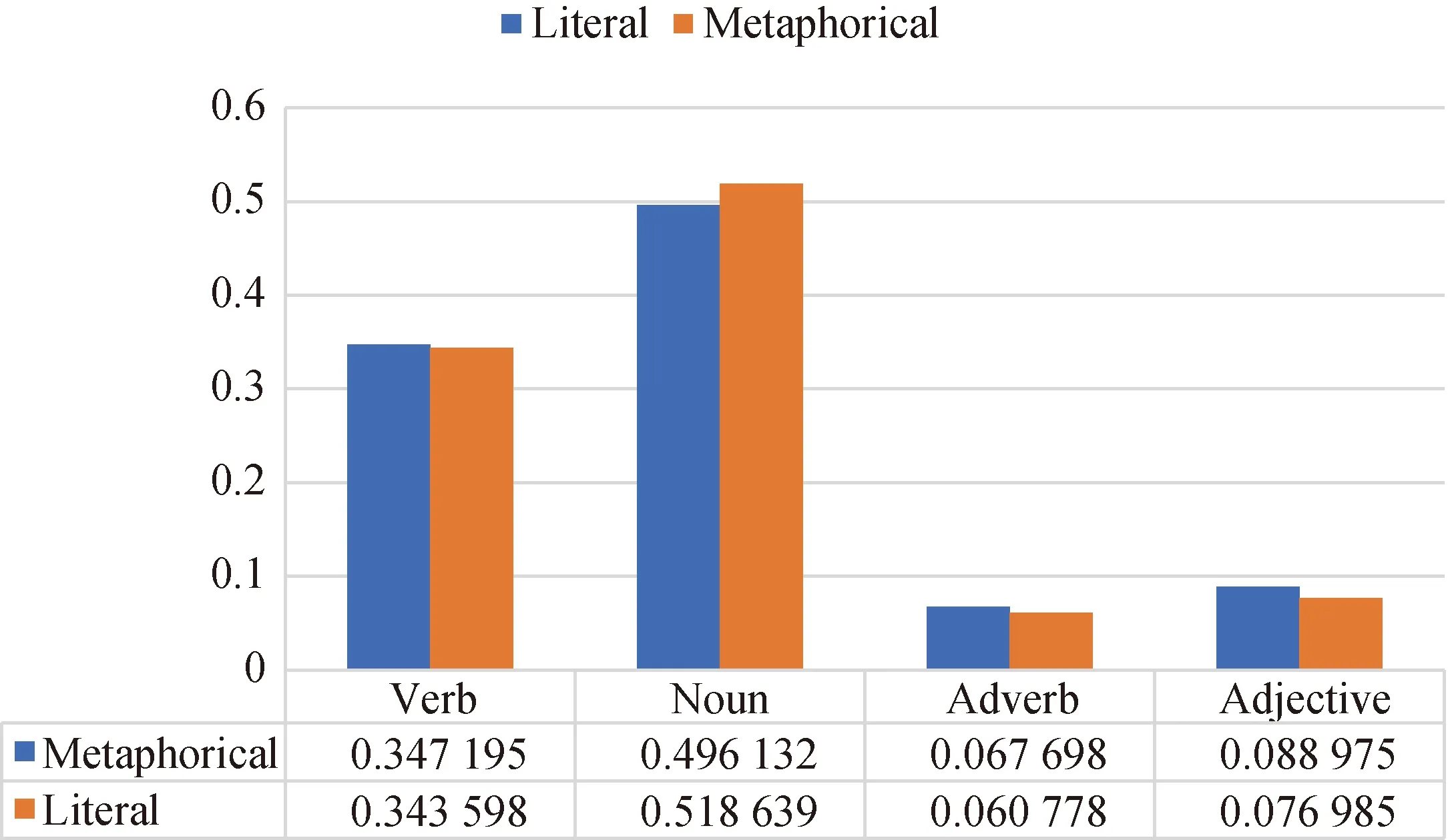
Fig. 5 Distribution of the four POS in the literal corpus and metaphorical corpus
In addition, adverbs and adjectives in metaphorical corpus accounted about 6.7% and 8.9% of the four POS, and adverbs and adjectives in the literal corpus accounted about 6.1% and 7.7% of the four POS. Adverbs and adjectives appeared more frequently in metaphorical curpus than in literal corpus, indicating that adjectives or adverbs are more often used in metaphorical corpus to modify nouns and verbs.
4 Conclusions
Based on the LSA method, this paper proposed a quantitative calculation method for metaphorical corpus, which included preparing corpus, word segmentation and POS tagging, extraction content words, generation the content word document matrix, Pearson content word correlation calculation, LSA content word correlation calculation, literal and metaphorical co-occurring content word statistics and POS statistics.
The corpus is from the Modern Chinese Corpus of Peking University. We first searched 1 540 sentences containing “飞翔(fly)” and marked them with literal sentence tag or the metaphorical sentence tag, extracted content words (nouns, verbs, adjectives, and adverbs), constructed the content words document matrix, and calculated the literal and metaphorical content words correlation degree matrix by Pearson and LSA. The results show that the content word correlation calculated by LSA is more obvious and has better discrimination.
In addition, the LSA calculation result was subjected to a statistical analysis of content words co-occurring in the literal corpus and metaphorical corpus. It shows that the number of co-occurring content words decrease with the decreasing of correlation degree. The high correlation content words are high requency words in both literal corpus and metaphorical corpus, so they shouldn’t be used as feature content words to distinguish between the literal corpus and metaphorical corpus. On the contrary, the low correlation content words are low frequency words in both literal corpus and metaphorical corpus, they can be used as feature words to distinguish between literal corpus and met.
Furthermore, a statistical analysis of the four POS of content words shows that the nouns have a higher probability in the literal corpus. The adverbs and adjectives in the metaphor corpus have a higher probability than the literal corpus.
Moreover, the research conducted word segmentation based on thejiebatool, and the segmentation results basically satisfied the research content. However, there are still some cases where the segmentation results are not accurate, including the inaccurate ofjieba. Future research can be done to improve the accuracy of word segmentation.
Finally, LSA based research methods and calculation tools can facilitate the development of step-by-step calculation tools needed by linguists, psychologists, and other NLP researchers. In the future, on this basis, we can continue to study the problem of metaphors in depth, and apply the LSA quantitative analysis method to the problems of literal recognition and metaphorical interpretation in order to understand the problem of metaphors more deeply.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Polyacrylonitrile/Graphene-Based Coaxial Fiber-Shaped Supercapacitors
- Highly Stretchable and Transparent Hydrogel as a Strain Sensor
- Effect of Processing Parameters on Morphology and Mechanical Properties of Hollow Gel-Spun Lignin/Graphene Oxide/Poly (Vinyl Alcohol) Fibers
- Characteristic Analysis and Harmonic Feature Identification of Micro-Vibration on Flywheels
- Defect Detection Algorithm of Patterned Fabrics Based on Convolutional Neural Network
- Tufting Carpet Machine Information Model Based on Object Linking and Embedding for Process Control Unified Architecture