基于模拟退火-轻型梯度提升机的电厂出力短时多点预测方法
2021-03-29邓真平熊中博周新宇
邓真平,熊中博,周新宇,谢 军
(1.重庆市科源能源技术发展有限公司,重庆 渝北 401147;2.嘉陵江亭子口水利水电开发有限公司,四川 广元 628400)
0 引言
在电力预测领域,对主力电厂出力的准确预测不仅对发电计划制定、机组检修有重要影响,对电网侧和发电侧的供需平衡等同样有重要影响.因此,可以说电厂出力预测既是制定发电计划、维修计划和电能销售计划的重要环节,也是确保电网安全、可靠、经济运行的基础.目前,电厂出力预测依据其时间尺度,可划分为短期预测、中期预测、长期预测三类.围绕这三类预测问题,研究者分别基于线性理论、非线性理论、组合分析建模、大数据挖掘等不同的方法开展了一系列研究,并取得了广泛的成果.陈伟龙[1]等面向丽水水电群的出力预测需求,提出了一种基于链表的水电站群拓扑关系描述方法,在此基础上建立了水电站群最大发电量模型.刘嘉[2]等为了克服预测精度不足的问题,利用NGBM(1,1)对负荷的整体发展趋势进行预测,得到随机变动的拟合精度指标,并在此基础上通过引入马尔科夫理论表征随机拟合精度的状态转移规律,构建了一种基于加权马尔科夫修正的NGBM(1,1)中长期预测模型.马哲[3]等从负荷周期相似性的角度出发,对负荷数据进行频谱分解,并利用K均值聚类算法匹配日负荷分量、日负荷趋势分量、负荷规则分量,以及负荷随机分量.在此基础上,建立各分量独立的负荷预测模型,最终得到综合的预测负荷值.崔和瑞[4]等考虑温度、风力、降水量等因素对夏季负荷预测的影响,利用SAS软件构建电力负荷序列与输入序列“温度”之间的ARIMAX模型.仿真表明,该模型对存在突变结构具有显著影响因素的短期电力负荷预测有潜在的应用价值.赵延文[5]从构建组合预测模型的思想出发,将灰色系统理论和回归分析用于负荷预测.在此基础上为使预测精度最优化,引入DS证据理论对两种模型的预测结果进行组合.
目前,随着大数据、人工智能等理论和技术的发展和成熟,有不少研究者将其应用到预测领域[6-8].例如,徐源[9]等通过历史负荷序列的增长趋势、波动性等变化特性的参数化表达,形成大数据聚类的样本.利用MapReduce的优势构造了一种改进的模糊聚类方法,并在综合相同聚类负荷的基础上建立预测模型.董浩[10]等将核主成分分析方法与极限学习机模型相结合,并把气象综合特征数据与历史负荷数据作为极限学习机神经网络的输入数据,通过极限学习机对实际电力负荷进行预测分析.陈艳平[11]等为克服负荷序列的非线性、非平稳问题,将EEMD应用于原始非平稳负荷序列的分解,并利用样本熵对各IMF分量进行分析,根据熵值大小叠加产生新的子序列.进一步在考虑气象、日期类型等因素的基础上,建立不同的Elman递归神经网络模型.
上述研究成果分别面向电网侧或者电厂侧的预测需求,基于不同的理论模型及方法进行了研究,为预测问题的解决提供了新的研究思路.然而,在实际运用过程中,不仅要关注预测的准确性,还要考虑算法计算的效率.基于此,本文针对电厂出力的预测问题,在考虑出力时序及其影响因素的基础上,引入LightGBM梯度提升框架,以提高计算的高效性,实现对电厂出力的短时多点预测.
1 LightGBM模型介绍
1.1 LightGB基本介绍
LightGBM(Light Gradient Boosting Machine,LightGBM)是一个轻量级的梯度提升机,该算法框架使用基于学习算法的决策树.这种决策树具有更快的训练效率、更低的内存使用、更高的准确率,支持并行化学习、可处理大规模数据等优点[12].此外,LightGBM框架在算法实现上还有如下一些特征[13-15].
1) 直方图算法:把连续的浮点特征值离散化成k个整数,并构造宽度为k的直方图.在数据遍历的过程中,将离散化后的值作为索引在直方图中累积统计量.这样在数据遍历后,直方图累积了需要的统计量,进而划分最优分割点.
2) 直方图做差加速:传统构造直方图的方法,需要遍历叶子上的所有数据.直方图做差仅需遍历直方图的k个桶,使得寻找兄弟叶子直方图的代价也相应减小,从而使运算速度得到提升.
3) 叶子生长策略:LightGBM采用Leaf-wise策略,从当前所有叶子中寻找分裂增益最大的一个叶子结点,然后往下分裂.同时,为防止无限制分裂和过拟合问题,增加了最大深度限制参数.
4) 支持类别特征:LightGBM框架优化了对类别特征的支持,可直接输入类别特征,同时在决策树上增加了类别特征的决策规则.
1.2 模拟退火算法基本介绍
LightGBM属于多参数框架模型,其计算效果的准确性依赖于参数设置的合理性.因此,将LightGBM框架用于电厂出力的预测时,合理标定模型参数是需重点考虑的问题之一.目前,常见的参数优化算法包括模拟退火、粒子群算法、差分进化算法等[6,16].本文在对LightGBM进行参数标定时,采用模拟退火(Simulated Annealing,SA)方法.
模拟退火属于随机寻优算法的一种,在求解过程中通过对某一温度值T进行迭代并利用Metropolis准则对解进行选择,最终可收敛于全局最优解.以均方根误差(Root Mean Squard Error,RMSE)作为期望函数f(w),用于评价参数的优劣性,则SA算法求解的流程可简要概况如下[17]:
1) 初始化参数:设置参数搜索空间P、初始温度T、内层迭代次数N,随机生成初始解w,并计算期望函数f(w)值.
2) 在参数搜索空间产生新的w',计算f(w')和Δf=f(w')-f(w).
3) 若Δf≤0,则接受新解w=w',f(w)=f(w'),否则可按照Metropolis准则接受新的解参数.
4) 判断是否达到迭代次数N,未达到迭代次数转到步骤2),否则转到步骤5).
5) 判断是否满足终止条件,若满足结束寻优过程,返回当前最优解,否则改变温度T,重置迭代次数并转至步骤2).
2 基于SA-LightGBM的电厂出力多点预测模型
2.1 样本特征构建
LightGBM从本质上来看是基于决策树的模型,与决策树模型的一般使用类似.LightGBM在使用上包括两个主要阶段,即训练阶段和测试阶段.训练阶段将已知的样本数据输入到LightGBM模型中,自动完成模型的训练和模型内部参数的标定.测试阶段则将测试数据输入经训练优化的LightGBM中,以验证模型的预测效果.
基于网络模型训练和测试的基本思想,在网络训练阶段需对电厂出力时序数据进行处理,并结合天气、节假日等因素数据构建训练样本.若k时刻及之前的出力时序为t(k),则历史出力时序可表示成T(k),即:
T(k)=[t(k-m),t(k-m+1),…,t(k-1),t(k)]
(1)
式(1)中m为嵌入时间维度,从时序预测的角度出发,该值表示了在电厂出力预测中,出力时序在模型输入端所占节点的个数,它与影响电力预测精度因素(如天气因素等)共同构成了网络输入.除了时序因素对预测有潜在的影响外,其他诸如天气、节假日等因素也会对模型的预测精度产生影响,记其他影响因素构成的输入向量为F(k),即:
F(k)=[f1,f2,…,fp]
(2)
式(2)中p为除时序因素外,其他外界因素对应的输入维度.因此,LightGBM模型的输入可由T(k)和F(k)表示,即:
S(k)=[T(k),F(k)]
(3)
若预测时间步长为h,则对电厂出力的预测可表述为给定S(k)作为LightGBM输入,t(k+h)作为LightGBM输出.通常在单步预测中,h的值为1,通过对模型的训练确定输入输出的映射关系.
2.2 电厂出力多点预测模型
通过对海量历史出力数据、天气数据、节假日等数据的处理,选择合适的嵌入时间维度m生成模型训练数据集和测试数据集.模型的训练和测试流程如图1所示.

图1 模型训练和验证流程

(4)
据此,可通过迭代的方式得到未来96点出力的预测结果,具体的算法流程如下:
算法: 电厂出力预测算法
输入: 输入特征向量S(k)
输出: 短时出力预测结果集Y
1 初始化LightGBM模型参数空间P,SA内层循环迭代次数N及初始温度T
2 利用SA在参数空间搜索LightGBM的最优参数,得到预测模型M,在模型M上进行迭代预测
3 fori←1 to 96 do
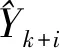
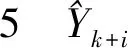
6 更新模型输入特征
8S(k+i)←T(k+i)+F(k+i)
9 end
10 返回Y
2.3 评价指标
出力模型预测结果的性能直接影响着电厂发电计划的制定,因此为了对模型的预测结果进行客观评估,以平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squard Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)作为主要的评价指标,各指标的定义如式(4)~(6)所示.
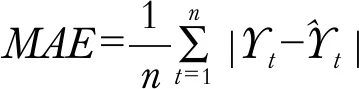
(4)

(5)
(6)
3 实验验证
为了对电厂出力的预测效果进行验证,以大唐重庆分公司某发电单位采集的电厂出力数据、气象数据、节假日等数据为基础,构造训练样本集和测试样本集.其中,电厂出力数据每隔15分钟统计一次,每日共96个时序数据值;温度和节假日数据包括日期类型、最高温度、最低温度等属性;样例数据分别如表1和表2所示.
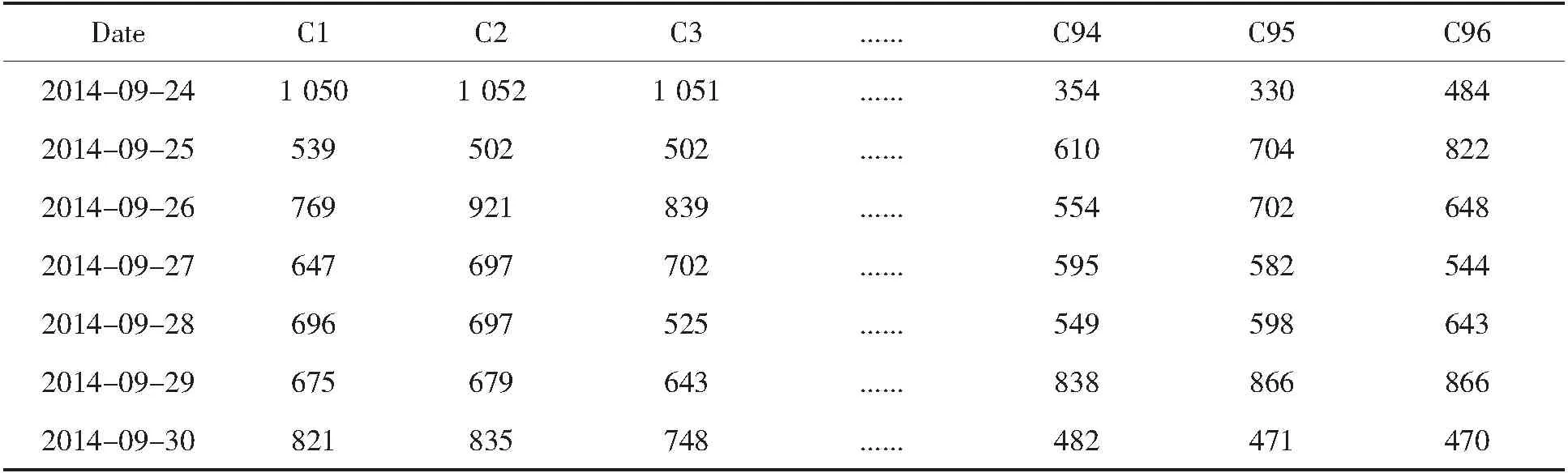
表1 电厂出力数据(96点)
表2中“DayType”字段包含了端午节、国庆节、劳动节、元旦节、中秋节和正常日.因此,该属性作为出力影响因素的一个维度,需要实现文本到数值编码的一般性转换,具体采用sklearn.preprocessing库中的LabelEncoder进行转换.

表2 电厂出力影响因素
图2和图3分别为休息日和工作日电厂出力的趋势对比.从图中可以看出,电厂出力曲线虽然整体趋势具有日相似性,但是在曲线的细节部分,日出力趋势仍具有一定的差异性和波动性.考虑到数据变化趋势之间的差异性,LightGBM模型必须具备针对特定数据变化趋势的学习和预测能力.因此,合理、准确地标定参数,对于保证LightGBM的预测效果至关重要.根据SA的参数寻优流程,设定LightGBM的基本参数搜索空间如表3所示,经过SA算法寻优化后,LightGBM针对此样本数据集最优的参数如表4所示.
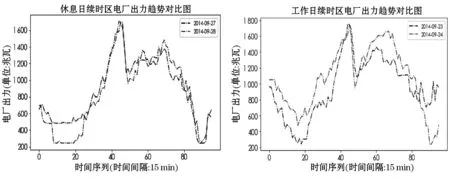
图2 休息日电厂出力趋势对比图 图3 工作日电厂出力趋势对比图

表3 LightGBM参数搜索空间

表4 SA优化后的LightGBM参数
为了对电厂出力进行每日96点出力预测,根据2.2节电厂出力预测流程,分别对2014年9月28日(休息日)和2014年9月30日(工作日)连续96点电厂出力进行迭代预测,整体预测结果如图4所示.
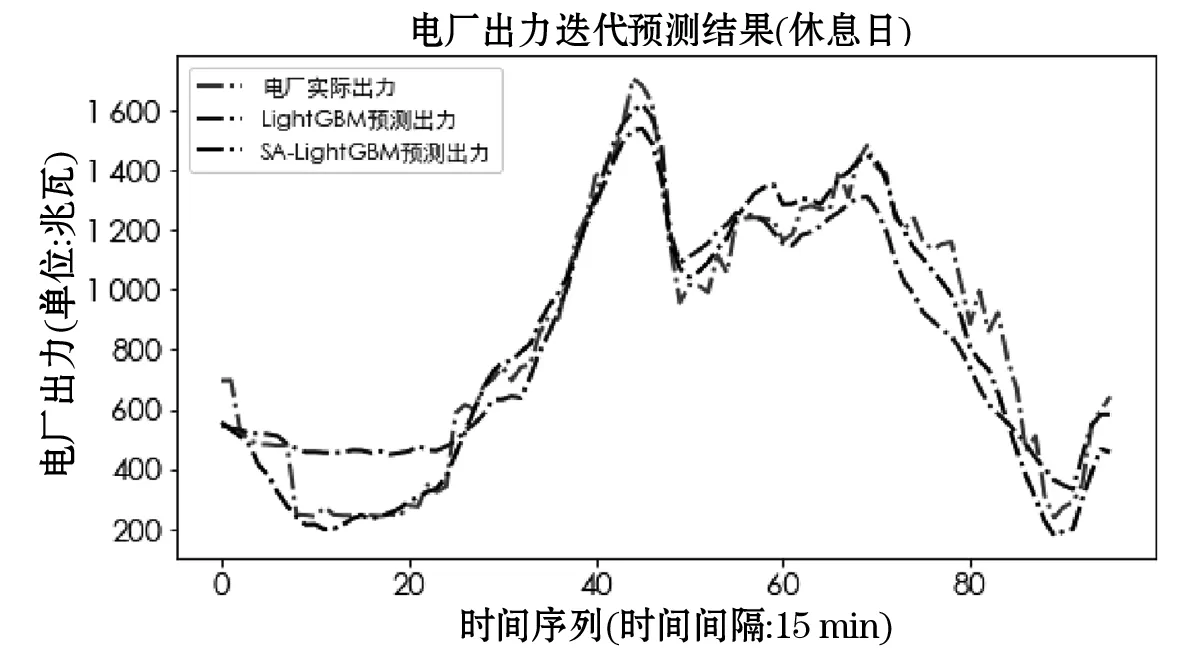
图4 休息日电厂出力迭代预测结果
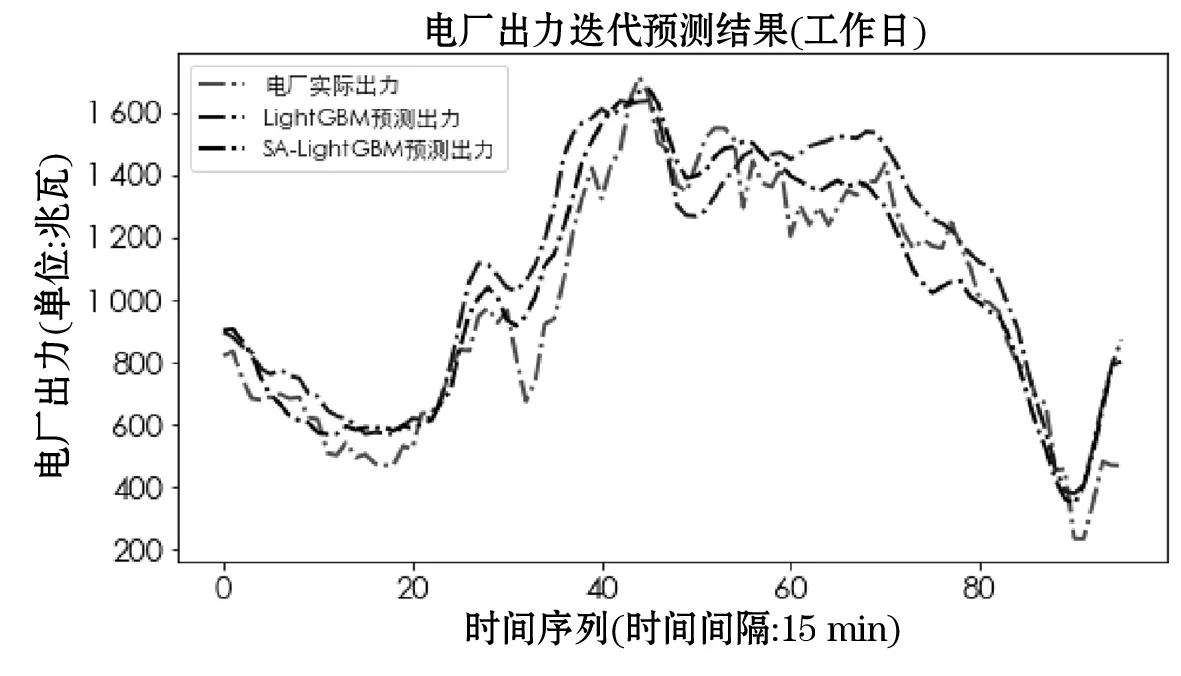
图5 工作日电厂出力迭代预测结果
图4和图5分别为休息日、工作日电厂出力96点迭代预测结果.表5为工作日和休息日出力数据经LightGBM和SA-LightGBM模型预测后得到的评价结果.根据表5,经SA-LightGBM模型优化后,休息日的预测出力与实际出力的指标值MAE为71.536 1,RMSE为94.694 9,MAPE为0.105 6;工作日的预测出力与实际出力的指标值MAE为92.871 9,RMSE为115.630 1,MAPE为0.123 5.可见,采用模拟退火算法对LightGBM进行参数优化,可有效提升模型的预测精度.

表5 电厂出力迭代预测评价指标
4 结论
本文针对电厂出力的短时多点预测问题,基于LightGBM框架,综合考虑时序、气象、节假日等因素,构造短时迭代预测模型.为了进一步对每日96点出力进行迭代预测,在每一轮预测结束后将预测值纳入输入时序,并作为新的模型输入.
实验结果表明,本文提出的出力预测模型能够对电厂出力进行迭代预测.但是,受数据波动性、电网负荷需求等因素的影响,电厂出力的预测精度仍需进一步提高.因此,在后续的电厂出力预测研究中,需进一步对出力时序与电网负荷、气象因素、节假日因素等数据之间的关联深入挖掘,以优化预测模型参数、提高预测精度、增强模型的适用性和实用性.
