基于AdaBoost 的MOOC 学习成绩预测模型研究
2021-03-25贾靖怡李玉斌姚巧红袁子涵
贾靖怡,李玉斌,姚巧红,袁子涵
(辽宁师范大学计算机与信息技术学院,辽宁大连 116081)
0 引言
从最初的网络课程、虚拟学习社区、精品课程到现在的视频公开课、资源共享课以及大规模在线开放课程(MOOC),在线教育方式始终存在学生参与度低、辍学率高、学习效果不理想等问题[1-2]。为在辍学前识别出有风险或问题倾向的学习者,从而进行有针对性的指导、干预和预警,MOOC 环境下的学习预测研究成为热点。预测研究的价值主要体现在3 个方面[3]:①教师可预测学习者可能遇到的问题,通过调整课程或教学方法提升学习体验;②教师或机构可使用预测结果决定课程设计及实施学习干预;③学习者可获得学习过程信息,使其反思自己是如何做的,从而提升学习表现。
当前的MOOC 在线学习预测研究主要集中在学习者流失率、辍学率、退课率、完成率、学习参与度等方面[4-6],对学业成绩、学习缺陷、认知障碍等主题研究相对偏少。流失率、辍学率、退课率等主题研究虽然引起广泛关注,但还处于初级阶段,并不成熟,单从预测指标数量就能窥见一斑。范逸洲等[7]在《MOOC 中学习者流失问题的预测分析——基于24 篇中英文文献的综述》中指出,有的研究预测指标数仅4 项,有的多达37 项。因此,在MOOC 学习者预测研究上还需要更多的实证工作,构建更加稳健和精准的预测模型,从而助力在线教育向更智能化方向发展。
1 成绩预测研究综述
MOOC 的主要特点之一就是注册人数众多,通常会有成千上万的注册者,可收集大量的信息了解课程情况,以便进一步分析。目前,大多数平台都记录或存储“学习者与平台交互”“学习者与课程交互”“学习者与学习者或教师的社会性交互”数据,分析这些数据不仅可发现问题,还可用来预测学习者学习情况与学习结果。
Yang 等[8]利用学生观看授课视频点击流和以前的评估成绩数据,采用训练时间序列神经网络方法预测学习成绩。对两个MOOC 数据集的评估显示,该算法比以往平均性能的基线高出60% 以上,比lasso 回归基线高出15% 以上。当学生回答较少问题时,该算法也具有较强的预测能力;Ren 等[9]采用个性化线性多元回归(PLMR)模型,通过跟踪学生在MOOC 上的参与情况预测学生下一阶段表现。分析结果表明,最好的成绩在课程进行到一半时取得,评分前的测验次数是相关性最高的变量;Sinha 等[10]基于每天的课程交互信息,包括学习者播放视频数量、章节交互次数和论坛发帖数量,利用条件随机域(CRF)概率框架对学习成绩进行预测。对交互特征组合进行对比分析得到模型最佳精度为58.1%,召回率为66.0%,加权F-score 为56.0%,超过了应用于每个序列位置的多个基线鉴别分类器;Brinton 等[11]提出带有因数分解机和K-NN 的算法,目的是预测用户在回答一个问题时第一次尝试(CFA)是否正确,测试结果显示该算法和预测指标具有早期检测能力;郝巧龙等[12]利用多元线性回归分析构建模型,识别出持续时间、学习进度、观看时长、笔记数、作业成绩、发帖数、回帖数、得分帖数等预测变量;王凤芹等[13]利用登录次数、在线时间、视频观看时间、看帖数、发帖数、回帖数、在线测验次数、每次在线测验成绩、作业提交次数、每次作业成绩等10 个预测指标,验证K 近邻优化算法在预测MOOC 学习成绩的有效性;赵帅等[14]基于情感词典统计学习者论坛讨论发言中积极、消极情感词语及词频,通过回归分析方法研究情感指数是否能有效预测成绩;金梦甜[15]构建基于深度神经因子分解机的学习效果预测模型。
上述研究虽然尝试利用各种技术预测MOOC 学习结果,既有经典的线性回归方程模型,也有当前非常流行的神经网络,但至今没有明确的主导预测技术。决策树、神经网络、支持向量机等这些基础模型与集成增强方法一起使用,也许可以获得更高的预测能力。从预测指标来看,三大范畴(学习者与平台交互、学习者与课程交互以及学习者的社会性交互)虽均有涉及,但主要是对时域(如在线时长、视频观看时间)和频域(如发帖条数、登陆次数)等“数量”型指标的统计,体现内容的“质量”型指标占比明显偏低。以帖子为例,仅考虑条数、不考虑发帖内容,一定会损失有价值的预测信息。另外,对“及格学习者”和“不及格学习者”预测,是用一套指标还是应该区别对待,似乎没有明确结论。本文将结合这些问题开展研究设计与实证。
2 基于AdaBoost 预测建模
2.1 预测指标
在文献分析基础上,本研究从“学习者与平台交互”“学习者与课程交互”和“学习者与学习者或教师的社会性交互”三大范畴、“时域”和“频域”两个向度,汇集“登录次数、在线时长、浏览课程资源次数、浏览课程资源时长、查看课程信息次数、查看课程信息时长、浏览视频次数、作业提交次数、参与测验次数、发布帖子条数、发布帖子字数、回评帖子条数、回评帖子字数”等13 个数量型指标,针对质性指标缺乏问题,构建“登录间隔、登录间隔标准差、发布帖子质量、回评帖子质量”4 个质量型指标,总计17 个预测指标,如表1 所示。
2.1.1 TF-IDF 累计值
TF-IDF 即词频逆文档频率,在自然语言处理中应用十分广泛,本研究用其衡量学者发帖质量。TF 表示词频数,指某个词语在学习者帖子中出现的总次数。在文本分析过程中,由于出现次数最多、频率最高的词语不一定代表帖子的内容特征,因此使用IDF 属性。IDF 表示逆文档词频,用以区分不同学习者帖子内容的差异性。TF-IDF 计算公式如下:
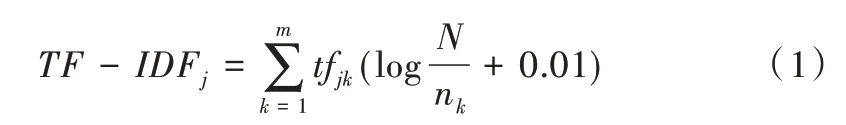
其中,TF -IDFi表示第j位学习者的TF-IDF 累计值;tfik是词语k在第j位学习者帖子词频数量+0.01是词语k在学习者帖子集合中的逆文档词频值,N 为总帖子文档数目,nk为包含词语k的帖子文档数量,m为整个帖子词向量空间维度。在计算过程中,每位学习者帖子合并为一个文档,使用结合jieba 中文分词工具和Python 语言自行编写的程序进行处理。
2.1.2 Δt 均值和标准差
Δt 表示学习者两次相邻登录的时间间隔。学习者多次登录平台后会有一系列的Δt 值。用Δt 的平均值表示学习者登录间隔属性,Δt 的标准差表示学习者登录离散情况,反映一定的行为规律。

Table 1 Description of prediction indicators表1 预测指标说明
Δt 均值计算公式如下:

Δt 标准差计算公式如下:
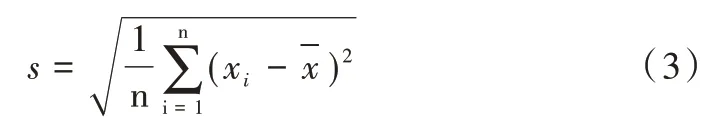
2.2 预测模型
AdaBoost 属于集成学习Boosting 算法的一种。集成学习算法核心思想是在训练集上使用一系列基础模型(如决策树、支持向量机、神经网络等)进行分类,然后采用一定的规则(如投票法)集成出一个模型,从而解决模型最优化问题。AdaBoost 作为Boosting 最受欢迎的实现方法,具有极强的适应能力[16]。因为AdaBoost 不仅根据基础模型的准度为每个模型附上权重值(α),还根据数学预测结果是否正确为每一个样本附上权重值(Wi),并经过多次迭代产生一个预测模型序列,最后采用加权平均法得到最终优化的预测模型。算法如下:
输入:训练集DT={(xi,yi)},i=1,2,…,n,yi∈{0,1}。其中,xi 为预测指标;yi 为学业成绩能否及格,0=不及格,1=及格
输出:预测模型:B(x)
(1)给训练集DT 每一个样本附上初始权重:
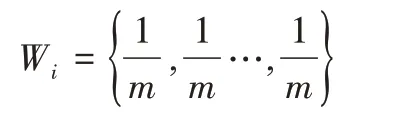
(2)for j=1 to k
(3)基于训练集DT 和初始权重Wi,训练出第一个学业成绩预测基础模型bk(x)
(4)计算模型bk(x)误差率,公式如下:
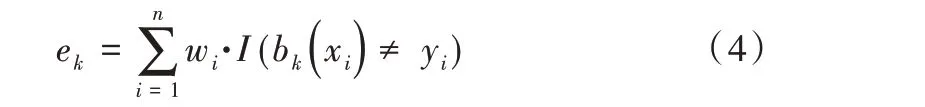
其中,如果预测结果正确,I(x)=1,否则I(x)=0
(5)计算分类bk(x)权重,公式如下:
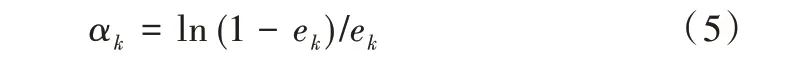
(6)根据公式(6)更新所有训练集的权重值,并归一化Wi。
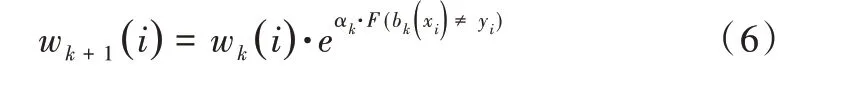
(7)end for
3 模型效果验证
3.1 数据集
选取2017-2018 学年春季和秋季两期参与中国大学MOOC 平台《互联网+教师知识个人管理》课程学习者相关数据进行效果验证。本课程两期注册总人数为11 126 人,导出其中有过发帖或回帖行为的319 位学习者数据作为研究样本。在数据提取和清洗过程中,严格按照平台提供的后台数据说明文档进行。由于17 个预测指标的量纲不同(如次数、时间、TF-IDF 值),不能直接计算,因此对数据进行归一化处理,转换到从0 到1 的同一区间。
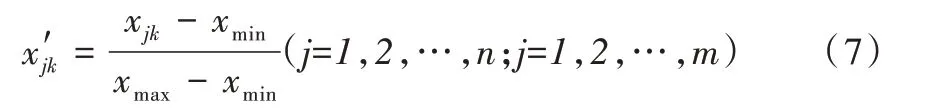
其中,xjk是原始数据,是归一化数据,xmin是第k 个指标的最小值,xmax是第k 个指标的最大值。
3.2 实验平台
RapidMiner 是由RapidMiner 公司开发、维护的一个开源大数据挖掘GUI 软件平台,该平台自带1 500 多个函数,可以搭建并部署数据挖掘与预测分析的各种流程。本实验使用RapidMiner9.4 运行AdaBoost 算法模型,基础模型是决策树,实验流程框架如图1 所示。
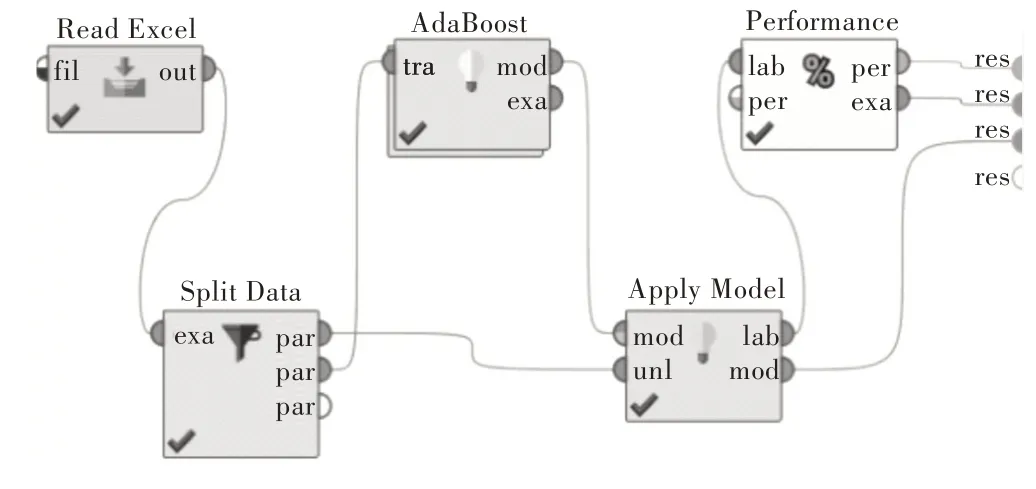
Fig.1 Experimental flow frame of AdaBoost algorithm图1 AdaBoost 算法实验流程框架
3.3 特征向量选择
对及格学习者和不及格学习者预测,是用一套指标还是区别对待,本研究通过特征向量选择对预测指标进行分组并加以验证。特征向量选择方法主要有主成分分析、卡方检验、信息增益等。由于本研究的所有指标经过标准化后全部为无量纲数值型数据,所以可以采用主成分分析法进行选择。首先把数据集导入SPSS22.0,然后调用Factor Analyze 过程进行分析,设置特征值大于1,采用最大方差法分析相关性矩阵。分析结果显示,KMO(Kaiser-Meyer-Olkin)检验统计量0.845,Bartlett 球形度检验的近似卡方值为4 787.54,主成分累计方差为79.16%,可以进行指标分组和精简。依据各主成分因子负荷不同,形成A、B、C、D 4个特征指标组,如表2 所示。
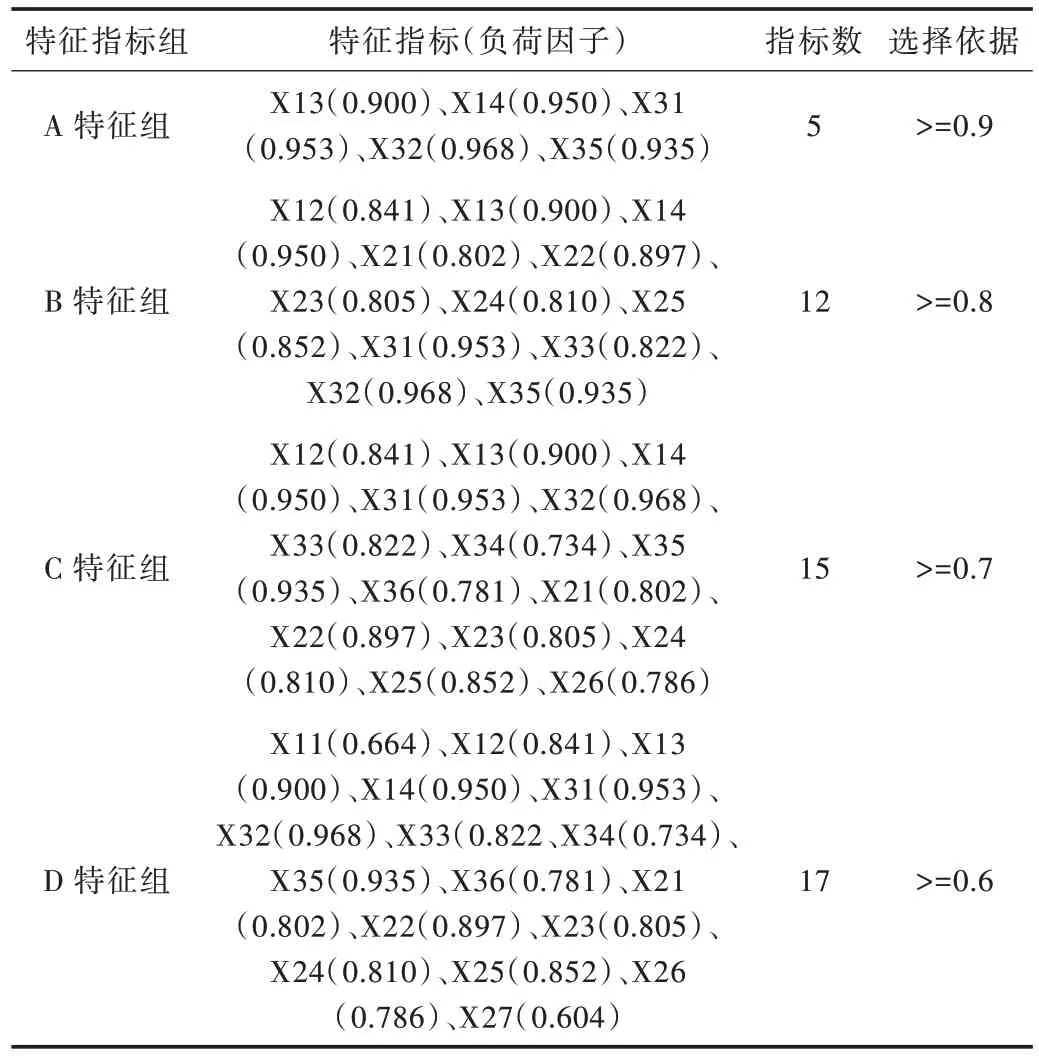
Table 2 Characteristic indicator groups表2 特征指标组
3.4 实验结果
基于实验平台输出的混淆矩阵,通过正精度(TP/(TP+FP))、负精度(TN/(TN+FN))和综合准度((TP+TN)/(TP+TN+FP+FN))3 个指标,对本文提出的基于AdaBoost 挖掘算法的MOOC 学习成绩预测模型进行全面评估。其中,TP代表真及格类,TN 代表真不及格类,FN 代表假及格类,FP代表假不及格类,实验结果如表3 所示。
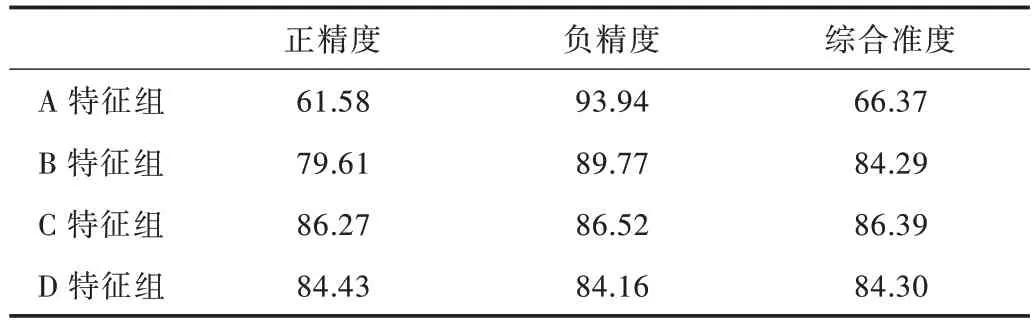
Table 3 Index of prediction ability of model表3 模型预测能力指标(%)
综合准度用来衡量模型的综合预测能力,对及格学习者和不及格学习者两种情况的预测精准度进行检测。从表3 可以看出,综合预测能力指标中C 特征组的综合准度为86.39%,预测能力最强;B 特征组和D 特征组的预测能力基本一样,A 特征组的预测能力最弱,综合准度为66.37%。
如果仅对“哪些学习者的学习成绩可能会不及格”情况进行预测,A 特征组的负精度为93.94%,数值最高,预测能力最强,也就是说利用X13、X14、X31、X32、和X35 这5个指标判断效果最好。如果仅对“哪些学习者的学习成绩可能会及格”情况进行预测,C 特征组的正精度为86.27%,数值最高,预测能力最强。
4 结语
利用学习者数据挖掘出有价值信息,是当前在线学习分析领域的研究热点。本文从学习者与平台交互、学习者与课程交互和学习者的社会性交互等多个方面汇集17 个特征指标,使用中国大学MOOC 平台的《互联网+教师知识个人管理》课程数据,对基于AdaBoost 算法的MOOC 学习者学习结果预测模型进行了验证。
本文构建的基于AdaBoost 算法的MOOC 学习者学习成绩预测模型具有较强的预测能力,综合预测精度为86.39%,具有实际应用价值。对“哪些学习者的学习成绩可能会及格”和“哪些学习者的学习成绩可能会不及格”两种情况进行预测,应该区别对待。对“不及格”情况进行预测,使用“登录间隔、登录间隔标准差、发布帖子条数、发布帖子字数、发布帖子质量”等5 个指标,预测精度更高;对“及格”情况进行预测,需要更多的预测指标,使用“在线时长、登录间隔、登录间隔标准差、浏览课程资源次数、浏览课程资源时长、查看课程信息次数、查看课程信息时长、浏览视频次数、作业提交次数、发布帖子条数、发布帖子字数、回评帖子条数、回评帖子字数、发布帖子质量、回评帖子质量”等15 特征指标预测效果更好,预测精度可达86.27%。TF-IDF 累计值、△t 标准差等体现质量的“质”型预测指标不但具有很高的因子负荷,而且全部进入预测模型,十分重要,今后应重视这类指标开发。
本研究不足之处是仅用一门课程数据对预测模型进行验证。为提高模型的泛化程度和稳健性,还需要更多数据集验证。另外,更多指标虽然有助于提升模型预测精准度,但不利于模型可解释性,后续要进一步寻求通过更少的指标对“及格”情况进行精准预测。
