深度学习在农业病虫害检测识别中的应用综述
2021-03-25边柯橙杨海军路永华
边柯橙,杨海军,路永华
(兰州财经大学信息工程学院,甘肃兰州 730030)
0 引言
目前,国内大多数农民对农作物病虫害的判别方法停留在传统的实地目测上,通过农作物的外观表面形态等进行判断,多依赖于个人经验。专家对于病虫害识别具有丰富经验,但往往不能及时赶往现场,或者因有限的人力资源不能进行大型区域识别,容易导致误判和漏判。如何有效、快捷地防治农作物病虫害,成为当前智能农业必须考虑的问题。
计算机视觉技术在农业应用中最为广泛,主要研究方向有作物病害检测与诊断[1]、农产品采摘预测[2]、农产品品质检测[3]、农产品分级等。使用计算机视觉技术在不影响农作物本身生长的前提下对农业病虫害进行检测识别,具有无损、快速、实时等特点。国内外专家学者在病虫害图像识别领域的研究工作主要集中在图像分割、图像特征提取、图像分类和识别等[4]。
本文研究的主要动因是:在农作物病虫害检测识别领域进行深入研究与探索,以促进农作物病虫害检测识别技术突破和广泛应用。为了全面认识农作物病虫害防治问题,本文重点分析39 项有关研究工作,这些研究对于深度学习在病虫害检测识别等方面的应用具有重要影响。
本文数据分析包括收集相关研究成果、详细审查与分析两个步骤。基于关键字搜索论文或期刊文章,主要来源于科学数据库CNKI 和ElsevierScienceDirect,以及Web 科学索引的科学服务网和谷歌学术。本文使用关键字“深度学习”“病虫害识别”“农业”进行搜索,过滤掉涉及深度学习但不适用于农业领域病虫害识别的文献。通过有效筛选,在搜索集合里选取有意义的论文共39 篇。本文主要就以下内容进行比较分析:①数据来源、类型及标注情况;②数据预处理或增强技术使用;③深度学习应用领域;④深度学习模型或其它相关模型的一般方法和类型;⑤度量标准和总体性能。
1 深度学习
深度学习方法是一种特征表示方法,它能将原数据通过简单的多种非线性模型组合转变为更高层次的抽象形式,而其核心是各层特征而不再是人工设计,通过通用的学习过程自主获得[5-8]。正是由于深度学习能自动提取高层次特征的特点,采用它进行图像处理时极大减免了特征工程的复杂操作,减少了模型训练时间[9-10],使得模型分析结果更精准[11],运行效率也相对较高[12]。并且,深度学习模型可以开发模拟数据集以解决实际问题[13]。
得益于深度学习在众多领域的成功应用,现阶段国内外大量学者将目光投向了深度学习和农业领域的结合上,而其中应用最普遍的深度学习技术是卷积神经网络(Convol-utional Neural Networks,CNN)[14-18]。卷积神经网络模型是一种前向神经网络和深度学习方法,通过共享权值、局部连接和池化达到网络更优化并降低过拟合。由于多层卷积层和池化层能提取图像的分类特征,Softmax 分类器能实现图像分类识别,因此其被广泛应用于图像识别相关领域。卷积神经网络最先由Lecun 等学者提出,用在手写体识别上,取得了较大成功。近年来,卷积神经网络在图像识别领域展现出强大能力。2012 年,Hinton 的研究小组提出用深度卷积神经网络识别图片,在ImageNet 数据集上将分类错误率大幅降低,掀起了深度学习的热潮。之后VGG(Visual Geometry Group)、GoogleNet 等在ImageNet 数据集上,将分类错误率进一步降低,它们对此前的卷积神经网络进行改进,使用更小的卷积核,以及更深的网络结构。这些网络在大的数据集上才会体现出性能上的优异。2012 年,AlexNet 模型被提出,将图像识别错误率较之前降低50%[14],至此,CNN 在图像识别和分类领域的应用被重新重视起来。
当前,深度学习模型大量涌现并得以推广应用,研究人员可以借鉴相关模型开展研究,避免从头开始模型构建,提高了工作效率。常用CNN 模型包括AlexNet、CaffeNet、VGG、GoogleNet 和Initiation ResNet 等。这些模型通过卷积层和池化层代替全连接层(见图1),并实现不同神经元之间的权值共享,使它们更类似于生物神经网络,降低网络复杂度,减少网络参数。并且,这些模型都经过一些数据集的预训练,其带有预训练的权重参数,会为某些特定问题提供相对有效的分类功能。
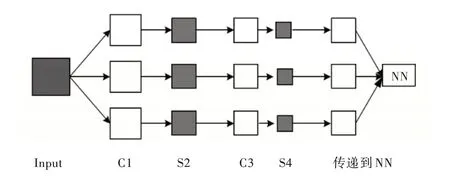
Fig.1 CNN basic model(C*;Convolution layer,S*:Pooling layer)图1 CNN 基本模型(C*;卷积层,S*:池化层)
此外,各种深度学习框架相继出现,以便于研究人员进行实验,最常见的有Goolgle 公司研发的Tensorflow、Mi⁃crosoft 公司研发的CNTK(ComputationalNetworkToolkit)、Fchollet 公司研发的Keras、DMLC 研发的MXNet 以及BLVC(BerkeleyVisionandLearningCenter)和社区贡献者共同研发的Caffe 等。这些深度技术框架主要被应用于图像识别分类、手写字识别、语音识别、预测、自然语言处理等方面。其中一些工具(如Caffe)包含了流行的模型,如上文提到Alexnet、VGG 和Googlenet,可以作为库或类使用。
近年来,基于深度学习的特征提取与识别方法受到了极大关注,并在自然图像分类识别中被成功应用。大量试验结果表明,基于深度学习得到的特征表达比手工设计的底层视觉特征,如HOG(Histogram of Oriented Gradient)、SIFT(ScaleInvariant-Feature-Transform)特征等,在图像识别方面具有更大的优越性。
2 农业病虫害检测识别中的深度学习应用
本文对39 项农业病虫害相关研究工作进行分析,并介绍它们的数据来源、所使用的数据预处理技术和数据增强技术、研究对象、选择的深度学习模型和体系结构、采用的性能指标。
2.1 数据源
观察所研究文章的数据集,如表1 所示,大部分研究使用的数据集规模较大,图像数目多达千张甚至上万张。
研究中涉及的数据集分为两类:一类是自主获取,包括采用高清相机或手机进行拍摄获取;网上获取并裁剪合成;使用高普光成像仪获取图像或使用农业互联网传感器采集昆虫数据信息;另一类来源于公开数据集,其中使用最为广泛的是Imagenet 和PlantVillage 等。ImageNet 数据集是为了促进计算机图像识别技术发展而设立的一个大型图像数据集,其中已经超过千万张图片,每一张图片都被手工标定好类别。PlantVillage 是一个公开数据集,已经收集成千上万健康和患病作物图片,并公开和免费提供这些图片。
一般认为,使用深度学习技术进行识别的类别越复杂,种类越多,需要的数据就越多。因此,大量真实的数据集在模型训练和测试中具有重要影响。
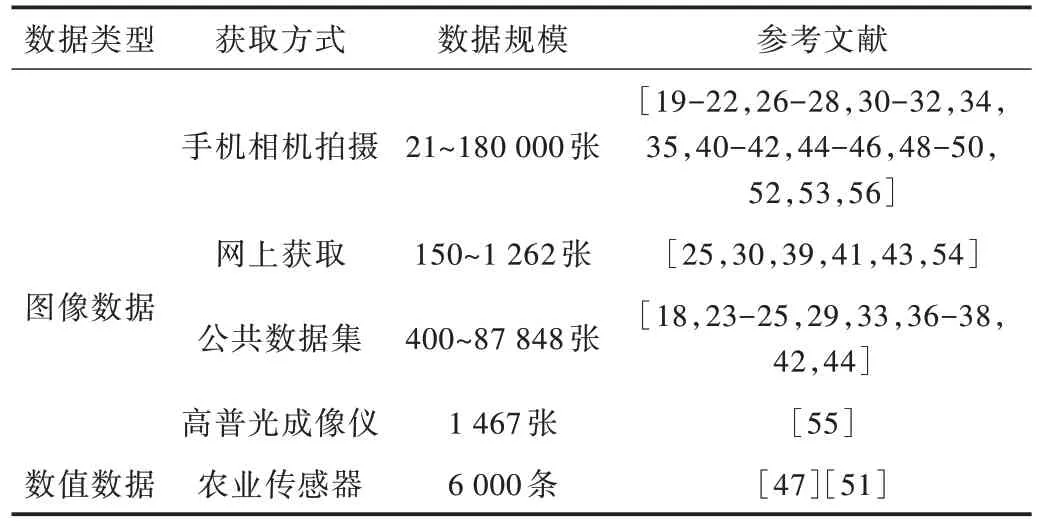
Table 1 Data source表1 数据源
2.2 数据预处理
部分研究(32 篇论文,80%)为了实现识别效果最优化,在图像或图像的特定特征输入到深度学习模型之前对图像作预处理。在使用深度学习对图像进行分类识别时,图像的亮度、对比度等属性对图像识别效果影响非常大,相同物体在不同亮度和对比度下的差别非常大。在农业病害图像检测识别问题中,经常会遇到阴影、强曝光之类的图片,这些因素都不应该影响最后的识别结果,因此要对图像作预处理,使得到的实验结果尽可能小地被无关因素所影响。调整图像大小是最常见的预处理过程,深度学习模型常用尺寸有:256×256、227×227、224×224 等。图像分割也是图像预处理的一种较流行的做法,可以增加数据集规模,也可以通过突出感兴趣的区域促进学习过程,使专家和志愿者更容易对数据进行注释。研究表明,采用分割图像的平均识别精度相比原始图像取得了更好的识别效果,其余数据预处理方法如表2 所示。

Table 2 Data preprocessing表2 数据预处理
2.3 数据增强
部分研究(24 篇论文,59%)采用数据增强技术,人为扩大训练图像数量,这有助于改进整体学习过程和性能,并且可以为实现泛化而向模型提供不同的数据。这种增强过程对于那些只拥有小数据集训练其深度学习模型的研究极其重要,作者使用合成图像对模型进行训练,并在真实图像上进行测试。在这种情况下,扩充的合成图像数据扩大了训练集,使其训练出的模型更有效,提升了泛化能力,能够更好地适应实际问题。尤其是,在Hu 等[19]的研究中,利用改进的条件将卷积生成对抗网络(C-DCGAN)生成新的训练样本进行数据增强,平均识别精度比旋转和平移的识别精度高28% 左右;DeChant 等[21]运用硬负挖掘技术,即采用55 步长的滑动窗口方法,将未感染植物的图像分解成不同像素;黄双萍等[55]通过对高光谱图像随机扔弃波段图像增加数据集规模。其它常见数据扩充方法如表3所示。

Table 3 Data enhancement表3 数据增强
2.4 研究对象
本文研究的39 篇论文都集中在农业病害领域,其中有33 篇论文对农作物病害叶片进行检测识别,4 篇论文直接对病虫图像进行检测识别,两篇论文对农作物病虫害进行预测。
2.5 应用模型与框架
从技术角度看,本文所涉及的研究工作大都(37 篇论文,95%)采用了CNN 模型。大部分研究(28 篇,72%)基于已存在的CNN 模型进行优化,包括AlexNet、LeNet、VGG16、ResNet 和DenseNet 等,或建立自己的卷积神经网络模型(9 篇,23%),如表4 所示。

Table 4 Deep learning network model表4 深度学习网络模型

续表
此外,有些研究利用迁移学习开展工作(14 篇论文,36%),这涉及到利用一些相关任务或领域的现有知识,通过微调预先训练的模型以提高学习效率。因真实数据集很小或具有复杂的多任务网络而无法从头开始训练网络,因此需要用另一个预训练模型中的权重对网络进行部分初始化。通过微调,这些模型将适应特定的任务和数据集,适用于VGG16、DenseNet、AlexNet 和GoogleNet 等模型。一些研究将深度学习模型与弱机器学习分类器进行结合,张苗辉[52]通过CaffeNet 提取害虫特征后,通过稀疏编码法,即构建稀疏字典,并通过稀疏表示算法获得测试样本的稀疏系数并进行分类识别;安强强等[53]利用自建的6 层CNN 网络提取害虫特征后,输入SVM(Support Vector Machines)中进行分类识别,相对于人工提取特征,深度学习的特征自动提取取得了更好的分类效果。通过深度学习模型自动提取特征提高了特征提取速度,相比于简单地提取颜色、形状和纹理特征,其最终分类识别效果更好。
除采用卷积神经网络模型外,有研究使用深度置信网络对农作物病虫害进行预测。张善文等[47]对深度置信网络进行改进,使用无监督和有监督训练形成特征集后输入BPNN 中对冬枣病虫害进行预测;王献锋等[51]提出一个改进型深度置信网络,由RBM(Restricted Boltzmann Machine)网络和一个DRBM 网络(判别RBM)构成,用于对棉花病虫害进行预测。深度置信网络的数据不同于卷积神经网络,其为数值数据,多采用农业传感器获取,数据获取手段单一是限制其预测效果的关键原因。
这些研究工作所用模型都在一些常用的深度学习框架下进行测试,其中Caffe 使用次数最多(9 篇论文,23%),其次是MATLAB(8 篇论文,21%)和Keras(7 篇论文,18%)以及Tensorflow(4 篇论文,10%)。Caffe 和MATLAB 广泛使用的一个可能原因是它们结合了各种CNN 模型和数据集,用户可以轻松、自动地使用这些框架和数据集,如表5所示。

Table 5 Main deep learning framework表5 主要深度学习框架

续表
2.6 性能指标与对比
对于分类效果评价指标,表6 列出了这些度量的符号和定义。在一些论文中,作者提到精度而没有说明其定义,假设他们为分类精度(CA,表6 中列出的第一个度量)。在本文研究中,将“深度学习性能”作为表6 中所列性能指标值。

Table 6 Main performance index表6 主要性能指标
在使用同一数据集且具有相同度量的前提下,基于同类问题对深度学习方法与其它技术进行比较(17 篇论文,57%),或基于深度学习不同模型之间进行比较后发现,几乎在所有的研究工作中,深度学习模型都优于其它方法,其在农作物病虫害检测、识别和分类中均表现出很好的效果。例如,在DeChant[21]的研究中,其使用分段式CNN 对玉米病害进行识别,在运行时,为一个图像生成一个热图大约需要2min,而对一组3 个热图分类则需要不到1s 的时间。在Cheng 等[33]的研究中,将卷积神经网络模型ResNet 与支持向量机和传统BP 神经网络相比,在复杂农田背景下的pest 图像识别精度有明显提高;黄双萍等[55]在水稻穗瘟病检测中,将优化的GoogleNet 模型与SVM 和词袋模型进行比较,准确率提高了14 个百分点。
3 讨论
分析表明,在每篇论文中,将基于深度学习的方法性能与其它技术进行比较时,最重要的是要坚持相同的实验条件(数据集和性能度量),并将基于传统机器学习的方法和其它每篇论文中所解决的特定问题而采用的先进技术进行比较。
每篇论文涉及不同的数据集、预处理技术、度量、模型和参数,因此每篇论文中使用的技术受到严格限制。基于这些约束条件可知,深度学习比传统的SVM、Decision Tree等分类器有更好的分类表现。在特征提取方面,相较于尺度不变特征变换、纹理、颜色和形状等传统方法,深度学习模型的自动特征提取更有效。
本文研究表明,一些研究工作取得了较好成果,因为其数据集具有较高的真实性和较大的规模性,而对于部分真实数据集则较少研究,观察其对模型的迁移学习预训练并在真实数据上进行测试,其中数据集中真实数据所占比率越高,分类效果越好。因此可以得出,迁移学习是深度学习的重要内容,它是解决各种研究问题中真实数据集不存在或不够大的关键,但其中数据集中真实数据所占比率仍是影响其实验效果的关键因素,真实数据比率越高,分类效果越好。
3.1 深度学习模型优化
大多数论文基于已存在的深度学习模型进行优化(28篇,72%)。优化目的包括减少训练参数、提高运行速度和提高分类效果等。
通过添加Dropout 层、改变池化组合、校正线性单元(Relu)函数、减少分类器数量等减少训练参数。采用SGD优化模型并提高分类效果,由于SGD 每次选择样本都具有一定的随机性,从而在训练过程中会产生些许波动,为了减少波动,可以选择加入优化器Momentum、RM-Sprop 和Adam,或采用批量随机梯度下降法(MSGD-stochastic Gra⁃dient Method with Minibart-ches),它将训练数据集分割成小批量,用于修正模型错误和更新模型参数。
有些研究采用了不同的优化方法。Hu 等[31]将标准卷积替换为可分离卷积,用于减少模型参数个数,提高模型计算速度;Albert 等[20]和刘永波等[44]通过向模型中补充额外特征以提高分类识别效果;贾少鹏等[54]为了弥补空间信息丢失,以胶囊网络代替全连接层。
研究也表明,并非网络深度越深,识别率越高,在不同的应用场景下,需要根据实际问题的复杂程度,选择简单或者复杂的网络。例如,Rahman 的研究中提出,相比于追求更先进的CNN 结构,农民更需要一个能够离线运行基于CNN 模型的水稻病虫害检测移动应用,因此其提出了一个两阶段的小型CNN 结构,参数相对于AlexNet、GoogleNet和LeNet-5 等大幅度减少,学习能力下降但运行效率提升,在实际应用中更加广泛。
3.2 深度学习缺点及局限性
(1)数据集要求较大。尽管数据增强技术可以增加一些具有标签的数据集,但实际上根据所研究问题的复杂性(分类数、所需精度等),深度学习至少需要数千张甚至上万张图像。有些研究没有考虑到研究对象的多种外界条件影响,使得数据采样不够充分,这一事实降低了对总体分析结果的可信度,尽管研究表明,这些模型似乎具有良好的通用性,但性能优化或上升幅度很小。因此,为了提高模型泛化能力,需要更加多样化的训练数据。而当前国内农业病虫害相关公共数据集较少,迫使研究人员耗费大量时间获取数据,降低工作效率。针对数据集较小的问题,除迁移学习外,部分研究采用数据增强技术对自己的数据集进行扩充。数据扩充能有效增加真实数据集规模,从而提高检测分类效果。但同时发现,迁移学习弱化了数据扩充的作用,即数据扩充对全新学习的影响大于迁移学习,但对于数量较小的数据集,迁移学习后进行数据扩充仍然可以有效提高模型识别性能。动态的数据扩充方式节省了存储扩充数据所需的巨大空间,丰富了数据的多样性,可以减轻模型过拟合现象,但在一定程度上破坏了原数据集的样本分布,增加了训练的波动性。
(2)数据预处理耗时长。数据来源冗杂混乱,需要对数据进行归一化或离散化以适应模型需要。有些数据集中不同类别之间的区分特征差别较小,或存在低分辨率、低准确度形式的噪音、作物阻塞、植物重叠和聚集等问题,对研究的识别效果有很大影响,因此要进行数据预处理以增强实现效果。
(3)实验条件不足。深度学习在训练过程中产生大量参数,耗时长且占用内存较大,需要较大的计算资源。有些研究为了减少参数数量,采取了一些优化方法,包括减少全连接层和卷积层,迁移学习或选用轻量级的CNN 模型。
3.3 深度学习在农业病虫害检测识别中的应用前景
在农业计算机视觉方面,深度学习应用已十分广泛,但多数都集中在土地覆盖分类、作物类型估算、作物物候、杂草检测和水果分级方面,对于种子鉴定、土壤和叶片含氮量、灌溉、植物水分胁迫检测、水蚀评估、害虫检测、除草剂使用、污染物鉴定等的研究相对较少。相关研究工作中讨论的一些解决方案表现出一定的商业用途,尽管模型培训需要大量时间(在高性能GPU 集群计算机上需要多个小时),但分类本身非常快(在CPU 上不到1s),因此可以很容易地在智能手机上加以实现。这为在全球范围内利用智能手机辅助诊断农作物疾病提供了一条可行路径。
根据当前农业病虫害检测识别可分为几下几个研究方向:
(1)建立国内大型农业图像数据库。与国外相关研究相比,我国农业病虫害图像数据库建立相对落后,一般的实验数据集大多是研究人员自行采集,没有建立起联通的数据库网络,而一般的图像采集将大大耗费研究人员的时间,降低研究效率。
(2)利用红外热成像和高光谱成像技术采集农作物信息。可见光成像技术已趋于成熟,为了弥补其只能采集农作物表面信息,引入红外成像和高光谱成像,这是农作物病虫害检测的一个重要方向。
(3)将手工提取特征和使用各种技术自动提取特征相结合,以提高整体性能。
(4)模型轻量化。提高算法执行速度,满足实时性要求,以实现在移动设备上的应用,这是当前深度学习在农业病虫害识别领域的重要突破方向。未来研究将致力于构建微型版本的具有较高内存效率的非顺序型CNN 架构。
