政府政务微博效能评估及可视化分析
2021-03-25贾斯涵郝琳琳
贾斯涵,王 英,郝琳琳,王 鑫
(1.吉林大学计算机科学与技术学院;2.吉林大学人工智能学院,吉林长春 130012)
0 引言
从2009 年开始,作为新型的社交媒体平台,微博逐渐走进了人们的视野中。10 年间,微博发展到如今的月活跃用户5.16 亿人次,愈来愈多的人开始借助微博了解世界,微博也因此成为人们沟通交流、情感表达的重要媒介,其间充斥着大量带有情感色彩的评论与观点,使得这些微博文本无论是在商业分析还是舆情监测中都具有重要的经济和社会价值[1]。政务新媒体是近年来政府紧跟时代脉搏的产物,是加快政府职能转变,提高政府治理能力的重要手段。作为政务新媒体发展最早、最成熟的社交平台,政务微博已经成为各级政务机构推行政务公开,拉近政府与公众距离的重要载体。
本文针对政府政务微博的效能评估及可视化分析问题,使用卷积神经网络解决政务微博评论的情感分析问题,利用Echarts 工具,从公众反响、传播能力、互动用户的整体特征等角度进行可视化,实现舆情统计和分析。
1 情感分析方法概述
文本情感分析,又称倾向性分析、意见挖掘等,是自然语言处理(Natural Language Processing,NLP)的一个重要领域。世界上绝大多数数据都没有预先定义文本的组织结构,通过构建模型识别和提取文本中的观点和特征,对文本进行理解和分类,可以帮助人们在数据爆炸时代快速处理非结构化文本,提高工作效率。现有的情感分类技术主要有3 类。
1.1 基于情感词典的方法
基于情感词典的分类方法比较机械化,需要大量文本作为基础素材,模拟人的思维进行判断,通过对语料库的人工整理构建不同粒度的情感词典,以及否定词词典、程度副词词典等自定义词典。
最基本的方法是对词典中情感程度相同的词组赋予相等权重,将分词后的词语与语料库词典中的词进行匹配,对情感值进行线性叠加,其中否定词和副词可以根据实际情况生成自己的判断规则:判断为否定词时,权值反号处理,判断有副词时,可以进行倍数处理。目前,较为知名的中文词典包括台湾大学整理的NTUSD 词典、知网发布的Hownet 情感词典以及清华大学李军中文褒贬义词典。
但无论如何改进,基于情感词典的分类方法都存在它独有的局限性,即它始终依赖于“词典”本身,这也意味着情感词典在面临新词的不断迭出和旧词新意等情况时,无法及时扩展更新。同时,由于情感词典的不同选择,情感分类结果也会因此受到影响。
1.2 基于机器学习的方法
近年来,随着人工智能的快速发展,机器学习不断进入人们的视野中,其关键步骤是如何使机器可以像人一样学习。基于机器学习的情感分析方法主要是手动进行文本特征提取,通过一系列指令让机器从数据中学习,最后根据这些指定的算法对文本实现分词,并输出情感分类的最终答案。它能有效解决词库无法及时更新的问题,在减少人工成本的同时,分类效果也很好。其中,较为常见的算法为支持向量机(SVM)、最大熵和朴素贝叶斯等。
1963 年,一种有监督的非概率模型,即支持向量机被提出。该算法基本原理是在训练集合中找到最优的超平面H,最优的分类超平面可以满足将不同类别的数据以最大间隔分开。将标记好的文本表示映射成多维空间上的点,通过学习将不同情绪的样本划分到空间的不同区域,并对新文本进行情绪极性预测[2]。
但是作为有监督的机器学习,其局限性体现在手动标记文本特征,同时过度依赖分类器。在大数据时代,基于机器学习的情感分析方法训练大规模文本数据较为困难[3]。
1.3 基于深度学习的方法
作为机器学习的一个重要分支,深度学习是利用深度神经网络模拟生物的神经系统解决特征提取问题[4]。有别于浅层模型,它可以自动从原始数据中学习层次化的特征,高效地标示出数据中蕴含的复杂模式[5]。同时可以很好地避免传统的情感分析方法带来的的局限,在进行文本情感倾向性分析时,它能够自动提取文本特征,并在学习过程中不断地修正模型。
卷积神经网络(Convolutional Neural Networks,CNN)在文本分类的第一个应用中是由Kim[6]提出的一个模型,在其研究结果中CNN 对于情感分类的效果要远好于SVM,避免了显示的特征抽取,同时网络可以并行学习,降低了运行的复杂度。其中,卷积神经网络的特征包括局部感知,可以减少参数数量,降低过拟合的可能性;共享权重可以帮助神经网络的输入保持空间不变性,混合可以简化从卷积层输出的信息[7]。在文献[8]中,作者对于TextCNN模型做了大量调参测试,对其进行的文本分类给出了具体建议,包括对预训练词向量、激活函数的研究等;在文献[9]中,作者对比了TextCNN 模型、基于TF-IDF 特征提取的传统机器学习模型以及LSTM 模型,实验结果显示在短文本分类中,TextCNN 模型的准确率远高于传统机器学习模型,且训练时间远小于LSTM 模型;文献[10]提出的动态卷积模型(DCNN)更加复杂,但其可以提取句子中活跃的特征,同时性能显示出非常好的结构。
长短期记忆网络(LSTM)作为特殊的RNN 网络,专门为了解决普通循环神经网络的长期依赖问题而设计。它由Hochreiter 等[11]于1997 年首次提出。接下来,越来越多的专家学者投入到情感分析研究中。刘腾飞等[12]提出结合循环网络和卷积神经网络的文本分类研究,结果显示这是一个可以利用卷积神经网络获得有价值的特征,利用循环网络高效获取文本内部信息的复合模型,在完成文本分类任务中显现出良好性能。李洋等[13]提出一种卷积神经网络和BLSTM 特征融合的模型,利用CNN 提取局部特征,利用BLSTM 提取与上下文本相关的全局特征,结果较二者分别使用准确率更优。
但是对于CNN 进行文本分类仍然需要大量的研究工作,未来还需要注意卷积核大小、超参数调节等问题,同时进行CNN 与其它深度学习算法的融合实验[14]。
2 基于深度学习的情感分类方法
自然语言处理领域较为活跃的研究方向包括文本分类,根据情绪的不同进行分类可以视为情感的倾向性分析。深度学习算法在计算机图像中取得显著成绩,运用到文本分类中也表现出色。
2.1 卷积神经网络
卷积神经网络属于前馈神经网络,最早可以追溯到1962 年的一项生物学研究。现已发展为深度学习领域一项重要模块,主要用于图像识别。它主要运用了3 种基本概念:局部感受野、共享权重和混合。
(1)局部感受野(Local Receptive Fields)。在卷积神经网络中,输入一般看作方形排列的像素矩阵,这不同于在传统网络中,输入的神经元被理解为纵向排列的形式。同时,与全连接层网络的每个输入神经元连接到每个隐藏神经元不同,卷积网络只将输入图像的像素进行局部区域连接,即一个隐藏神经元对应输入神经元的一个小矩阵,该矩阵叫做局部感受野,针对不同的神经网络可以移动不同的跨距。这样可以有效解决全连阶层网络而不考虑空间结构问题。
(2)共享权重(Shared Weights)。由于一部分输入像素对应一个隐藏神经元,因此在卷积网络中,每个连接对应相等的权重,同时每个隐藏神经元也对应一个相等的偏置。同时,将卷积层中训练的所有权重或偏置设置为相同的权值,这种平移不变性可以有效减少需要学习的参数量。共享的权重和偏置可以被视为一个滤波器或者卷积和。
(3)混合(Pooling)。混合也称作池化。其本质是简化从卷积层输出的信息,起到类似压缩图片的作用。混合算法一般包括最大值混合(max-pooling)和L2 混合(L2 pool⁃ing)。其中,最大值混合是计算出相邻区域内的最大激活值,而L2 混合是取区域内所有值平方和的平方根。神经网络结构不同,两种算法使用效果也不同。卷积神经网络的多卷积核使得其最终可以获得多种特征。
2.2 TextCNN
Kim[6]在2014 年提出了TextCNN,结构如图1 所示,他将用于图像识别的卷积神经网络应用于文本分类技术中,利用不同大小的卷积核提取文本中的关键特征,从而达到良好的文本分类效果。
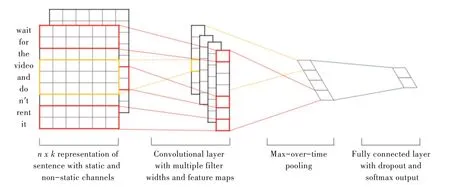
Fig.1 TextCNN model structure图1 TextCNN 模型结构
(1)嵌入层(Embedding Layer)。嵌入层输入降维后的句子矩阵,其中每一行表示一个词向量,若矩阵大小为n×k,则词向量的维度为k,矩阵大小为7×5,则词向量维度为5。类似CNN 模型中输入图像的原始像素。
(2)卷积层(Convolution Layer)。在TextCNN 模型中,由于文本的最小粒度是词,因而词向量的维度s 就是卷积核的宽度。高度即窗口大小一般设置为2、3、4,可以得到不同的特征图,同时考虑了文本的上下文。
(3)池化层(Polling Layer)。TextCNN 在池化层中选用1-Max-pooling 抽取每个特征中的强特征,认定其为最重要的特征,同时解决了经过窗口大小不同的卷积核后特征向量维度不相等的问题,并保证了特征值位置不变。
(4)全连接层(Fully Connected Layer)。TextCNN 的最后一层为全连接层,输出时经过softMax 激活函数,它用来计算每个类别可能为正确结果的概率,最终可以将具有最大值的特征作为该文本的类别。
其中,TextCNN 的详细过程如图2 所示。
3 研究思路与框架
3.1 研究思路
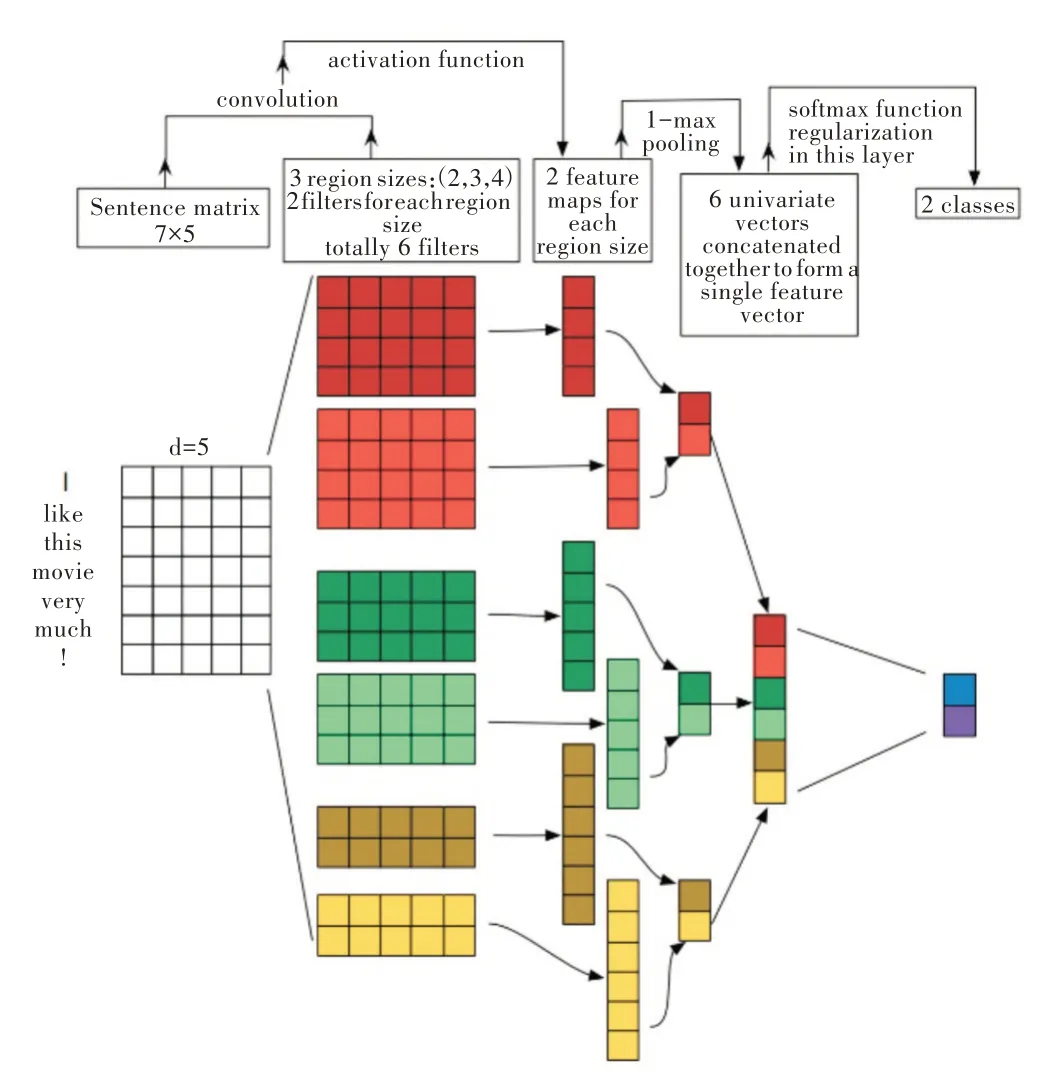
Fig.2 TextCNN 's specific process图2 TextCNN 的具体过程
鉴于微博篇幅精简、表达生活化等特点,针对微博评论的情感倾向性分析,在分类前需要对非结构化的原始数据集进行预处理,即对文本进行中文分词和词向量训练,将文本转换为数字特征的同时进行降维处理,并联系上下文语义。本文采用基于深度学习的方法,区别于传统情感分类算法的词典构建和特征提取,深度学习算法更加高效和精准。对此,采用TextCNN 深度学习算法对政务微博下的评论进行训练,完成积极、中立、消极的情感分类。
针对数据可视化部分,据微博原文下参与互动的用户相关信息、评论内容及政务微博本身,本文将采用Echarts工具构建图表,直观展示政府政务微博的受众特点、传播能力等特征,达到对效能评估结果的可视化展示目的。
本文通过引入对信息其它层面多维度的统计与分析,改进了情感倾向性分析独立存在的问题,形成多角度交叉对比,最终达到效能评估目的,并实现可视化分析,使枯燥的数据更加生动具体,让人一目了然。
3.2 效能评估及可视化分析
本文的效能评估是指将训练好的用户评论数据集与互动用户数据集和政务微博数据集一同进行交叉或独立式处理,包括从用户地区分布、用户年龄分布等角度进行统计,最终达到效能评估结果,而其中的情感倾向性分析为本文效能评估重点。
对于可视化分析,本文采用Echarts 开源可视化工具作为将非结构化的数字信息转化为可视化图表的媒介,以更为直观的方式让数据在可视化的同时达到展现分析结果的目的。
3.3 研究框架
本文通过对政府政务微博进行可视化的效能评估,提供更科学的评估手段,不仅可以推动技术上的革新,同时更有利于推进媒体管理模式创新。数据集选自法制日报、平安北京、首都网警、人民日报、中国警方在线以及最高人民检察院的政务官方账号所发布的1 385 条微博、其下的17 587 条评论,以及13 679 名参与讨论的微博用户信息。
根据已有的微博评论,采用基于深度学习的情感分析方法,包括对数据集进行切分、预处理和分类。在分类过程中,采用三分类算法,将情感倾向性划分为积极、消极和中立。同时,在微博用户属性、政务官方微博活跃程度等方面进行数据统计和对比,最终利用Echarts 开源可视化库对结果进行展示。
政府政务微博效能评估及可视化分析总体方案可大致分为以下4 个步骤,如图3 所示。
(1)Jieba 中文分词。分词的目的是进行情感分析,需要使用的数据集为微博评论文件中的评论部分,并将数据集划分为测试集和训练集。分词选用的是精确模式,可以将句子中的词准确地加以分解,有利于后续文本分析。
(2)词向量训练。传统特征提取方法需要评估函数才能进行权重计算,而评估函数是基于统计学方法的,需要规模较大的训练集,本文所使用的数据集规模较小,不适用于类似TF-IDF 的传统做法。采用Keras 平台的嵌入层进行词向量训练模型可以有效解决one-hot 的维度爆炸问题,将文本数据映射到低纬度稀疏矩阵中,并可以直接应用于TextCNN 后续步骤。
(3)TextCNN 分类算法。TextCNN 分类算法来源于卷积神经网络,其在文本分类中展现了很好的结果,解决了传统神经网络由于全连接层而需要训练大量参数的问题。使用三分类算法,在最后一层使用softMax 全连接层,将积极、消极、中立的分类预测以概率形式输出。
(4)可视化显示。由于本文数据集规模较小,采用MySQL 数据库进行存储,使用PHP 语言执行SQL 语句进行数据库的连接和操作,同时与HTML+CSS+JavaScript 结合进行后续Web 可视化应用。在可视化实现过程中,使用Echarts 开源可视化库从多种角度对用户信息、政务微博和评论内容进行统计和整理,最终以多种形式的图表呈现政府政务新媒体的评估结果。
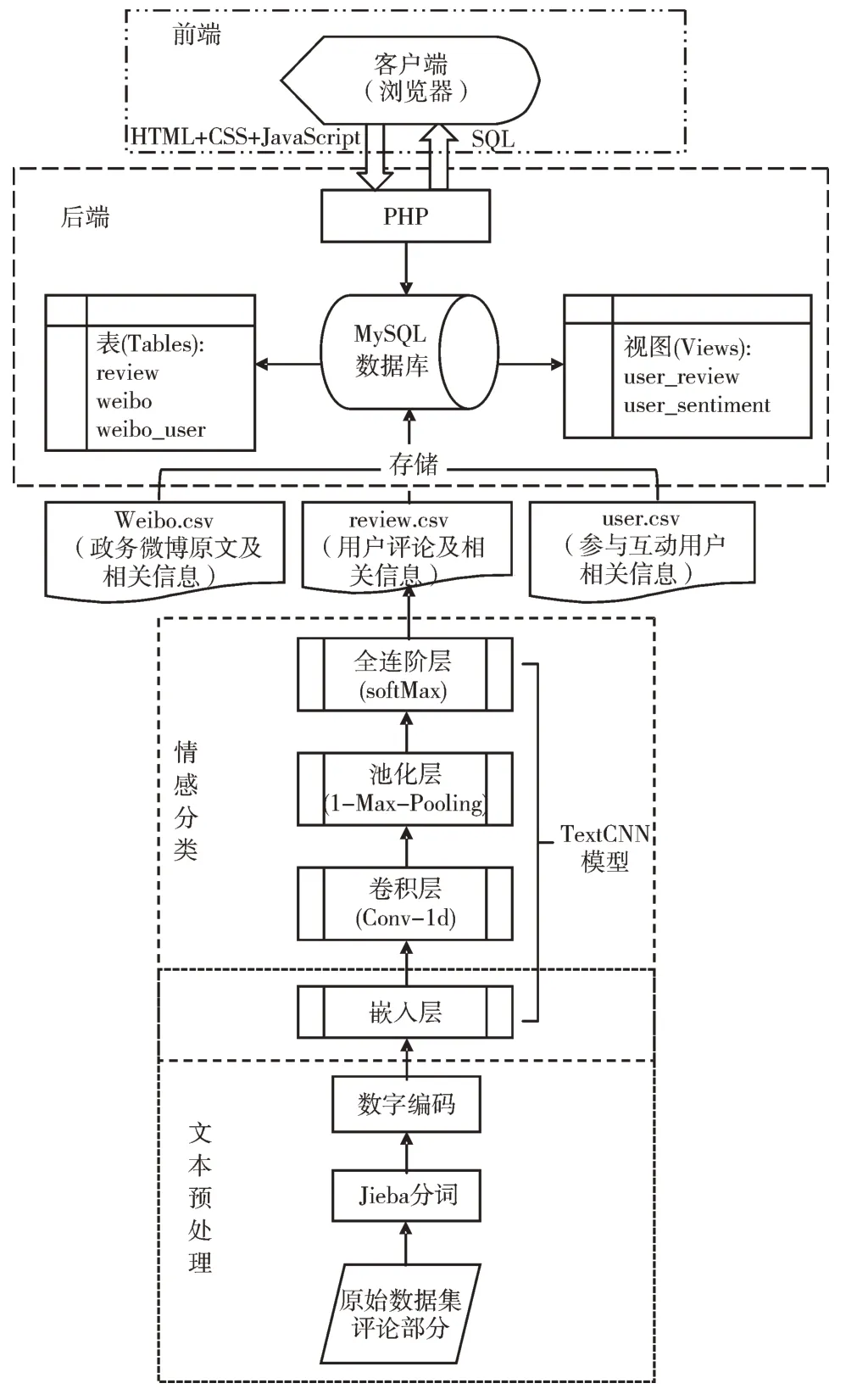
Fig.3 The overall scheme of effectiveness evaluation and visual analysis of government Microblog图3 政府政务微博效能评估及可视化分析方案
4 情感分类模型实现
4.1 文本分布式表示
首先采用Keras 的Tokenizer 模块将分词后的文本转化为机器可识别的数字矩阵,创建好Tokenizer 对象后,利用fit_on_texts()函数根据词的词频进行编号,出现次数越多,编号越小。采用texts_to_sequences()函数,将文本转换成数字特征,形成整数形式的索引序列。使用pad_se⁃quences()函数对每条文本进行填充或修剪,设置一个固定值,超过阈值的会被截掉,不足的会在序列前面填充0,设置的最大长度为50。利用TextCNN 模型的第一层Embed⁃ding 层将每个编码的词进行one-hot 编码,然后通过卷积神经网络进行线性变换,使其嵌入到低维空间中,最终映射成为稠密矩阵,同时通过神经网络不断迭代,嵌入的词向量得到训练和更新,使得上下文语义也得到了联系。
4.2 TextCNN 模型搭建
本文选用通过卷积神经网络处理文本分类的TextCNN模型。模型结构如图4 所示。
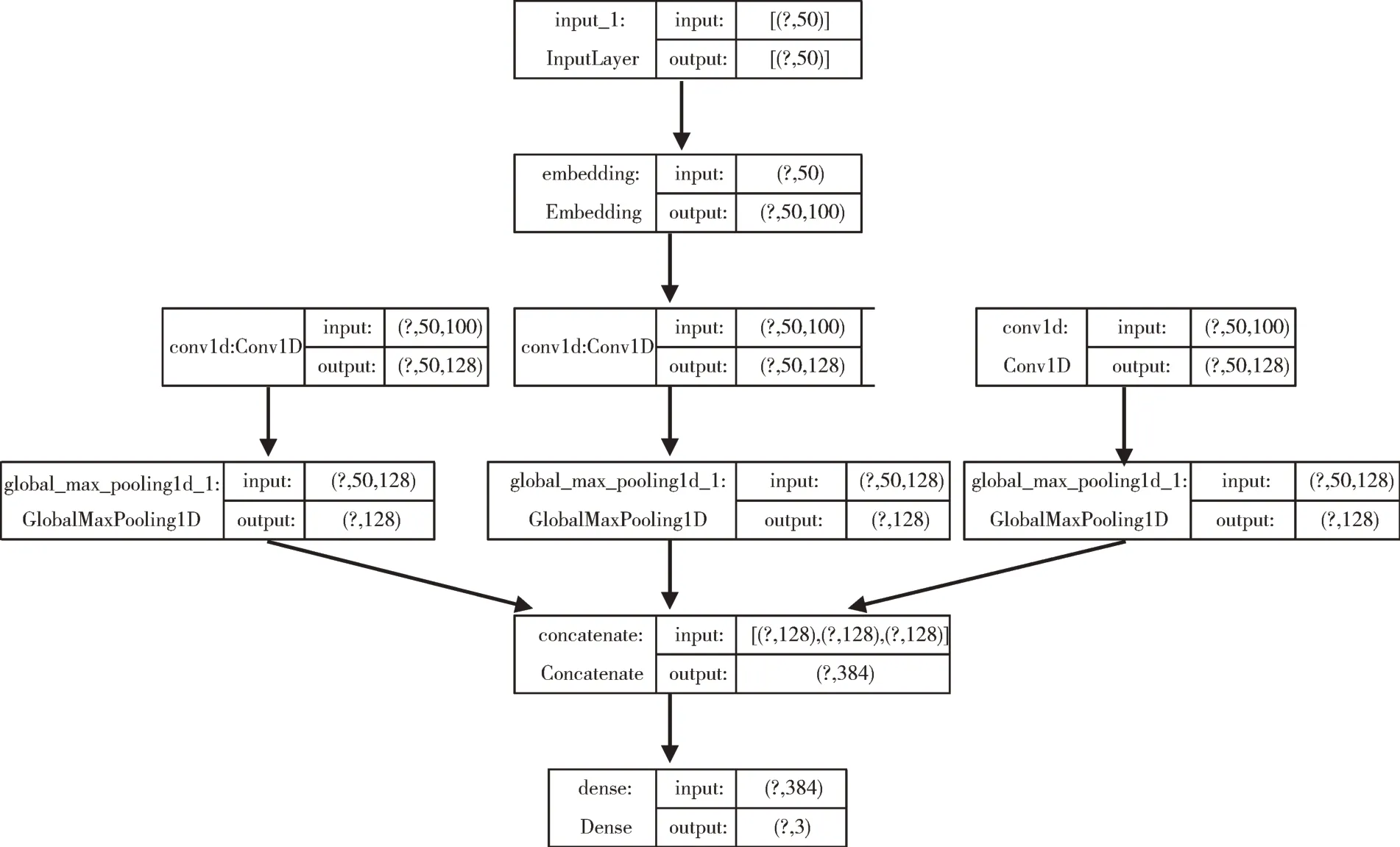
Fig.4 Construction of TextCNN model图4 TextCNN 模型搭建
第一层为嵌入层,第二层为一维卷积,第三层为池化层,窗口大小分别为3、4、5,它们通过融合层拼接在一起,其中激活函数为线性整流函数(Rectified Linear Unit,RE⁃LU),克服了sigmoid 函数在饱和区域收敛慢的问题,减少了反向传播求误差梯度的计算量,提高了训练速度。最后进入全连接层,经由softMax 函数输出3 种情感类别的概率。
配置训练模型,损失函数(loss)是编译模型必须存在的两个参数之一,本文选用解析损失函数,它是Keras 提供的一种交叉嫡代价函数,帮助神经网络从错误中快速学习,交叉嫡是非负的,因此模型正确率越高,交叉嫡的值越接近0。另一个重要参数为优化器(Optimizer),采用梯度下降算法找到偏置和权重的最优解,使代价函数最小化。选用自适应矩估计(Adaptive moment estimation,Adam)优化器,它属于随机梯度下降(SGD)算法的改进,通过随机抽取小规模训练样本进行计算,并在随机梯度下降算法的基础上增加了一阶动量和二阶动量,可以加速梯度下降并自动调整学习速率,进而减少训练时间。
训练模型,fit()函数用来按照指定的迭代次数训练模型。训练集样本数为11 200,每轮包含100 个样本用来计算一次梯度下降算法优化损失函数,到第5 轮停止训练,同时指定验证集的样本数为1 400。
最终训练结果如图5 所示。

Fig.5 TextCNN model training results图5 TextCNN 模型训练结果
5 可视化功能设计及构建
5.1 数据库结构设计
采用phpMyAdmin 作为客户端管理数据库,它支持使用PHP 语言执行SQL 各种语句以完成对政务数据的统计和可视化。
以下是关于政府政务微博数据集存储在数据库中的基本表结构:
(1)review 表(政务微博评论表)用来存储政务微博下的评论及其相关信息。具体结构如表1 所示。

Table 1 Review Form(Government Microblog review Form)表1 review 表(政务微博评论表)
(2)weibo 表(政务微博表)用来存储政务微博原文内容及标题等相关信息。具体结构如表2 所示。
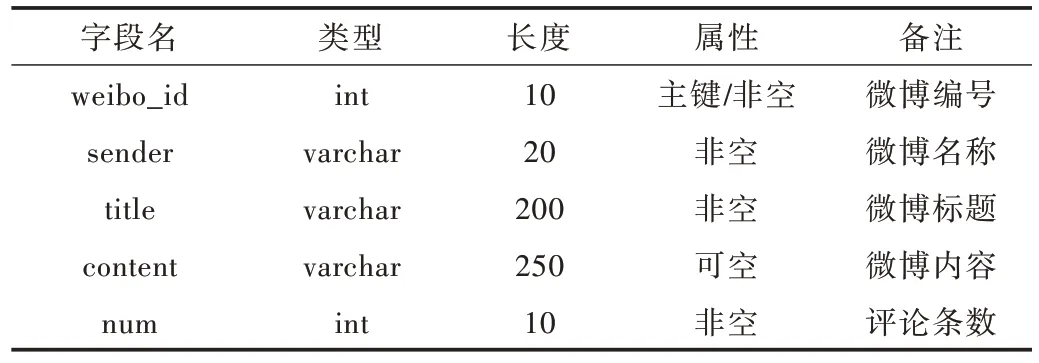
Table 2 Microblog table(Government Microblog table)表2 weibo 表(政务微博表)
(3)weibo_user 表(微博用户表)用来存储评论过政务微博的用户相关信息。具体结构如表3 所示。

Table 3 Weibo_user table(Weibo user table)表3 weibo_user 表(微博用户表)
本文还在微博用户表、政务微博评论表和政务微博表的基础上建立了两个视图user_review 和user_sentiment,它不占用实际内存空间。可以用来解决子查询中的重复调用问题,降低代码复杂度。
5.2 可视化功能设计
由于Echarts 的本质是一个Javascript 的图表库,故只要将官网下载的js 文件放入项目的工程下,利用script 标签就可以将图表组件引入HTML 页面中。绘制时,调用echarts.init()函数初始化实例对象,创建option 数组以JSON 串的形式配置参数并导入需要统计的数据,最后经由对象调用setOption()函数显示图表。
可视化主要分为3 部分:①对参与政务微博讨论的用户信息进行统计;②政务微博与用户间互动信息整理;③用户评论所体现出的情感倾向性分析。具体模块如图6所示。
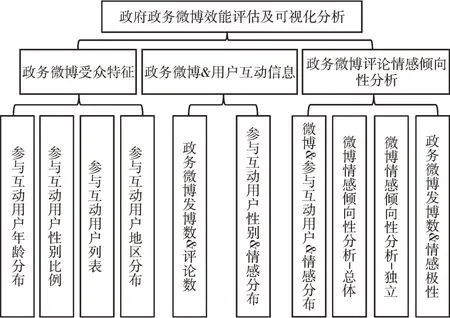
Fig.6 The overall function design图6 功能整体设计
5.3 可视化结果展示
微博用户年龄分布如图7 所示。该部分从年龄角度展示不同年龄阶段对政府政务微博的参与程度,从“0~10岁”、“10~20 岁”到“50~60 岁”、“60 岁以上”共划分7 个年龄阶段。采用雷达图对不同年龄群体的数量进行统计和显示,便于实现横向比较。其中,各年龄段都在关注政府政务信息,这体现政民互动在年龄层面上的普及性,较为明显的是,青年群体已然成为政务微博建设过程中的主力军。
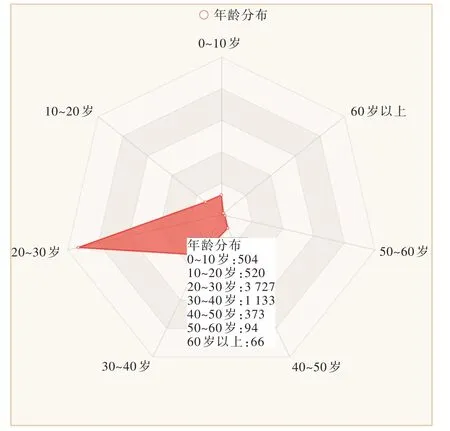
Fig.7 Age distribution of Microblog users图7 微博用户年龄分布
政务微博发博数与评论数展示如图8 所示。针对不同政务微博之间与政务微博内部两个维度,采用双柱状图的模式对微博发博数量和得到评论总数量进行统计。通过标签标记最高点和最低点,从侧面反映出发博数量和评论数量没有必然联系。政务微博是否受用户欢迎,更多与新闻本身的内容与质量有关。
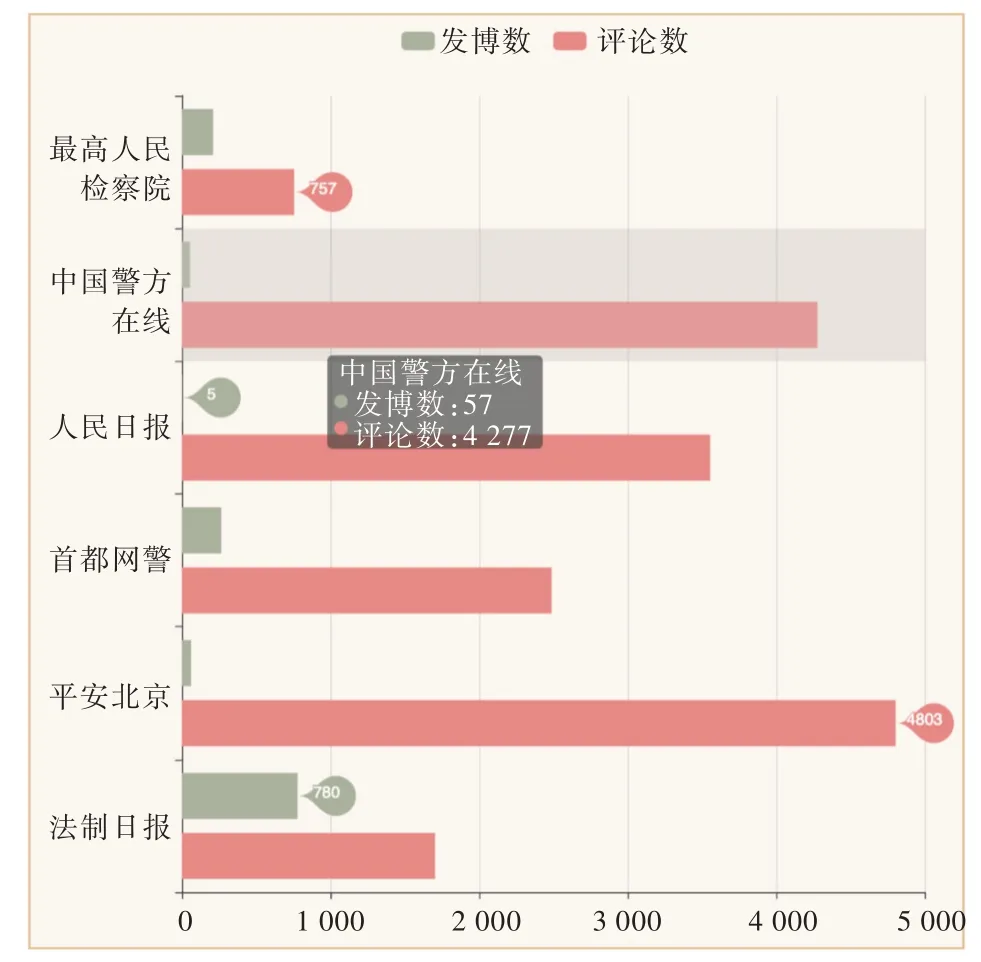
Fig.8 Number of government posts and comments on Microblog图8 政务微博发博数与评论数
情感倾向性分析展示如图9 所示。针对不同的政务媒体,统计微博原文下代表不同情感极性评论的各自数量及评论总数。可以看出,评论数量无论多少,3 种情感极性在各自政务微博总评论中所占比例大致相同,且大多数评论表现出较强烈的感情倾向,展示出人们对政务工作的高度参与。
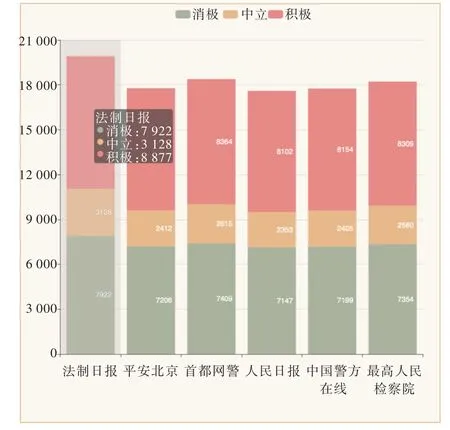
Fig.9 Sentiment orientation analysis(independent)图9 情感倾向性分析(独立)
性别与情感分布展示如图10-图12 所示。该部分以性别作为分类标准,统计参与互动的微博用户的情感部分。由于数据集中男女总数不同,故采用各自性别的评论总数作为比例公式中的分母,该性别的不同情感作为分子。如图10 所示,男性和女性在与政务微博互动时,评论内容所显示出来的中立情感占各自群体总数的比例大致相同;而如图11 和图12 所示,男性群体评论所倾向的消极情感的占比远高出女性,女性群体的评论所显示出的情感更加积极。
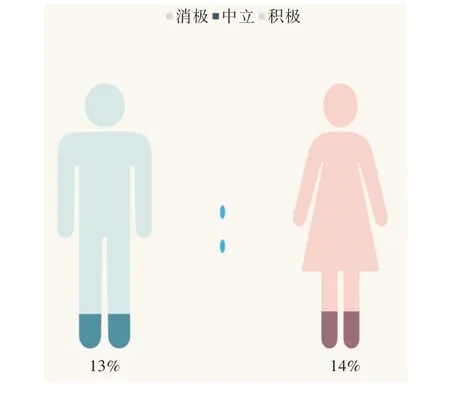
Fig.10 Gender and emotional distribution(neutral)图10 性别与情感分布(中立)
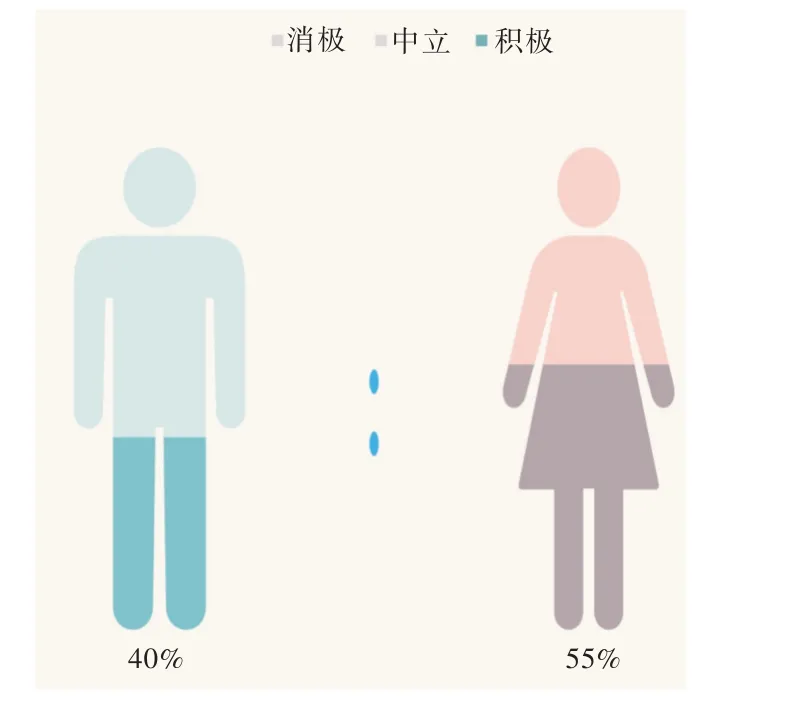
Fig.11 Gender and emotional distribution(positive)图11 性别与情感分布(积极)
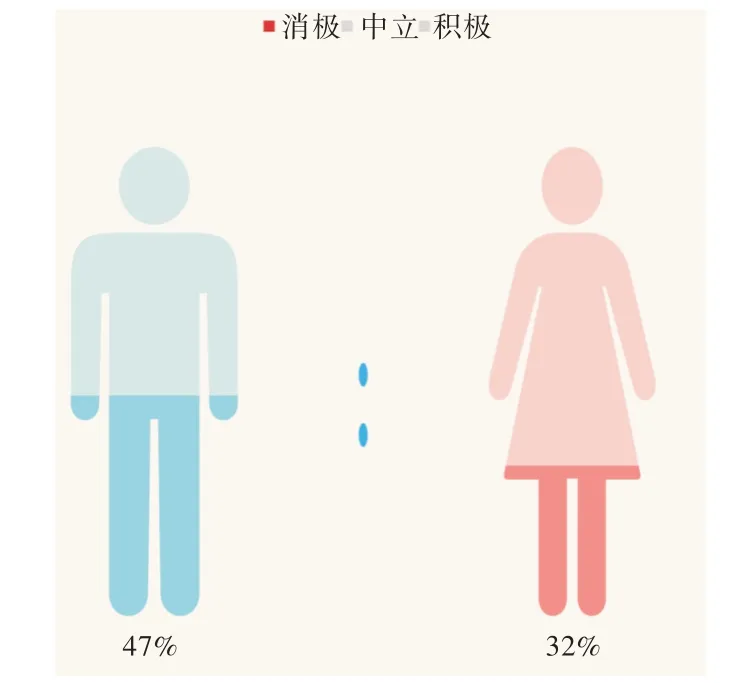
Fig.12 Gender and emotional distribution(negative)图12 性别与情感分布(消极)
6 结语
本文重点对微博评论所隐含的情感倾向性进行分类统计,采用基于深度学习情感分析方法中的TextCNN 模型对经过预处理的文本进行训练、评估和预测,对数据进行数据库导入、统计、分析和可视化。在MySQL 数据库中创建表和视图,方便实现后续对数据的查找和调用。采用Echarts 开源可视化工具将数据嵌入到柱状图、雷达图、地区分布图等图表进行展示,同时通过参数更改,实现对组件的个性化调整。
本文不足之处在于结果是静态化展示,而众所周知的是,将时间划入统计范畴的动态可视化将更具有比较性和说服力。情感倾向性分析为三分类,而显然人类的情感不可能只有三种,未来可以考虑进行更多分类研究,这更有利于细化舆情监测针对公众情感分析相关内容,使政府收集的民情民意更加精准,帮助政务部门对舆论作出及时正确的引导。同时,研究中数据集规模较小,得到的结果不足以代表全部政务微博现状,并且采用的数据集仅来源于政务微博,未来还可以对微信公众号和政务新媒体客户端和网站进行统计,使结果更具有说服力。
