基于迁移学习的NSGAⅡ算法
2021-03-25刘璐,蒋艳
刘 璐,蒋 艳
(上海理工大学管理学院,上海 200093)
0 引言
进化优化算法是一种基于模拟自然生物进化过程的算法,通过使用染色体表示问题的解,选择适合的染色体群进行复制、交叉、变异和选择,产生新的更能适合环境的染色体群[1]。此过程不断循环迭代,直到找出最适合环境的个体,得到问题的最优解。
1993 年Srinivas 等[2]设计了非支配排序遗传算法(Non-dominated Sorting Genetic Algorithm,NSGA),这是第一代多目标进化算法之一;2002 年Deb 等[3]对NSGA 算法进行改进,在此基础上提出第二代多目标进化算法NSGAⅡ算法(Non-dominated Sorting Genetic Algorithm Ⅱ,NSGAⅡ)。NSGAⅡ算法由于提高了种群的进化水平和搜索效率,成为目前最流行的多目标进化算法之一;陶文华等[4]将差分进化融入NSGAⅡ算法,差分进化算法对初始种群进行交叉和变异操作得到新种群,该算法获得的Pareto 最优解集更均匀;路艳雪等[5]通过设计正态分布交叉算子和改进的自适应变化变异算子,能够快速获取Pareto 最优解集,提高了算法的收敛速度和精确度。
传统的进化优化算法中初始种群都是随机产生的,没有考虑之前是否优化过相似问题,都是从零开始搜索解。迁移学习[6-7]是通过已有知识解决具有相关性但不同源域问题的一种新的机器学习方法。相比于传统机器学习方法,迁移学习并不要求训练样本和测试样本独立分布,也不需要大量的训练样本,适用于小数据样本量训练。迁移学习在文本处理[8]、情感分类[9]、图像数据处理[10]和推荐系统[11]等领域应用很好。目前,迁移学习在进化优化领域有了一定应用,Feng 等[12]将迁移学习运用到车辆路径问题中,提出文化基因进化框架;徐茂鑫等[13]提出新的迁移蜂群优化算法并应用到电力系统的无功优化中;Dinh 等[14]在使用遗传算法优化神经网络权重时,将源任务得到的个体解集进行保存,在处理新任务时从个体解集中迁移出个体代替初始个体;邱立明[15]在动态多目标优化的算法框架Tr-DMOEA 基础上提出基于流形的迁移动态多目标优化算法并运用到多任务优化问题研究中;杨康[16]提出基于相似历史信息迁移学习的骨干粒子群优化算法并应用到旅行商问题中。
上述研究将迁移学习融入进化优化算法,提高了算法性能,但都是对单目标和动态多目标问题的研究,并不适用于静态多目标。鉴于此,本文基于NSGAⅡ算法融入迁移学习思想,设计了基于迁移学习的NSGAⅡ算法(Tr-NS⁃GAⅡ),解决静态多目标优化问题。
1 相关工作
1.1 多目标问题
多目标优化问题[1](Multi-objective Optimization Prob⁃lem,MOP)一般由决策变量、目标函数和约束条件组成,可以写成如下形式:
式中,x=(x1,x2,x3,...xn)∈D为决策变量,y=(f1,f2,...,fm)∈Y表示目标向量,D为决策空间,Y为目标空间。
定义1(Pareto 支配)设MOP 的两个可行解为x1、x2,对应的目标F(x1)、F(x2)满足以下条件时:
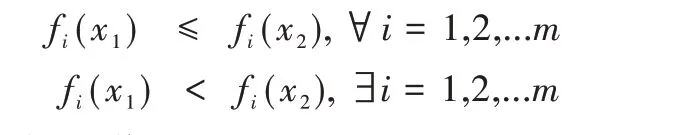
称x1支配x2,即x1≻x2。
定义2(Pareto最优解集)对于MOP 的可行解x*满足{x*|∃x,x≻x*},可行解x*称为Pareto 最优解,所有可行解组成的集合即为Pareto 最优解集(POS,Pareto Optimal Set)。
定义3(Pareto 最优前沿)对于MOP 的最优前沿POF(Pareto Optimal Front,POF),是POS 映射在目标空间上的值,POF={y*|y*=F(x*),x*∈POS} 。
1.2 NSGAⅡ算法
NSGAⅡ算法[17]相较于NSGA 算法采用了快速非支配排序,从而降低了算法的计算复杂度。同时NSGAⅡ算法提出拥挤度和拥挤度比较算子两个概念,代替原NSGA 算法需要适应度共享策略。NSGAⅡ算法还引入精英策略,扩大采样空间,将父代种群和子代种群合并,保证优良个体能够留存下来。快速非支配排序和拥挤度距离计算步骤如下:
(1)快速非支配排序。首先计算出所有个体两两之间的支配关系,得到当前群体的非支配解集,记为第一层;再从剩余的个体中找出非支配解集,记为第二层,循环到所有个体都被分层。
(2)拥挤度距离。拥挤度距离是估量一个解的空间周围解的聚集程度。对于每个目标函数,先对非支配解集中的解按照函数值大小排序,再计算周围两个解构成的立方体平均边长,结果即为拥挤度距离,另外边界的拥挤度距离设为无穷。
1.3 迁移学习
1.3.1 最大均值差异
定义4(最大均值差异)将源域和目标域的数据通过特征映射函数映射后,求两者的均值之差即为最大均值差异[18](Maximum Mean Discrepancy,MMD),其中φ表示χ→H的映射,公式如下:
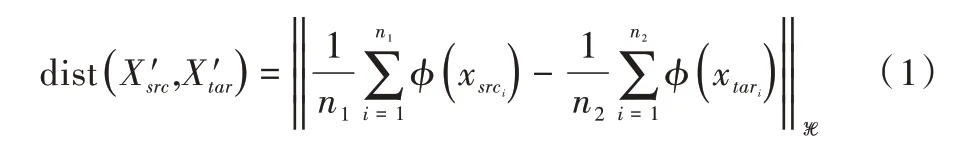
1.3.2 迁移成分分析
迁移学习按照学习方法划分为基于样本的迁移学习、基于特征的迁移学习、基于模型的迁移学习和基于关系的迁移学习4 类。本文设计的算法采取基于特征的迁移学习中的迁移成分分析。Pan 等[19]提出迁移成分分析(Transfer Component Analysis,TCA)方法。TCA[20-21]在处理领域自适应问题时,当源域和目标域边缘分布不同时,通过映射函数将两个领域的数据映射到一个高维的再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS),使得映射后的数据在映射空间中分布相似,数据距离缩小,属性相近。在TCA 算法中引入核矩阵K 和L 如下所示:
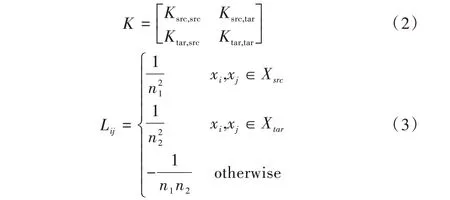
令φ(x)=WTκx,则K 可以写成:
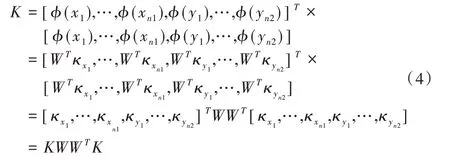
将K 带入MMD 公式,其中K 是一个对称矩阵:
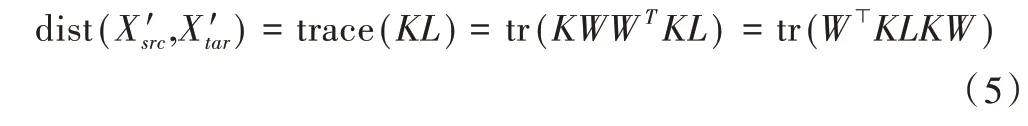
最终将TCA 优化目标化简得到公式(6),其中H是一个中心矩阵H=In1+n2-1/(n1+n2)11⊤,I是(n1+n2)维单位矩阵,μtr(W⊤W) 是惩罚项,(KLK+μI)-1KHK的前m 个特征值就是源域和目标域降维后的数据。
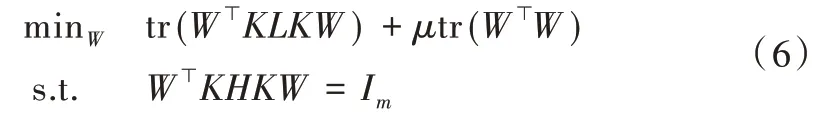
2 Tr-NSGAⅡ算法
传统的进化优化算法都是从定义域中随机产生初始种群,本文引入迁移学习思想设计Tr-NSGAⅡ算法。首先建立一个储存库,存储函数的一些历史信息,包括目标维数、决策变量维数、特殊函数(例如三角函数、幂函数等)和函数的最高次幂等特征,及函数的Pareto 最优解集,将其作为源域记为Xs,其中Pareto 最优解集内解的个数为S。当获得新任务时,提取目标函数特征,与储存库中的函数比较,找出最相似的函数;再对目标函数随机产生初始种群并进行非支配排序,得到的种群T记为目标域Xt。将Xs 和Xt 通过TCA 算法学习得到Xs_new 和Xt_new。针对Xs_new 中每个个体s计算Xt_new 中个体t与其欧几里得距离,得到L(l1,l2,...,ls),li为一个s与Xt_new 中所有t的欧几里得距离,并对每个li进行内部排序,取第一个数li1构成M;在M中返回Xt_new 中个体序号,找出Xt 中对应个体形成新的种群。如果M中元素个数过少,为了保证种群的多样性,源域和目标域的定义域不一定相同,以避免局部收敛,按照一定比例r选取li,r的取值范围为[10%,20%]。Tr-NSGAⅡ算法流程如下:
输入:多目标优化问题F(x),个体数N,进化代数,核函数,储存库;
输出:问题的最优解,储存库;
(1)建立储存库,提取目标函数的特征,与储存库中的函数比较,找出最相似的原函数,并记其Pareto 最优解集为Xs,Xs 为源域。
(2)对于目标函数F(x)随机产生初始种群N,对种群进行非支配排序,并进行选择、交叉和变异得到种群Q,记为Xt,Xt 为目标域。
(3)通过TCA 算法学习,选择合适核函数将源域(Xs)和目标域(Xt)映射到高维希尔伯特空间,得到映射后的源域(Xs_new)和目标域(Xt_new)。
(4)设置初始种群P 为空集。
(5)对于Xs_new 中的每个个体,计算Xt_new 中的个体与其欧几里得距离,找出最小值,返回Xt_new 中个体序号,并在Xt 中找出对应个体并入种群P。
(6)当P 小于N 时,随机产生N-P 个个体,并入P。
(7)令进化代数为零,利用NSGAⅡ算法对种群P 进行快速非支配排序、拥挤度距离排序和精英选择策略进行更新。
(8)得到目标函数最优解,将目标函数放入储存库,更新储存库。
3 Tr-NSGAⅡ算法实验
3.1 实验环境及测试函数
本实验采用Python3.7 实现所提出的算法,测试环境为Intel(R)Core(TM)、1.30GHzCPU、16GBRAM。储存库里的函数为ZDT1~4、ZDT6 系列、BNH 和Belegundu,目标函数共有10 个[1],具体形式见表1。
3.2 实验方法
本文选用4 种不同的评价指标,从解的收敛性、解集的均匀性和算法的综合性能来评价解的有效性。
(1)收敛性。GD 表示算法所获得的非支配解集P 与问题真实的Pareto 前沿P*之间的平均最小距离,GD 越小表示算法的收敛性越好,计算公式如下:
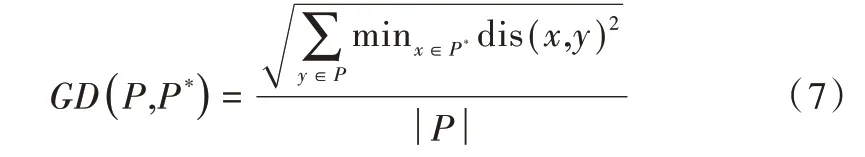
(2)均匀性。Spacing 表示每个解到其它解的最小距离标准差,Spacing 越小表示解集越均匀,计算公式如下:
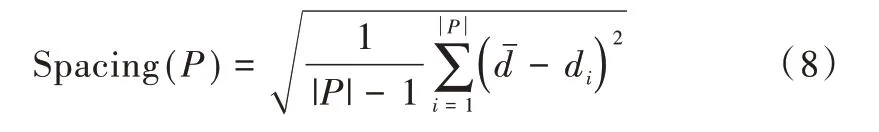
(3)算法综合性能。IGD 表示算法所获得的非支配解集与问题真实的Pareto 前沿P*距离的平均值。IGD 越小表示算法的综合性能越好,即算法的收敛性和解集多样性越好,计算公式如下:
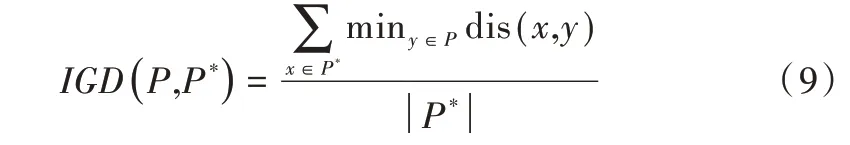
3.3 实验结果分析
将两种算法分别运行30 次,找出其中最优解。对于收敛性指标GD,有80% 的函数下降,其中两个函数变化率在5% 以下,一个函数变化率在5%~50% 之间,5 个函数变化率增加了50% 以上。函数TNK 最多改善99.97%,说明Tr-NSGAⅡ算法相对于NSGAⅡ算法收敛性能得到很好优化。对于解集均匀性指标Spacing,有60% 函数下降,其中一个函数变化率在5% 以下,3 个函数变化率在5%~50%之间,两个函数在50% 以上,函数TNK 收敛性能优化率达到100%,说明Tr-NSGAⅡ算法所得到的解集分布较为均匀。对于算法综合性能指标IGD,80% 的函数综合性能得到改善。函数Con 和函数4 变化率在5% 以下,有3 个函数变化率在5%~50%,3 个函数变化率在50%~100% 之间,其中修改后的ZDT1 函数和修改后的ZDT6 函数综合性能都得到很好改善,变化率在95% 以上,表明Tr-NSGAⅡ算法收敛性和解集的多样性较NSGAⅡ提高很多,即Tr-NS⁃GAⅡ算法的综合性能更好。综上,引入历史信息的Tr-NSGAⅡ算法在种群的搜索效果明显好于NSGAⅡ算法,解集的均匀性和多样性得到提高。测试函数实验结果如表2所示,Tr-NSGAⅡ和NSGAⅡ之间不同指标变化率实验结果如表3 所示。

Table 1 Objective functions表1 目标函数
4 结语
本文设计了基于迁移学习思想的Tr-NSGAⅡ算法,在存有历史信息的储存库中找出相似的历史问题得到源域,通过TCA 算法将源域和目标域映射到高维再生核希尔伯特空间,即将历史信息迁移到新的目标函数中,得到含有历史信息的种群,再利用NSGAⅡ算法继续求解目标函数。对10 个改进的多目标测试函数进行试验,结果证明Tr-NSGAⅡ算法有效提高了种群的搜索效率,算法的收敛性能得到改善,优化了解集的均匀性和多样性,表明迁移学习可以融入进化优化算法解决静态多目标问题。但是本文所用的历史任务和新任务之间属性类似,实验数据集来源于标准的多目标函数测试集,当面对实际问题(如选址问题、背包问题和车间调度问题)时,历史任务和新任务之间匹配策略应该如何设计还需进一步研究。
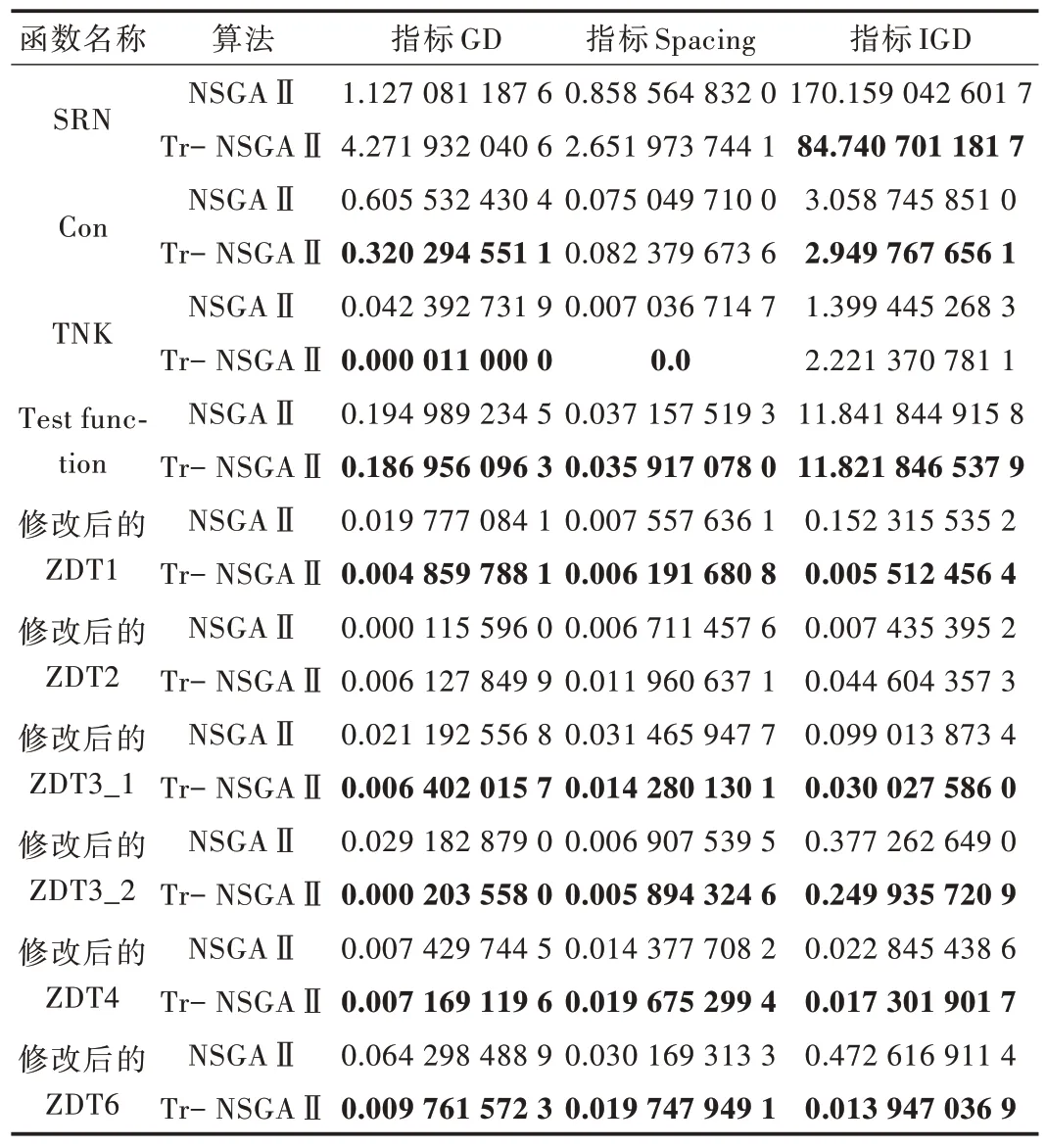
Table 2 Experimental results of algorithm optimization test function表2 比较算法优化测试函数实验结果
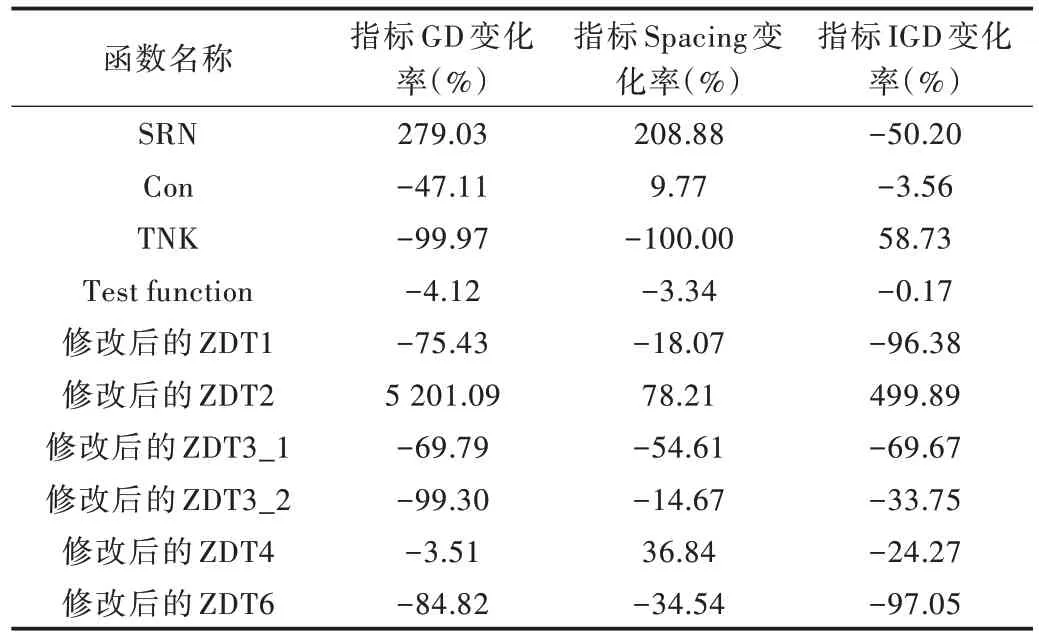
Table 3 Experimental results of different index change rates between Tr-NSGA Ⅱand NSGA Ⅱ表3 Tr-NSGAⅡ和NSGAⅡ之间不同指标变化率实验结果
