基于cw2vec 与CNN-BiLSTM 注意力模型的中文微博情感分类
2021-03-25卢昱波刘德润蔡奕超杨庆雨刘太安
卢昱波,刘德润,蔡奕超,杨庆雨,陈 伟,刘太安,
(1.山东科技大学计算机科学与工程学院,山东青岛 266590;2.山东农业大学信息科学与工程学院,山东泰安 271018;3.山东科技大学智能装备学院,山东泰安 271019)
0 引言
据中国互联网络信息中心(CNNIC)发布的第45 次《中国互联网络发展状况统计报告》[1],截至2020 年3 月,我国网民规模为9.04 亿,手机网民所占比例高达99.3%,互联网普及率达到64.5%。移动终端和互联网的大规模普及已经改变了人们收集信息、表达观点的方式,越来越多的公众更倾向于通过网络发表意见、抒发情感。互联网上产生大量网民的认知、态度、情感和行为倾向,这些信息集合为网络舆情[2]。目前以新浪微博为代表的中文微博取得空前发展。根据新浪微博2020 年第一季度财务报告[3],2020年Q1 的月活跃用户为5.5 亿,移动端月活跃用户突破5亿,日活跃用户2.41 亿。面对数据的爆炸性增长以及微博用户较高的自由度进行中文微博的情感分类,不仅可对内容监控,而且也是突发事件预警及舆情分析的基础,不但能帮助决策者更快地了解大众意见,还能为企业进行市场分析、调查、反馈提供更多有参考性的信息。因此,中文微博信息处理技术具有重要的理论与应用价值。
情感分类研究可分为基于情感词典的情感分类方法、基于传统机器学习的情感分类方法和基于深度学习的情感分类方法。基于情感词典的方法根据现有的情感词典和计算规则获得情感类型。国外对情感词典的研究较早,其中应用最广的英文词典是SentiWordNet[4];在中文情感分类中,使用最广泛的是知网HowNet 情感词典[5]。传统的基于机器学习的情感分类方法解决基于情感词典方法中存在的问题,该方法将文本转换为结构化数据,然后构造基于机器学习的分类器,最后确定文档情感类型。Pang等[6]首次将机器学习引入情感分类中,通过实验对比各类算法在电影评论情感分类中的表现,发现支持向量机的分类性能最优;García 等[7]在影评数据集上训练朴素贝叶斯模型,提高了情绪分析的准确率;为克服传统机器学习方法在时间序列上信息表达不足的缺点,基于深度学习的情感分类将深度学习模型引入自然语言处理领域,取得了很好效果;基于卷积神经网络理论,Yang 等[8]改进Kim 提出的模型,对Twitter 的推文进行分类研究,验证了卷积神经网络对Twitter 信息情感分类的优越性能;Hassan 等[9]提出基于CNN 和LSTM 的网络结构ConvLstm,利用LSTM 代替CNN 中的池化层,减少局部细节信息的丢失,在句子序列中捕获长期依赖关系,表现出较好的分类效果;Wang 等[10]提出连接CNN 层的输出作为RNN 输入,将得到的句子特征表达输入至Softmax 分类器,取得较好的分类效果。
从上述研究可知,目前理论不仅对中文的情感词训练缺乏关注,而且单一的深度学习模型也无法对局部特征和上下文信息同时提取。因此,本文提出基于中文笔画的cw2vec 模型对中文词进行训练,使用CNN-BiLSTM 注意力的混合深度学习模型对中文文本进行情感分类。在相同的数据集上对比不同的单一深度学习模型,验证本文方法的有效性。
1 cw2vec 模型
在自然语言处理领域,词向量的训练有重要作用,广泛应用于词性分类、命名实体识别、机器翻译等领域[11]。现存的方法主要是词级别的基于上下文信息表征学习,如2013 年Mikolov 等[12]提出两种神经网络语言模型—连续词袋模型CBOW(Continuous Bag of Words)和Skip-gram 模型,从大量的新闻单词中训练出词向量Word2vec,但是大量的词向量模型都是基于英语进行训练的。汉字作为中华民族的几千年文化,具有集形象、声音和词义三者于一体特性,内部包含了较强的语义信息。由于中英语言完全不同,单个英文字符是不具备语义的,因此Cao 等[13]通过使用笔画n-gram 词向量捕获中文词的语义和形态信息。将中文笔画划分为5 类,将笔画特征也使用相同向量表示,每个词语使用n-gram 窗口滑动的方法将其表示为多个笔画序列,每个gram 和词语都被表示成向量,用来训练和计算它们之间的相似度,如表1 所示。

Table 1 The relationship between stroke names and numbers表1 笔画名称与数字对应关系
词语向量化过程如图1 所示。将中文词语分割为单个字符,按照笔画顺序抽取汉字笔画特征得到整个词语的全部笔画信息,使用编号代替笔画特征完成数字化,最后用大小为n 的窗口生成n-gram 笔画特征。

Fig.1 The process of extracting n-gram stroke features from Chinese characters图1 汉字抽取n-gram 笔画特征过程
在cw2vec 模型中,定义相似函数sim(w,c)单词与其上下文之间公式如式(1)所示。

其中,w和c分别是当前位置的词和上下文单词,S(w)为当前词语w所对应的n 元笔画集合,q→为当前词语q对应的n 元笔画向量,为上下文词语的词向量。目标函数计算公式如式(2)所示。
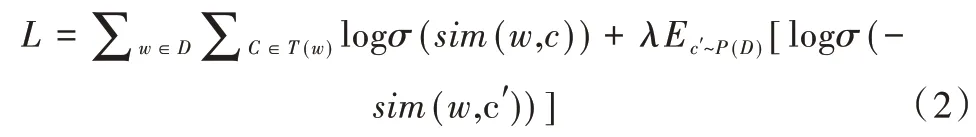
其中,w为当前词语,D为训练语料,T(w)是当前词语划窗内所有词语集合,σ是sigmoid 函数。c′为随机选取的词语,称为“负样例”,λ是负样例个数,Ec'~P(D)是期望,表示c′根据词频分布进行采样,即语料库中出现频率更高的单词可能被采样的概率更高。
2 CNN-BiLSTM 注意力模型
通过cw2vec 模型预先训练好词向量,将其作为分类模型输入。先使用CNN 进行局部特征提取,然后利用BiL⁃STM 进行上下文全局特征提取,最后通过注意力模型进行加权并采用Softmax 分类得到情感极性。模型结构如图2所示。
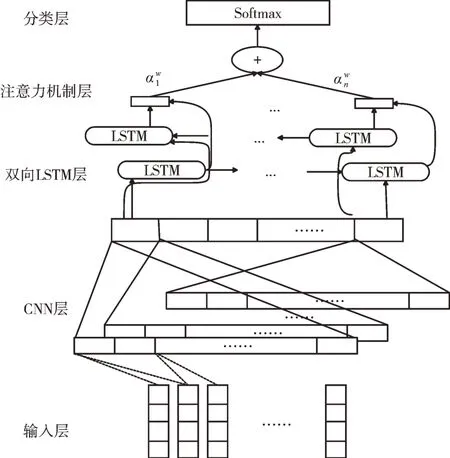
Fig.2 Network structure of CNN-BiLSTM attention model图2 CNN-BiLSTM 注意力模型的网络结构
2.1 CNN
CNN 是一种具有卷积结构的前馈神经网络模型,本质上为多层感知机[14]。卷积结构能够减少内存量占用,其中局部链接和权值共享操作是其广泛应用的关键[15]。CNN具有多层网络结构,卷积层、池化层和全连接层是卷积神经网络的基本组成部分。
卷积层主要通过卷积操作感知文本的局部信息,不同尺寸的卷积核能够提取不同的特征,卷积计算公式如式(3)所示。
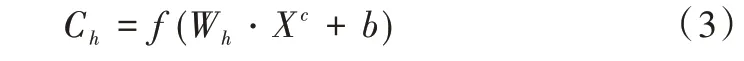
其中,Ch为不同高度过滤窗口提取到的特征,Wh为对应的权重矩阵,XC为特征矩阵,b为偏置,f为激活函数。在训练过程中,使用Rule函数作为激活函数以提高模型的收敛速度。在对长度为n的句子进行卷积操作后生成特征图Ch,如式(4)所示。
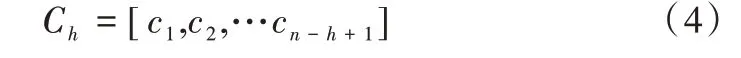
池化的主要作用是在保留局部最优特征的同时减少参数实现降维,防止过拟合。在情感分类中,一般采取最大池化策略,即只保留最大特征丢弃弱特征,如式(5)所示。
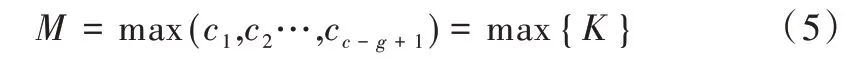
由于BiLSTM 输入必须是序列化结构,池化将中断序列结构K,所以需要添加全连接层,将池化后的K向量连接成向量J,如式(6)所示。

2.2 BiLSTM 模型
长短时记忆(Long short-term memory,LSTM)是一种特殊的RNN,主要解决长序列训练过程中的梯度消失和梯度爆炸问题[16]。对于中文文本,复杂的语法和句法结构使文本的上下文都有一定的联系,因此该层搭建了双向LSTM对文本语义进行编码,分别学习上文和下文,其内部结构如图3 所示。
图3 中,xt为t 时刻输入,ht为t 时刻输出,ct为t 时刻细胞状态。LSTM 主要通过ft、it、Ot三个门结构有选择性地实现信息流动。
ft表示遗忘门,用来控制ct-1中的信息遗忘程度,计算公式如式(7)所示。
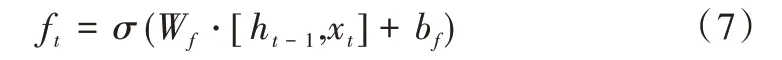
其中,σ为Sigmoid函数,Wf为遗忘门权重,bf为遗忘门偏置。

Fig.3 Internal structure of LSTM图3 LSTM 内部结构
it代表输入门,负责控制信息的更新程度,计算公式如式(8)所示。利用tanh函数得到候选细胞信息,计算公式如式(9)所示。依赖于遗忘门和输入门,更新旧的细胞信息ct-1得到新的细胞信息ct,更新公式如式(10)所示。
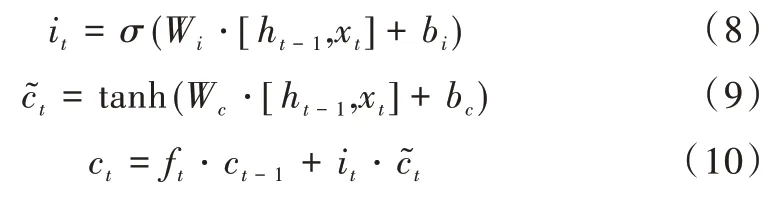
其中,Wi表示输入门权重,bi表示输入门偏置,Wc表示候选细胞信息权重,bc表示候选细胞信息偏置。
Ot代表输出门,用以控制信息输出,计算公式如式(11)所示。最终t时刻的隐层输出ht计算公式如式(12)所示。

其中,Wo为输出门权重,bo为输出门偏置。
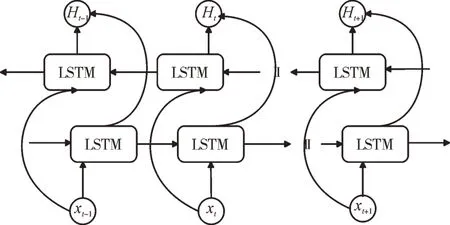
Fig.4 Bidirectional LSTM model structure图4 双向LSTM 模型结构
但是LSTM 模型只能学习到当前文本的上文信息,忽略了当前词语与下文的联系,因此通过构建双向LSTM 充分学习上下文语义信息,如图4 所示。为t 时刻正向LSTM 的输出向量为t 时刻反向LSTM 的输出向量,t 时刻双向LSTM 的输出Ht由连接而成,如式(13)所示。

2.3 注意力模型
注意力机制(Attention mechanism)的思想源于人类视觉系统中的“注意力”,最早应用于视觉图像领域[17],可通过注意力概率分布的计算得出部分特征对整体的重要程度[18]。由于每个词对于句子整体情感表达的重要程度不同,为了突出关键词对情感表达的贡献度,在双向LSTM 模块后引入注意力机制。通过对双向LSTM 层提取到的序列信息进行加权变换,以生成具有注意力概率分布的向量,突出文本中重要特征对情感类别的影响程度,使情感分类准确率得到提升。计算公式如式(14)、(15)、(16)所示。
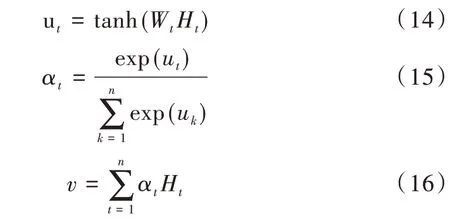
其中,ut表示Ht通过tanh层得到的隐层,Ht表示t 时刻双向LSTM 输出的特征向量,αt表示通过Softmax 函数得到的注意力权重,v表示加权后得到的特征向量。
用Softmax 层计算出所有可能标签的概率,如式(17)所示。将公式进行变换得到多次迭代后的网络参数,获得得分最高的序列作为预测标记的正确序列。
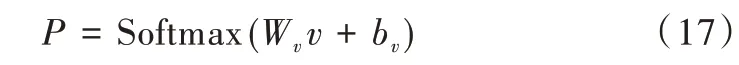
式中,Wv表示权重矩阵,bv表示偏置。
为使模型的分类误差最小化,使用交叉熵作为损失函数并加入正则项防止过拟合,计算公式如式(18)所示。
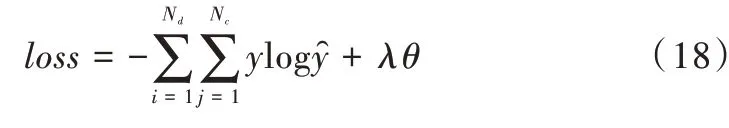
式中,Nd表示训练集的大小,Nc表示情感类别的数量,y为文本中情感的类别,为模型预测的文本情感类别,λ表示L2 正则化,θ表示模型参数的集合。
3 实验结果与分析
3.1 实验数据
数据集来自GitHub 网站公开的标注微博评论,正面情感标注为1,负面情感标注为0,包含正向情感5 万条,负向情感5 万条共计10 万条。实验分别从正向和负向情感数据集中选取前3 万条作为训练集,其余数据作为测试集。
3.2 数据处理
(1)文本预处理。由于微博的表达形式多样化,所以部分微博文本会带有特殊符号,去除URL 地址、表情符号、用户提及符号、转发符号和主题符号等数据中的特殊符号不会影响微博文本的情感分析。本文使用正则表达式对其进行清理。
(2)文本切分。在中文中,词与词之间没有明显的分隔符,因此需要先对文本进行分割,然后才能继续分词。有很多常见的中文分词工具如jieba、NLPIR、pyltp 等。通过比较不同的分词能力,本文选择使用jieba 分词工具。
(3)去停用词。解析微博文本时会有很多没有实际意义的高频词,如介词、代词和连词等。这些词只是通过前后词的连接使句子更加流畅,如“的”“了”“啊”等,在占用大量存储空间的同时会降低数据处理效率,因此需要删除。常用的有哈工大停用词表和百度停用词表。为了使停用词覆盖面更加全面,对上述两个停用词列表进行集成和删除,获得一个新的停用词列表来过滤停用词,以提高处理效率。
3.3 实验环境与评价指标
(1)实验环境。本文实验环境与参数如表2 所示。
(2)评价指标。情感分类作为文本分类的一种,常见的评估指标有准确率(accuracy)、精确率(Precision)、召回率(Recall)和F1 值,计算公式如式(19)-(22)所示。

其中,T 是预测正确的数量,N 是全部数量。TP 是正向类预测为正向的数量,FP 是负向类预测为正向的数量,FN 是正向类预测为负向的数量。

Table 2 Laboratory environment configuration表2 实验环境配置
3.4 实验结果分析
在Tensorflow 深度学习框架下搭建CNN-BiLSTM 模型,为优化模型性能进行大量的调参实验,最后设置本文的超参数如表3 所示。

Table 3 Parameter setting of emotion classification model表3 情感分类模型参数设置
(1)词向量模型对比实验。为验证基于中文笔画的cw2vec 模型在中文微博分类的有效性,均采用相同的中文微博文本数据集进行实验,选取目前使用最多的word2vec中CBOW 模型和Skip-gram 模型作为参照实验。分类模型采用本文提出的CNN+BiLSTM+注意力混合深度学习模型,评价指标采用准确率,实验结果如图5 所示,准确率如式(19)所示。
实验结果表明,基于中文笔画的cw2vec 模型比基于英文字母的CBOW 模型和Skip-gram 模型分别提升2.35%和1.19%,cw2vec 模型可以更好地利用汉字结构和笔画信息有效捕捉汉字特征,准确率更高,鲁棒性更好。
(2)分类模型对比实验。为验证混合深度学习模型有效性,全部采用cw2vec 模型训练好的中文微博数据集作为输入,设置SVM、CNN、LSTM 和BiLSTM 模型进行对比实验,实验结果如图6 所示,评价指标如式(20)-(22)所示。
通过图6 可知,SVM 模型作为机器学习中比较典型的分类模型,实验结果较差;CNN 模型只对局部特征进行提取,学习词语间长距离依赖的能力较差,最后的分类效果不理想;对比LSTM 模型与BiLSTM 模型,由于权值共享,会造成文本处理过程中的相对公平,但关注上下文的双向LSTM 比只关注上文的LSTM 分类效果有所提升;CNN+BiLSTM+注意力模型、混合深度学习模型通过增加CNN 和注意力机制可以更好地提取局部关键特征,与BiLSTM 单一的深度学习模型相比,混合深度学习模型的精确率、召回率和F1 值分别提升1.88%、3.56% 和2.72%,证明混合深度学习模型结合cw2vec 模型在情感分类上更有效。
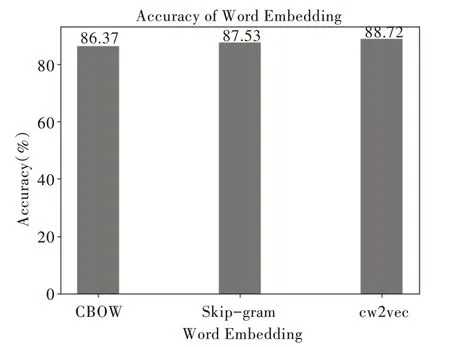
Fig.5 Comparison of segmentation model results图5 分词模型结果对比
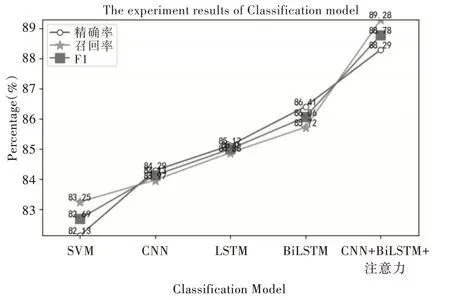
Fig.6 Experimental results of classification model图6 分类模型实验结果
4 结语
本文提出基于中文笔画的cw2vec 和CNN-BiLSTM 注意力模型相结合的混合深度学习中文微博文本情感分类方法,通过cw2vec 模型将中文文本表示为词向量作为CNN 的输入层,并使用CNN 提取局部特征,利用BiLSTM模型提取中文文本的上下文特征并增加注意力模型获取重要特征,加权后使用Softmax 函数进行分类。使用公开标注的中文微博数据集,先通过与CBOW 模型和Skipgram 模型进行对比,证明基于中文笔画的cw2vec 模型的有效性,然后在cw2vec 模型基础上与SVM、CNN、LSTM 和BiLSTM 经典模型进行对比,证明本文提出的cw2vec 和CNN-BiLSTM 注意力模型结合的方法有效。由于本文重点研究中文微博信息,没有考虑英文文本,未来可考虑在中英文文本混合分类中加入中文微博表情方法进行情感分类研究。
