基于文本特征和语言知识的神经网络情感分类
2021-03-08杨善良
杨善良
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
文本情感倾向性分类在网络舆情、危机公关、品牌营销等领域有着广泛应用。网络媒体上积累了大量的用户评论数据,这些数据集中反映了网民对社会热点事件、政策实施和产品服务的情感、态度和倾向。由于网络评论数据分析具有很强的实用价值,在业界和学术界得到了深入的研究。Ye等[1]研究旅游博客数据中的情感倾向性分类问题,帮助旅游者选择喜欢的旅游目的地。Bollen等[2]通过判断Twitter文本的情感倾向来预测道琼斯工业指数的涨跌。
情感倾向性分类把评论数据分成正面、负面和中性等类别,已成为自然语言处理领域重点研究内容之一。在网络环境下,文本表达具有不规范的特点,常使用缩略词、网络新词,具有拼写错误、语法错误等问题,给情感倾向性分类带来了很大挑战。解决情感倾向性分类问题的方法主要包括基于词典的方法、传统机器学习方法和深度学习方法等。
为提高网络文本情感倾向性分类的准确率,研究语言知识和情感知识在模型中发挥的作用,本文提出基于文本特征和语言知识融合的卷积神经网络MI-CNN(multi-features integrated convolutional neural network)模型,把词语、词性、情感词典等外部知识融合到情感倾向性分类模型。首先使用词向量训练模型训练词向量,加入词性和情感词语产生多种特征数据,用于消除词语歧义和表达情感信息;然后构建卷积神经网络模型,通过特征层融合和分类层融合的方法将多种特征融合到模型中;最后训练神经网络模型,评估模型情感倾向性分类效果。
1 相关研究
神经网络模型在图像处理、语音识别和文本分析等领域得到了广泛应用,取得了比传统机器学习方法更好的效果。LeCun等[3]提出经典的卷积神经网络模型LeNet5,并应用于图像分类。在文本情感倾向性分类上,神经网络模型也取得了非常好的效果。Kim[4]最早使用卷积神经网络对句子进行分类,将深度学习引入文本分类领域。Huang等[5]使用LSTM循环神经网络表达句子向量,然后再根据句子向量表达篇章向量,进行篇章级情感分类。由于神经网络结构在很大程度上决定了模型的效果,学者对神经网络结构进行了更深入的研究。例如Zhang等[6]通过融合CNN、LSTM、Attention等多种模型的优势来解决单个神经网络模型的缺陷,提出CCLA情感分类神经网络模型。刘敬学等[7]针对短文本分类的特点,结合卷积神经网络CNN和长短记忆网络LSTM,提出一种字符级神经网络模型。
在神经网络模型中使用词向量表示文本信息,词向量表示能力是影响模型效果的重要因素。2013年由Google发布的词向量训练工具Word2vec实现了CBOW和Skip-Gram两个词嵌入模型[8-9],成为在自然语言处理领域使用深度学习模型的基础。根据情感倾向性分类表达情感信息的需求,研究者对词向量训练模型进行了改进。例如Tang等[10]使用情感词嵌入模型SSWE训练词向量,以提高情感倾向性分类模型效果。Xiong等[11]使用情感词典和远距离监督信息训练包含情感信息的词向量。何鸿业等[12]使用词语和词性拼接,然后训练Word-Pos向量,消除词语歧义,提高词向量文本表示能力。
文本情感特征表示和使用对情感倾向性分类效果起到重要作用,学者研究了多种情感特征及其组合方法。梁斌等[13]针对特定目标情感分析任务,提出多注意力卷积神经网络模型,模型中使用词语、词性和词位置等3种注意力特征矩阵。陈珂等[14]针对中文微博情感分析任务,提出多通道卷积神经网络模型,融合词语、词性、词位置等多种情感信息特征。杜慧等[15]在对象级情感分类中使用词性信息和对象注意力机制,提出融合词性和注意力机制的卷积神经网络模型。
文本情感倾向性分类是自然语言处理领域的重要任务之一,神经网络模型在情感分类问题上取得了成功,但是关于文本特征表示、语言知识表示、情感知识表示以及多特征融合等问题的研究仍不充分。本文在词向量表示的基础上,增加词性信息和情感词语信息等外部知识;然后改进卷积神经网络模型结构,在特征层和分类层融合多种特征,以提高情感倾向性分类效果。使用词嵌入模型训练词语向量WV(word vector),词语向量能够表示词语的上下文信息和语义信息;使用词语和词性拼接后训练词语词性向量PoSV(part of speech vector),使用不同向量表示同一词语的不同词性,避免了部分词语歧义问题;使用情感词语和文本情感标签训练情感词向量SWV(sentiment word vector),SWV能够表达词语的情感信息。将多种特征融入到神经网络模型中,以提高卷积神经网络情感分类模型的效果。
2 文本特征表示
词向量是神经网络语言模型中重要的文本特征表示形式,通过词向量训练模型得到词向量表示。本文在词语特征的基础上,增加词性特征和情感特征。使用神经网络语言模型训练词语、词性和情感词3种特征向量,使用词嵌入模型训练语料数据得到词语向量WV,在词性信息的基础上训练得到词性向量PoSV,在情感词典和情感标签等外部知识的基础上训练得到情感词向量SWV。
2.1 词语特征
神经网络语言模型在词语信息表示上发挥着重要作用。词语是组成句子的基本单元,反映了评论文本的基本信息,是最重要的文本特征;词语特征向量表达了词语的语义信息,本文采用连续词袋模型CBOW(continue bag of word)[10]训练语料得到。CBOW模型根据当前词语的上下文预测当前词语,模型结构如图1所示,包括输入层、投影层和输出层三层结构。假设当前词语表示为向量wi∈Rm,m是向量维度,输入层是当前词语的上下文,选取上下文窗口大小为c,上下文词语序列表示为context(wi) = [wi-c,wi-c+1,…,wi+c-1,wi+c];投影层是输入层上下文词向量的累加和或求平均,这里使用累加操作,累加计算如式(1)所示;输出层使用Hierarchical softmax计算当前词语出现的概率p(wi|context(wi))。使用对数似然函数作为CBOW模型的目标函数,如式(2)所示,其中W是训练样本中包含的所有词语。在CBOW模型上训练语料数据,得到包含语义信息和上下文信息的词语特征向量。
wsum=∑wj∈context(wi)wj,
(1)
L=∑wi∈Wlbp(wi|context(wi))。
(2)
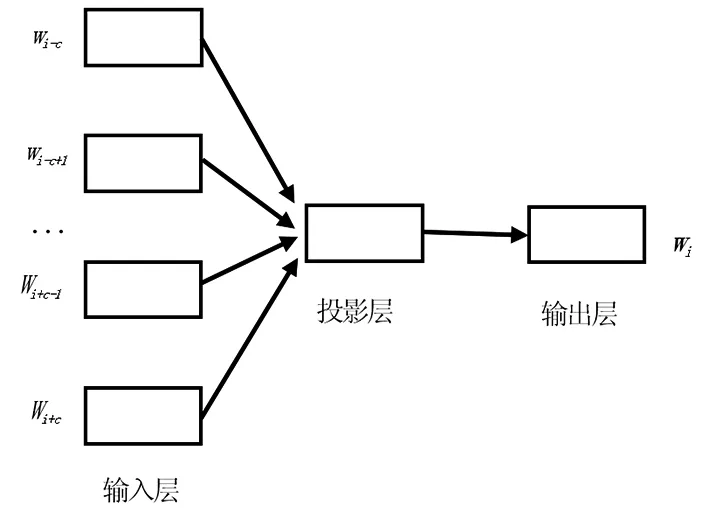
图1 CBOW模型结构Fig.1 Model structure diagram of CBOW
2.2 词性特征
词性是词语在文本中表现出来的重要语言知识,词性特征向量在词语特征向量的基础上加入词性信息,用于解决词语表现出不同词性时出现的歧义问题。使用CBOW模型训练得到的词向量,一个词语使用一个词向量表示。但是词语经常存在一词多义的现象,也就是同一个词语在不同的语境下表达的语义不同,这种情况下就会出现歧义。例如“员工的新制服非常漂亮。”和“警察制服了歹徒。”,这两句话里面都有“制服”一词,但是其表达的词义完全不同。使用词性可以区分一词多义现象,第一个句子中的“制服”是名词,表示统一制式的衣服;第二个句子中的“制服”是动词,表示用武力驯服。
本文使用词性缓解词语歧义问题,将词语与词性拼接后形成“词语_词性”字符串。然后使用CBOW模型训练词向量,将词性信息编码到向量中,同一个词语的不同词性使用不同向量表示。例如上述示例中的词语“制服”,词性特征向量w11表示“制服_动词”,w12表示“制服_名词”。当同一个词语在语境中的词性不同时,w11和w12能有效解决词语歧义问题。
2.3 情感特征
情感特征在情感倾向性分类中是重要的信息,文本表达的情感倾向多由其中包含的情感词语决定,但是在词向量训练模型CBOW中没有考虑情感信息。本文设计能够学习词语情感信息的特征向量训练模型,即情感特征向量模型。使用情感词典和情感标签作为情感特征向量模型的监督信息,然后使用模型预测每个词语的情感倾向性,以及预测词语所在上下文的情感标签,最后通过联合训练优化模型参数,得到包含情感信息的情感特征向量。情感特征向量训练模型结构如图2所示,包含输入层、全连接层、tanh层和输出层四层结构。输入层是当前词语的上下文,选择上下文窗口大小为k,上下文词语序列表示为w= [wi-k,wi-k+1,…,wi+k-1,wi+k];全连接层对上下文词向量做线性变换,如式(4)所示;tanh层使用双曲函数对全连接层做非线性变换,如式(5)所示;输出层使用softmax函数计算当前词语在情感倾向性类别上的概率分布,计算方法如式(6)所示。公式中Wl1、Wl2、bl1、bl2是网络模型参数。使用情感词典和语料训练模型得到情感特征向量。
input=embedding(w),
(3)
outputl1=input·Wl1+bl1,
(4)
outputtanh=tanh (outputl1),
(5)
y=softmax(outputtanh·Wl2+bl2)。
(6)

图2 情感词向量训练模型结构Fig.2 The diagram of sentiment word embedding training model
3 卷积神经网络模型
卷积神经网络CNN被广泛应用于图像处理、语音识别、文本分析等领域,在情感倾向性分类任务上也取得了非常好的效果。为了充分利用文本数据中的情感信息,提高情感倾向性分类准确率,本文提出基于多特征融合的卷积神经网络模型MI-CNN。模型使用词语特征向量、词性特征向量和情感词特征向量作为特征数据,然后使用卷积神经网络处理特征数据,最后预测文本的情感倾向性类别。
3.1 卷积神经网络结构
卷积神经网络结构由Hubel和Wiesel于1962年提出,经过多年的发展演变,目前已经是深度学习领域重要的网络结构。在自然语言处理领域所使用的卷积神经网络结构如图3所示,由输入层、卷积层、池化层、全连接层和输出层等组成。输入层将词语映射成词向量输入到神经网络模型中,词向量通过预训练模型得到。这里输入层的数据为x(x1,x2,...,xn),其中xi∈Rk表示语句中第i个词语的词向量,向量维度为k。卷积层使用卷积核对输入数据进行操作,卷积核权重矩阵W∈Rh,k,其中h为卷积窗口处理词语的数量,卷积操作的计算方法如式(7)所示,其中f为激活函数,xi:i+h-1表示从第i到第i+h-1个词语,b表示偏执量。经过单个卷积核操作后得到特征向量c(c1,c2,...,cn-h+1),c的维度为n-h+1。
ci=f(w·xi:i+h-1+b)。
(7)

c′=max(c)。
(8)
全连接层将特征向量映射到向量z(zj)上,并输入分类器进行分类。使用逻辑回归方法进行分类,根据softmax公式得到各个类别的概率分布p(yi|z;θ),如式(9)和(10)所示,其中θ为变量参数,bj为偏置参数,yi为分类类别。输出层输出概率最大的分类类别作为预测值。
sθ(yi)=∑zj∈z(zj·θij+bj),
(9)
p(yi|z;θ)=esθ(yi)/∑yi∈yesθ(yi)。
(10)

图3 卷积神经网络结构Fig.3 The structure of convolutional neural network
3.2 情感倾向性分类模型
在基于多特征融合的卷积神经网络模型MI-CNN中分别采用特征层融合和分类层融合两种融合方法,形成特征层融合模型MI-CNN-F和分类层融合模型MI-CNN-C。特征层融合模型MI-CNN-F先融合特征再使用卷积神经网络处理,结构如图4所示。首先对多种特征向量进行组合,输入词语向量WV、词性向量PoSV和情感词向量SWV,拼接后得到综合特征向量,然后进行卷积层和池化层操作,最后使用全连接层和分类器进行情感分类。MI-CNN-F模型结构包括6个部分。
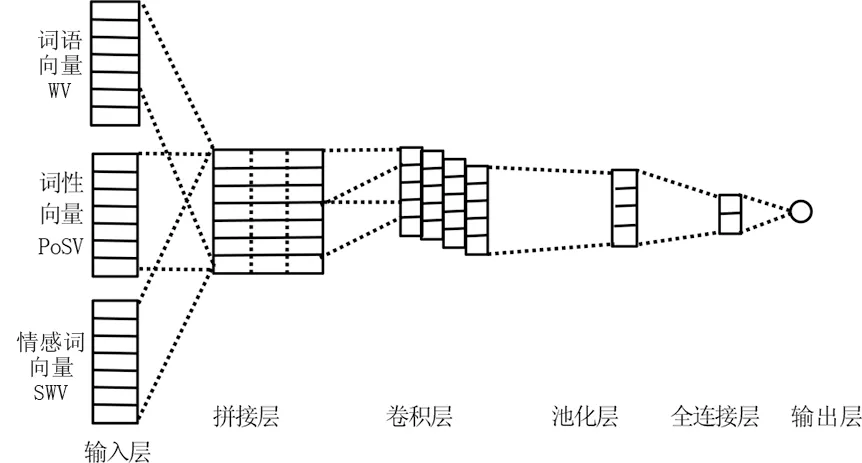
图4 特征层融合模型MI-CNN-F网络结构Fig.4 The network structure of features fusion model MI-CNN-F
1)输入层,接收词语特征向量、词性特征向量和情感词特征向量,输入到卷积神经网络模型。
2)拼接层,将多种特征向量进行拼接组合,形成整体特征向量。
3)卷积层,对特征数据使用多个卷积核进行卷积操作,卷积核的宽度为特征向量维度,高度分别设置为1、2、3,每个卷积核提取出一组特征向量。
4)池化层,对每个卷积核得到的特征向量进行最大池化操作,通过池化操作获取每组特征向量的重要信息。
5)全连接层,使用全连接层连接全局特征向量和情感类别,通过权重矩阵学习特征向量和情感类别之间的非线性关系。
6)输出层,使用softmax函数输出概率最大的情感类别。
在模型中使用线性整流函数ReLU作为卷积层中的激活函数,卷积操作的计算如式(11)所示,其中h为卷积窗口的长度。
ci=ReLU(w·xi:i+h-1+b)。
(11)
(12)
在经过全连接层处理后,得到长度为类别数量的向量,根据softmax函数计算的概率分布得到最后的分类结果。使用随机梯度下降法训练神经网络模型,在训练模型过程中使用交叉熵作为模型的损失函数。
分类层融合模型MI-CNN-C将在卷积神经网络处理之后,再将多种特征的处理结果进行拼接融合。模型结构如图5所示。首先将特征向量输入到卷积层和池化层进行处理,然后通过拼接层融合多种特征的处理结果,最后使用全连接层和分类器进行情感分类。MI-CNN-C模型同样包含6个部分,每个部分的计算方法和特征层融合模型类似。
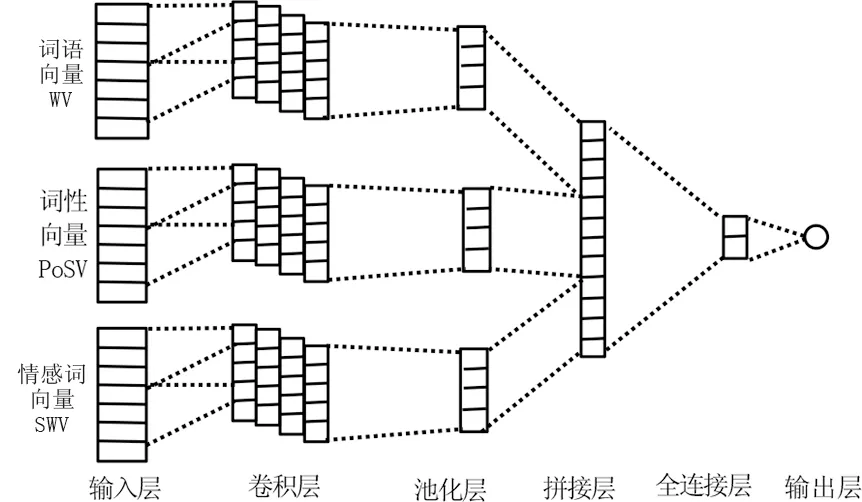
图5分类层融合模型MI-CNN-C网络结构Fig.5 The structure of classification level fusion model MI-CNN-C
4 实验
4.1 数据集
实验中采用中国科学院谭松波整理的酒店评论语料数据集,简称Hoteldata。数据集包含重复数据,经过去重处理,得到的酒店评论数据集包含2 296 篇正面评论和2 435 篇负面评论,总共4 731 篇评论。
4.2 实验指标
评价指标采用准确率Precision、召回率Recall和F-score,其计算如式(13)、(14)、(15)所示。其中TP是分类结果中正确的数量,FP是分类结果中错误的数量,FN是该类样本数据集中未被正确分类的数量。F-score是综合考虑准确率和召回率的调和值,反映了模型的整体效果。
(13)
(14)
(15)
4.3 特征组合比较
MI-CNN模型在文本特征的基础上,增加了词性和情感词语等语言知识作为输入数据,增强了文本语义信息和情感信息,该实验通过调整输入特征数量和组合来检验模型的情感分类效果。使用词语向量WV、词性向量PoSV和情感词向量SWV等3种特征进行组合得到WV、PoSV、SWV、WV+PoSV、WV+SWV和WV+PoSV+SWV等6种特征组合形式。
特征层融合模型MI-CNN-F的特征融合实验结果见表1。从表1可以看出,词语特征、词性特征和情感词特征的组合方式WV+PoSV+SWV取得了最好的情感分类结果,该组合的正面类别F值达到89.9%,负面类别F值达到90.7%,宏平均F值达到90.3%,高于其他特征组合方式,说明多种特征组合能够提高分类效果。使用单个特征作为输入的情况下,情感词向量SWV的F值为89.4%,高于词语向量和词性向量,说明情感特征在情感分类任务中发挥重要作用。
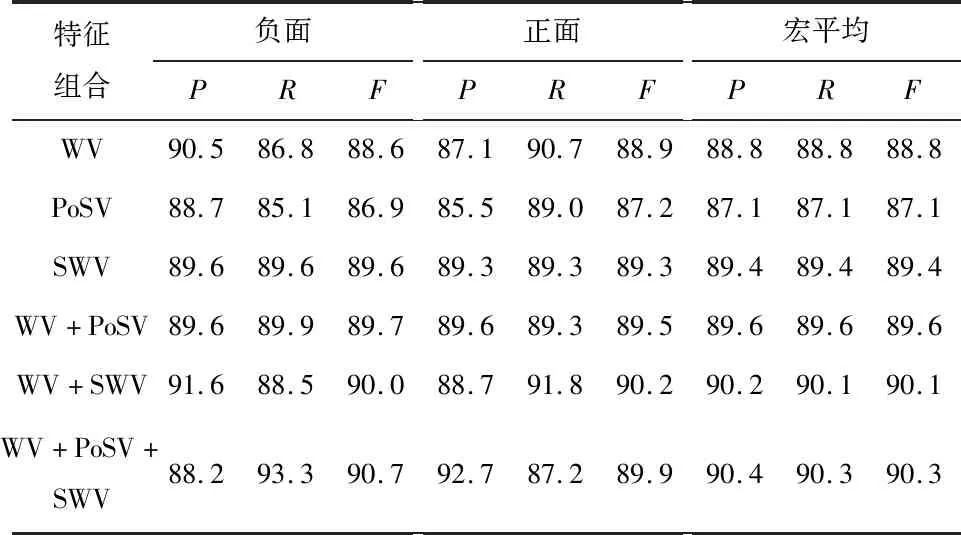
表1 MI-CNN-F模型特征组合实验结果Tab.1 The experiment result of MI-CNN-F with different features combination 单位:%
分类层融合模型MI-CNN-C的特征融合实验结果见表2。从表2可以看出,词语特征、词性特征和情感词特征的组合方式WV+PoSV+SWV取得了最好的情感分类结果,明显高于其他单个特征或两个特征的组合方式。3种特征组合的正面类别F值达到92.8%,负面类别F值达到93.2%,宏平均F值达到93.0%,高于其他特征组合方式,说明在分类层融合模型中组合多种特征能够提高分类效果。
实验验证了在文本特征的基础上,加入词性特征和情感词特征等外部语言知识,能够有效地提高卷积神经网络情感分类模型的准确率。

表2 MI-CNN-C模型特征组合实验结果Tab.2 The experiment result of MI-CNN-C with different features combination 单位:%
4.4 融合方法比较
在MI-CNN模型中使用了特征层融合和分类层融合两种融合方法。通过对比表1和表2 MI-CNN-F和MI-CNN-C两个模型的实验结果,研究合适的特征融合方式。在WV+PoSV+SWV特征组合数据上进行实验,MI-CNN-C的宏平均F值比MI-CNN-F模型提高了2.7%。说明采用分类层特征融合方式的效果更好。
4.5 模型比较
为了验证所提出的MI-CNN 模型的有效性,和相关文献中的多种模型进行比较。从情感分析相关文献中选择使用谭松波酒店评论数据集作为实验数据的研究作为基准模型,包括LSA-SVM[16]、情感词典模型[17]、HGSD[18]、W2V-Att-CNN[19]等4种。将本文模型MI-CNN-C的最优结果作为文本特征和语言知识融合的结果。各种模型的准确率、召回率和F值的结果见表3。从表3可以看出,本文模型的F值均高于其他基准模型,验证了文本特征和语言知识融合的卷积神经网络模型的有效性。

表3 模型对比试验结果表 Tab.3 The result of comparative experiment 单位:/%
5 结束语
本文提出了融合多种特征的卷积神经网络模型MI-CNN,将文本特征和语言知识融入情感分类模型中。在酒店评论数据集上进行了实验,实验结果表明了本文模型的有效性。该模型探索了在神经网络模型中融入外部语言知识的方法,为多特征融合提供了有效形式,并在情感倾向性分析任务上进行了实验验证。在以后的研究中,将继续研究文本情感特征表示方法和注意力机制在该模型结构上的应用,进一步提高情感倾向性分类模型的准确性。
