融合用户信任度的概率矩阵分解推荐算法
2021-03-08陈辉王锴钺
陈辉,王锴钺
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
大数据时代,由于互联网和电子商务的信息量大、种类多、更新速度快,导致了信息超载问题。不断发展和寻找新的技术来与用户进行互动、交流和提供个性化的体验,增加浏览量、销售量并留住用户是非常重要的。然而,搜索引擎只能被动地接受命令和执行命令,为用户挖掘感兴趣的信息并不是独立的、主动的。于是,利用数据的力量来预测用户兴趣的推荐系统(RS)得到了大量关注。在用户不主动搜索的情况下,RS可以根据已有数据将某些项目精确地推荐给有此需求的用户,帮助用户应对信息超载难题,提高信息的有效利用。但RS面临数据稀疏性、冷启动、负面评价影响、评分情绪倾向、商家信任度评价等问题。
目前,RS已广泛应用于各个行业,不同的应用行业采用的推荐方法同源异流。基于协同过滤的推荐系统(CF)应用最为广泛[1],它是一种通过从其他类似用户或项目中收集评价信息来自动预测用户倾向的技术。以CF算法为基础,针对用户倾向相似度问题,很多学者对其进行了进一步研究和改进。Polatidis 等[2]提出了基于协同过滤的多层推荐算法,在衡量相似度时,对相似性进行排序并分成不同等级,每个等级增加相应的限制条件以此来增加相似度衡量的准确性。王付强等[3]提出了一种基于位置的非对称相似性度量的协同过滤推荐算法(LBASCF),将余弦相似性与基于位置的相似性融合,得到一个新的非对称用户相似性。Suryakant等[4]考虑了用户的评分习惯,提出一种基于均值散度度量相似性的计算方法,将余弦相似性(COS)、Jaccard相似性和MMD[5]相似性算法相结合,计算总体相似度。于金明等[6]提出了一种基于评分相似性和结构相似性两部分构成的新的项目相似度量方法,但只考虑联合评分用户对相似度的影响[6]。肖文强等[7]在相似度计算中,分别引入了物品时间差、流行物品权重以及用户共同评分权重来提高相似度度量的准确性。Li等[8]提出一种改进相似度和遗忘曲线相结合的推荐算法,计算用户之间的相似度时,考虑了具有共同分数项目的数量对相似度的影响,提高了相似用户集合的准确性。Fu等[9]考虑了部分用户的个性化需求,结合K-means聚类方法,采用基于社区因子的计算方法代替传统的相似度计算方法,提高推荐精度。Jiang 等[10]提出了一种基于可信数据和用户相似度融合的slope one算法,将改进后的相似度算法与slope one算法的权值相加,得到最终的推荐结果。
由于矩阵分解模型具有良好的可扩展性和较强的理论基础,在基于模型的推荐系统中得到了广泛的应用,许多学者从不同的角度对其进行了建模。Forsati等[11]介绍了一种基于社交排名的协同过滤模型PushTrust,从用户的社交环境中提取用户的潜在特征并进行排名,能够同时利用信任、不信任和中立关系,将其整合到矩阵分解算法中。Yang等[12]提出了基于概率矩阵分解的TrustPMF推荐模型,该模型对基于矩阵因子分解的社会推荐模型提供了概率解释,整合用户评分数据和这些用户之间的社会信任网络来提高推荐的性能。Xu[13]提出了一种基于矩阵分解的结合社会信息和物品关系的推荐算法,对物品的特征信息进行正则化约束,在矩阵分解和降维过程中保持数据特征的稳定性。
然而,由于CF的性质,评分矩阵过于稀疏是基于该技术的推荐系统存在的关键性问题,如商业推荐系统的可用评分信息密度通常不到1%[14]。传统的计算相似性的方法,如余弦相似性(COS)、修正余弦相似性(ACOS)、皮尔逊相关系数(PCC)以及约束皮尔逊相关系数(CPC)[15]等都是针对用户间的联合评分来进行相似用户查找的,在面对稀疏的数据集上显得力不从心。同时,几乎所有基于内容和基于模型的CF算法都无法处理从未对任何项目进行评分的用户[16]。但事实上,现实生活中产生的数据是庞大且稀疏的,大部分用户的评分都低于20项,这使得用户之间缺少联合评分,由此计算的推荐结果准确率较低。从这个角度来看,传统的忽略非联合评分项的推荐系统可能不再适用。
为了提高传统协同过滤算法的效果,本文利用KL散度计算用户间的联合评分项以及非联合评分项,充分利用评价信息找到信任度较高的同倾向用户,提出一种运用用户信任度正则项约束概率矩阵分解模型的推荐算法。该算法通过在概率矩阵分解模型(PMF)[17]中加入用户信任度正则项,缓解推荐系统冷启动以及稀疏性问题,通过实验逐步建立改进算法所涉及的不同参数值,并在MovieLens 1M和Epinions数据集上进行对比实验。
1 相关工作
1.1 评分矩阵
在CF中给用户的建议取决于两种收集用户倾向信息的方式,一种是显式反馈信息,即用户对该项目的评分;另一种是隐式反馈信息,即浏览网页次数、购买次数等,与该用户喜好相似的其他用户对该项目的评分也属于隐式反馈的一种。用户对项目的评分可以用一个用户-项目矩阵来表示,矩阵中的每个项表示各个用户对各个项目的倾向值。
假设U={u1,u2,…,um}是一个用户集,I={i1,i2,…,in}是一个项目集,所有用户对所有项目的评分构成评分矩阵,见表1。

表1 用户-项目评分矩阵Tab.1 User-item rating matrix
表1中,rui表示用户u对项目i的评分,代表用户的倾向程度。如果用户u对项目i没有进行评分,则rui=0。实际上,用户-项目矩阵非常稀疏,它意味着矩阵中有许多项的值为0。为了克服这一问题,本文运用PMF算法对用户-项目矩阵进行隐式反馈信息的寻找,并且考虑用户间的信任度,通过KL散度相似性算法寻找倾向程度相似的用户,设计规范化项来约束目标函数,提高推荐系统的准确率。
1.2 概率矩阵分解模型
PMF是基于模型的CF推荐算法的一种,将高维的评价矩阵降维,得到用户隐藏特征矩阵和项目隐藏特征矩阵,通过计算二者的内积对评价矩阵的缺失值进行进一步的预测。
给定一个m×n评价矩阵R,采用秩为d的两个低维矩阵U、V来拟合,拟合式为
R≈UVT,
(1)
式中:U∈m×d;V∈d×n,d≤min{m,n};U代表每个用户对d种特征的倾向程度;V代表d种特征在每一个项目中的存在程度。

p(R|U,V,σ2)=
(2)
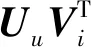
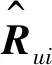
(3)
2 融合用户信任度的概率矩阵分解推荐算法
2.1 基于KL散度的相似性计算
相似性计算在CF中处于重要地位,常用的相似性度量方法无法完整地利用评分信息,只考虑了用户间的联合评分项,不适宜处理非线性的情况。但在实际生活中,极度稀疏的数据集上的联合评分项较为匮乏,利用传统算法寻找相似用户会出现误差,影响推荐结果。
KL散度(kullback-leibler divergence) 是一种广泛应用于评价两种概率分布差异的度量方法[18],若两个对象分别服从两个相同或不同的概率分布,使用 KL散度能高效地区分重叠现象较为严重的对象。因此,本文综合用户间的联合评分项以及非联合评分项,利用KL散度的优势提出项目相似度计算模型。
在评分矩阵中,可将所有用户对某两个项目i和j的评分看成两个离散数组,替换KL散度公式中的概率密度函数,得到i与j的KL距离计算公式为
(4)

两项目间的相似性计算公式为
(5)
虽然KL 距离是非对称的,但在评分矩阵中,运用项目i所有评价信息来近似项目j所得的误差和运用项目j的所有评价信息来近似项目i所得的误差具有相同的意义。所以,采用式(6)代替式(5)中的D(i,j):
Ds(i,j)=(D(i,j)+D(j,i))/2,
(6)
则项目i和项目j的KL相似度改写为
(7)
用户对某个项目的倾向程度会受到相似用户的影响,也就是说,用户的特征向量与他的相似用户差别不大。对基于KL散度的相似性计算结果进行排序,来获得用户间的信任度排名,得到用户的前K个相似用户。设用户u,v对项目i,j评分为(rui,-)和(-,rvj),没有联合评分项,在极度稀疏的评分矩阵中这样的问题屡见不鲜,为此,利用稀疏数据集中普遍存在的非联合评分项,计算用户u和用户v的信任度:
(8)
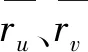
2.2 基于用户信任度的概率矩阵分解模型
为用户推荐的项目应该与用户的倾向程度越接近越好,而相似的用户之间具有相似的倾向程度。基于这一假设,在计算用户信任度时利用KL散度,从中选择信任度最大的K个相似用户,并在矩阵分解过程中保持这种联系,使得相似用户间的特征向量更加接近,并且可以根据信任度的不同而对不同用户区别对待。因此,在式(3)的损失函数中加入一个正则项:
(9)
式中:K(u)表示用户u的前K个最为相似的用户;Uf表示用户的第f个相似用户的特征向量;α表示用户相似度正则系数。该正则项表示相似用户间的信任度差距,最小化目标函数使它们之间的差距最小,使得用户特征向量更加贴近其相似用户的特征向量。得到如下模型:
(10)
目标函数局部最小值采用随机梯度下降法求得,对式(10)中Uu和Vi的偏导数如下:
(11)

(12)
参数更新方式:
(13)
(14)
式中β为学习速率,选取的值太大会导致迭代结果发散,越来越偏离最小值;β越小虽然会得到更精确的结果,但是时间代价太大,因此需进行实验,选择合适的学习速率。
2.3 算法描述
利用2.1节中用户信任度计算和2.2节中的PMF模型,得到融合KL散度用户信任度计算的概率矩阵分解协同过滤推荐算法(MDCF-KL) 伪代码如下:

Algorithm1 MDCF-KL算法 Input:用户-项目评分矩阵,正则化参数α、λ和η,最大迭代次数H,学习速率β,特征向量维度d,相似用户数量K以及推荐项目数量N。Output:用户隐藏特征矩阵U,项目隐藏特征矩阵V,预测评分值Pre_R以及N个推荐项目。Initialize:随机初始化U、V(σ2=1的标准正态分布),根据3.3节中表3设置参数值。1.forv<=mdo2.fori<=ndo3.forj<=ndo4.calculateKL(i,j)5.calculateS(u,v)6.endfor7.endfor8.N[v]=S(u,v)9.endfor10.Sim-K=sorted(N[v],num=K)11.forh<=Hdo12.forallrui∈Rdo13.Uu←Uu-β∂L∂Uu14.Vi←Vi-β∂L∂Vi15.endfor16.h=h+117.endfor18.Pre_R=U∗V19.Top-N=sorted(Pre_R[u][],num=N)
3 实验结果与分析
3.1 数据集
本文实验采用的数据集为MovieLens1M和Epinions。MovieLens1M只允许对自己看过的电影进行评分,分值在1~5之间。在这组数据中,每个人至少给20部电影打分,电影包括19种类型。Epinions涵盖了分布在美国和欧洲的消费者对商品的评价。数据集的具体信息见表2。

表2 数据集信息Tab.2 Datasets information
3.2 评价标准
在对算法性能和有效性进行评价时,采用平均绝对误差(MAE)、准确率(Precision)和召回率(Recall)三种指标,计算表达式为:
(15)
(16)
(17)
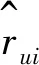
3.3 实验结果与分析
为了得到理想的对比结果,本文根据参考文献推荐的参数值以及参数调优的结果选择最优实验参数,实验参数设置见表3。

表3 参数设置Tab.3 Parameter settings
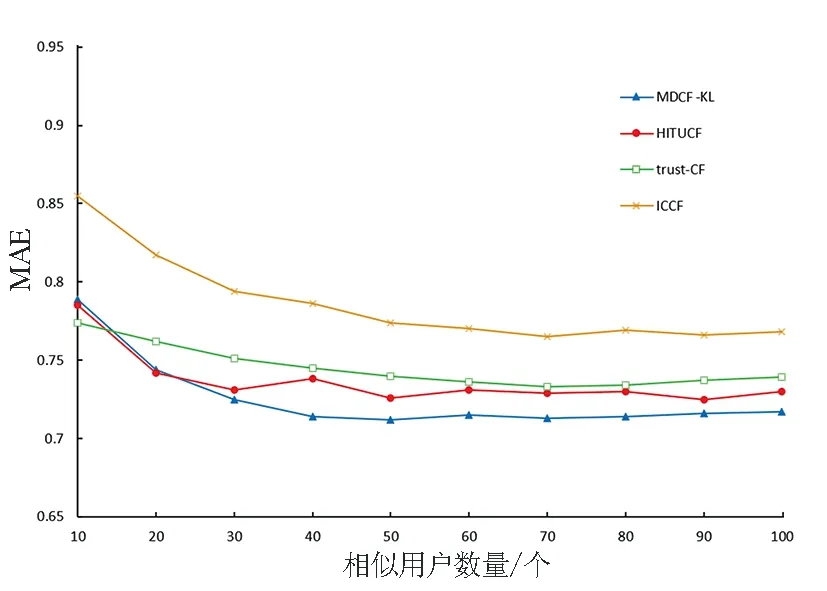
MDCF-KL算法和HITUCF[8]、ICCF[9]以及trust-CF[10]三种对比算法在MovieLens1M和Epinions两个数据集上的MAE测试效果如图1所示。
(a)MovieLens 1M数据集

(b)Epinions数据集图1 两种数据集上MAE比较Fig.1 Comparison of MAE values on two datasets
从图1可以看出,随着相似用户数量的增加,四种算法的曲线都呈下降走向,而且逐步趋于平缓。在MovieLens1M数据集上trust-CF、ICCF在相似用户数量为70时达到最优值,MDCF-KL、HITUCF在相似用户数量为50时更快地达到最优值,MDCF-KL算法相比较于其他三种算法平均绝对误差明显减少。在Epinions数据集上ICCF与其他三种算法有较大差距,主要原因是ICCF算法过于追求用户的个性化需求,导致符合条件可以参与计算的评分项目极其稀少,不适用于更为稀疏的数据集。其他三种算法的平均绝对误差虽然有所增加,但仍能保持一个相对良好的性能,尤其是MDCF-KL算法,能通过非联合评分项判断相似用户并结合概率矩阵分解,在较为稀疏的Epinions数据集上更有优势。
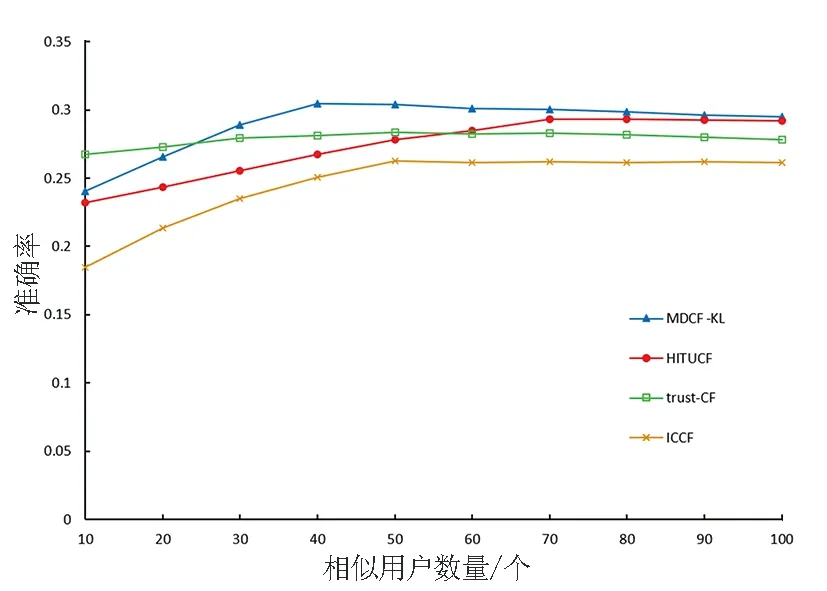
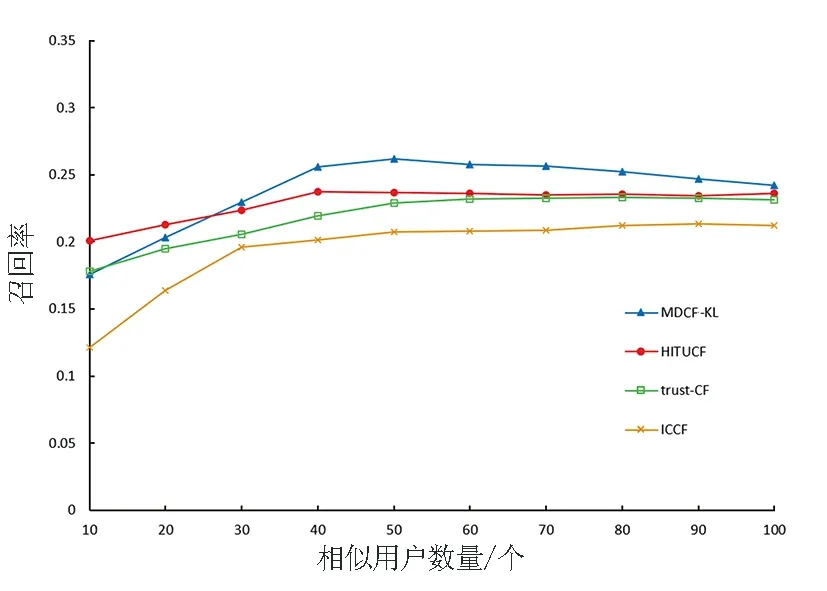
为了进一步验证MDCF-KL算法的有效性,分别在MovieLens1M和Epinions数据集上针对不同相似用户数量,采用召回率和准确率两个指标对各算法的表现进行实验比较,如图2、图3所示。
(a)准确率比较
(b)召回率比较图2 MovieLens 1M数据集上准确率和召回率比较Fig.2 Comparison of precision and recall on MovieLens 1M dataset
从图2可以看出,在MovieLens1M这个评分矩阵密度相对较高的数据集上,MDCF-KL、HITUCF和trust-CF的准确率和召回率较为相近,相似用户数量少于30时,三种算法表现各有优劣,但在相似用户数量为40时,MDCF-KL准确率得到了最优结果。随着相似用户取值逐渐增加,推测出的用户喜欢物品范围越来越小,导致MDCF-KL召回率下降,但仍然优于其他三种算法。
(a)准确率比较
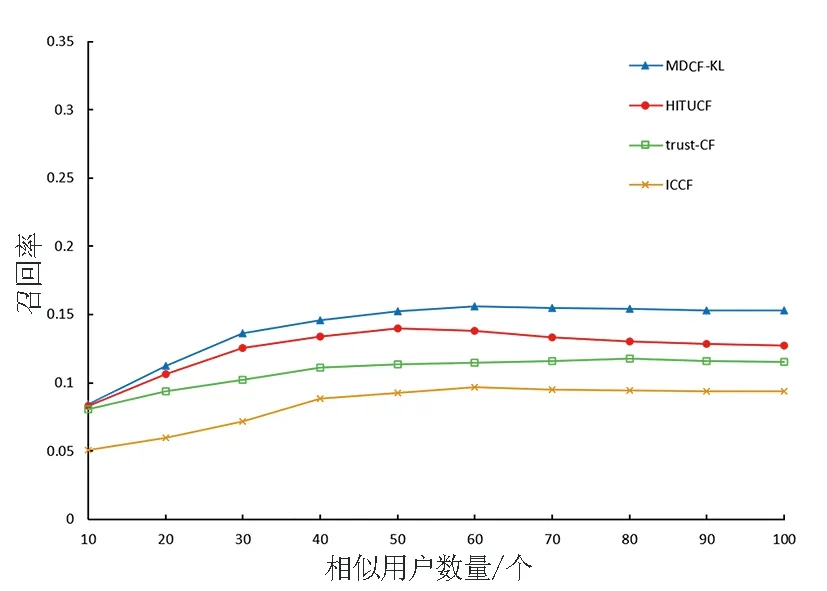
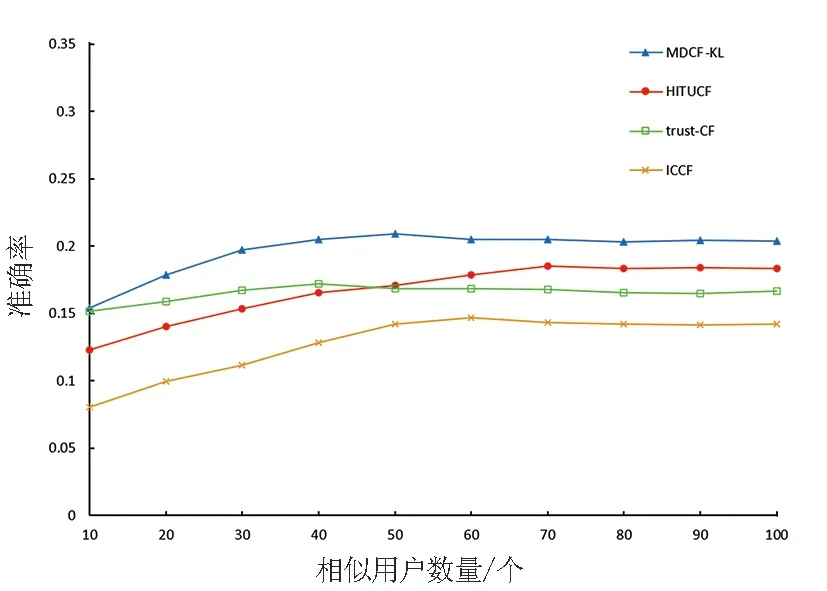
(b)召回率比较图3 Epinions数据集上准确率和召回率比较Fig.3 Comparison of precision and recall on Epinions dataset
从图3可以看出,Epinions数据集上,随着数据稀疏程度增大,MDCF-KL算法在相似用户数量小于40时,准确率相比较于其他三种算法有明显的提高,并在相似用户数量达到60时准确率和召回率取得最优结果。这是由于本文算法充分考虑了非联合评分项,增加了评分的利用率,在面对更为稀疏的数据集时有着较为明显的优势。
4 结束语
为了解决冷启动以及数据稀疏的问题,本文将用户非联合评分引入PMF推荐系统,提出了一种基于概率矩阵分解和正则约束用户信任度关系的算法。通过对MovieLens1M以及Epinions数据集的实验分析表明,MDCF-KL方法能有效提升推荐性能,并且在更稀疏的Epinions数据集上取得了明显成效。在下一步的研究工作中,将会考虑需求中的长尾效应,挖掘零散、个性化但数量极大的尾部需求;利用拉普拉斯等分布来更有效地拟合潜在特征向量,贴合实际情况,提高长尾项目建模的能力。
