基于深度学习技术的纤维混凝土CT图像中短切玻璃纤维的快速识别模型
2021-03-05李他单
张 鹏, 洪 丽,2,3, 李他单
(1.合肥工业大学 土木与水利工程学院, 安徽 合肥 230009;2.同济大学工程结构服役性能演化与控制教育部重点实验室, 上海 200092;3.合肥水泥研究设计院有限公司,安徽 合肥 230051)
0 引 言
混凝土以拥有众多优点而被广泛应用于建筑工程中。但是混凝土的抗拉强度低,易开裂,严重影响其耐久性和安全性。研究显示[1],纤维的掺入能够有效抑制裂缝的开展,明显提高混凝土的抗拉性能和抗裂能力。然而,纤维在基体中的分布对其增强效果有重要影响[2]。大量研究表明[3-6],当纤维分布方向与裂缝开展方向垂直时,纤维增强效果最显著;而当二者平行时,增强效果最差。因此,获取纤维混凝土中短切纤维的分布有利于进一步揭示纤维在基体中的作用机理。
但是针对混凝土中纤维分布的研究,主要基于CT成像技术并获取纤维混凝土的切片图像[7,8],通过图像分析,逐一通过人工标记法确定纤维的位置[9,10],这类方法需要消耗大量的人力且效率低。文献[11-14]采用传统的图像处理法识别短切纤维,该方法首先对图像进行灰度化处理,根据纤维与背景图像的像素值大小不同,再采用阈值法对图形进行二值化分析,使纤维在图像中分割出来。该方法对钢纤维的识别效果较好,因为钢纤维与混凝土基体的密度差别明显。但是,该方法对原始图像的精度要求高,无法准确地分割含有丰富背景噪声的图像,且因玻璃纤维、玄武岩纤维等与混凝土基体的密度差异小,导致阈值法对这类纤维的识别准确率低。
随着机器学习技术的不断发展,基于深度学习的图像识别已经成为计算机视觉领域的一个研究热点。DeeplabV3+[15]语义分割模型,作为深度学习的代表算法,其在图像识别领域具有重要应用。Zhou[16]等基于深度学习技术建立了混凝土表面孔洞快速识别方法。
为了快速准确获取纤维混凝土中短切纤维的分布,本文基于深度学习技术,以课题组前期获得的玻璃纤维混凝土Nano-CT图像为数据集,采用DeeplabV3+模型建立了短切玻璃纤维的快速识别方法。
1 数据来源
为获取纤维在混凝土基体中的真实分布状态,课题组前期通过对玻璃纤维混凝土(Glass Fiber Reinforced Concrete,GRFC)试件进行钻芯取样,获得直径8 mm、高20 mm的圆柱体样品,并通过X-ray Nano-CT无损检测技术,获取了玻璃纤维混凝土样本中核心部分的正、侧和水平方向的扫描图像[17]。其中,正向扫描图像共993张图像,部分图像如图1所示,图像大小为400 pixels×400 pixels×3。从图1中可以看出,灰色的线条状组分即为短切玻璃纤维,其长度为12 mm, 直径13 μm,密度约2.63 g/cm3;与短切玻璃纤维灰度相近的即为水泥砂浆基体,其密度约为2.37 g/cm3[18];黑色的组分为孔洞,密度为0;白色的组分为未水化的水泥颗粒,其密度最大。

图1 玻璃纤维混凝土的X-ray Nano-CT扫描断面图
2 模型的构建
本文基于深度学习对纤维混凝土中的短切纤维进行识别。整体过程分为四个阶段,数据预处理、模型的建立、模型的训练和模型的验证,如图2所示。

图2 基于深度学习对短切玻璃纤维的快速识别过程
2.1 图像预处理
2.1.1 数据增强
基于X-ray Nano-CT扫描试验,本文共获取了850张含有玻璃纤维的有效图片。为提高快速识别模型的精度,作者通过数据增强技术对原始图像分别进行镜像、旋转或局部放大,将850张原始图像数据增强至2 773张,其中2 400张为训练集,30张为验证集,73张为测试集。
2.1.2 数据标记
为了与快速识别模型的预测结果进行比较,提高模型的泛化能力,本文利用labelme软件将原始图像中的短切玻璃纤维标记为白色,而其他背景均标记为黑色,生成的标签图像如图3所示。

图3 数据标记
2.2 模型的训练
2.2.1 模型构建
DeeplabV3+[15]是Google团队开发的语义分割模型,其不仅具有空洞卷积(Atrous Convolution)算法和空间金字塔模块(Atrous Spatial Pyramid Pooling,ASPP),还引入了Encoder-Decoder结构,通过Encoder结构获取高级特征语义信息,Decoder结构进行像素级的分割预测,可更精确的对图像特征进行提取和识别。
将纤维混凝土Nano-CT图像输入到Encoder结构中,经过主干网络Xception(图4)提取所需的图像特征。首先,从Xception中抓取一个低尺度的特征图引入Decoder结构中,提供边缘特征。其他的图像特征进入ASPP,从不同尺度获取图像的基本信息,随后经过一个1×1卷积核降维后,将特征图引入Decoder结构,并与边缘特征进行融合,最后上采样到原始图像大小。最后,将得到的预测结果与标签图像对比计算误差,寻找一次参数的局部最优解至此完成一次训练,经过多次训练迭代得到最优化权重。

图4 主干网络Xception结构示意图[15]
2.2.2 损失函数
本文采用交叉熵损失函数(Loss),模型在输出的预测结果中对每个像素点进行分类并计算该点在每一类中的概率值,损失函数是计算真实概率值和预测概率值之间的差异,计算公式如下:
(1)
式中:Loss为损失函数值;m为图像样本中像素个数;n为类别个数,本文中只有背景和纤维两种,所以n等于2;p(xij)表示真实概率值,而q(xij)表示预测概率值。
2.2.3 评价指标
本文引入准确率ACC(Accuracy)[19],交并比IoU(Intersection over Union)[19]和F1-score[20]三个指标评价DeeplabV3+模型的预测结果。准确率ACC为样本中所有预测正确的像素占总像素的比例,其计算公式如下:
(2)
式中:TP为真正例,将正类别正确地预测为正类别的像素数;FP为假正例,将负类别错误地预测为正类别的像素数;FN为假负例,将正类别错误地预测为负类别的像素数;TN为真负例,将负类别正确地预测为负类别的像素数。
IoU为图像预测结果和标签图像进行比较后,所得到的识别物体的交并比,计算原理如图5所示。
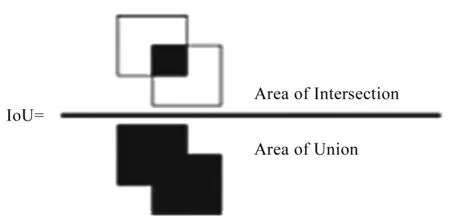
图5 IoU的计算示意图
F1-score[20]是精确率[21](Precision)和召回率[21](Recall)的调和平均值,具体计算公式如下:
(3)
3 模型的训练与验证
3.1 试验环境
Python语言中的Keras是一种以Tensorflow为后端的开源神经网络库,DeeplabV3+是在windows操作系统上使用Keras搭建的,所有的训练和验证都是在GPU(Graphic Processing Unit)上完成的。具体的软件版本和硬件型号见表1。

表1 环境配置表
3.2 训练
3.2.1 参数配置
本文数据集中的训练集共有2 430张图像,每次向模型中同时输入2张图片。因此,模型中每个周期(epoch)需要1 215个迭代步数(step)才能完全历遍整个数据训练集。在每次迭代过程后都会计算网络的训练损失,样本每循环训练3次就保存1次权重文件。本文在分析过程中选择的激活函数为ReLU函数,优化器选择自适应矩估计[22](Adaptive Moment Estimation,Adam)模块。参数设定完成后开始训练,以验证集的Loss为基准,当Loss 3次不下降时,下调学习率至当前学习率的0.5倍;当Loss连续10次不再下降时,停止训练。
3.2.2 初始学习率对比
为了得到更好的网络参数,本文设置了3组不同的初始学习率进行训练。图6显示了训练损失函数Loss和交并比IoU在不同初始学习率下的变化情况。图6的Loss曲线中当学习率为1e-2时,在5个epoch之前Loss下降速度较快,随着训练的逐步进行Loss值下降速度变缓,最终的Loss值也明显高于其他两个学习率的Loss值;学习率为1e-3在训练刚开始就有着较低的Loss值,其后Loss值的发展变化情况同学习率为1e-4类似,均在前20个epoch下降,在第20个epoch后趋于稳定,最终两者的Loss值基本保持一致,其表现为两者对训练集有着同样的学习速率。而在IoU曲线中当学习率为1e-2时,学习率上升明显缓于其他两种学习率的IoU曲线,达到稳定时是在35个epoch;学习率为1e-3和1e-4时曲线上升速率快幅度大,在epoch为20时达到稳定,学习率为1e-3的IoU更高一些。综合分析,当学习率为1e-3时模型的表现最好,为模型的最佳初始学习率。

图6 不同初始学习率下训练集Loss和IoU的变化曲线
3.3 结果分析
图7分别显示了在最佳初始学习率下多种指标IoU、F1-score和ACC在验证集中的变化情况。从图7中可以看出,交并比IoU在20个epoch左右时趋于稳定; 而F1-score初期快速上升,在20个epoch前震荡上升,20个epoch后增长缓慢趋于稳定;准确率ACC一直保持在较高的水平,这是因为数据集中大部分为背景像素,短切纤维在图像中像素占比低,权重小。最终在验证集中,IoU为0.65,F1-score为0.79,ACC为0.99。

图7 验证集不同指标的变化曲线
DeeplabV3+模型的对该GFRC扫描图片中短切纤维的分割结果如图8所示。从比较原图8(a)和分割结果图8(b)可发现,DeeplabV3+模型对本文数据集的分割效果较好,因为DeeplabV3+模型拥有金字塔ASPP模块,可以从不同尺度方向上对短切纤维的特征进行采集,所以在预测过程中较高的还原了短切纤维的边界特征,使其保持高分割精度。

图8 DeeplabV3+模型的验证结果
另外,在测试集中的计算结果表明DeeplabV3+模型的准确率ACC、交并比IoU和F1-score分别为99.3%,67.2%和80.4%。这表明,DeeplabV3+模型能够准确识别混凝土中的短切玻璃纤维。
4 结 论
本文基于DeeplabV3+深度学习模型,对玻璃纤维混凝土Nano-CT图像中的短切纤维进行了快速识别,得到的结论总结如下:
(1)基于数据增强技术实现了对玻璃纤维混凝土图像数量的扩充,建立了满足深度学习技术的玻璃纤维混凝土图像数据集。
(2)模型采用DeeplabV3+模型,通过不同初始学习率之间进行比较,确定了本数据集的最佳初始学习率为1e-3。
(3)模型验证结果表明,DeeplabV3+在短切玻璃纤维的识别效果上,准确率ACC、交并比IoU和F1-score分别达到了99.3%、67.2%和80.4%。
(4)作者们拟进一步借助图形学原理获取短切纤维在图像中的分布信息,为建立短切玻璃纤维在混凝土中的分布模型及其对纤维混凝土破坏行为的影响奠定基础。
