基于异构多核SoC 器件的相控阵探伤仪设计
2021-03-04谢长生陈振娇王胜辉
谢长生,陈振娇,张 俊,王胜辉
(1.中国电子科技集团公司第五十八研究所,江苏 无锡214035;2.上海海骄机电工程有限公司,上海201801;3.上海市特种设备监督检验技术研究院,上海200333)
1 引 言
PE 管的原材料是聚乙烯,它是一种高分子有机合成材料。PE 管的焊接质量直接影响到管道系统的安全和寿命,为了安全考虑,必须对PE 管环焊缝进行内部缺陷的全面探伤,但是目前对PE 管焊接缺陷检测尚无成熟可靠的方法,国内和国际上在此领域尚处于探索和研究阶段。相比于采用传统的超声无损探伤,超声相控阵检测技术具有较宽的有效探伤范围、良好的缺陷定位和定量分析能力、更高的缺陷分辨率及检出率[1]。目前市面上的相控阵探伤仪主要用于金属领域,在PE 材料及环焊缝探伤方面尚有待改进和增强。
PE 超声相控阵探伤仪由于要用于作业现场检测,所以对其便携性、待机时间长等有一定要求。相控阵探伤仪的算法复杂、计算量大、实时性强,所以其软硬件实现架构必须具有很强的信号和数据处理能力。TI 公司推出了C66AK2Hxx 系列数字信号处理SoC 器件,内含多达4 个ARM 核、8 个C66x DSP核。此处设计采用该系列中的一款C66AK2H06 芯片,其含2 个ARM 核、4 个C66x DSP 核。将其运用到PE 超声相控阵探伤仪设计中,可达到高性能、低功耗、低成本的目标。
2 系统原理
PE 超声相控阵探伤仪主要有信号发射/接收、信号处理、图像处理、用户人机界面、测量计算、数据库管理等功能组成。其中信号发射/接收、信号处理、图像处理是相控阵探伤仪的核心部分,其处理流程如图1 所示。
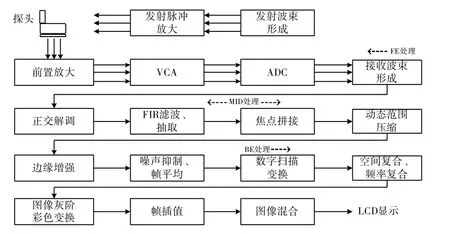
图1 PE 超声相控阵探伤仪算法处理流程
发射脉冲放大、VCA、ADC 为模拟前端,功能为生成高压发射脉冲以驱动探头、接受探头回波信号及预放、压控增益放大以及模数转换等。发射波束形成、接收波束形成为数字前端,发射波束形成产生发射脉冲序列,接收波束形成接收来自于多路ADC的数据,实现对某一给定深度和方向的聚焦,其后经过解调和FIR 滤波、动态范围压缩、边缘增强、噪声抑制、灰阶变换、帧插值等各阶段信号处理、数据处理和图像处理,最后在LCD 上显示出被检测物的超声图像[2-3]。此外还有测量、计算分析、数据库管理、扫查控制以及用户人机界面等功能,一般由上位机(HOST 端)实现。
超声相控阵探伤仪的具体架构实现有不同的方法。前端设计一般采用高压开关、VCA、ADC 等器件,电路结构相对比较固定。发射、接收波束形成目前主要采用FPGA 或ASIC 来实现,以上是前端处理,中后端实现方案比较多,有FPGA+PC 架构的,有FPGA+DSP+PC 架构等。在此采用TI 公司推出的C66AK2H06 异构多核SoC 器件,除了波束形成这种计算数据通量大的运算采用FPGA 实现外,其它信号处理、数据处理和图像处理及HOST 端的用户人机界面、测量计算、数据库管理等功能均可采用一片C66AK2H06 芯片实现,也省去了HOST 端处理的CPU 芯片或PC 板,提高了产品的便携性,降低了功耗,具有一定的先进性和优越性。
设计实现的PE 超声相控阵探伤仪的系统框图如图2 所示。

图2 PE 超声相控阵探伤仪系统框图
基于C66AK2H06 异构多核SoC 芯片对超声成像的中、后端算法处理以及HOST 应用程序进行了并行设计与实现,充分利用了其中多核DSP 的数据处理性能与C 语言编程的灵活性,采用软件实现数据和图像处理,提高设计的灵活性,使系统具有可扩展性和可升级性优点。本系统软件架构和算法处理流程图3 所示。图中标灰色的模块为ARM(HOST)上运行的软件模块,无标色的模块为DSP(Local)上运行的软件模块。ARM 端主要实现用户应用程序,包括用户界面、测量计算、注册、档案、报告、工作表管理以及输出和联网功能。DSP 端主要实现扫查控制、解调、基于Vector(扫描线)和Frame(扫描帧)的数据计算、扫描变换、图像处理等。本系统中的信号处理、数据处理和图像处理算法运算量大,采用DSP实现,正好发挥C66AK2H06 SoC 中多核DSP 的高性能数字信号处理能力和灵活的算法实现能力。
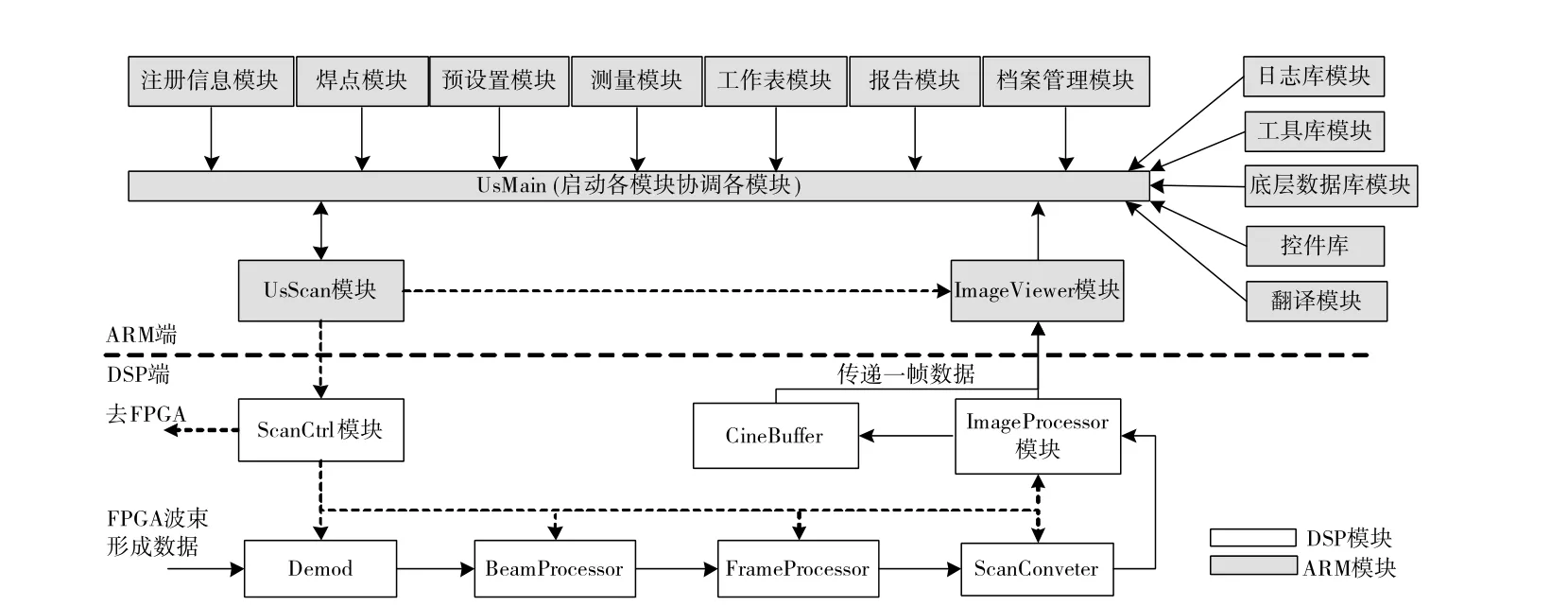
图3 软件架构和其算法处理流程
3 算法方案实现
3.1 C66AK2H06 器件介绍
多核DSP 器件通过将多个DSP 内核集成在一个芯片内,极大提高了数字信号处理芯片的运算性能。C66AK2Hxx 系列高性能数字信号处理SoC 采用异构多核架构,DSP 部分的每个DSP 内核可以运行单独的程序,且拥有相互独立的内存空间,可看作是一种典型的MIMD 计算机。不同于多个DSP 芯片组成的系统架构,多核DSP 单芯片具有片上共享的存储空间以及快速的核间通信能力。
此处采用的66AK2H06 芯片,拥有2 个ARM核和4 个DSP 核,其功能框图如图4 所示。
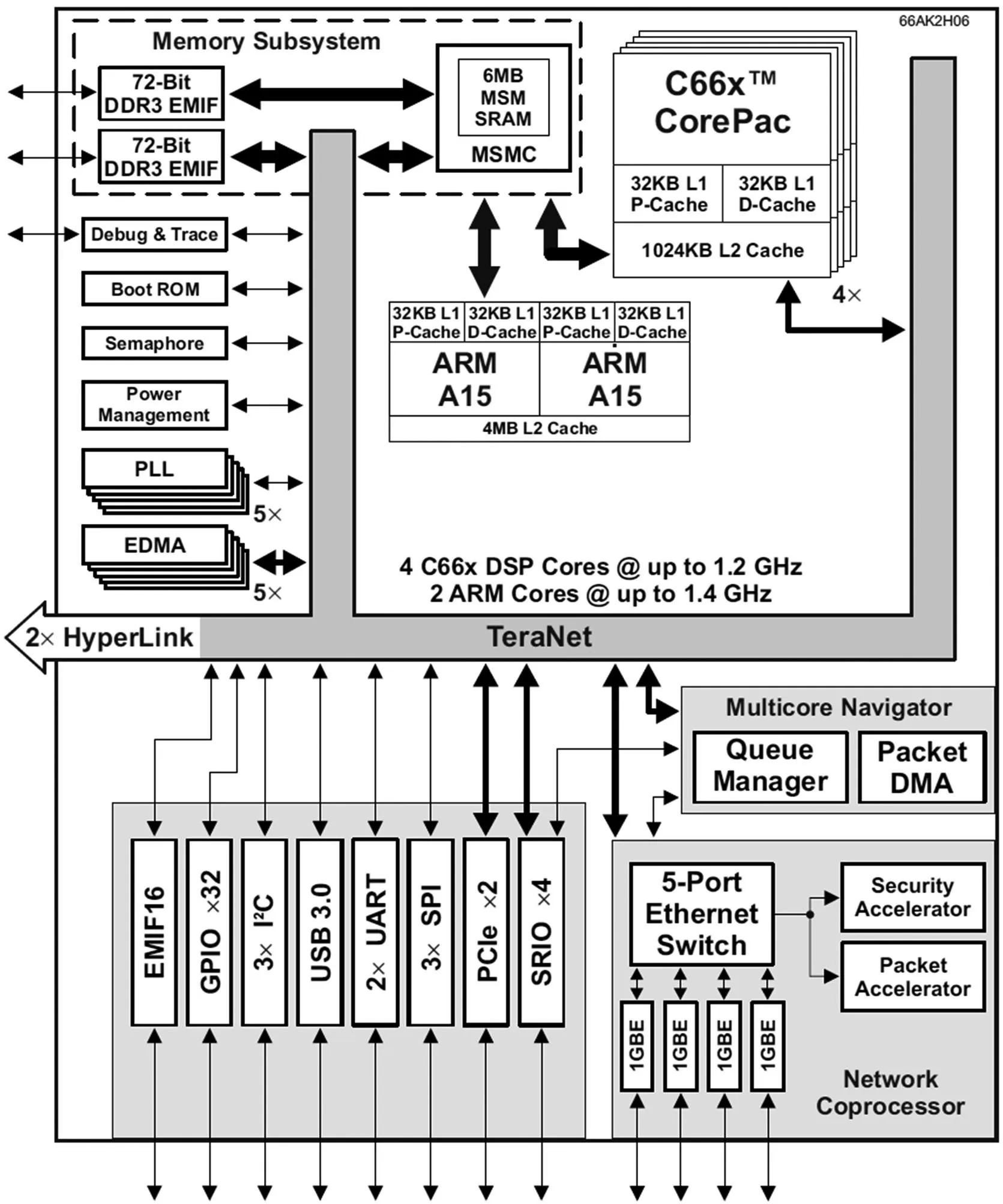
图4 C66AK2H06 功能框图
其中,DSP 核为1.2 GHz 定/浮点DSP 核,性能高达定点40 GMacs/Core、浮点20 GFlops/Core 运算能力。采用4 级存储结构,每个C66x 核心上都集成了32 kB 的L1 程序缓存和L1 数据缓存以及512 kB 的本地L2 存储。ARM 核为A15 ARM,工作在1.4GHz下,具有32 kB 的L1 程序缓存和L1 数据缓存以及共用的4 MB 的L2 存储。除此之外,芯片还集成了多核共享存储器控制器(MSMC),所有核共享MSMC控制的存储空间,包括6 MB 的片上SRAM 以及通过72-Bit EMIF 接口扩展的DDR3 外部DRAM[4]。
3.2 软件并行计算方案实现
程序并行设计首先对应用进行任务规划,将一个应用分解为多个任务,然后根据一定的任务分配模式将其分配到相应的DSP 核上执行。实现方案归纳分析如下:
1)主从模式
主核作为控制核进行任务分配、调度和触发。该模式适用于含有多个独立任务的应用。主核与从核间需要进行频繁地消息通信,从核之间不需要进行同步和数据传递。
2)基于任务的分配模式
各核处理不同的任务,核之间的工作以流水线的方式进行。该模式适用于分布式控制和数据处理的应用,这类应用中通常包含多个复杂的算法模块,单个DSP 核不能满足计算能力需求,且各算法模块间有很强的数据依赖关系[5]。该实现方式很容易实现核间任务的分配,但要在每个核中分配相近的计算负荷是很困难的。
3)基于数据的分配模式
各核处理相同的任务,每个核分配、处理输入新扫描线或新扫描帧数据的一部分,且通常每个核所分配的输入运算数据量大小是相等的,所以每个核上的任务计算量是均衡的。该实现方式需要在数据的划分和计算结果的整合上作相应的考虑和优化。
4)基于帧的分配模式
该实现方式是一个核或核集合处理给定扫描帧的所有处理功能,包括该帧所包含的所有扫描线处理。多个核或核集合可同时处理多个连续独立帧,根据系统的帧速率要求确定需要的独立的核或核集合个数。此法的不足之处是从数据输入到帧计算结果的延迟要比前两种方法略大,但DSP 核处理任务均衡,数据处理吞吐率高,在高强度的计算时会用到。
系统对实时性有一定的要求,最终设计方案综合了上述所列的前三种方法的多核程序开发任务分配模式,采用了Core0 核为主核,Core1耀Core3 为从核。Core1-Core2、Core3 以及Core0 之间以基于任务的分配模式采用流水方式执行算法处理。Core1、Core2 之间则采用基于数据的分配模式对接收波束形成数据分块并行处理。
多核并行计算的关键是如何分配每个核完成任务的时间使之相近。如果每个核之间的计算任务分配不均衡,则系统最终性能会受计算量最繁重、耗时最长的那个核所限制。一般来说数据吞吐量大、算法复杂的处理要花很长时间。
为高效地实现超声成像算法,首先对算法在单个DSP 核上运行的性能进行评估,然后根据算法各模块的时间消耗和数据依赖关系进行任务规划,将算法分配到4 个DSP 核上执行。核间通信采用MessageQ 消息队列和Notify 方案来实现各DSP 核间的扫查指令传递、状态通知和任务同步,使用EDMA3 来实现片外(FPGA 和DDR3 内存)、共享内存、DSP 核本地内存之间的数据交换。利用Core 0实现统一的同步控制、消息分发和数据传输接口。
最终DSP Core 0耀Core 3 核任务以及在系统中所承担的算法运算分配如表1 所示。
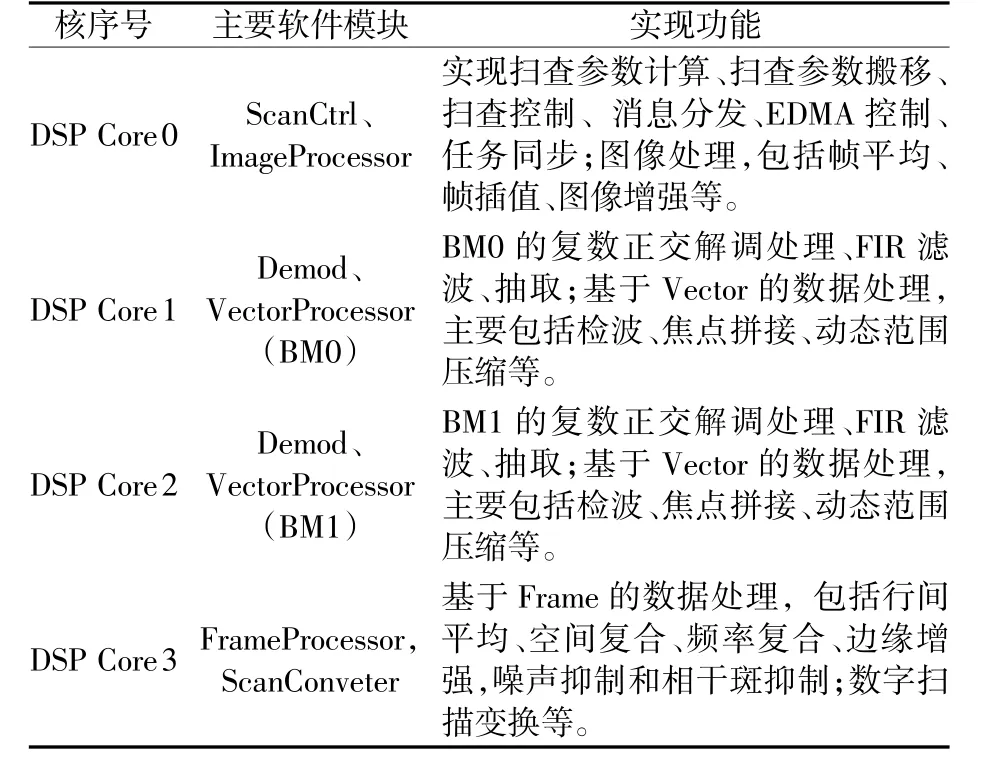
表1 DSP 核任务分配
Core 0 为主控核,主要进行消息的分发、参数数据的搬移、EDMA 控制,以实现DSP 各运算模块、FPGA 和前端的设置、以及Core 1耀Core 3 算法任务的统一调度。复数正交解调和FIR 滤波放在Core 1、Core 2 上执行。由于复数正交解调和FIR 滤波运算是很耗时的算法运算,此处采用两个DSP 核,分别对经过接收波束形成的多波束BM0、BM1 分开并行计算。行间平均、空间复合、频率复合、数字扫描变换(Scan Converter)等放在Core 3 上执行,数字扫描变换后的图像处理如图像增强等放在Core 0 核上运行。设计使用C66AK2H06 的4 个DSP 核以流水方式从Core 1/Core 2→Core 3→Core 0 进行数据处理。DSP 核间的数据传输、参数传递、状态通知和控制如图5 所示。
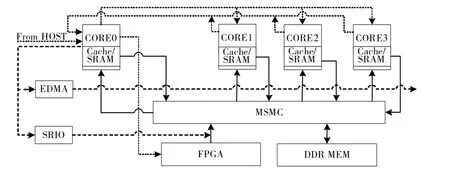
图5 DSP 端运行流程
图中实线代表超声数据的传输,虚线代表MessageQ、Notify、中断的传输,长划线代表EDMA和SRIO 数据传输控制。由图可见,Core 0 作为主控核接收HOST(ARM)传来的扫查指令,然后通过消息队列将其派发给各个所需要的DSP 核、FPGA 及其它前端器件,完成扫查序列切换的扫查参数设置。DSP 接收来自FPGA 的中断,将波束形成后的数据通过SRIO 总线,传输到Core1 和Core 2 的MSMC SRAM 空间。其后依次通过Core 1/Core 2、Core 3、Core0 的算法处理,并将处理好的数据最终输出到HOST 作进一步处理及显示。同时各个核的运行状态和输出数据的内存首地址通过Notify/中断也统一发送给Core0,然后Core0 在适当时刻通过Notify/中断通知相关DSP 核启动数据传输和任务启动,使多核中的各算法任务和数据传输有条不紊进行。
3.3 核间通信及片间通信
核间通信包括数据传输和同步。数据传输包括核间算法参数以及扫查指令的传输;同步主要是在核间交互任务完成状态和共享资源的状态。由于算法参数、扫查指令、状态变量的数据量大小是不一样的,所以要采取不同的通信方式。
在Host(ARM)和Local(DSP)以及不同DSP 核任务之间传输的算法参数,其大小在几十kB 到几百kB,此处采用EDMA 传输在不同核间内存地址空间进行传输,扫查指令大小32 B耀64 B,采用消息队列(MessageQ)机制传输,同步采用Notify/中断来实现。MessageQ 虽然比Notify/中断延迟大,比EDMA带宽低,但灵活性好,尤其是,调用者无需考虑接收者和接收处理的事,这使得核间频繁的可变长度扫查指令传输变得很方便。对MessageQ 机制,接受者需要事先订阅它们感兴趣的信息。消息分发模块维持订阅列表,每当消息发布,便将消息发给订阅者。
在HOST(ARM)和Local(DSP)之间的通信,在此选用TI 提供的SYSLINK。SYSLINK 是一个runtime 软件和移植工具包,简化了ARM 和DSP 之间的通信,提供ARM 和DSP 之间信息交换的通信协议,实现多核之间的软件互连。同时通过SYSLINK使用,一个核可以指定为Master,控制其它Slave 核的执行,包括Slave 核的bootload 启动,ARM 也可以通过SYSLINK 存取公用模块[6]。
HOST-DSP 间通信包括:接受ARM 过来的消息;将消息传递到订阅消息的DSP 线程中;将消息发送给ARM 不同的线程。整体通信情况如图6。消息队列方案通过在共享内存中开辟消息队列的方法实现DSP 核间的通信,接收DSP 核通过中断或轮询专属消息队列的方式来完成消息的获取,发送DSP 核可拥有多个写消息端,即可同时向多个DSP 核发送消息。该方案支持可变长度数据的发送和接收,可满足DSP 核同步、核间数据传输等多种需求[7-8]。

图6 HOST-DSP 间通信
DSP 上的消息分发使用了消息队列和信号量。硬件信号量是多核处理器中一种新模块,实现快速实时的操作,并和硬件中断联系在一起,实现多核之间的握手协议,其工作流程如图7 所示。
Core 0 中的Diapatcher 进程是负责消息分发的,其消息分发的流程如下:
Step1:初始化线程、MsgNotify、消息队列方案所用资源;
Step2:使用MessageQ_get()函数等待HOST 传来消息;

图7 DSP 上的消息分发工作流程
Step3:对消息进行同步处理;
Step4:将消息发送到目标队列中;
Step5:通知目标线程处理消息。
消息分发过程中,Core 0耀Core 3 中的目标线程处理如下:
Step1:等待Core0 中的Diapatcher 发送过来的信号量;
Step2:从消息队列中获取消息;
Step2:根据MessageID 处理消息;
Step4:释放消息。
C66AK2H06 芯片和片外的通信除了和DDR3存储器、LCD 显示屏、SD 卡及网络之外,主要是和FPGA 通信,用于前端控制参数传送的和波束形成数据的接收。此处采用SRIO 接口。SRIO 通信接口优点是占用管脚少,数据带宽高。系统超声扫查时序如图8,一次扫查波束形成数据最大32 kB,接收时间0.2ms,故BFM 数据速率为160MB/s。设计中的SRIO 接口速率选择为3.125Gb/s,其数据传输速率峰值可达312.5 MB/s,大于BFM 数据速率,满足波束形成数据传输的需要。同时使用GPIO 接口,产生中断INT_BFMRD 进行传输的同步控制,数据传输采用DirectIO 机制。

图8 超声扫查时序
3.4 内存分配设计
C66AK2H06 内存系统可划分为L1P/L1D、L2、MSMC SRAM、DDR3 存储四级,其中前三级为片上存储。32 kB 的L1D、512 kB 的L2 既可以作Cache也可以作SRAM 使用,视实际需要而定。不同层级存储器有不同存取带宽,依L1P/L1D、L2、MSMC SRAM、DDR3 次序递减。高带宽会减小取指、数据存取的时间,从而提高整个算法的运算速度[9]。因此关键的代码和数据应尽量放在片上存储,甚至L1 上。表2 给出了不同层级的存储器的理论带宽。

表2 不同层级存储器的理论带宽
在DSP 软件方案的6 MB 的MSMC RAM 中规划了BeamBuffer、IQBuffer、VectorBuffer、FrameBuffer、ImageBuffer、DisplayBuffer 等几部分,用于各DSP核、ARM 核中的各进程处理数据的存储和交换。其中,BeamBuffer 是暂存从FPGA 来的波束形成后的数据;IQBuffer 是复数正交解调后的数据;VectorBuffer是检波后、扫查线处理的数据暂存;FrameBuffer 是扫查帧处理的数据暂存;ImageBuffer 是图像后处理的数据缓存;DisplayBuffer 是图像显示的数据缓存。DDR3 片外存储大小配置为64MB,DSP/ARM 代码、消息通信、发射/接收波束形成Cache 参数数据、各算法处理的参数/表数据、扫查指令、程序堆栈空间都分配在DDR3 上。另外CineBuffer 也分配在DDR3上,用于DSP 和ARM 之间的连续128 帧图像数据保存和传输。整个DSP 算法处理完的数据存储到DDR3 的CineBuffer 区域,然后传输到HOST(ARM)端,用于其后与图形、字符等数据等混合并显示。
L1、L2 除了一部分用于Cache 外,同时可规划出一部分作为SRAM 使用,用来存放对算法速度影响大的代码、参数和数据,提升DSP 核存取指令和数据的速度。由于L1、L2 的空间有限,所以一般只对当前运算用到的关键参数和数据才传输到L1、L2上。为充分利用DSP 核的运算性能,DDR3、MSMC SRAM 与L1/L2 之间采用EDMA 传输和PingPong机制。多级内存的具体规划方式如图9。

图9 多级内存规划
4 实现结果
此PE 超声波相控阵探伤仪的核心基本上基于异构多核信号处理SoC 来实现,因此不需要独立的CPU,FPGA 也可选择较小一些的容量,故其便携性和低功耗性能得到提高。系统实现的关键是系统响应速度和运算能力是否能满足系统技术指标要求。系统主要技术指标如下:
探测深度>20cm;
扫查帧频>20Hz;
线密度>200 线/帧;
系统启动时间<12s;
模式切换时间<1s。
通过对系统的测试,发现模式切换时间、扫查帧频这两项是主要需要优化的指标。
为优化模式切换时间,需要考虑到:模式切换需要做的工作是扫查模式的设置、探头文件等相关资源文件的读取、波束形成Cache、解调、TGC、数字扫描变换的算法系数、曲线、查找表等算法参数的计算,以及算法参数的传输等。为减小模式切换时间,在此比较了对模式切换时间影响较大的算法参数计算及传输的3 种方式,分别为:
方式1:ARM 计算,ScanCtrl 模块位于ARM 上;
方式2:DSP 计算,ScanCtrl 模块位于DSP Core 0 上;
方法3:DSP 分布计算,ScanCtrl 模块主体计算功能位于DSP Core0,部分计算在DSP Core1耀Core 3中进行。
由于参数计算中有大量的浮点运算,所以用DSP 分布计算效果最好,既发挥了定/浮点DSP 核的优势,也发挥了多核的优势,使算法参数计算时间大幅度减少。其余部分参数计算是在本地进行的,节省了其后参数数据传输的时间,进一步缩减模式切换时间。此外,模式切换时间还包括一帧扫描图像通常接收、处理和显示的时间,一般不会超过50 ms。优化后模式切换时间可控制在1s 以内。不同算法参数计算方法和对模式切换时间的影响对比如表所3 示。

表3 不同算法参数计算方法及结果比较
关于扫查帧频,一方面和各核算法的计算速度有关,另一方面和扫查序列切换的时间有关。扫查序列切换主要的工作内容是扫查指令的传输、下一个扫查线的算法参数准备就绪。为降低扫查序列切换时间(如图8 中的T1),采用硬件中断SCSync 来触发扫查序列控制工作,并采用高中断优先级,以减少扫查指令传输、下一个扫查线算法参数传递的响应时间。中断优先级具体设定如表4 所示。

表4 中断优先级
实验测试表明,得到的扫查指令传输(大小为32 B,采用MessageQ)时间为6.2 μs,当前扫查线算法参数传递时间为15μs 左右,加上FE 前端消息传输时间,总共不超过24μs。因此在实际设计中,从SCSync 到TxTrig 的T1 值,设定为30 μs 即可。对于探测深度20 cm,扫查周期可控制在230 μs 之内(T1=30μs,T2+T3 取200 μs 值),对于200 扫描线/帧,帧频指标即可达到21.7Hz 以上,满足帧频20Hz设计要求。
当探测深度降低时,扫查帧频就会提高。为获得较为理想的实时成像,要求算法处理帧频在40Hz以上,这样对每个DSP 核上算法运算执行时间会有相应的限制。假设1 帧256 线,线频是256×40Hz=10240Hz,亦即执行Vector Processing 任务的DSP 核总处理时间不超过97.66μs,执行Frame Processing任务的DSP 核总处理时间不超过25ms,即Core1、Core2 的计算负荷是最大的。
Core1、Core2 的运算任务是复数正交解调、FIR滤波、抽取、检波、焦点拼接、动态范围压缩等。其中比较耗时的是复数正交解调、FIR 滤波。为加快速度,在此将计算使用频率高的SIN/COS 表(<4 kB)、FIR 滤波器系数缓存在L1 存储器中,将TGCTable、SQRT 表、LOG 表等算法参数缓存在L2 存储器内,程序代码存储在MSMC SRAM 中,运算的输入输出数据存储在MSMC SRAM 中,通过尽量使用高的内存读取速度提高了DSP 核整体处理性能。经过实验测试,复数正交解调所花费运算时间为18.3 μs,128阶FIR 滤波所花费运算时间为26.7μs,两者相加为45μs,占DSP 核可用时间的46%,为满足线频、帧频的要求提供了保证。
通过对基于C66AK2H06 的相控阵探伤仪设计的优化和结果分析,系统实现的性能满足技术指标需求,基于多核DSP 的算法能够处理每秒钟40 帧以上尺寸为512×256 的超声图像,满足了实时成像的要求。PE 超声相控阵探伤仪的实际界面如图10。
图10 PE 超声相控阵探伤仪界面图
为测试本PE 超声相控阵探伤仪的实际效果,对PE 管焊接质量进行检测,实验结果如图11。图11(a)所示表明焊接正常,图中的白色亮点是金属丝;图11(b)所示为焊接中存在缺陷,白色横线是因为未熔合故障造成的。
本设计不仅具有常规相控阵探伤仪的检测能力,而且针对PE 检测应用进行了有针对性的优化,提供了作业现场照片和作业位置等数据上传、与中心数据库联网管理、空间复合成像、材料特性设置和声速校准等功能。
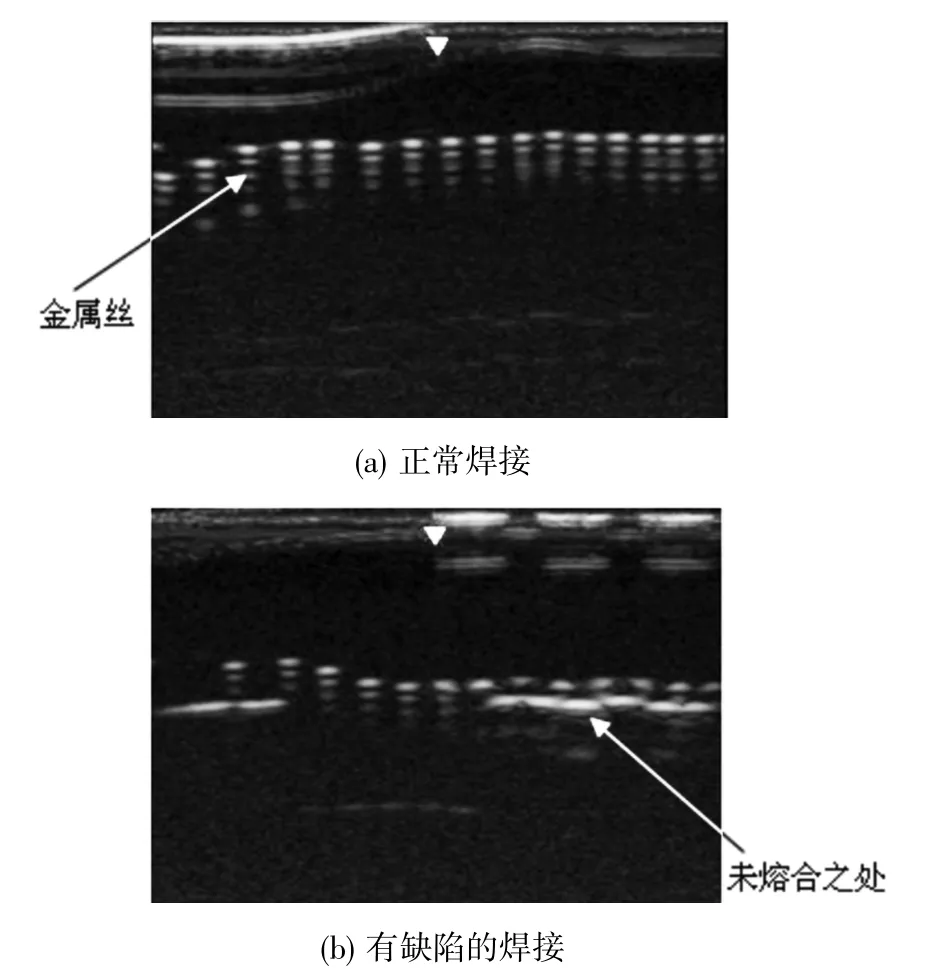
图11 PE 超声相控阵探伤仪实测效果
本PE 超声相控阵探伤仪的设计和PE 管道超声相控阵检测技术的研究,为上海市燃气用PE 管道焊接接头相控阵超声检测地方标准的制定提供了技术支撑[10]。
基于异构多核数字信号处理SoC 的设计需要较多的开发考虑,在后续研究中,还可针对某些应用场合作出进一步优化和完善,如优化通信方式,利用异构多核SoC 芯片内部专用设计的多核导航器、队列、仲裁器来进一步提高核间数据通信的运行效率和传输带宽[11]。
5 结 束 语
设计实现了基于异构多核数字信号处理SoC器件的PE 超声相控阵探伤仪,对其系统架构、算法组成和软件部分的实现技术进行了研究,将HOST应用程序和本地算法运算在一个异构SoC 处理器芯片中完成,并对多核并行计算和核间通讯、内存设计等关键技术进行分析、设计及优化。相比于以前的实现方法,采用异构多核SoC 器件的相控阵探伤仪系统架构更加灵活,整机系统具有很好的可扩展性和可升级性,性能有所提高、功耗更低、更加便携化。
