SQL查询在妇产科医院统计工作中的应用
2021-02-17周哲颖史佳敏
周哲颖 史佳敏 黄 锐
同济大学附属第一妇婴保健院,200125 上海
大数据背景下的医院管理中,统计工作除了执行国家卫生统计报表制度外,各种科研、质量、管理数据等精细化需求,均需要统计人员更多地致力于数据查询与数据挖掘工作[1]。病案首页数据整合了病人的基本信息、住院过程信息、诊疗信息和费用信息,是医院考核的重要依据。在填写病案首页数据时,设定了统一的代码和填写要求,由此形成的首页数据库经过层层质控标准监测,其数据在精准性、客观性、应用性上更胜于其他信息系统。某医院是一所三甲妇产科专科医院,年分娩量位列当地全市第一。该院病案首页数据除了依据国家卫生健康委员会颁布的2013版病案首页数据标准外,还根据医院专业特色增加产科的一些过程变量和结局变量,形成了一对多的数据表结构分布。由于病案统计软件自带的统计查询功能,只能接受简单的查询条件,在查询的自由度、效率上不能完全满足医院庞大的数据需求[2],数据深层检索必须依靠结构化查询语言(structured query language,SQL)语言编写查询语句,才能兼顾实现医院数据大、快、准的统计要求。
1 数据表结构情况
某医院病案统计软件是基于.Net平台面向服务对象进行3层构架模式,Client—Application—Database,数据库采用SQL Server 2008,客户端使C# 语言编写,开发工具为Microsoft visual studio 2010 。其基本数据表架构有6大核心数据表和各类代码表构成。
1.1 6大核心数据表
(1)患者基本信息表(tbt_patient_base):包括病人本次住院id、住院号、姓名、入院日期、出院日期、住院科别、门急诊诊断、医疗组别等。
(2)患者诊断信息表(tbt_ patient _icde):包括本次住院id、诊断编码、诊断名称、入院时情况、疾病转归等。
(3)患者手术信息表(tbt_ patient _icpm):包括本次住院id、手术时间、手术编码、手术名称、切口愈合等级、麻醉方式、手术医生等。
(4)孕产信息表(tbt_patient_preg):包括本次住院id、孕周、出血、胎次、产次等。
(5)分娩信息表(tbt_patient_baby):包括本次住院id、分娩时间、分娩胎数、新生儿体质量、身长、评分、分娩结局(活/死)、分娩方式等。
(6)费用信息表(tbt_patient_cost):包括本次住院id、总费用、诊疗费、护理费、检查费、治疗费、手术费、药费、耗材费等16种首页涵盖的费用类别与其子费用。
1.2 患者信息汇总表
患者信息汇总表(tbt_patient_info),汇总了一个出院病人的基本信息、诊断信息(前7个)、手术信息(前5个)、孕产妇信息、分娩信息(本次住院分娩第1胎信息)、费用信息。
此外,该院住院号的管理模式采用每人在各院区使用唯一住院号的模式。在设计数据库之初约定,病人每次住院使用同一个住院号,但每次住院时后台也会自动分配给病人一个id,不同的住院时间id不同,但住院号相同。
2 实例
2.1 横向关联,实现一对多记录的查询
由于病案统计系统的设计限制,在系统自带的查询功能里,无法实现一对多的统计检索。例如一个病人本次分娩双胎或多胎的情况下,系统自带的统计查询只能显示第1个孩子的信息,因此要查询2020年的所有围产儿的分娩量及其信息(单胎+多胎),此时就需要利用SQL语句查询,完成所有围产儿的信息统计。围产儿是指孕周大于等于28周的分娩胎儿,包括活产和死胎。查询语句如下:
SELECT A.patno,A.patname,b.babyweight,
b.babysex,b.babyagp,b.babydate
FROM Tbt_patient_info A, Tbt_patient_baby B
WHERE A.id=B.id
and year(A.outdate)=′2020′
and A. gestation >=28
语句的第1句是显示产妇的住院号patno、姓名patname、新生儿体质量babyweight、新生儿性别 babysex、AGP评分 babyagp、新生儿出生时间 babydate。第2句用到SQL最常用、最基本的关联语法:将患者信息汇总表Tbt_patient_info和分娩信息表Tbt_patient_baby用本次住院的id相关联,查询条件是孕周(gestation)≥28周并且出院时间是2020年。
根据上述介绍的表结构,表Tbt_patient_info里只记录母亲的部分信息和本次分娩的第1胎信息,如果仅用到Tbt_patient_info表,则只能显示2020年所有产妇及其分娩的第1条信息。如果产妇本次分娩了双胞胎,则也仅显示产妇本次分娩的其中一胎信息,缺失了本次分娩的2胎及以上的信息。因此必须关联Tbt_patient_baby表(Tbt_patient_baby记录了分娩产妇的所有胎儿信息),加上关联条件A.id=B.id,可获得所有的28周及其以上的围产儿信息。
2.2 纵向提取,实现同一变量的纵向查询
在医院科研工作中,常常需要调阅一些同时伴随症的病历。以调阅2020年诊断同时伴有重度子痫前期和妊娠糖尿病的病人为例,如果在系统自带的查询界面上设定查询条件为诊断编码“O14.1(重度子痫前期)并且 O24(妊娠糖尿病)”,则查询的结果为0;若查询条件改为“O14.1 或者 O24”,则输出的结果为重度子痫前期病人或妊娠期糖尿病病人。针对这样的结果,只有导出查询结果,然后取住院号和出院日期相同的重叠记录,才能统计出同时患有指定2种疾病的病人人数。这种方法需要花更多的时间进行二次人工筛选,在效率和准确性上不及SQL的语言查询:
select A.patno,patname ,icdename11,a. icdename 21,a icdename 22,a. icdename 23,a. icdename 24
from Tbt_patient_info a,Tbt_patient_icde b
where a.id=b.id
and YEAR(a.outdate)=′2020′
and b.Icdecode like ′O14.1%′
and a.id in
(select id from T_dmr_patient_icde where left(icdecode,3)=′O24′)
这是一个嵌套语句,首先选定患者信息汇总表Tbt_patient_info和患者诊断信息表Tbt_patient_icde。选定Tbt_patient_info是为了显示患者的住院号、姓名、主要诊断、其他诊断等患者基本信息,其中Tbt_patient_info中横向记录了患者的1个主要诊断和6个其他诊断。但由于每个病人的情况不同,在诊断中无法确定某个诊断(例如本例中的重度子痫前期O14.1)在第几顺序诊断上:既有可能在主要诊断(icdename11),也有可能在其他诊断1(icdename21)或者其他诊断2(icdename22)或第N个诊断上。因此在这种情况下引入患者诊断信息表Tbt_patient_icde。根据上述表结构介绍可知Tbt_patient_icde表中诊断编码和诊断名称的变量只有1个,多个诊断是垂直纵向记录的,可以相对固定诊断编码变量。诊断数据记录方式见表1和表2。

表1 患者信息汇总表Tbt_patient_info 诊断记录方式
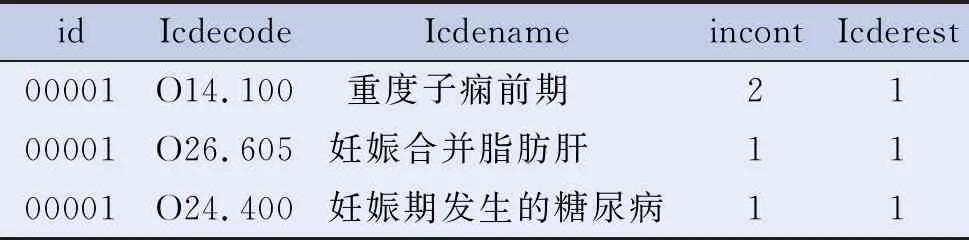
表2 患者诊断信息表Tbt_patient_icde诊断记录方式
在选定好数据表、确定好相关变量后,即可编写第1步查询语句:
Select A.id,A.patno,A.patname, A.icdename11,A icdename 21,A. icdename 22,A icdename 23,A icdename 24
from Tbt_patient_info a,Tbt_patient_icde b
where a.id=b.id
and YEAR(a.OutDate)=′2020′
and b.IcdeCode like ′O14.1%′
第1步查询Tbt_patient_info表中出院日期是2020年并且Tbt_patient_icde表里疾病编码模糊匹配是′O14.1′(这里使用b.IcdeCode like ′O14.1%′,由于重度子痫前期有3个编码和诊断,分别是O14.100、O14.101、O14.102,我们可以统一写成 like ′O14.1%′)。同样2个表用id关联,即a.id=b.id。
第2步查询语句是在第一步查询基础上增加:
and a.id in
(select id from T_dmr_patient_icde where left(icdecode,3)=′O24′)
语意是:在查询出2020年诊断为重度子痫前期的这些病人中,通过这些病人的id继续在病人诊断信息表中搜索出同一个id里存在妊娠期糖尿病(O24)诊断的出院病人。即先确定重度子痫前期的人群,再在这个人群中继续搜索有糖尿病的人。通过这样2步的查询,就可以获得同时患有2种指定疾病的患者人数和相关信息。
2.3 时间关联检索,实现同一住院病人不同时间住院的关联查询
重返率是目前医院质量安全的重要监测指标[3],以31 d非计划再入院指标为例,如果从系统自带的界面查询,查询条件基本无法给定;若依靠平时制度约定的上报记录进行人工检索,花费时间久,而且存在一定比例的漏报现象。但是通过SQL关联性数据查询,就能实现快速锁定统计范围:
select a.patno 住院号,a.patname 病人姓名,b.outdate 前次出院日期, c.indate 后次入院时间,DATEDIFF(dd,b.outdate,c.InDate) 间隔时间,b.IcdeName11 前次诊断,b.opername1 前次手术,b.OperName2 前次手术,b.OperName3 前次手术,c.icdename11 后次诊断,c.opername1 后次手术,c.OperName2 后次手术,c.OperName3 后次手术
from T_dmr_card_base A, T_dmr_card_info b,T_dmr_card_info c ---b是前次,C是后次
where a.id=b.id
and YEAR(a.OutDate)=′2020′
and b.id<>C.id
and b.PatNo=c.PatNo
and c.PatNumb=b.PatNumb+1
and b.againplan=’2’
and DATEDIFF(dd,b.outdate,c.InDate)<=31
本例引入了2个表,分别是患者基本信息表tbt_patient_base、患者信息汇总表tbt_patient_info,其中tbt_patient_info 在本实例里引入2次,分别代表B区的前次信息和C区的后次信息。通过B区信息和C区信息的平行比较,在条件中加入关键变量住院次数(Patnumb)就可以获得同一个病人多次住院的记录。其中关键条件解读如下:
① b.id<>C.id and a.PatNo=c.PatNo 表示前一次住院的ID不等于后次住院的ID,但前一次住院和后一次住院是采用同一个住院号(在前文已经阐述该院管理病案号的模式);
② c.PatNumb=b.PatNumb+1 表示后一次的住院次数=前一次住院次数+1;
③ b.againplan=’2’ 表示前一次住院的再入院计划为‘否’;
④ and DATEDIFF(dd,b.outdate,c.InDate)<=31 表示前次出院日期后后次入院日期间隔日期<=31 d。
从第1句select中,我们除了调取病人的基本信息,更多的是调取病人前次诊断和手术和后次入院的诊断和手术,以及2次相邻入院的时间间隔天数。通过这样的语句可以将前后2次住院的情况清楚地显现出来,从而可以看出前后的诊疗是否具有延续性,即计划内的。比如在妇产科中,葡萄胎在31 d内的再入院治疗是属于正常计划内的。又如分娩后31 d内再入院,后次诊断是胎盘粘连,手术是清宫术则属于非计划内的。通过这样的查询均可以完整地罗列出来各种非计划再入院的情况。
2.4 对象关联检索,实现母-婴的关系查询
母-婴的疾病关系是妇产科医院一项重要的管理研究内容。从目前的数据库结构上,可以通过界面查询的是母亲情况和出生孩子的体质量、身长、评分的关系,但想进一步查询孩子具体的某一疾病和母亲孕产期疾病与处置关系时,则还是需要通过SQL的关联性数据查询,进行一个范围的确定,再进行病历讨论和质量评估。
例如,医院需要对诊断为“新生儿缺氧缺血性脑病”的病例进行母亲孕产期管理的回顾性分析,就需要查询孩子诊断编码为P91.600,其母亲的疾病史、手术史、孕产期情况。具体语句如下:
select distinct A.patno 母亲住院号, A.patname 母亲姓名, A.outdate 母亲出院日期, A.outdays 母亲住院天数,A.deptname 母亲出院科室,A.icdename11 母亲主要诊断,icdename21 母亲其他诊断1,A. icdename22 母亲其他诊断2,A. icdename23 母亲其他诊断3, A icdename24 母亲其他诊断4,A. icdename25 母亲其他诊断5,A.icpmname1母亲手术1, A icpmname 2母亲手术2, A. icpmname3 母亲手术3, A. icpmname 4 母亲手术4, A. icpmname5 母亲手术5
from Tbt_patient_info A , Tbt_patient_base B, Tbt_patient_icde C
where b.outdate>=′2015-01-01′and b.outdate<′2021-01-01′
AND C.icdecode=′P91.600′
AND B.id=C.id
AND RIGHT(A.patno,6)=SUBSTRING(B.patno,4,6)
本例我们逻辑假定孩子相关住院信息表和诊断表为Tbt_patient_base、Tbt_patient_icde,母亲的相关住院信息表为Tbt_patient_info。因此设Tbt_patient_info 为A,从A区中罗列出母亲的基本信息包括基本信息、住院时间、住院科室、相关疾病、相关手术等。
罗列好母亲信息后,再将孩子限定条件编写出来:即从Tbt_patient_icde搜索出诊断编码为′P91.600′,从Tbt_patient_base限定孩子出院时间是2015—2020年,语句为:
from Tbt_patient_base B, Tbt_patient_icde C
where b.outdate>=′2015-01-01′and b.outdate<′2021-01-01′
AND C.icdecode=′P91.600′
AND B.id=C.id。
最后将母亲的住院号和孩子的住院号关联起来。这里不能用id,因为id是针对同一个对象的,不同对象的id没有关联性。但该院的母婴住院号之间是有一定规律的,即母亲住院号的后6位与其孩子住院号的第4至第9位是相同的。通过母婴住院号关联的语句为:
RIGHT(A.patno,6)=SUBSTRING (B.patno,4,6)。
通过这样的SQL语句搜索就可以获得孩子诊断编码为P91.600的相关母亲历次住院情况。数据表逻辑见图1。

图1 母-婴关系数据表逻辑图
3 讨论
SQL结构化的查询语句,作为统计使用的数据查询语言是最常用的功能,通过select —from—where—group by—order by等结构语句可以快速地将不同的数据表内数以万计的记录通过某个条件和表间的共同索引构建组成一个新的查询结果[4]。
研究通过实例分析,展示了SQL在解决不同对象,相同对象不同时间、空间之间的关系查询。相对于固有的报表统计软件,其数据高度自由结合性能在统计工作中起到了极大的辅助作用,其中熟悉数据库架构关系和语言表达逻辑是掌握该技能的关键[5]。首先要充分了解系统后台的数据表结构及结构关系,在检索时能快速反应出所用数据表。其次掌握SQL的逻辑关系与表达方式,在查询之初能构建出较明确的E-R(实体-联系)模型,并能将E-R模型进行数据语言的转换,可以方便地实现不同主体数据的关系构建。本文始终使用SQL最基本的select语言,而未用union是为了方便读者进行体会。
使用结构化的查询语句是大数据时代的必备技能,随着DRGs的推广、国家与地市的三级公立医院绩效考核的相继推出,对医院的质量要求和管理要求提上了一个新层次。毋庸置疑,数据是医院考核的重要依据,而多元化的数据需求也是新时代医院管理统计服务工作必须面对的新挑战[6]。统计人员应该加强自身业务学习,将工作经验和数据技能相结合,以促进职业综合素质的提高。
