基于高通量测序Survey评估测定雷竹基因组大小
2021-02-14杨杰芳曾庆南王海霞
杨杰芳,甘 然,曾庆南, 程 平,王海霞
(江西省林业科学院,江西 南昌 330032)
雷竹(Phyllostachysviolascens‘Prevernalis’)是早竹的变种,因惊蛰出笋得名,又名雷打竹、打雷竹、燕竹、天雷竹等,笋期早、笋味鲜甜,深受市场欢迎。该竹种原产于浙江临安、余杭一带,当地有经营和食用雷竹笋的习惯,种植面积一度超6.7万hm2。近年来,随着劳动力成本不断攀升和林分退化,雷竹产业成功的向江西东北部转移,在赣东北地区已形成了7.3万hm2的稳定种植区[1]。雷竹在长期人工栽培过程中,种内产生了一定程度的遗传变异,形成了若干变异类型。目前,对其研究多在植株形态性状、竹笋产量或品质的测定等方面,较少涉及细胞学、生化以及分子生物学,分子生物学方面有运用RAPD、AFLP等标记研究雷竹不同变异类型间存在亲缘关系和遗传变异[2],但不同栽培类型可以区分,雷竹基因及其遗传多样性研究更是薄弱。为了更好的评价雷竹种质资源,对雷竹开展基因研究十分必要。
植物单倍体基因组内所含DNA的总量,称为基因组的大小,即C值。每个物种的C值是固定的,可用于评估植物的生物学特性,为其基因组和转录组学的研究提供依据,是比较和进化基因组学研究的基础。目前,测定基因组大小的方法众多,如流式细胞技术通过分析染色体组型信息推断其基因组大小,通过基因组跳槽分析预测基因组大小、重复序列及早合度等[3-5]。
研究采用低深度、高通量测序对雷竹基因组进行初步研究,采用K-mer法预测雷竹基因组大小、杂合度和重复序列等信息,为后续雷竹基因组测序和分析提供依据。
1 材料与方法
1.1 试验材料
试验材料来自于江西省林业科学院竹类国家林木种质资源库保存的细叶乌稍雷竹(弋阳种源),选取本年度新竹的嫩叶作为待测对象,于2021年5月10日采集,采集后及时放液氮内保存,带回试验室处理待测。
1.2 基因组DNA检测检
测前,先采用1%的琼脂糖电泳检测DNA样品是否有降解以及杂质;NanoPhotometer®分光光度计检测样品纯度(IMPLEN, CA, USA);Qubit® 2.0 Flurometer(Life Technologies, CA, USA)检测DNA样品浓度。
1.3 DNA的提取和文库构建
基因组调查由武汉古奥基因科技有限公司完成。检测合格的DNA样品通过Covaris超声波破碎仪随机打断成长度为300~350 bp的片段,用1ug gDNA模板,根据TruSeq DNA Sample Preparation Guide(Illumina,15026486 Rev.C)方法经末端修复、加A尾、加测序接头、纯化、PCR扩增等步骤完成整个文库制备。文库构建完成后,先使用Qubit 2.0进行初步定量,稀释文库至1 ng·μL-1,随后使用Agilent 2100对文库的insert size进行检测,insert size符合预期后,使用Bio-RAD CFX 96荧光定量PCR仪,Bio-RAD KIT iQ SYBR GRN进行Q-PCR,对文库的有效浓度进行准确定量(文库有效浓度>10 nM)。构建好的文库通过Illumina Hiseq进行PE(150)测序。
1.4 测序数据质控
测序数据的产生是经过了DNA提取、建库、测序多个步骤的,为减少无效数据对生物信息数据高级分析带来干扰,比如建库阶段长度的偏差、测序阶段测序错误等情况,测序过程中,通过以下方法过滤无效数据:
高通量测序(illuminanova 6000)得到的原始图像数据文件经碱基识别(Base Calling)分析转化为原始测序序列(Sequenced Reads),原始测序数据中会包含接头信息、低质量碱基、未测出的碱基(以N表示),这些信息会对后续的信息分析造成很大的干扰,通过精细的过滤方法过滤掉(Clean Data)含有接头序列的reads,去除由于PCR扩增等原因引起的duplicated reads,当单端测序read中的一端含有的N的含量超过该条read长度比例的 10% 时去除此对pairedreads;当单端测序read中的一端含有的低质量(<=5)碱基数超过该条read长度比例的 50% 时去除此对paired reads,得到有效数据。
1.5 K-mer分析
基于Clean Data,采用K-mer法对雷竹基因组大小进行估计。取K值为17,统计A、T、C、G4中碱基的K-mer值,根据Lander-waterman算法计算K-mer总数和深度,并据此统计K-mer频数分布、计算绘制K-mer曲线,根据曲线获得K-mer深度C值、预估基因组大小。
2 结果与分析
2.1 基因组DNA检测
Qubit检测DNA浓度为2 330.0 ng·μL-1,OD260/280=1.95、OD260/230=2.22、NC/QC=1.22,提取的DNA质量较好,基因片段长度97.03%集中在6 659-60 000 bp之间、峰值为59 475 bp(见图1),样本总量和质量均能满足建库要求。
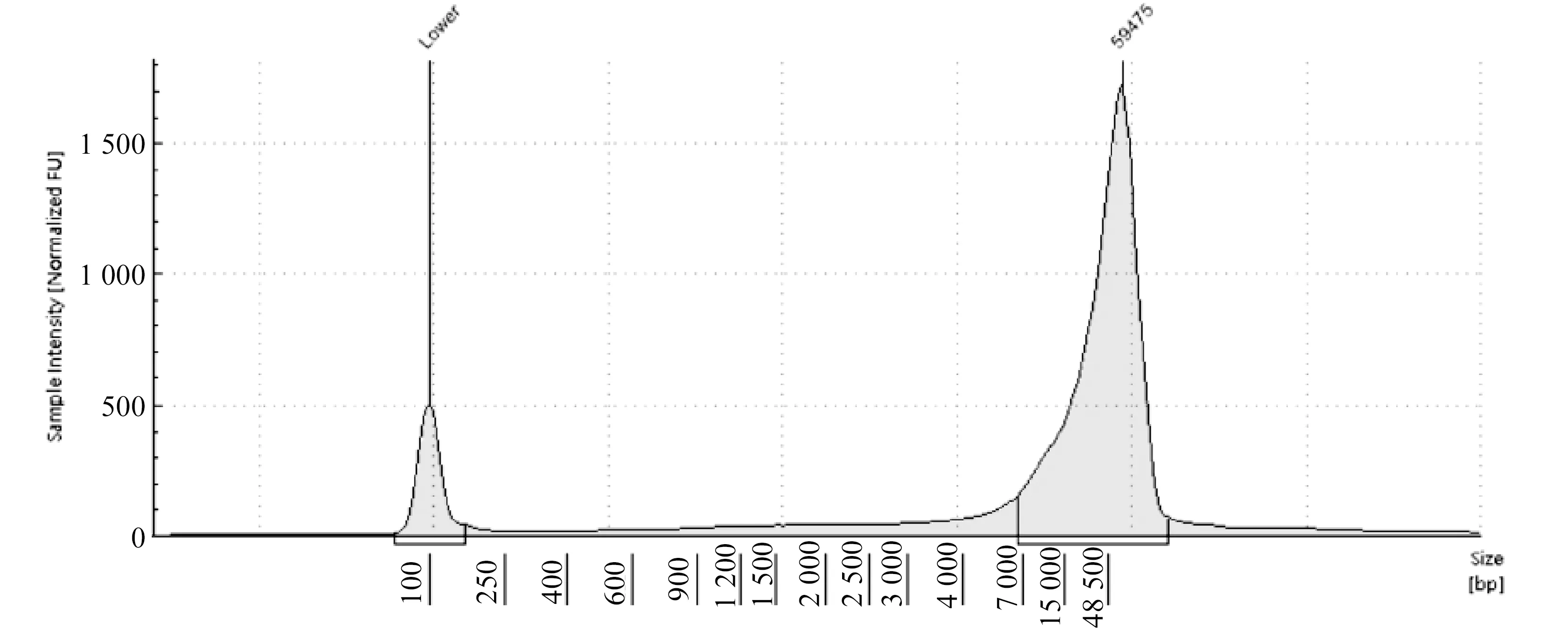
图1 雷竹基因电子电泳图Fig.1 Gene electrophoresis map of Phyllostachys violascens ‘Prevernalis’
2.2 基因检测及文库构建
研究采用二代Illumina Nova测序平台、双端测序获得长150 bp的小片段文库测序原始数据199.41 Gb,获得雷竹ReadNum 1 335 892 282条,Q20=97.89%,Q30=93.88%,说明剪辑测序准确度较高,满足后续数据分析要求。雷竹基因组测序数据中A与T、C与G的互补碱基数基本一致、位置碱基N为0,但由于前几个碱基测序质量较低、DNA模板扩增偏差等原因,导致每个Reads前几个碱基有较大波动,是正常现象(见图2)。GC含量呈现出单峰(图3)。同时,进行NT库对比(见表1),结果显示,雷竹基因比对到近源物种刚竹属毛竹(Ph.edulis)和禾本科水稻的DNA上,证明该文库数据中不含有明显的外援污染。

表1 雷竹样本的文库数据NT库比对
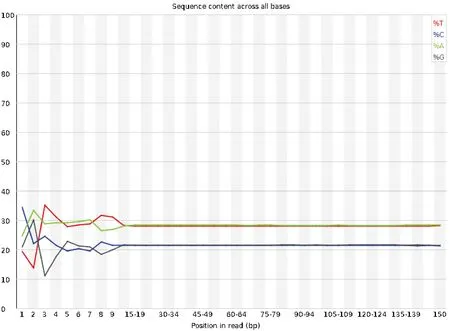
图2 碱基频率分布图Fig.2 Base frequency distribution

图3 GC含量分布结构图Fig.3 GC content distribution structure
2.3 K-mer分析
基于K-mer分析法来估计基因组的大小、杂合率及重复序列信息。取K=17,根据Lander-waterman算法、泊松分布法统计K-mer频数分布,进而计算获得K-mer深度分布曲线和深度乘积曲线,并根据曲线K-mer深度估计值c,估计雷竹基因组的大小。计算得到K-mer数为131 976 528 091,基因组大小约为1 913 Mb,修正后为1 897 Mb,杂合率为1.7%,重复序列比例为69.38%,详细情况见表1。

表2 雷竹基因组特征统计分析(K=17)
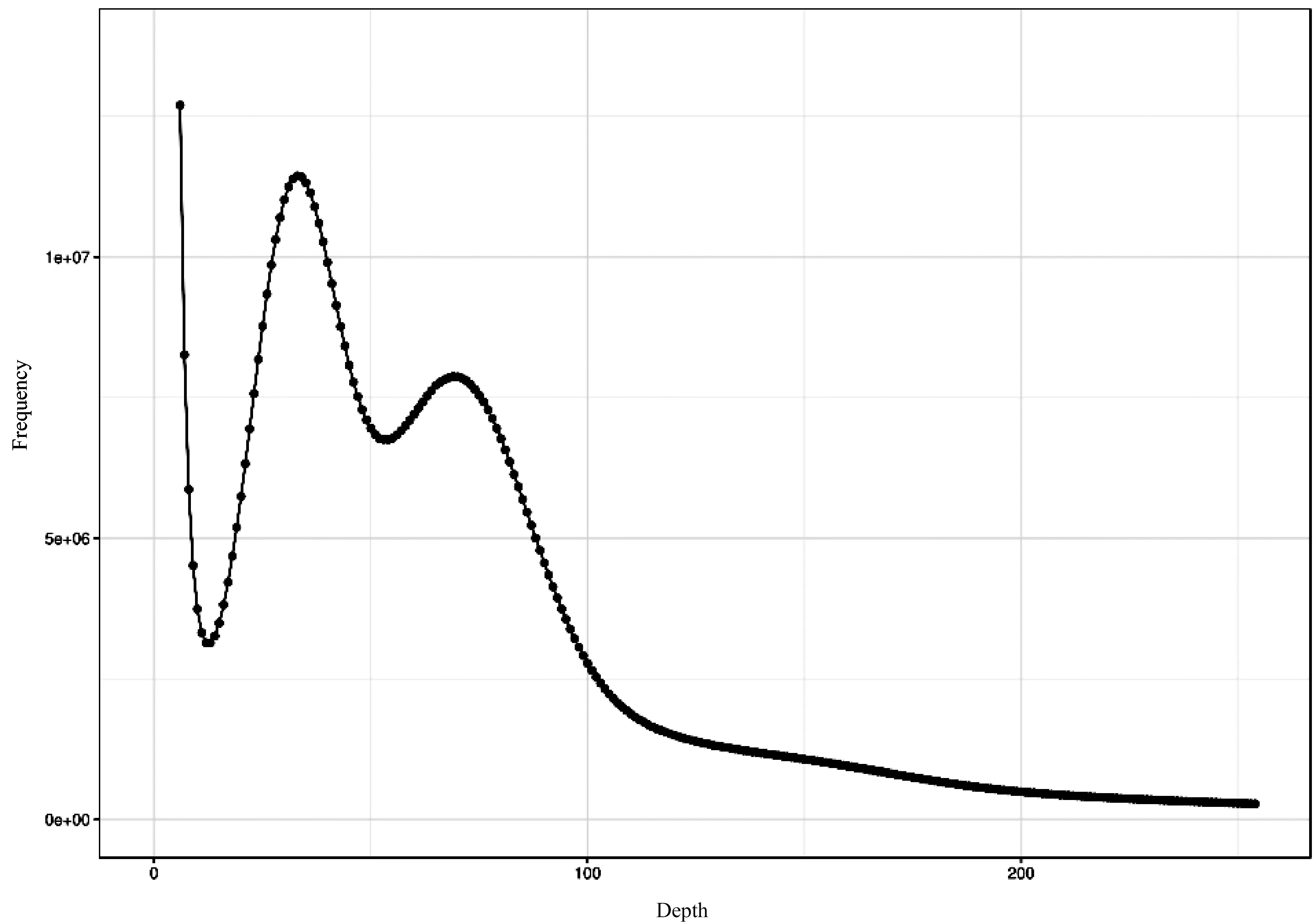
图4 深度和K-mer频率分布图Fig.4 Depth and K-mer frequency distribution
3 讨论
雷竹是禾本科竹亚科刚竹属植物,刚竹属是人类开发利用强度较高的竹类植物,雷竹则是近年来经济贡献较高的一个竹种,然而已发布的竹类植物基因组仍然较少。
高通量测序是一种精确的分析未知基因组的方法,研究采用高通量测序对雷竹基因组进行初步研究,结果表明雷竹基因组杂合度较高(1.7%),说明雷竹基因序列差异大,有性繁殖难度大,种群扩大很大程度上依赖于无性繁殖。同时,雷竹基因重复片段多(69.38%),属于复杂的植物基因组,基因组大小约为1 897 Mb,是水稻基因组的4倍多,全基因组数据量大,基因组装难度也相对较大。
加强雷竹基因组的研究,明确雷竹遗传资源的遗传基础,探明雷竹遗传资源的遗传多样性和亲缘关系,为雷竹遗传资源的保存、测定、评价、遗传育种和合理开发提供科学依据,是林下经济、竹笋产业发展的物质基础,对解决当前雷竹种质资源混杂和指导雷竹生产具有十分重要的意义。
