本地差分隐私频率估计研究综述
2021-02-04王广艺
王广艺,杨 庚
(1.南京邮电大学计算机学院、软件学院、网络空间安全学院;2.江苏省大数据安全与智能处理重点实验室,江苏南京 210023)
0 引言
频率估计是数据挖掘领域研究的一个基本问题,旨在计算特定数据项出现的频率,有助于云服务运营商了解客户端软件最新统计数据,检测恶意软件行为,也可应用于频繁出现的数据项(heavy hitter)查询、用户行为预测等。然而,如果直接采集用户信息,可能存在严重的隐私泄露隐患,攻击者可通过链接攻击、前景知识攻击等方式推测用户持有的数据项,不可信的第三方数据收集者也可能意外泄露用户敏感信息。如何高效地兼顾隐私保护与频率估计准确性是数据挖掘领域亟需解决的问题。
差分隐私(Differential Privacy,DP)[1]是一种基于数据扰动的隐私保护方法,具有严格的数学定义,可对隐私保护程度进行量化分析;同时,差分隐私无需考虑特殊的攻击假设,攻击者无法根据不同的输出判断记录是否在原数据集中。差分隐私分为中心差分隐私(Central Differential Privacy,CDP)和本地差分隐私(Local Differential Privacy,LDP)[2-4],因而针对频率估计问题的差分隐私算法包括CDP 频率估计算法和LDP 频率估计算法。
在传统CDP 频率估计中,数据管理员向数据库添加随机化噪声,发布查询结果。CDP 频率估计可与机器学习算法深度融合,如频繁项集挖掘、频繁序列挖掘、频繁子图挖掘等[5]。但是,由于数据存储系统安全性、用户对数据管理员的信任度等因素限制,CDP 频率估计在实际应用中存在较大局限。
为了应对CDP 频率估计存在的问题,Kasiviswanathan等[3]于2011 年正式提出LDP。LDP 直接在用户端扰动数据编码结果,将其发送至服务器,之后服务器进行统计查询。由于真实数据一直保留在用户设备端,服务器不需要承担隐私泄露的风险。LDP 具有轻量化的优势,在计算能力较弱的设备上也能轻松实现。目前LDP 频率估计已被应用于微软Windows10 操作系统[6]、小米MIUI 等以提升软件质量、改进用户体验。
但是,LDP 频率估计也存在通信成本较高、添加的噪声较多、依赖的用户规模较大和高维数据分析准确性较低等问题。针对这些问题,已有研究聚焦于如何进一步提高LDP 频率估计的实用性。现有方法主要分为三类,第一类是单值频率估计方法,如Rappor 算法[7]、HCMS 算法[8]等;第二类是泛化频率估计方法,如DE 算法、OUE 算法、OLH算法等[9];第三类是集合数据频率估计方法,如LDPMiner算法[10]、SVSM 算法[11]、PrivSet 算法[12]等。本文着重介绍LDP 在这3 种频率估计中的应用,深入分析不同算法性能,对下一步研究工作进行展望。
1 LDP 频率估计基础知识
1.1 本地差分隐私
LDP 是一种强隐私保护方法,该技术可收集单个随机答案,给予用户一定的可否认性,也使数据收集者免于隐私泄露的风险。同时,通过分析大量该类随机数据,数据收集者仍可建立准确的统计模型。
定义1 ε-本地差分隐私[4]。给定算法M,定义域为Domain(M),值域为Range(M)。M满足本地差分隐私,当且仅当对任意一对输入t和t’(t,t’∈Domain(M)),成立不等式为:
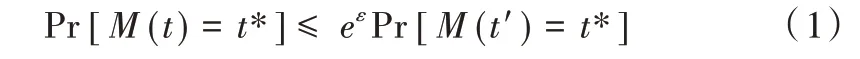
其中,t*⊆Range(M)。ε(ε>0)称为隐私预算。ε越小表示隐私性越好、可用性越差。
差分隐私有3 个重要特性:①序列组合性[13]。给定z个隐私算法{f1,f2,…fz}和数据集D,执行在D上的fi满足εi(1≤i≤z)-差分隐私,则z个算法组合算法满足∑iεi-差分隐私;②并行组合性[13]。将数据集D分成z个不相交的子集,D={D1,D2,…Dz},执行在每个子数据集上的算法满足εi(1≤i≤z)-差分隐私,则整个算法满足max{εi}-差分隐私;③后期处理的影响[14]。对差分隐私算法的结果作后期处理,则算法仍满足差分隐私,且隐私保护水平与原先算法保持一致。
CDP 具备这3 条性质,LDP 兼具第1、3 条性质。LDP没有直接的并行组合性,因为每个用户只有1 条记录,不能被切分。
定义2 敏感度[14]。敏感度是差分隐私中的1 个重要概念。对于任意1 个函数function:D→Rd,敏感度Δ(func⁃tion)定义为:
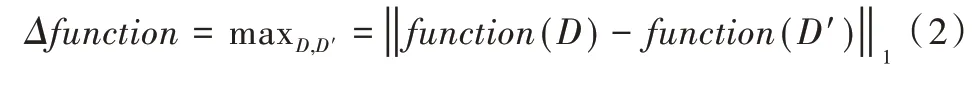
R表示映射的实数空间,d表示函数function的查询维度,D和D’是任意两个邻近数据集(D和D’差别至多为1个记录)。
1.2 LDP 频率估计
LDP 频率估计指为用户提供LDP 保护的同时确定数据项频率的过程。给定数据集D={v1,v2,…vn},对任意元素v∈D,算法f的目标是以满足LDP 的方式计算v出现的频率。算法f主要分为3 步:①将用户值编码成1 个向量或1 个数;②在用户端扰动编码结果;③服务器解码聚合和校正。随机响应[15]是算法f采取的主流扰动机制,确保数据集在输出信息时受单条记录的影响始终低于某个阈值。针对随机响应举例如下:当回答1 个二值问题时,回答者秘密地抛掷一枚不均匀的硬币(正面朝上的概率为Pr,反面朝上的概率为1-Pr,Pr>0.5)。若正面朝上,回答真实答案;若反面朝上,回答相反答案。根据LDP 定义,eε=Pr(/1-Pr)。
差分隐私还具有隐私增益性[16]。在设计自适应频率估计算法时,隐私增益性是否成立是算法选择的重要指标。隐私增益性表示通过使用更小的采样率,使算法达到更高的隐私保护水平。具体而言,将差分隐私算法f应用到数据集D,利用采样率β(β<1)从原始数据集中获得D。为满足ε-LDP,算法f可使用更大的隐私预算ε’(ε’>ε)。ε’与ε的关系如式(3)所示。

该性质成立与否取决于算法f的内部结构。
1.3 频繁项集挖掘
频繁项集挖掘是数据挖掘领域的一项重要技术,旨在找出频繁出现在事务数据集中的项集[17]。设D是事务数据集,D={D1,D2,…Dn},D中数据项的集合I={item1,item2,…itemsize},Di⊆I(1≤i≤n)。设非空集合set⊆I,则称set为1个项集。set的支持度是D中包含set的事务计数。若set的支持度大于预定义阈值λ,则称set为频繁项集。频繁项集具有极重要的单调性:频繁项集子项集一定是频繁的,非频繁项集的超集一定是非频繁的。
频繁项集挖掘的经典算法包括Apriori 算法[18]、FPGrowth 算法[19]和Eclat 算法[20]。Apriori 算法通过限制产生候选项集挖掘频繁模式,FP-Growth 算法借助频繁模式树发现频繁项集,而Eclat 算法采用倒排思想。
项集填充采样是频繁项集挖掘过程中常用方法[10]。首先指定长度参数len、项集itemset、额外项集合dummy={i1,i2,…ilen},对任意i∈dummy,i∉I。额外项在计算频率时忽略不计。若项集长度|itemset|<len,则从dummy中随机挑选len-|itemset|个不同的项添加到itemset中;若|itemset|>len,则从itemset中均匀采样len个项构成新项集,如果itemset无序,可直接截断。将itemset长度统一转化为len后,从itemset中均匀采样单个数据项输出,记输出项为v。
2 LDP 频率估计性能分析
尽管LDP 频率估计为用户和数据收集者提供了很强的隐私保证,但是LDP 是以最严格的假设为基础,即假设攻击者拥有最大背景知识,而这在实际情况中十分罕见。由于LDP 对隐私性的保护过于严格,这在很大程度上影响了结果可用性。在许多应用中,LDP 频率估计也暴露出一些问题,如通信成本较高、随机化噪声较多、依赖数据量较大和高维数据分析准确性较低等,因此,LDP 算法应当再三权衡隐私性、可用性、数据量的关系。
受限于用户设备的网络和电量等因素,LDP 频率估计应当维持合理的通信成本。然而,LDP 在用户端对数据的编码结果通常为1 个向量,为了提高频率估计的准确性,用户端应当发送尽可能多的坐标。此外,在LDP 频率估计中,用户可能需要参与多个查询任务,用户和服务器之间会进行多次通信。上述方式将增加通信成本。当用户记录是高维数据时,通信代价也较高。
由于在CDP 中敏感度是常数,所以CDP 噪声为Ω(1)。然而,在LDP 中,任意两个用户不知晓对方的记录,因此,LDP 不存在全局敏感性的概念。LDP 对每个用户数据都添加噪声,扰动结果被发送至服务器。即使每个用户的随机化噪声均为常数,服务器聚合结果的噪声也会达到Ω(n0.5)(n为用户个数)。因此,LDP 和CDP 相比,添加的随机噪声较多,这导致准确性较差。
在设计LDP 频率估计算法时,为了抵消正负向噪声,服务器需聚合大量的扰动结果,该方法需要较大的数据量。然而,在网络空间安全等领域,用户规模较小是常见现象。例如,当一位信息安全工程师正在分析针对特定漏洞的恶意软件行为时,只有受到恶意软件感染的用户的观察报告才有意义,但由于恶意软件的针对性,受感染的用户数量可能很少。由于用户规模无法达到LDP 依赖的数据量大小,这会导致统计值与真实结果之间的偏离程度更为明显。
当用户记录是高维数据时,即每条用户记录包含多个数据项,一个直观的解决方案是分割隐私预算,多次调用LDP 算法分别采集每个位置数据项,利用差分隐私序列组合性使算法满足LDP。然而,由于数据高维性,该方案致使每个数据项分配到的隐私预算很少,这降低了查询准确性和查询效率。
3 频率估计中的本地差分隐私保护方法
LDP 频率估计需要解决上述性能分析问题,但是目前LDP 频率估计方法仍然不能达到这一目的,所以更多的科研人员重点研究怎样为频率估计提供更可靠的LDP 保证和更高的查询准确性。这些研究主要包含3 类方法:单值频率估计方法、泛化频率估计方法和集合数据频率估计方法。本文将分别讨论这3 种类型的LDP 方法在频率估计中的应用。
3.1 单值频率估计
单值频率估计指每个用户只有一个数据项,用户将自身数据编码加噪后发送至服务器,服务器会根据候选项集合分析大量随机数据,建立统计模型。单值频率估计主要采用的技术包括哈希函数和矩阵变换,这两种技术可以在降低通信成本的前提下获得合理的统计准确性。谷歌Rappor 算法[7]、苹果CMS 算法[8]和HCMS 算法[8]均应用了哈希函数技术,其中HCMS 算法还应用了矩阵变换技术。
3.1.1 Rappor 算法
Rappor 算法将随机响应与布隆过滤串[21]结合。设布隆过滤串B(也称比特串)的长度为k,哈希函数个数为h。用户首先使用布隆过滤器将v映射到B,然后使用扰动机制对B添加噪声。扰动过程分为永久随机响应和瞬时随机响应。记永久随机响应的结果为B’,B’在用户端被缓存,用户每次使用真实数据时B’会代替B,这样即使用户值被报告多次,攻击者也无法推断出用户真实答案。给定概率参数r,对于B中每个坐标i,有:
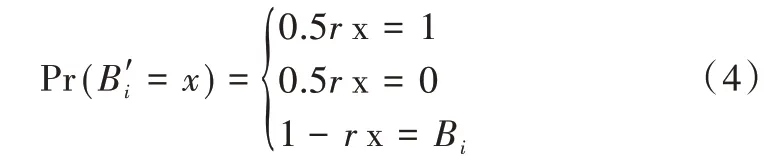
记瞬时随机响应的结果S=(s1,s2,…sk),初始化S为0,指定概率参数p、q,则:
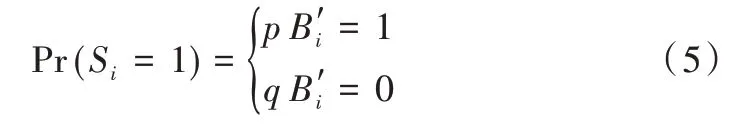
用户发送S。
永久随机响应满足ε1-LDP,其中,
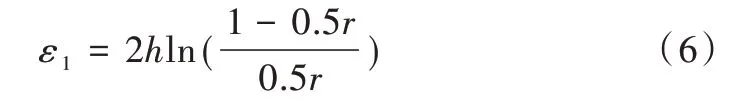
在式(6)中,若不考虑布隆过滤器,如果1 个比特串长度为1,Pr(0|0)=Pr(1|1)=1-0.5r,Pr(1|0)=Pr(0|1)=0.5r,则此时隐私保护程度为ln((1-0.5r)/0.5r)。再经过布隆过滤后,每一个原始值被映射到的比特串中最多有h个1,对于两个原始输入,它们的比特串最多只有2h位不一样。因此,式(6)中隐私保护程度需乘以2h。
瞬时随机响应的结果依赖p,q,r。
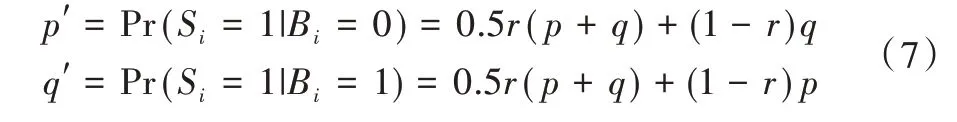
瞬时随机响应满足ε2-LDP,其中,
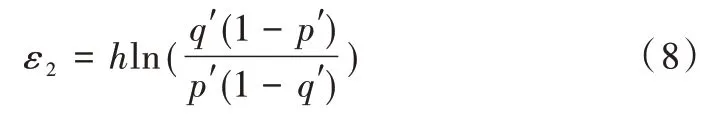
为了降低哈希函数冲突概率,每个用户被随机分配到1 个组中。假设有num个组,用户在发送数据时需说明自己属于哪个组。由于每个用户组在布隆过滤器中使用不同的哈希函数,若num太小,则分组很可能造成哈希函数值碰撞;若num太大,每个组用户数会很少,这导致频率估计中误差较大。
现以1 个具体应用案例说明服务器端解码过程。假设词库中只有单词1、单词2 和单词3,对应布隆过滤串分别为10 001 000、01 000 010 和00 010 010。服务器需要统计词库中每个单词出现的次数。用户将经过永久随机响应的比特串保存在本地。用户每使用1 次单词,就经过1次瞬时随机响应把比特串发送至服务器。假设单词1 出现两次,单词2 和单词3 出现1 次,对应比特相加得到比特串bitString=21 012 020。
服务器的目标是确定bitString,它采集每一个比特上1的总数(一共有k个比特)。由于每个比特相互独立,服务器可先只分析1 列。设第i个比特有w个1,n-w个0(n为用户个数),服务器平均收到的1 的个数为count。
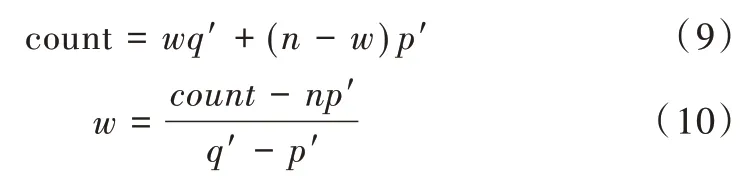
服务器通过式(10)估计原始值中每个比特1 的个数,本例中,服务器计算得到bitString=21 012 020。由于每个用户组哈希函数公开,服务器了解每个单词对应的布隆过滤串,结合bitString计算出单词1 出现两次,单词2 和单词3 均出现1 次。此外,服务器还需借助假设检验、最小二乘法和LASSO 回归进一步拟合词频。Rappor 算法中的哈希函数导致服务器端复杂的解码过程,而且哈希函数值碰撞问题依然存在。
3.1.2 CMS 算法
用户从哈希函数集合{h1,h2,…hk}中均匀采样1 个哈希函数,将项v散列到输出域中的1 个数,结果用长度为m的向量vector单热编码表示(散列结果对应坐标置为1,其余坐标为0)。用户对向量中的每个坐标以概率Pr作真实回答,以概率1-Pr作相反回答。用户将哈希函数索引与向量发送至服务器。此时vector 只有一个坐标为1,敏感度为2,所以为满足差分隐私,Pr取值为:

服务器使用所有来自用户的向量构建k×m的矩阵Matrix。每当1 个向量到达服务器,服务器将向量添加到Matrix的第j行(j为哈希函数索引)。服务器取出Matrix[j,hj(v)](1≤j≤k)并计算均值。
3.1.3 HCMS 算法
HCMS 算法首先类似CMS 算法,用户得到向量vector。设H为哈达玛基变换矩阵,vector’=H·vector。vector’中的每个坐标取1 或-1。用户从vector’中随机采样1 个坐标,对该坐标以概率eε/(1+eε)作真实回答。用户将哈希函数索引、vector’采样索引、坐标值发送至服务器。
服务器使用来自用户的报告值构建矩阵Matrix。Ma⁃trix的第(j,index)个元素聚合了用户使用哈希函数hj与采样索引index的坐标值。服务器使用哈达玛矩阵的逆矩阵对Matrix作矩阵变换,最后计算Matrix[j,hj(v)](1≤j≤k)k个元素的均值。
HCMS 算法中的矩阵变换与Rappor 算法中的哈希函数功能类似,可降低通信成本,但是在编码过程中也会造成额外的信息损失。
3.2 泛化频率估计
为了比较同等隐私保护水平下不同单值频率估计算法计算复杂度、查询准确性和通信成本,需将单值频率估计推广到一般情形。泛化频率估计的核心问题是设计合适的扰动机制。扰动的目的是保证得到频率的无偏估计,同时尽可能减小统计值方差。该问题的主要挑战是减小高维数据带来的影响。
Wang 等[9]提出了一个泛化频率估计机制:pure LDP。pure LDP 首先定义函数Support,Support(y)表示通过y可以确定出现的用户值构成的集合。定义概率p*、q*为:
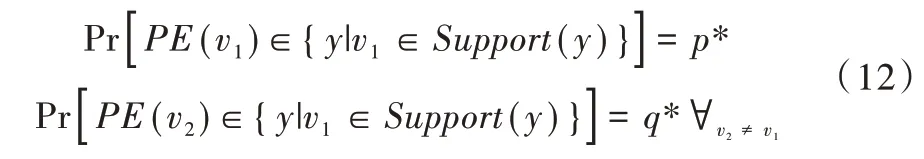
PE是编码扰动函数,{y|v1∈Support(y)}是v1的支持集合。p*表示任意值v1被映射到v1的支持集合的概率,q*表示任意其他值被映射到v1的支持集合的概率。当且仅当存在概率p*和q*,p*>q*时,机制pure LDP 成立。为了满足ε-LDP,q*>0,p*/q*≤eε。
在pure LDP 中,假设共有n个用户,元素i出现的真实次数为c(i),可通过式(14)计算c(i)的无偏估计。
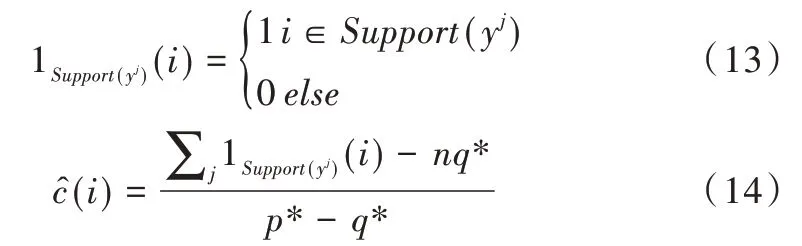
其中yj是用户j发送的值。
文献[9]得到了3 种效果较好的扰动方法:DE、OUE、OLH,具体描述如下:
DE 算法:设用户值为v,项空间大小为|I|。扰动公式为:
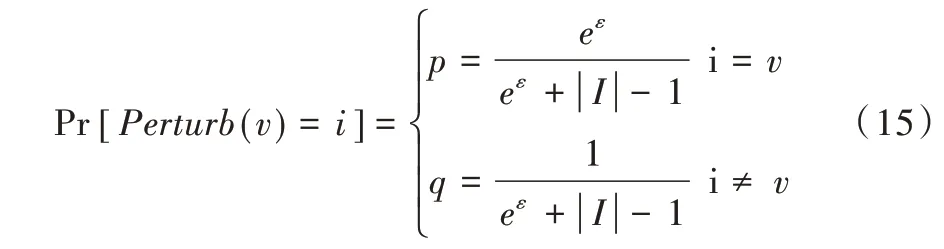
此时Support(i)={i},p*=p,q*=q。
OUE 算法:用户项被单热编码成向量B。扰动公式为:
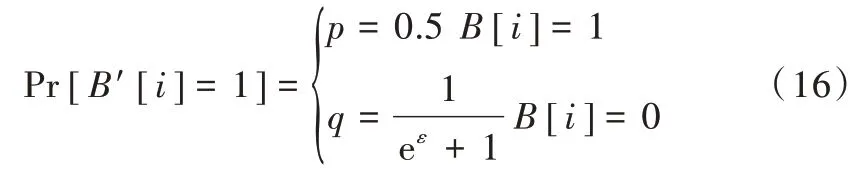
因为eε=(p(1-q))/((1-p)q),所以可作如下变换,ε=ε1+ε2,eε1=p/(1-p),eε2=(1-q)/q。ε1和ε2分别是传送比特1与比特0 消耗的隐私预算。由于向量中只有1 个坐标为1,因此,用户在发送比特0 时应该分配更多的隐私预算。在极端情况下,令ε1=0,ε2=ε,可得到p和q的最优值。OUE 的支持函数Support(B)={i|B[i]=1},p*=p,q*=q。
OLH 算法:设H为哈希函数集合,用户从H中均匀采样得到函数function,function将用户值v映射到[g]={0,1,…g-1}中的一个元素b,其中g≥2。OLH 的信息损失包含两个方面:编码阶段的信息损失与差分隐私扰动引起的信息损失。当g较大时,LDP 频率估计算法在编码阶段可保留更多信息,在随机响应时则损失更多信息。通过对估计值方差求偏微分,OLH 算法得到g的最优值为。扰动公式为:
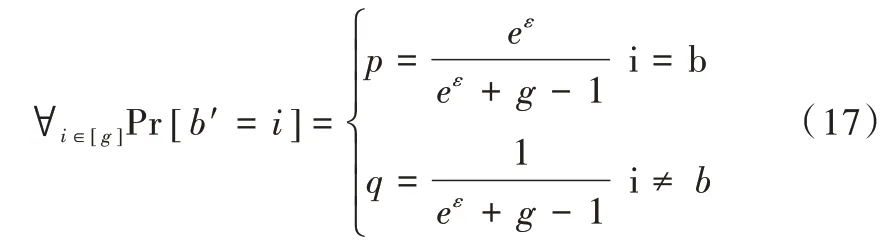
该方法的支持函数Support(<function,b’>)={i|function(i)=b’},p*=0.5,q*=1/g。
DE 在|I|较小时估计更准确。当|I|较大时,OUE 和OLH表现更好且准确性一致。OUE 计算成本低,通信成本高。OLH 通过应用哈希函数降低了通信成本,但同时增加了计算复杂度。
为了满足LDP,添加的噪声可能导致许多项的估计频率小于0。此外,LDP 算法可能导致频率总和不等于1。Wang 等[22]指出服务器可以利用非负性(所有项频率均大于等于0)和规范性(频率总和为1)这一事实提高频率估计准确性。算法利用先验分布时,估计会偏向先验分布。还考虑了多种利用先验分布的算法,这些算法中有的只要求频率满足非负性,有的只要求频率满足规范性,有的要求两个性质均被满足。但是引入概率先验分布又会带来其它问题。例如,将所有负估计值改为0 可提高个别频率估计值准确性,然而引入的正偏差会累积到范围查询中。
Jiang 等[23]研究了本地信息隐私(Local Information Pri⁃vacy,LIP),LIP 对敌手的背景知识建模,利用概率先验分布设计隐私保护机制。LIP 所需噪声取决于隐私预算与数据先验分布。LIP 根据先验分布计算扰动参数。当数据值相当确定时,翻转该值概率较小;当数据值发生概率较小时,LIP 通过较大的扰动概率保护其隐私。因此,LIP 得到了比LDP 更高的可用性。其构建了1 个通用机制估计收集到的数据项,该机制将估计值均方差最小化,可被视为随机响应的一般形式。
现有LDP 机制往往以相同的方式扰动数据,或对输入添加相同大小的噪声。然而,在许多实际场景中,不同的输入具有不同程度的敏感性,因此,用户需要不同级别的隐私保护水平。Gu 等[24]设计了输入判别隐私保护算法,以反映不同输入的隐私要求,并首次提出输入判别本地差分隐私(InputDiscriminative Local Differential Privacy,IDLDP)的概念,设计了基于一元编码的IDUE 算法,通过求解最优化问题计算扰动概率。由于输入判别保护的存在,IDUE 算法实用性更高。
已有研究主要目标是提高输出结果可用性,DP 算法安全性被忽略。Cao 等[25]研究了针对LDP 频率估计的数据投毒攻击。其研究表明为了根据攻击者的需要操纵数据分析结果,攻击者可注入虚假用户,虚假用户将伪造的数据发送至服务器。不同的LDP 频率估计算法对投毒攻击有不同的安全级别。例如,OUE 和OLH 对投毒攻击具有相似的安全级别;当项数目大于阈值时,DE 的安全性低于OUE 和OLH。该研究还设计了两种对策防御投毒攻击。在第1 个对策中,服务器对项频率的概率分布建模,要求项估计频率满足非负性和规范性。由于投毒攻击是通过虚假用户伪造数据,所以虚假用户的数据可能遵循与真实用户数据不同的模式,因此,在第2 个对策中,服务器通过分析用户数据统计模式检测虚假用户。但该研究未涉及如何将投毒攻击推广到LDP 频繁模式挖掘。
3.3 集合数据频率估计
集合数据频率估计研究的是当每条用户记录中包含多个数据项时如何进行数据发布。集合数据频率估计包括heavy hitter 查询、频繁项集挖掘、数据项分布估计和高维数据分析等。不同于单值频率估计,集合数据频率估计通常需考虑隐私预算分配问题。
heavy hitter 查询目的是发现频率高于给定阈值的项。由于每个用户数据项个数不同,因此,该问题具有挑战性。针对该问题,Qin 等[10]设计了LDPMiner 算法。LDPMiner使用填充采样技术,若用户端不填充项集,则很难计算单个数据项被采样的概率,服务器也很难对频率进行准确估计。
设每个用户ui的数据集合为vi,长度参数为len,用户数为n,项空间大小为d,第j个项出现次数为cj,则
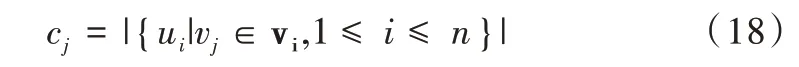
服务器需确定top-k频繁项及其对应频率。
LDPMiner 包含两个阶段:
阶段一:用户使用len对事务填充采样得到v,使用一半的隐私预算对v进行扰动,将扰动结果发送至服务器。服务器确定估计频率最高的2k个项,构建候选项集合IC,将IC广播给用户。
阶段二:用户计算IC与事务的交集,使用取值为2k的长度参数对交集填充采样得到v,使用一半的隐私预算对v进行随机响应,将扰动结果发送至服务器。服务器需将候选项统计计数乘以2k。
因为两个阶段均满足差分隐私,根据差分隐私的序列组合性,LDPMiner 满足ε-LDP。LDPMiner 的缺点是只能确定频繁项,不能挖掘频繁项集。
目前已有多篇文献研究了CDP 频繁项集挖掘[26-28],但是针对LDP 频繁模式挖掘问题的研究很少。Wang 等[11]设计了heavy hitter 查询算法SVIM 与频繁项集挖掘算法SVSM,发现GRR 算法(即前文所述的DE 算法)具备隐私增益性,而OUE 算法和OLH 算法不具备该性质。依据该性质,Wang 等设计了自适应频率估计机制Adaptive。Adaptive 机制可根据隐私预算ε、项空间大小d、长度参数len选择合适的频率估计算法。
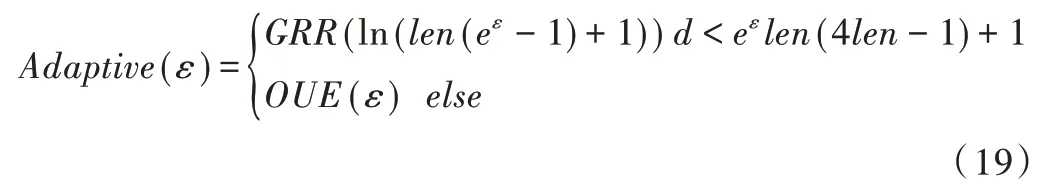
其中,GRR 和OUE 括号里的参数表示算法被调用时实际使用的隐私预算。
不同于LDPMiner 采取分割隐私预算的策略,SVIM 算法将用户分成3 组,每组用户参与1 项查询任务。SVIM分成3 个阶段:
阶段1:第1 组用户使用取值为1 的长度参数对事务填充采样得到v,使用Adaptive 机制报告v。服务器统计频率最高的2k个项,构建频繁项候选集合IC,把IC广播给下一组用户。
阶段2:第2 组用户首先计算事务与IC的交集,之后使用Adaptive 机制报告交集大小。服务器计算len(保证90% 的交集长度不大于len),之后将IC和len发送至下一组用户。
阶段3:第3 组用户求事务与IC的交集,使用len对交集填充采样得到v,通过Adaptive 机制报告v。服务器计算IC中每个项的频率,得到top-k频繁项及对应频率。
频繁项集挖掘的挑战是如何减小频繁项集候选集合大小。SVSM 算法将用户分成5 组,对应该算法5 个阶段,前3 个阶段的算法流程和SVIM 一致。
阶段4:记top-k频繁项构成的集合为topKS。服务器根据topKS构建频繁项集候选集合:生成topKS所有子集,在生成过程中,一旦发现子集长度大于,则直接丢弃该子集。因为若子集长度大于,该项集非空子集个数会大于k,而子集支持度大于等于项集支持度,所以该项集不可能是频繁项集。对topKS的一个子集X而言,服务器使用式(20)估计X频率。
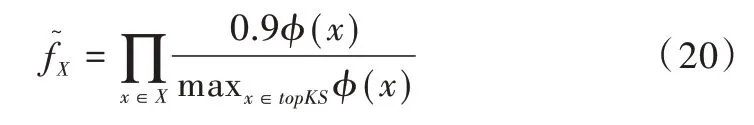
其中Φ(x)是项x的频率。服务器选择频率最高的2k个子集构成频繁项集的候选集合ISC,把ISC发送至下一组用户。第4 组用户寻找同时在事务和ISC中的项集,满足条件的项集构成集合vs,使用Adaptive 机制报告vs大小。服务器计算len,之后将ISC和len发送至下一组用户。
阶段5:第5 组用户寻找同时在事务和ISC中的项集,满足条件的项集构成集合vs。vs是集合的集合,但同样可采用类似填充采样的方法获取vs中的项集v。用户使用Adaptive 机制报告v。服务器对ISC中的每个项集计算频率,将频率乘以校正因子以提高估计准确性。由此,服务器得到top-k频繁项集。
由于猜测频率,SVSM 算法统计误差变大。填充长度的选择是主观的,目前没有理论支持。如何自适应地选择合理的填充长度依然是一个亟待解决的问题。
Wang 等[12]设计了一种集合数据聚合算法:PrivSet。PrivSet 可帮助服务器统计分析集合数据(如数据项的分布估计、集合大小的分布估计)。在PrivSet 算法中,每个用户独立使用差分隐私指数机制[29]输出元素定义域的1 个子集,该过程不需要分割隐私预算。根据元素定义域大小、集合中的最大项目数和隐私预算等参数校准输出子集的大小及其输出概率。为了解决集合异构性问题,PrivSet 算法将填充项添加到集合数据中。有了这些填充项,服务器可估计用户集合大小分布,该估计过程不会造成额外的隐私损失。
Wang 等[30]研究了LDP 高维数据分析问题,指出当用户记录同时包含数值属性和分类属性时,服务器可分别对集合中的数值属性与分类属性进行均值估计和频率估计。值得注意的是,一旦用户端使用单热编码将某个分类属性编码成长度为total的向量(total为该属性所有取值情况的个数),求解频率估计可以转化为求解均值估计。提出了分段机制PM 和混合机制HM,并将PM 和HM 扩展到多维数据中。该方案可用于传统机器学习(如线性回归、逻辑回归和SVM 分类),但目前尚不清楚如何将其应用于更深层次的数据分析任务(如深度神经网络)。
4 未来挑战
当前已有一些综述性文献针对LDP 的发展方向问题进行了研究。如文献[31-32]主要关注机器学习中的本地差分隐私保护;文献[33]主要侧重于LDP 在安全车联网中可能的应用方向;文献[34]介绍了LDP 空间数据采集问题;文献[35]总结了LDP 频率估计的主要问题,包括统计准确性问题、数据安全性问题、计算复杂度问题和通信成本问题。针对LDP 频率估计的现有解决方案只能在一定范围内、一定条件下取得理想效果。与CDP 相比,LDP 是一个相对较新的研究领域,而且由于LDP 的性质独特,科研人员仍面临不少挑战。
(1)融合CDP 和LDP 的优势难度很大。现有差分隐私文献通常将CDP 和LDP 分开考虑,但这两种隐私保护模型并不是对立关系。融合CDP 和LDP 可以允许用户在本地添加少量噪声,同时实现较高级别的隐私保护程度。然而,该操作涉及安全混洗和复杂的数学推导证明。安全混洗通常是黑盒模型,缺乏具体的实现方法。文献[36]设计了混合差分隐私方案以查询heavy hitter,计算Web 搜索日志中最流行的记录。该方案对内测用户和普通用户分组分别应用不同的隐私保护模型,提高了输出结果可用性,但需要付出额外的预处理成本以划分信任关系。
后续研究需继续关注如何更好地实现CDP 和LDP 的优势互补。例如借助密码学原语和非串通的服务器,使隐私保护频率估计能够提供近似CDP 的准确性保证,同时类似LDP 不依赖可靠的第三方数据收集者。
(2)自适应分配隐私预算方法不足。当用户记录是高维数据或用户参与多个查询任务时,算法通常需分配隐私预算。隐私预算分配决定了差分隐私随机化噪声,影响隐私保护水平和结果可用性。若隐私预算分配次数较多,会迅速增加噪声,导致数据可用性急剧下降。因此,LDP 频率估计需优化隐私预算分配。然而,由于许多LDP 算法创新点与隐私预算分配无关,它们通常将隐私预算均匀分配。
在CDP 中,王璇[37]利用泰勒级数、p级数、特殊级数分配隐私预算,减小了噪声增量速度,分析比较了不同隐私预算分配方案的优缺点。研究人员可以考虑在LDP 中运用级数知识自适应分配隐私预算,观察频率估计算法性能可否进一步提高。
(3)高维数据隐私效用权衡依然困难。LDP 高维数据分析取得隐私效用权衡是十分困难的。已有方法主要利用哈希函数[7,9]、矩阵投影[8,38](如哈达玛矩阵、正交矩阵)处理该问题,但是现有方法主要聚焦于单值频率估计。当算法处理集合数据时,通常采样1 个或几个数据项并将数据项发送至服务器。采样可减小通信代价,但势必导致统计准确性降低。
未来可进一步关注LDP 高维数据统计方法,主要考虑两个方面的问题:如何提高集合数据采样效率和统计精度;如何借助数据项间的关联进行降维,平衡查询准确性与通信开销。
(4)缺乏实时数据发布方法。用户数据可能随时间发生变化,需服务器每隔一段时间重新计算统计值。现有LDP 频率估计方法主要关注静态数据,而许多现实场景要求数据发布方法具有连续数据发布能力。在发布每一次数据的过程中,服务器很难预知后续需发布的数据。每次发布数据均会累加噪声方差,最终降低了数据可用性。因此,服务器需提高LDP 频率估计连续数据发布的精确性和效率,满足大规模连续数据发布的要求。在LDP 中,针对该问题的主要方法是缓存技术,然而当数据频繁发生改变或数据变化剧烈时,缓存技术失效。
LDP 实时数据发布需考虑两种变化情况:①用户个数如何变化;②用户数据如何变化。同时,科研人员可使用滑动窗口模型[39]、自适应隐私预算分配、用户动态分组等方法改进扩展LDP 连续数据频率估计算法。
5 结语
随着移动智能设备计算能力和存储能力的不断增强,众包数据采集和数据挖掘技术迅速发展。同时个人隐私问题成为用户关注焦点,隐私问题极大限制了数据挖掘在工业中的应用。因此,设计保护个人隐私的数据发布框架具有重要意义。
LDP 作为一种新兴的隐私保护模型,可同时保护用户隐私和服务器隐私,成为信息安全领域研究热点。由于当前LDP 频率估计方法依然存在许多问题尚未解决,科研人员需继续深入研究本地差分隐私保护,促进数据挖掘技术在实际应用中进一步发展。
