矩阵分解技术在电影推荐系统中的应用
2021-02-04蔡崇超许华虎
蔡崇超,许华虎
(1.上海大学计算机工程与科学学院,上海 200444;2.湖州职业技术学院物流与信息工程学院,浙江湖州 313000)
0 引言
为解决社交网络信息过载问题,需引入用户或内容推荐系统。传统的推荐系统以协同过滤算法为主,该算法没有考虑到社交网络中不同用户之间的关联关系对推荐结果的影响。并且,在社交网络研究过程中发现,大多数用户对于内容的评论较少,绝大多数内容由少数人产生,即存在着稀疏矩阵问题。
本文主要研究基于社交网络关系的推荐系统在电影领域的应用情况。随着移动互联网在人们日常生活中的全面渗透,互联网公司往往应用千人千面技术增加用户粘度,在影视领域这种情况更加普遍。
相比而言,电影点评推荐相关研究开展得较早。目前,在推荐系统领域较为成熟的电影数据集有很多,例如movielens[1]、Netflix[2]、Douban[3],以上都是推荐系统较为常用的数据集,本实验主要在Douban 和Netflix 上进行。
协同过滤推荐算法[4-5]在电影推荐领域较为常见,该算法通过记录用户行为预测用户喜好,进而完成电影推荐任务。王骏等[4]通过改进神经协同过滤模型,利用多层感知机的非线性特征处理提取隐含高阶特征信息以及贝叶斯个性化排序算法提取排序信息,使推荐更加精准,但是该方法忽略了社交网络中用户之间关系的影响力。随着社交网络的兴起,用户之间有了更加复杂的关联关系,这使得单纯的协同过滤算法推荐精度有所下降。
在社交网络中用户之间的社交关系和用户发布的内容往往有很强的关联性[6-7],人们总是倾向于关注与自己兴趣点近似的人群。Koren 等[2]首次将矩阵分解技术引入电影推荐系统中,不过其当时的数据集较小,同时仅仅将其应用到了一个数据集,本文实验扩展了Koren 等的数据集规模。肖晓丽等[3]通过引入信任机制,通过定义直接信任、间接信任、传递路径和计算方法度量社交网络用户之间隐含的信任值,将社交网络转换为信任网络,为推荐系统中基于用户关系提升推荐精度提供了理论依据。
本文的创新之处在于,传统的电影推荐系统主要以协同过滤算法推荐为主,很少将社交网络信息作为重要参考,本文通过矩阵分解技术[2,8-9]设置特征参数、损失函数、随机梯度下降等方法对推荐系统的精度进行改进,同时融合社交网络用户信息关系,进而提升推荐系统精度。由实验结果可知,在两个实验数据集上精度分别提高62%、51%。
1 相关问题
社交网络是一个巨大的实时信息传播平台,根据用户发布的内容寻找相似用户,可以找到自己感兴趣的电影或内容,Massa 等[10]于2004 年提出将社交网络中的相互关系融入推荐算法中构建推荐模型。Lin & Gemmis 等[11-12]通过构建用户—项目评分矩阵进行用户相似度计算,以提升推荐系统精确度。
传统的推荐系统假设用户是独立且分布相同,这种假设忽略了使用者的社交关系。在类似于电影社交网络领域,网络中的不确定关系往往成为影响推荐精度的重要因素,如果两个用户兴趣相同,观点相近,那么认为他们之间的关联关系会大于那些具有不同兴趣和关注内容的人。如果两个人喜欢电影的个数超过一定比例,则认为他们有相同的欣赏品味,这种社交网络关系可以在很大程度上影响推荐结果。
1.1 矩阵分解技术
对于一个电影推荐系统而言,其用户和电影之间的关系转换为一个user-item 矩阵。矩阵中的行代表用户,列代表电影。若用户对电影有过评分,则矩阵中处于用户对应行与电影对应列的交叉位置表示用户对电影的分值,该矩阵被称为评分矩阵。通过矩阵分解技术[13-14],可以将us⁃er-item 评分矩阵分解为2 个低秩的用户电影矩阵,同时降低计算复杂度。利用线性回归思想,通过最小化观察数据的平方寻求最优用户和项目的隐含向量表示,进而用于预测缺失评分。
1.2 梯度下降算法
求解矩阵分解最优化问题时,本文采用梯度下降法(Gradient Descent),其核心思想是沿梯度下降方向逐步迭代。梯度是一个向量,表示一个函数在该点处沿梯度方向变化最快,变化率最大,而梯度下降方向指负梯度方向。在实际实验过程中采用随机梯度下降算法,随机梯度下降算法[15-17]指在迭代过程中随机选择一个或几个样本的梯度替代总体梯度,从而极大降低了计算复杂度。本文求解目标函数最小化方法使用的就是随机梯度下降算法。
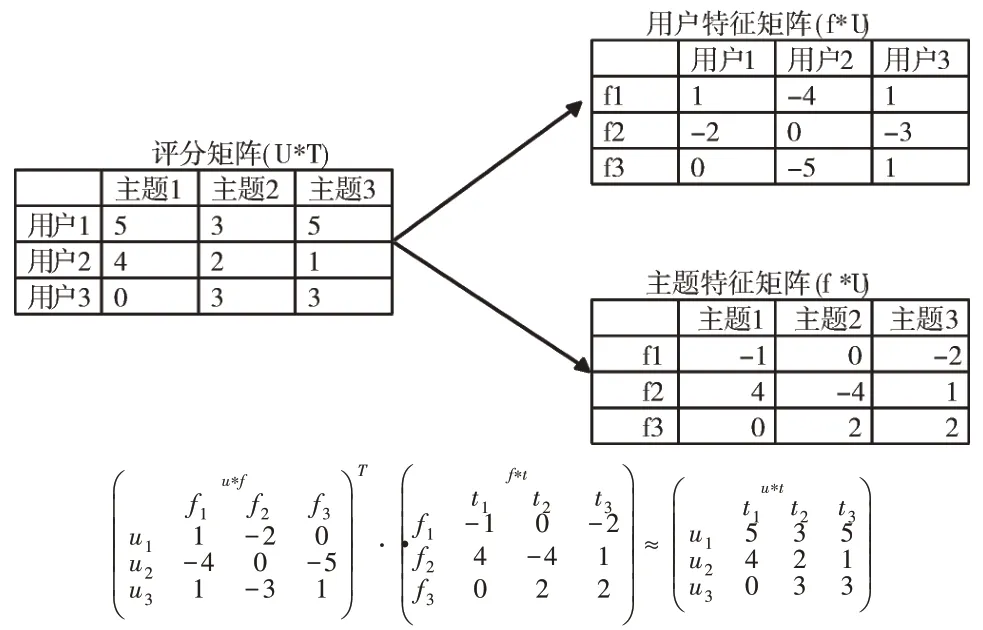
Fig.1 Relationship among user,topic and latent factor matrix图1 用户、主题、潜在因子矩阵之间的关系
2 基于矩阵分解技术的电影推荐系统
矩阵分解技术用途十分广泛,基于矩阵分解技术的电影推荐系统可以解决传统推荐系统技术中存在的矩阵稀疏、冷启动等问题。本文首先分析基础矩阵分解技术,然后考虑损失函数构建,最后通过梯度下降算法进行最小值求解。
2.1 基础矩阵分解技术
通过矩阵分解技术构建了一个用户—电影矩阵。在该推荐系统中用户集合U={U1,U2,…Um}。电影集合M={M1,M2,…Mm},用户对电影的评分矩阵R={Rut},其中,Rum 表示用户u对电影m的评分,每一部电影都得到一个向量q,每一个用户也得到一个向量p,如式(1)所示。

为了防止过拟合问题,加入正则化λ(‖pu‖2+‖qi‖2),λ为正则化参数。最终得到求解公式如式(2)所示。
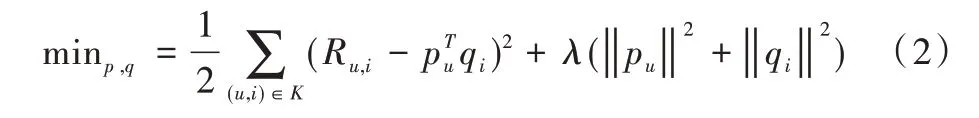
接下来利用求最小值方法计算出新评分矩阵的各项参数值。
2.2 损失函数构建
当在电影社交网络中的两个用户同时讨论一个电影,其中一个较为偏激,针对某一个话题经常表达较为悲观的情绪,而另一个用户则显示出较为正面的情绪。在电影选取过程中,由于电影分布不同也可能存在偏差。对于用户而言,不同的用户针对相同电影表现出的情感倾向性的激烈程度并不相同。此外,同一个用户针对不同的电影时,表现出的情感倾向性也不同。为此,通过Koren 等[2]的研究表明,在推荐系统中考虑用户和主题偏差可以有效改进系统的推荐精度。矩阵分解模型通过明确考虑以下偏差参数解决这些问题,如式(3)所示。
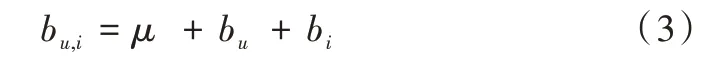
其中,bu代表了用户偏差,bi代表电影偏差。将偏差计算整合到式(1)中,得到公式如式(4)所示。
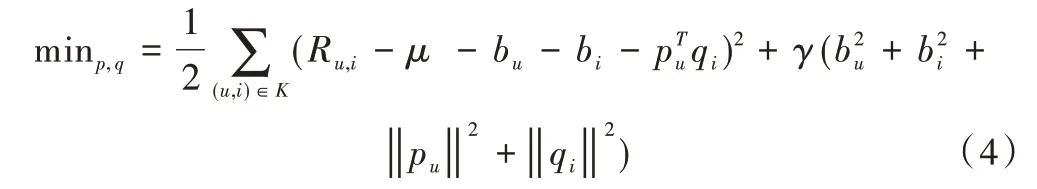
2.3 最小值求解
建立评分矩阵和损失函数后,需通过优化算法进行最小值求解。本文使用随机梯度下降算法进行最小值求解,过程如式(5)—式(8)所示。
对于目标函数式(4),对其进行求梯度,如式(5)—式(6)所示。
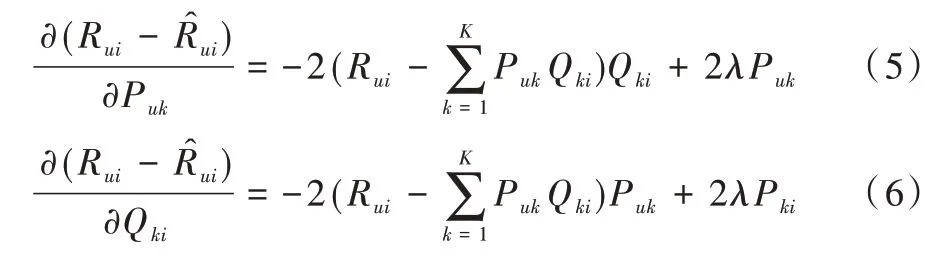
利用梯度下降进行最小值求解,如式(7)—式(8)所示。
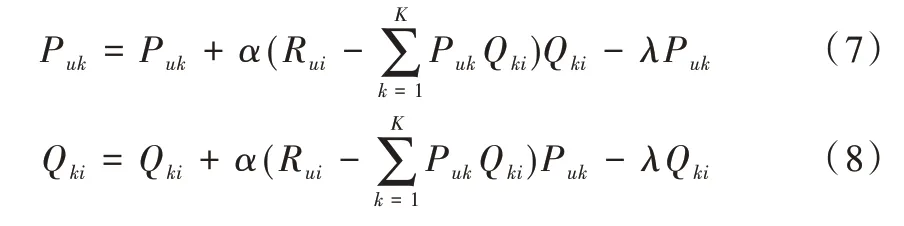
通过上述随机梯度算法,对分解后的矩阵进行参数估计,得到相应的矩阵参数。
2.4 算法流程
本文首先对数据进行抽取式整理,其次根据测试数据比例进行实验,设置矩阵分解模型参数并进行不同角度的观察,最后利用梯度下降算法得到最优解。流程如图2 所示。
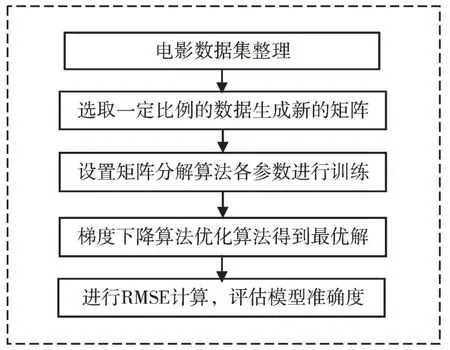
Fig.2 Process of algorithm图2 算法过程
4 实验设计与分析
4.1 数据集分析
本文选择Douban 电影评论和Netflix 数据集作为社会推荐的参考数据集。
Douban 是一个以电影评论为主的社交网站。用户注册后,能够对其它已经发布的电影或即将发布的电影发布评论和打分,评分登记是1~5 的整数。这些评价分数和评论会影响其它网站用户,是一部电影是否值得观看的依据。网站用户之间可以有关注和被关注的关系,评论内容有短评和长评。本文实验中使用的数据集来源于豆瓣网站,tsv 文件总大小为46.8M,包括94 890 个用户,共有81 906个不同项目,每个用户至少有一次评论,总共有11 742 260条评论。在实验过程中为了考察不同数据集大小情况,分别选取K 篇文章的所有评论进行试验,K 的大小分别为5、10、15、20、25。选取这些数据内容是为了与Netflix 数据集规模保持一致,方便对比。
Netflix 数据集由Netflix 网站提供,该数据总计有100万用户评论,其中评论用户500 000,电影总计17 000 部。每一个点评的评分在1~5 区间。在实验过程中,分别选取10 000、25 000、50 000、75 000、100 000 条评论数据作为试验数据。数据集规模如表1 所示,其中豆瓣电影数据集以讨论的电影数目进行分类,Netflix 数据集以评论数据进行分类。从整体看,评论数目的规模较为相近。
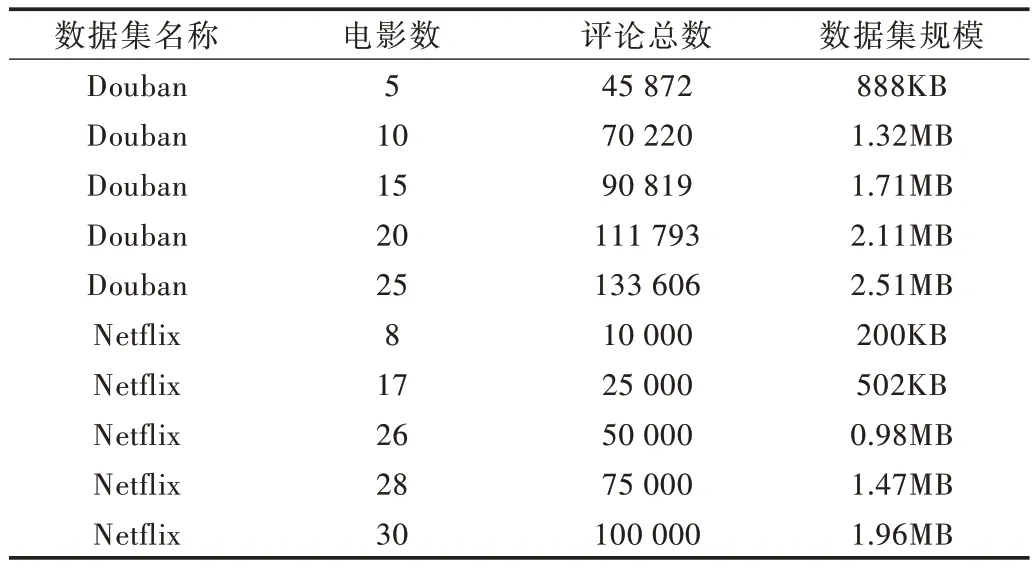
Table 1 Dataset size表1 数据集规模
4.2 评价指标与模型参数
采用均方根误差RMSE 和评价绝对误差MAE 对试验结果进行评价。这两个评价指标的值越低表示预测准确度越高。
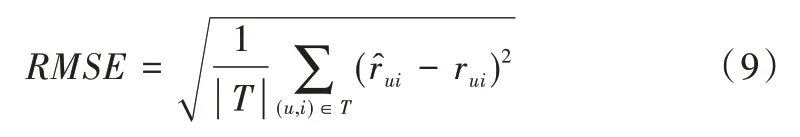
矩阵分解模型是本次实验的主要贡献,除原本矩阵外,主要参数有4 个,如表2 所示。

Table 2 Parameters and values表2 参数含义和取值范围
其中,K 表示潜在用户特征向量个数,将其取值范围设定为2~10。
Alpha 表示学习率(learning rate),代表梯度下降算法中迭代步长。学习率一般不宜过大,过大时,迭代过程会出现震荡现象。在实验过程中,将其值设置为0.01。
Beta 表示过拟合参数,在实验过程中将其设置为0.01。在进行梯度下降算法求解过程中可能会造成过拟合问题,所谓过拟合,就是过分地拟合了样本数据,造成引入了大量噪音,无法呈现原本规律,但又无法针对特殊样本数据进行剔除,因此干脆对所有参数加入随机因子,即正则项。正则化是降低过拟合问题的常见手段。
Iterations 表示迭代次数,迭代次数越多,准确度越高,但是相应的计算开销也会增大,在实验过程中将其值的范围设定为10~100。
4.3 实验结果与分析
依据上述数据集、评价指标和模型参数设置等内容,通过实验观察该模型如何改变推荐精度。
首先将本文提出的模型应用于豆瓣数据集中,数据集规模按照评论个数划分为45 872、70 220、90 819、111 793、164 122。具体结果如表3 所示。
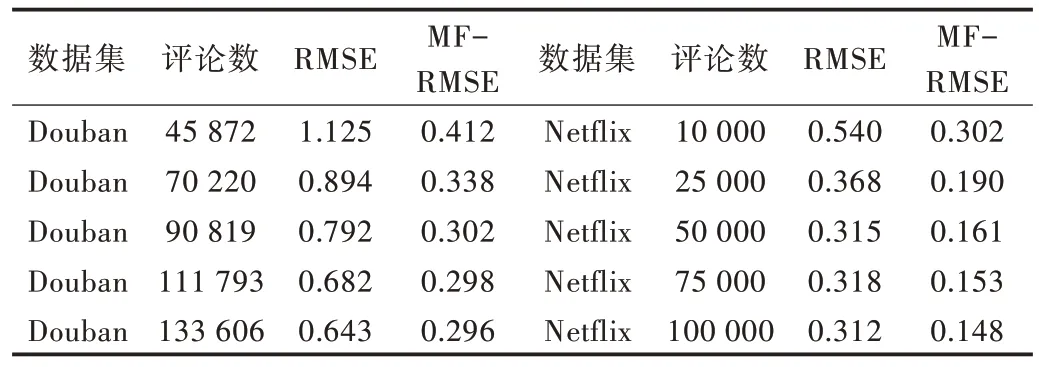
Table 3 Evaluation values表3 评测值
RMSE 的值表示对原始电影评论集设置测试用例比例后得到的RMSE 误差,MF-RMSE 表示应用本文提到的矩阵分解技术后得到的RMSE 值。可以看出,MF-RMSE 对于推荐精度有了较大提升。同时还可以看出,随着评论数即样本数据的增加,无论是Douban 数据集还是Netflix 数据集,评论精度有较大幅度提升,具体如图3 和图4 所示。
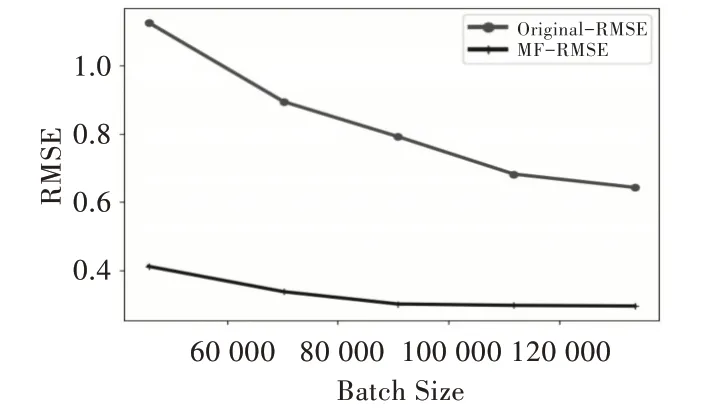
Fig.3 Douban dataset图3 Douban 数据集
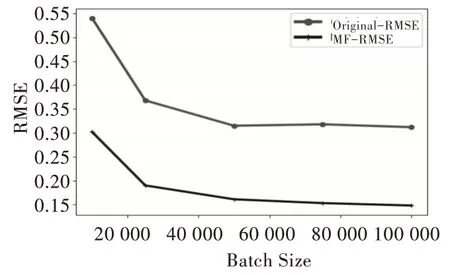
Fig.4 Netflix dataset图4 Netflix 数据集
通过上述实验内容可以看出,使用矩阵分解技术前后,推荐系统的准确度有了相应提升。随着数据集的增加,推荐精度也会有相应增加,但是增长幅度会有所减小,数据集规模达到一定程度后,要提高精度有一定难度。上述两个实验虽然基于不同的数据集,但是数据规模较为相似,得到的数据结论也较为相似,因此本文提出的算法颇具代表性。
5 结语
本文提出了一种矩阵分解算法,将其应用到电影推荐系统中。该算法通过融合用户和电影内容之间的评分机制,利用矩阵分解技术进行内容推荐,首先将用户—电影评分矩阵分解为用户潜在因子矩阵和主题潜在因子矩阵,然后引入损失函数防止出现过拟合现象,最后利用梯度下降算法进行最优值求解。将该方法应用于Douban 电影数据集和Netflix 电影数据集后取得了较好效果。在未来工作中,可将用户之间的关联关系和动态内容作为一个重要因素整合到模型中,以更好地提高推荐系统精度。
