贝叶斯框架下的自适应质量变量预测模型
2021-02-04朱雨婷
朱雨婷,田 颖
(1.上海理工大学机械工程学院;2.上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
在工业生产过程中,关键产品质量指标测定对于提高生产效率、保障生产安全具有重要作用[1]。软测量技术主要通过建立一定的数学模型,利用易于获得的过程变量估计难以测得的关键变量[2]。软测量建模是该技术的核心内容。
贝叶斯网络[3-5](Bayesian Network,BN)是一种基于概率建立的数学模型,对于解决工业生产工程中变量不确定性与不完整性问题具有很强优势。因而贝叶斯网络在质量变量预测中的应用成为研究热点。本文利用最大期望(Expectation Maximization,EM)算法对高斯混合模型[6-8]中的未知参数进行估计,以获得高斯混合模型逼近贝叶斯网络联合概率,降低网络训练过程复杂度,实现质量变量预测。EM 算法作为一种迭代算法,被用于带有隐变量的概率参数模型最大似然估计,其最大不足在于不能自动调整混合模型中单高斯模型数量,只能事先赋予初值,导致难以选择最优的模型数值,且会导致混合模型中参数估计产生偏差。针对该问题,已有研究从不同方面提供了较合适的解决方案,其中最经典的是由Figueiredo 等[9]提出的F-J算法,但该算法不能解决自动消除权值过小的单高斯模型问题。因此,为了优化高斯模型结构,可引入带有合并算子的F-J 算法。
另一方面,当过程变量之间存在线性关系时,将对基于贝叶斯网络的质量变量预测模精度和泛化能力造成一定影响。因此有必要在训练网络前,对过程变量进行主成分特征提取[10-12]。这不仅可以解决过程变量之间的线性问题,对数据降维,还能将提取的主元作为网络输入变量,降低网络训练难度。
再者,在实际工业生产过程中,机器老化、工作环境等因素变化会导致模型退化问题[13-15]。因此,进一步引入即时学习这一自适应策略[16-18],对于实时的待测样本,通过比对数据库已知的有标签样本,选择相似度最高的一组训练质量变量预测模型,可提高模型预测精度和泛化能力。为了提高样本选择速度,本文认为由于在较短的时间内获得的有标签样本具有同一性。基于该思想,对数据库样本进行分组可在一定程度上缩短网络训练时间。
由此,本文提出基于PCA-BN 的自适应质量变量预测模型。首先,对于数据库中的有标签样本进行分块,当待测样本出现时,将待测样本过程变量与各组过程变量均值进行相似度计算,将相似度极高的几组有标签样本融合成训练样本;其次,将获得的训练样本先通过主成分特征提取,取消变量之间关联性,将提取得到的特征变量作为贝叶斯网络的输入建立质量变量模型,提高模型精度;第三,在通过高斯混合模型逼近贝叶斯网络获得参数估计的过程中,利用带有合并算子的F-J 算法自动消除权值过小的单高斯模型问题,使EM 算法顺利收敛,获得结构清晰简化的GMM 模型;最后,利用基于PCA-BN 的自适应质量变量预测模型,估计待测样本。该方法综合利用即时学习提高模型泛化能力与BN 强大的函数逼近能力,基于田纳西伊斯曼(Tennessee Eastman,TE)仿真过程获得的数据可验证方法可行性及有效性。
1 基于即时学习的快速训练样本选取
即时学习(Just-in-time learnnig,JITL)可以同时处理非线性和时变性问题,其优势在于可建模提供准确的训练样本集。但是在样本选取过程中,需将待测样本与数据库中的每一个样本进行相似度对比,时耗很大。为了进一步提高样本选择速度,本文认为在一定时间间隔内,工业过程状态不发生漂移等变化,获取的数据样本应具有同一性。因此,将数据库X总=[x1,x2,x3,…xN]划分成小的块S=[s1,s2,s3,…sM],计算每个块均值U=[u1,u2,u3,…uM],选择均值与待测样本xq相似度较高的一组作为训练子集,建立待测样本最优局部模型。
余弦距离是典型的相似度计算方法之一,利用空间中两个向量之间的夹角余弦值作为衡量标准,其度量准则如式(1)所示。
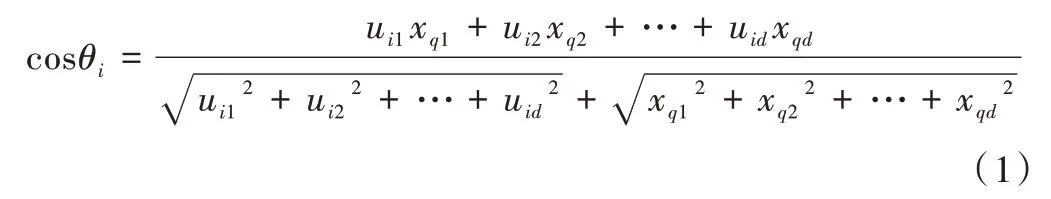
其中,θi表示数据库中第i个块均值与待测样本xq的夹角,uij表示第i个块均值的第j个变量,d为总变量个数。
余弦值越大,即越接近1,则表示夹角越接近0°,相似程度越高。计算出m个块与待测样本余弦值,选择一组较大值,将其对应的样本子集合成为1 个训练集。
2 主成分分析
主成分分析(Principal Component Analysis,PCA)能够通过线性变换,用少数几个主成分解释多个变量之间的内部结构。本文对于获得的训练样本集,利用PCA 进行线性变换,一方面可对数据降维,降低后续网络训练复杂度;另一方面可消除变量之间的相关性,提高模型预测精度。
首先,对样本x=[x1,x2,x3,…xd]进行线性变换。
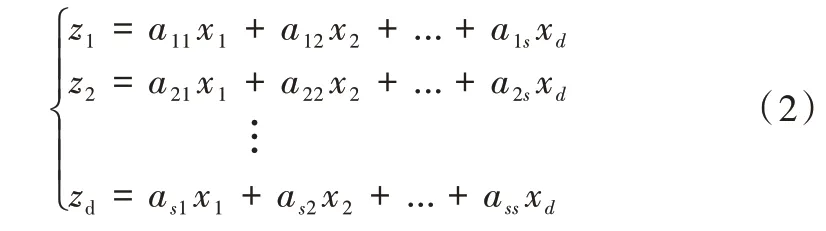
其中,d表示变量个数,zi是由过程变量通过线性变换获得的中间变量,aij表示变量x-j对成分zi的贡献。
将有n个样本的训练集X=[X1,X2,X3,…,Xn] 进行标准化,得到相关系数R。

其次,根据协方差矩阵计算特征值、主成分贡献率和累积方差贡献率,确定主成分个数。因为R是正定矩阵,特征值为正,即λ1>λ2>...>λn>0,v1,v2,v3,…,vn为对应的归一化特征向量。特征值表示各主成分方差,其值反映了各主成分影响。主成分贡献率计算方式为:

其中,φi是成分zi的贡献率。
3 基于贝叶斯网络的质量变量预测模型
3.1 模型结构
贝叶斯网络(BN)又被称为信念网络,是一种概率图模型,可以模拟人类处理推理过程中不确定因果关系,其拓扑结构本质是一个有向无环图,由随机变量为节点及连接节点的有向弧构成。本文为简化网络训练过程,选择原因节点时,尽可能满足两个条件:一是变量满足条件独立,二是各节点间不存在父节点。对于数据变量组合x=[x1,x2,x3,…xd,y],本文用于质量变量预测的贝叶斯网络模型如图1 所示。
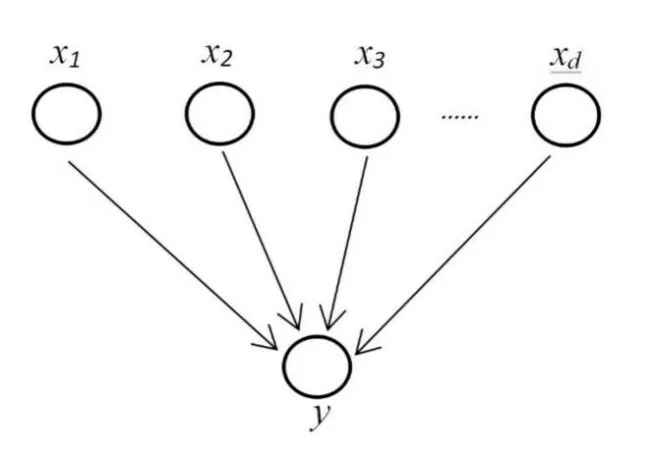
Fig.1 Quality variable prediction model based on Bayesian network图1 基于贝叶斯网络的质量变量预测模型
其中,原因节点x1,x2,…xd表示过程变量,结果节点y表示质量变量,即模型获得的估计值。进而,过程变量的联合概率分布可表示为:
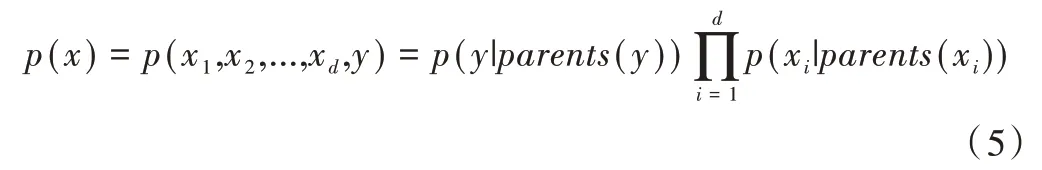
其中,p(xi|parents(xi)) 表示xi的条件概率分布,p(y|parents(y))表示y的条件概率分布。
3.2 贝叶斯网络联合概率密度的近似求解
贝叶斯网络结构复杂,不易于求解,故而通过建立高斯混合模型近似求解贝叶斯网络联合概率密度,可以得到结构相对简化的网络模型。
3.2.1 高斯混合模型
高斯混合模型(Gaussian mixture model,GMM)由多个单高斯混合而成,数据中的每1 个样本都能被分到对应的高斯元中。设训练样本集X=[X1,X2,X3,…,Xn],样本数为m,维数为d。若这组数据共由M 个不同的单高斯分布生成,则Xi的混合概率可表示为:
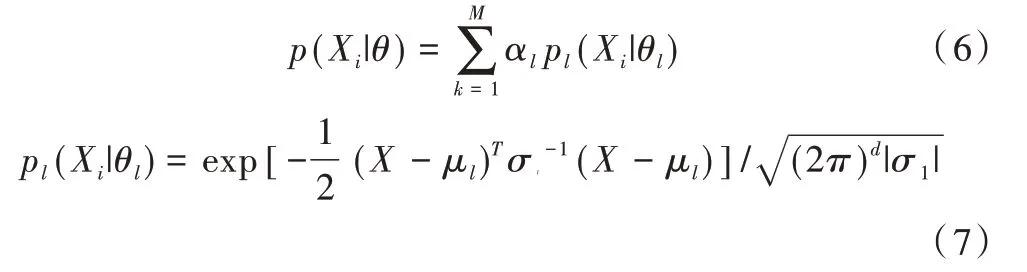
其中,αl是第l 个高斯元Cl的混合系数,满足,μl和σl分别是Cl的均值和协方差,θl=(μl,σl)。需注意两个问题:①当σl是奇异的,则而且σl是不可逆的;②当pl(Xi|θl)=0,则pl(Xi|θl)不能为分母。这两个问题均会导致算法终止,故将式(7)改写成式(8)。
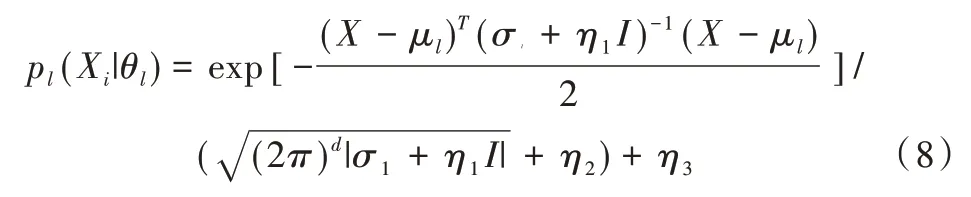
其中,η1、η2、η3是非常小的数值,I是单位矩阵。
因此,GMM 模型可对未知参数Θ={(α1,θ1),(α2,θ2),...,(αM,θM)}进行估计。
3.2.2 基于改进F-J 算法的EM 算法
EM 算法常用于GMM 参数Θ的估计,假设样本X=[X1,X2,X3,…,Xn],将作为GMM 模型参数初始值,将高斯元数量初始设为M0,则混合系数初始值定为1/M0。
首先进行基于改进F-J 算法的EM 算法运算,如式(9)所示。
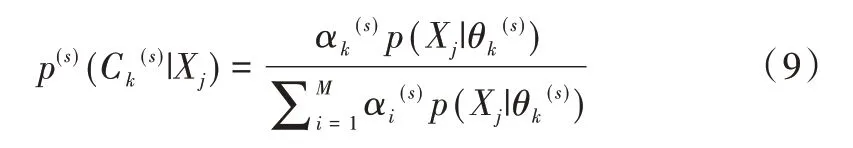
其中,p(s)(Ck(s)|Xj)表示第s次迭代时第j个样本属于第k个高斯元Ck(s)的后验概率。
运算第二步骤为:
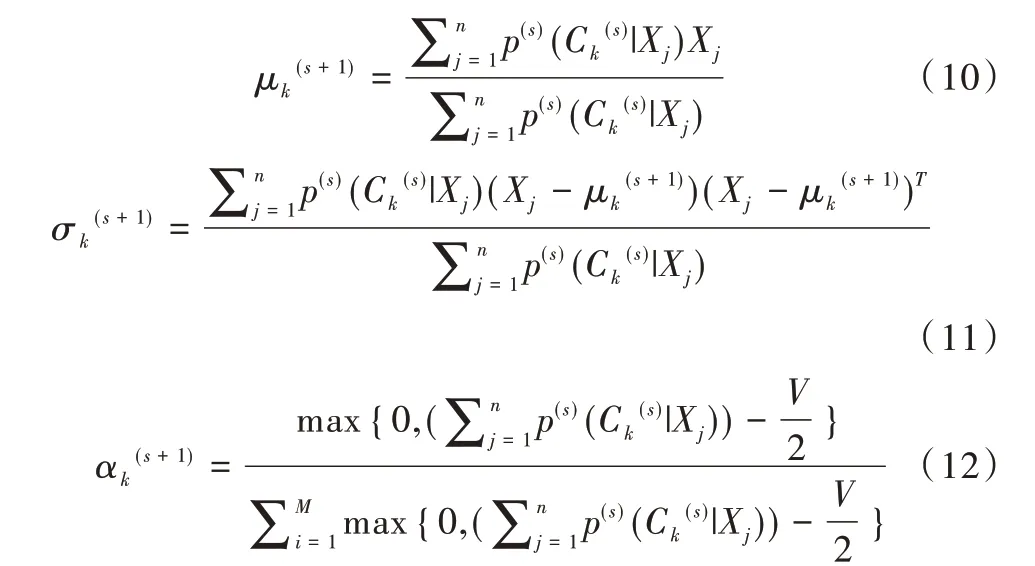
其中,μk(s+1)、σk(s+1)、αk(s+1)分别表示第s+1 次迭代中高斯元Ck(s+1)的均值、协方差和混合系数,V=(d2+3d)/2,d是过程变量个数。
在进行步骤二时,合并算子过程为:令Ci(s)为第s次迭代时,混合系数值最小成分,并且值为αi(s),相应由Ms个成分混合组成。
(1)当αi(s)<1/M0,则计算Ci(s)和其他各成分的距离,将成分Ci(s)与其距离最近的Cj(s)合并,获取更新后的混合系数后重复该步骤。
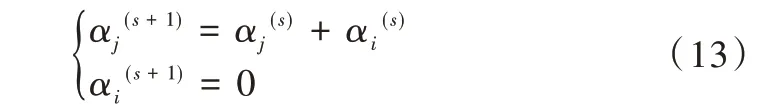
(2)当所有αi(s)>1/M0,则需要检查两次迭代中参数是否发生变化,如果超出特定的1 个非常小的范围,重复上一步骤;否则,停止迭代。
按照上述步骤更新高斯模型参数,可以保证每个高斯成分具有显著的占比。
3.3 模型构建
本文针对一非线性多输入单输出系统,采用高斯混合分布近似求得贝叶斯网络联合概率密度后,可根据原因节点(过程变量)的值预测结果节点(质量变量)值。
设p(x;μ,σ)为多维正态密度函数,μ,σ分别为均值、协方差矩阵,如果xT=(x1T,x2T),μ=(μ1T,μ2T)且σ=,其中,x1表示过程变量,x2表示质量变量,则贝叶斯网络联合概率密度由式(5)可进一步表示为:

对于第l个高斯元可得:

则对于混合模型有:

进而,根据贝叶斯公式推导可得:
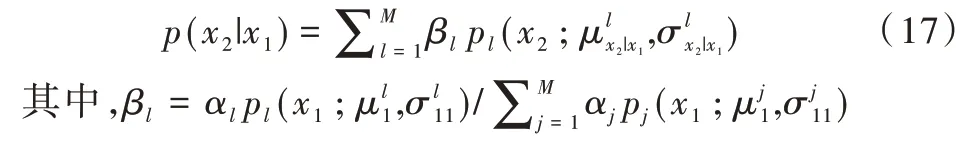
最后,根据x2的估计值可得:
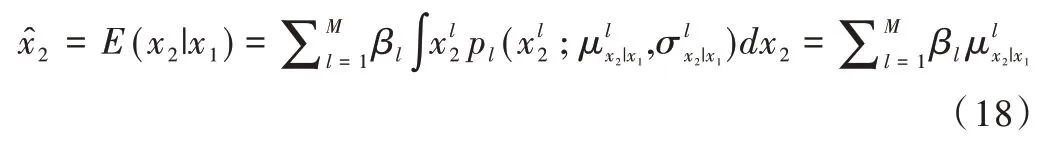
4 基于PCA-BN 的自适应策略建模及仿真
4.1 基于PCA-BN 的自适应策略建模
依据建模原理,建立基于PCA-BN 的自适应策略模型,其结构如图2 所示。首先,将现有数据库数据分块,产生多个局部数据子集,将查询样本与这些数据子集进行相似度对比,选择最具有相似性的一组数据子集构建训练集;然后,对训练集的过程变量进行主元提取,并将提取的变量作为贝叶斯网络输入,最后对查询样本进行质量变量预测输出。
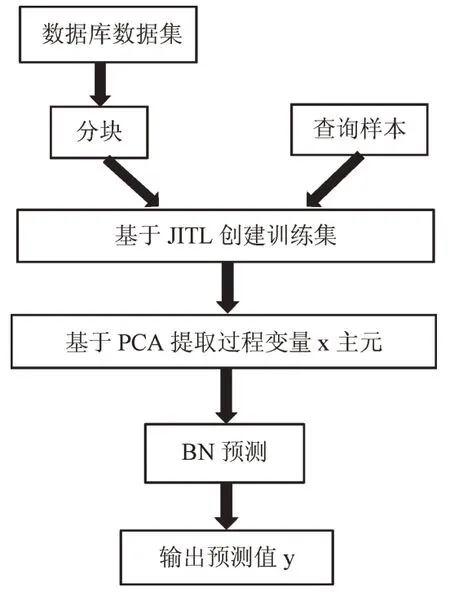
Fig.2 Process of adaptive strategy prediction model based on PCA-BN图2 基于PCA-BN 的自适应策略预测模型流程
4.2 工业应用
Downs 等[19]依据实际化工过程建立了Tenessee East⁃man(TE)仿真系统,详细流程结构如图3 所示。在过程控制的研究领域中,由于TE 过程可较好地体现实际工业生产过程中的许多典型特征,因此常应用于质量变量预测、过程监控与故障检测研究。
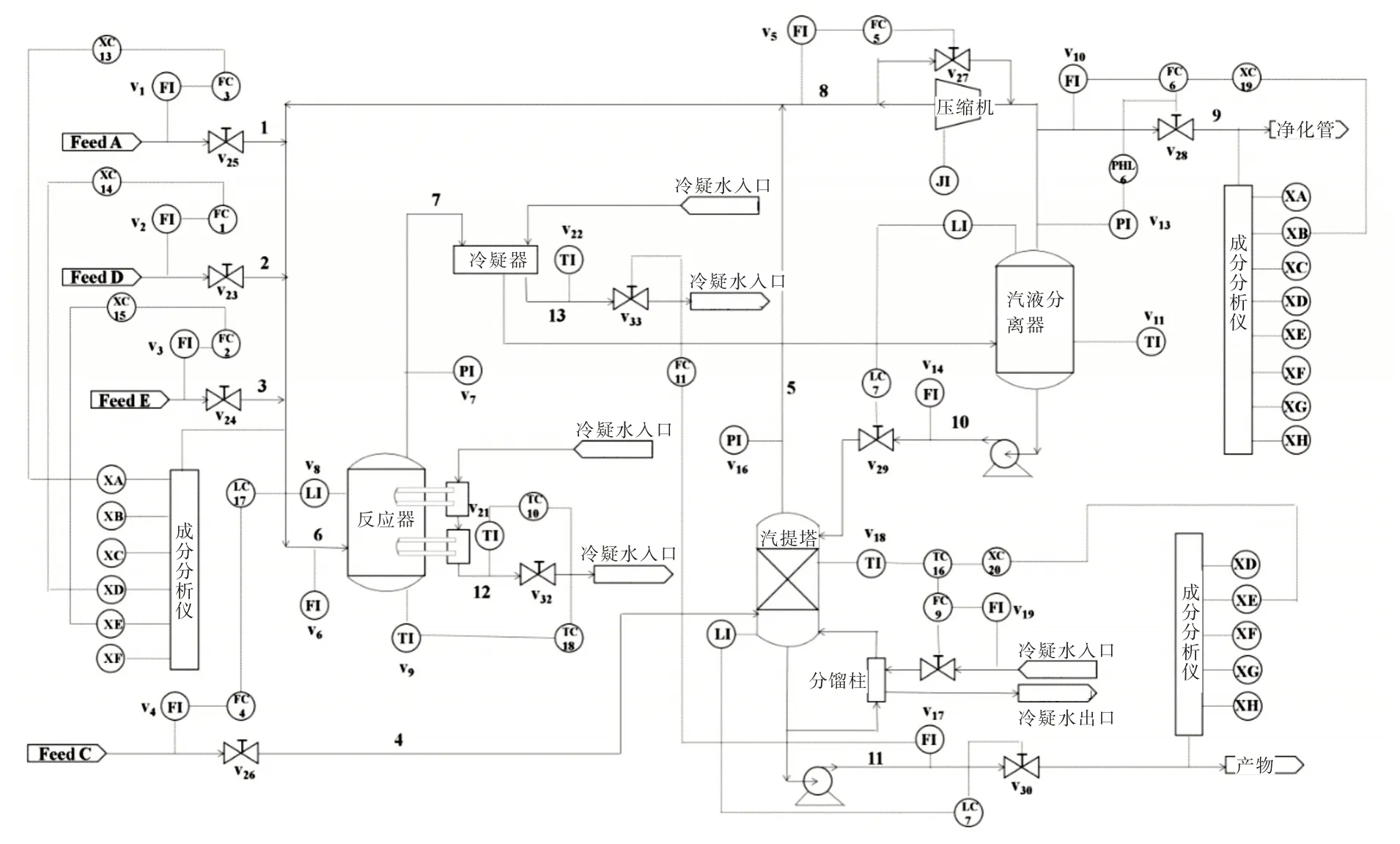
Fig.3 Flow of TE porcess图3 TE 过程流程
TE 仿真主要由反应器、冷凝器、压缩机、气液分离器和汽提塔5 个模块构建而成[19]。数据集由测量变量和操作变量两部分组成。整个反应过程涉及XA、XB、XC、XD、XE、XF、XG、XH 等8 种物质,其中XG、XH 为最终产品,牵涉的反应如式(19)所示。
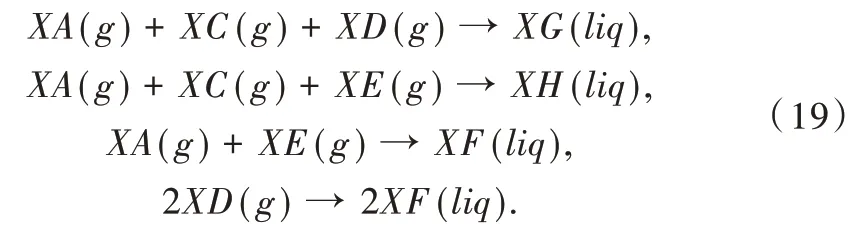
TE 过程涉及到11 个操作变量、41 个测量变量,其中测量变量可再细分为22 个连续过程变量和19 个非连续组分变量[20]。其中,对最终产品XG、XH 的实时监测为有效提高输出产品质量控制系统奠定了基础。本文主要研究多输入单输出的非线性系统,利用成分分析仪分析获得19 个非连续组分变量,该过程相对较为复杂,故选择33 维变量作为输入,即由11 个操作变量和22 个连续过程变量组成输入,并选择最终的XG 成分含量作为输出变量,进而建立预测模型。具体步骤为:①将数据库数据进行分块,将大的数据集分成若干个局部数据子集;②对于待测样本,先筛选出这些数据子集中与之相似度较高的一组有标签样本作为模型训练集;③利用主成分分析对输入变量作特征提取,消除变量之间的相关性,降低数据维数,简化贝叶斯网络复杂度;④利用获得的主成分变量作为贝叶斯网络原因节点,对应的XG 成分作为结果节点,建立TE 过程的自适应PCA-BN 质量变量预测模型。
本文共有960 组数据,选择60 组作为测试样本,900组作为数据库,鉴于主元个数设定为17,所以每次从中选择600 组作为训练样本。若测试样本数量过少,算法将无法正常运行[6]。
为了证明本文方法可行性,将其与同等情况下的PCR和PCA-BN 的预测结果相对比,如图4-图6 所示(彩图扫OSID 码可见),MAE 分别降低了26.2% 和14.4%,RMSE 分别降低了10.3% 和7.5%,RE 分别降低了11.5% 和8.3%。MAE(Maximum Relative Error)表示最大相对误差,RMSE(Root Mean Square error)表示均方根误差,RM(Relative Er⁃ror)表示相对误差。经对比可以看出基于JITL 的PCA-BN预测精度比传统方法更高,可有效解决软测量过程中时变性问题。

Fig.4 Prediction curve based on PCR图4 基于PCR 的预测曲线
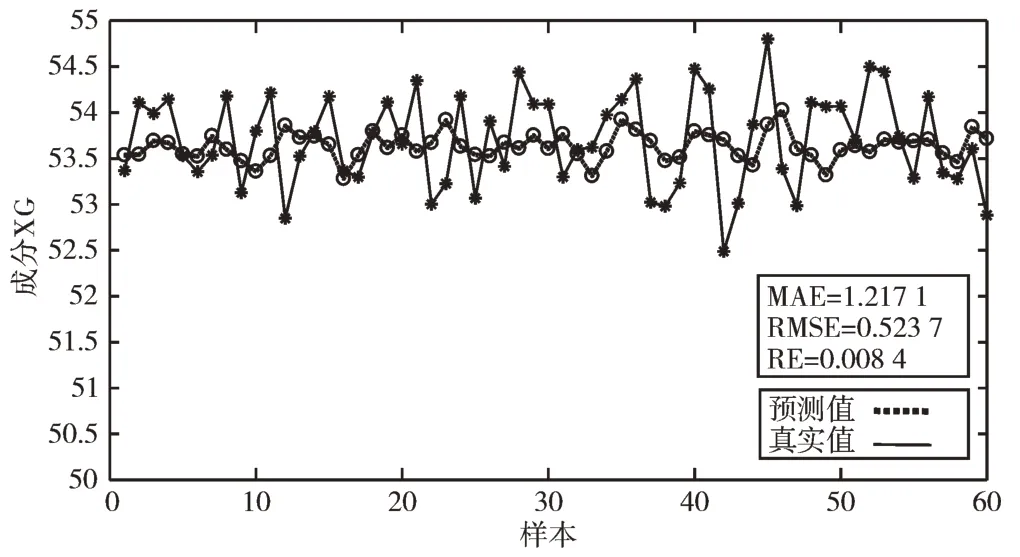
Fig.5 Prediction curve based on pca-bn图5 基于PCA-BN 的预测曲线
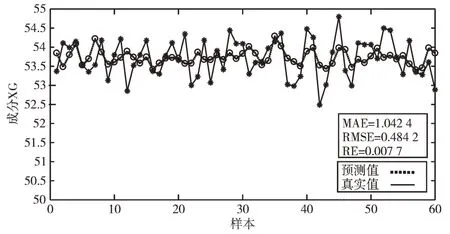
Fig.6 Prediction curve based on adaptive strategy in Bayesian framework图6 贝叶斯框架下基于自适应策略下的预测曲线
5 结语
本文将JITL 与PCA-BN 结合,提出了基于PCA-BN的自适应质量变量预测模型。首先利用JITL 从分块好的数据库数据集中,选出与待测样本相似度较高的1 组局部模块作为训练样本,缩短样本筛选时间;再利用PCA 提取过程变量主元,借此作为原因节点进行降维并简化BN 网络;接着利用带有合并算子的F-J 算法改善EM 算法,从而获得高斯混合模型参数估计;最后基于高斯混合模型逼近贝叶斯网络联合概率密度的思想,训练得到清晰简化的网络模型,进而估计质量变量值。使用该方法建立TE 过程的成分XG 预测模型与PCR,PCA-BN 等方法相比,预测精度更高。但该方法仍存在不足之处,对于每一个查询样本,都需重新选取训练样本从而建立一个新的贝叶斯网络,较之传统方法虽然预测精度有所改善,但是计算时耗也会更大。如何在提高精度的基础上,还能控制计算时长,仍需进一步研究。
