基于级联特征网络的人体姿态估计
2021-02-04
(河北工业大学人工智能与数据科学学院,天津 300401)
0 引言
目前,多人姿态估计已成为人体姿态估计研究的热点问题。现有的多人姿态估计方法分为两类:自顶向下的方法和自底向上的方法。自顶向下的方法首先从图像中定位人体位置,然后对每个人体目标使用单人姿态估计获得最终姿态估计结果;自底向上的方法则首先直接检测图像中所有人体关键点,并根据图像中的其它关联信息将属于同一人体目标的关键点组合成一个完整的人体姿态。
为了提高关键点检测精度,本文提出级联特征网络(Cascaded High-resolution Representation Network,CHRN),该网络以HRNet[1]网络为基础,通过构建主体网络与微调网络的结构定位人体关键点。主体网络利用多通道、多阶段模式提取深度特征,并以多尺度融合方式将多阶段深度特征进行融合,获得图像中更加全面且综合的信息;微调网络级联整合主体网络提取的多阶段深度特征,对主体网络中识别率较低的人体关键点进行在线挖掘[2]。
本文主要贡献为:①提出级联特征网络的高效网络模型,通过级联深度特征并结合在线关键点挖掘提高不易识别关键点的识别率,进而提升关键点整体识别率;②将本文方法与其它经典算法进行系统比较,在MPII[3]数据集上对人体姿态估计的直观效果和识别精度进行评估。实验结果证明,本文方法具有一定有效性和先进性。
1 研究现状
随着深度学习方法在计算机视觉领域的广泛应用,卷积神经网络(CNN Convolutional Neural Network)[4-5]在人体姿态估计方面得到了良好发展。最近研究[6-13]主要依赖于卷积神经网络,韩金贵等[4]对此作了比较全面的研究综述,本文主要关注基于卷积神经网络的多人姿态估计方法。多人姿态估计方法可分为两类:自顶向下的方法和自底向上的方法。
自顶向下的方法[2,14,16]通过将单人姿态估计与目标检测相结合,以解决多人人体姿态估计问题。Fang 等[14]使用空间转换网络(Spatial Transformer Networks,STN)[15]处理不准确的边界框,然后使用堆叠沙漏网络完成关键点检测;He 等[16]在Mask-RCNN 模型中结合实例分割和关键点检测,将关键点附加在RoI 对齐的特征映射上,通过堆叠沙漏网络获得每个关键点的位置;Chen 等[2]在特征金字塔网络[17]上开发GlobalNet 用于多尺度推理,并通过在线关键点挖掘重新预测。自顶向下的方法将关键点检测模型的注意力集中到图像中各人体目标上,这样减少了图像中其它冗余信息干扰,获得了良好表现。
自底向上的方法首先直接预测所有关键点,并将它们组合成所有人的完整姿势。在Ladicky 等[18]提出使用基于HOG[19]的特征和概率方法联合预测人体部分分割和部分位置;Pishchulin 等[20]提出DeepCut 方法,该方法将图像中的多人人体姿态估计问题转换为整数线性编程(Integer Linear Program,ILP)问题;Insafutdinov 等[21]使用更深层次的ResNet[22]改进DeepCut 提出DeeperCut,并采用图像条件成对匹配获得更好性能;Cao 等[23]使用CPM(Convolu⁃tional Pose Machines)将关键点之间的关系映射到部分亲和域(Part Affinity Fields,PAF),并将关键点组合成不同的人体姿态;Kocabas 等[24]提出MultiposeNet 在检测人体关键点的同时,利用另一个分支检测人体目标位置,为关键点聚类提供依据。由于目标不明确,关键点定位空间过大,目前自底向上的方法在精度上仍然低于自顶向下的方法。
为提高关键点检测精度,本文提出级联特征网络(CHRN),将主体网络与微调网络相结合,增加对不易识别关键点的关注度,从而提高关键点检测整体精度。
2 本文方法
CHRN 使用HRNet 提取图像特征,并借鉴CPN 模型思想,包含主体和微调两个分支子网络。
在CHRN 中,主体网络负责提取图像特征并检测容易检测到的关键点,微调网络使用瓶颈模块和级联整合主体网络各阶段特征,并通过关键点在线挖掘检测不易识别的关键点。
2.1 主体网络
主体网络部分以HRNet 网络模型为基础,通过该模型结构中不同分辨率的深度特征输出层构建而得。该网络共有4 个并行的深度特征提取子网络,网络结构如式(1)所示。
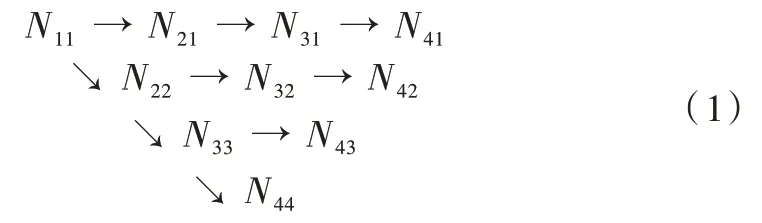
式(1)中,Nij为HRNet 网络的基本处理单元,其中横向为分支,包括4 个分支,分支数j=1,2,3,4,纵向为阶段,包括4 个阶段,阶段数为i=1,2,3,4。
将4 个并行的深度特征提取子网中第i个阶段的输入记 为C={C1,C2,…,Ci},第i阶段的输出记为,输出的分辨率和宽度与输入的分辨率和宽度相同,在同一个阶段的不同分支中,交换单元多尺度融合方式如式(2)所示。
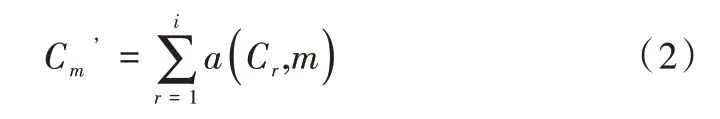
式(2)中,函数a(Cr,m)表示将Cr从分辨率r上采样或下采样到分辨率m,Cm’为C’包含的元素,上采样使用最邻近采样,然后使用1×1 的卷积进行通道对齐,下采样使用3×3 的卷积,当r=m,如式(3)所示。

2.2 微调网络
本文在基于主体网络生成的高分辨率特征图上附加使用OHKM 的微调网络分支,对主体网络预测的关键点进行修正。微调网络将上述构建的主体网络各阶段提取的深度特征:C111、C212、C313、C414以及人体关键点置信度热图H作进一步特征提取,具体结构如式(4)所示。
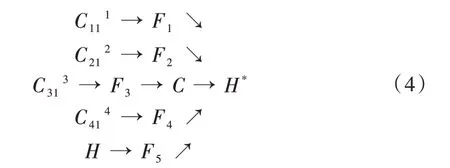
式(4)中,C111、C212、C313、C414、H经过进一步特征提取后分别生成F1、F2、F3、F4、F5,其中F1、F2、F3、F4、F5的宽度和分辨率都相同,C为F1、F2、F3、F4、F5的特征级联,H*为经过人体关键点在线挖掘的人体关键点置信度热图。
3 实验
为验证本文方法的有效性,在公开的MPII 数据集上对本文方法进行评估,并与一些优秀方法进行对比。
3.1 数据集与实验设置
MPII 数据集包含约25 000 张图像,其中有5 000 张图像用于测试,其余图像用于训练。评价指标为:头部标准化概率(Percentage of Correct Keypoints According to Head Size,PCKh)。
3.2 级联深度特征网络实验
为验证级联特征网络关键点定位有效性,将该网络应用于单人姿态估计,表1 展示了本文方法在MPII 测试集上进行单人姿态估计PCKh@0.5 获得的定量性能。实验表明,HRNet+RefineNet 模型结构加入微调网络后,对于肩部、髋关节、膝关节和踝关节的平均精度比HRNet 均有所提升。加入OHKM 后的结果表明,本文提出的CHRN 人体姿态估计使HRNet 的平均精度由92.3% 提高至92.7%。
3.3 人体姿态估计实验效果
为了证明级度特征网络对多人姿态估计的有效性,在MPII 数据集中进行多人姿态估计对比实验验证。其中,对比方法相关数据来源于MPII 数据库排行榜。实验结果如表2 所示。

Table 1 Performance comparison of MPII test sets(PCKh@0.5)(single-person pose estimation)表1 MPII 测试集性能比较(PCKh@0.5)(单人姿态估计)
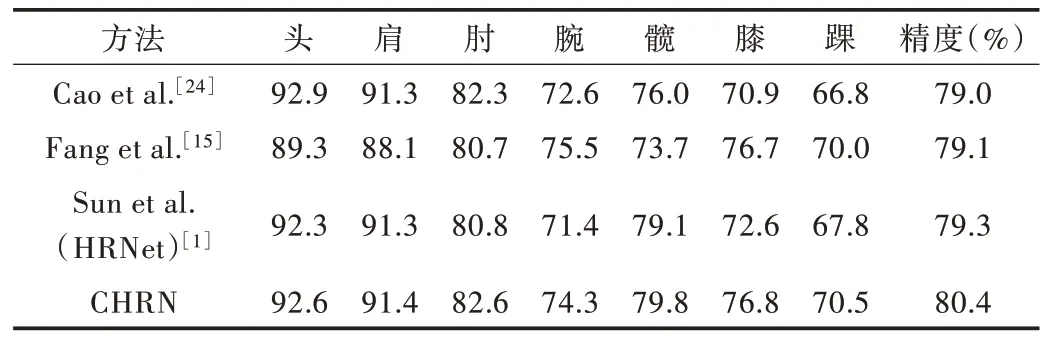
Table 2 Performance comparison of MPII test sets(PCKh@0.5)(multi-person pose estimation)表2 MPII 测试集性能比较(PCKh@0.5)(多人姿态估计)
表2 展示了本文方法在MPII 测试集上进行多人姿态估计的定量性能。表2 中的对比算法为MPII 数据集排行榜前3 名的识别精度。其中,“CHRN”表明,级联深度特征网络模型使用自顶向下方法得到平均精度为80.4%,高于其它算法。同时,CHRN 模型对于踝关节、膝关节和髋关节等较难识别关键点的识别精度有所提升,证明CHRN 对于较难识别的关键点有更强的定位能力。
4 结语
本文提出的级联特征网络通过提升不易识别关键点的识别精度以提高人体姿态估计准确率。研究表明,在人体姿态估计中由于关键点本身特性不同,关键点在模型训练过程中应区别对待,即为不易识别的关键点分配更多计算资源。下一步工作主要是对关键点进行分类细化,具体到各类关键点应分配多少计算资源可达到最优结果。
