双流融合的动作识别方法研究
2021-02-04
(安庆师范大学计算机与信息学院,安徽安庆 246133)
0 引言
动作识别在各种领域应用广泛,如公共场所安全、医疗服务和教育教学等[1]。人体动作识别中的数据获取大都依赖视觉传感器(如相机)或者可穿戴惯性传感器,通过构建合适的网络模型对数据中的特征进行学习,实现动作分类[2-3]。大规模人体动作数据集[3-4]的建立和多种检测方法[5-7]的引入,加快了人体动作识别领域的发展。目前,在面部动作及常见肢体动作如行走、跳跃等方面实现了较高的识别精度。
深度学习(Deep Learning)通过网络拟合方式自动挖掘数据中的信息特征,成为动作识别领域的新方向。对于数据集而言,基于深度学习的动作识别方法可以分为基于视频数据(Video-based)的识别方法与基于骨骼数据(Skele⁃ton-based)的识别方法。
传统基于视频数据的动作分类方法根据视频帧中的空间信息和时间域上的信息表示进行建模。Simonyan 等[2]提出双流(Two-Stream)的识别方法,对视频图像和密集光流(Optical flow)分别训练卷积神经网络(Convolutional Neu⁃ral Network,CNN),再对输出的概率求均值并输出最终识别率;Donahue 等[8]使用递归神经网络(Recurrent Neural Network,RNN)替代基于流的设计;Wang 等[9]通过稀疏采样,使用加权平均方法处理时间/空间流特征图,提升算法准确性。双流方法既可以学习视频图片的色彩轮廓信息,又可以学习动作的短时时序信息,但对于动作的长时时序信息网络无法较好处理。
三维卷积神经网络(3D Convolutional Neural Network,3D CNN)对若干连续帧的视频图像建立模型,可以较好地处理时间序列信息。如Tran 等[10]引入3D CNN 作为特征提取器,使用反卷积解释模型;王永雄等[11]将3D CNN 融入残差网络,提取动作的时空特征,实现了较好结果。3D CNN 既可以通过网络模型学习视频数据单帧图像的位置轮廓信息,又可以学习连续帧之间的时间信息。但是网络参数量巨大,训练速度较慢。
目前,通过在视频图像中添加注意力机制,一些方法也达到了较好分类结果。Sharma 等[12]使用带有注意力模块的CNN 网络作为图像编码器,对编码过的图像信息使用三层长短时记忆网络(Long Short-Term Memory,LSTM)学习图像在时序上的变化,最终达到较好动作识别效果;Yao等[13]使用3D CNN 和RNN 结合的网络作为编码/解码器,引入注意力机制学习全局上下文信息;Sudhakaran 等[14]使用添加注意力机制的网络自发关注手部运动,再利用卷积长短时记忆网络(convolutional Long Short-Term Memory,conv LSTM)学习时间序列信息,达到较好效果;曹晋其等[15]使用CNN 与LSTM 相结合的方式,在CNN 中添加注意力机制,达到较好识别效果。注意力机制在一定程度上让网络模型的参数聚焦于某些关键像素,更好地学习视频图像的色彩信息和轮廓信息。但网络过度关注某一区域也会导致全局信息缺失。
视频数据有良好的色彩信息和轮廓信息,通过网络模型可以充分地学习到这些信息。并且,视频数据采集方便,构建大规模数据集也相对容易。但是视频数据通过相机采集,只存在二维平面的位置特征。对于视频图像,目前大部分网络模型只能学习人员的色彩轮廓信息,信息丰富度较低,这也是此类方法识别精度较低的原因。
基于骨骼数据的识别方法通过构建可以学习关节点坐标的空间位置信息和关节点在时序上变化信息的网络模型,实现分类效果。Du 等[16]根据人体结构将骨骼分为5个部分,然后分别将它们输入到分层递归神经网络(Bidi⁃rectional Recurrent Neural Network,BRNN)中以识别动作;Song 等[5]使用3 层LSTM 网络,并在空间和时间上加入At⁃tention 机制,使网络关注重要的关节点和时间点,达到较好识别效果;胡立樟[17]提出一种综合LSTM 与最大池化的设计,能够学习不定时间跨度的上下文特征;Li 等[18]提出分层CNN 网络,学习联合共现和时间演化的表示形式。通过将人体关节点的三维坐标作为输入,可以学习更丰富的空间位置信息;而以LSTM 处理时间序列信息,可以让网络模型学习更长时间。但只是简单地将人体关节的三维坐标作为一个整体输入到网络模型中,并未充分考虑人体关节点之间的连接关系。
图卷积(GraphConvolutional Network,GCN)在动作识别领域的应用让这一领域有了新的发展。Yan 等[7]首次将GCN 引入动作识别领域,使识别结果有了较大突破。Si等[19]应用图神经网络捕获空间结构信息,使用LSTM 建模时间动态;Si 等[6]在已有基础上引入Attention 机制,使用LSTM 网络学习时间特征,获得NTU RGB+D 数据集[3]的较好分类结果。该方法通过图卷积,让网络模型学习人体关节点之间的相对位置关系,丰富空间位置信息内容。
骨骼数据具有空间三维信息,可以直接体现人体运动的空间变换。但由于缺乏图像的轮廓信息,对于差异度较小的动作,只使用骨骼数据,网络往往难以区分。同时,采集人体关节点数据需要专业设备,在某些情况下并没有采集数据的条件。
以上方法均是对单一类型数据进行建模,各有利弊。本文分别对两种数据建立不同的网络模型,并对两种模型输出结果进行概率融合。该方法在一定程度上结合了两种数据的优点,较为有效地实现了两种数据的信息融合。
1 相关原理
1.1 图卷积原理
图卷积是对于输入数据首先构建图拓扑结构,再使用类似卷积运算的方式处理这些数据。对于基于骨骼数据的动作识别,通过图卷积可以很好地学习骨骼关节点之间的空间位置关系,从而对动作进行较好地分类识别。
图卷积与传统卷积类似之处便在于,图卷积的计算过程也是一个先采样再加权求和的过程。图卷积的采样方式与传统卷积类似,传统卷积对中心像素点及周围像素点进行采样后输入卷积网络,而图卷积则对中心节点及邻居节点进行采样后输入网络。本文方法只对中心节点及周围一阶邻居点进行采样,对于与中心节点相连节点个数不足3 个的,会补上节点信息为空的哑节点。两者卷积参数有不同定义,传统卷积参数完全由网络反向传播计算,而图卷积参数是通过添加拉普拉斯矩阵后反向传播并训练得到[20]。对于任意图结构,在已知节点所包含的初始特征信息后都可以通过图卷积的方式计算聚合后的信息F:
其中,D 表示采样后图结构的度矩阵(Degree Matrix),A 表示采样后图结构的邻接矩阵(Adjacency Matrix),X 表示邻居节点所包含的信息,ω表示网络参数。通过合适的网络训练参数ω,可以将周围节点的信息聚合到中心节点,从而构建更丰富的节点信息。再对这些信息使用分类器分类,可以实现较好的动作分类效果。
1.2 注意力机制原理
卷积神经网络对图像进行卷积计算并不断凝炼图像像素特征,其网络最后一层的输出包含丰富的信息。而将这些信息输入全连接层时训练得到的参数客观上反映了最后特征图有哪些区域应该值得关注。通过对所有通道的结果求和,输出注意力热图(见图1)[21],这样的模块称之为注意力模块。注意力参数α可以表示为:
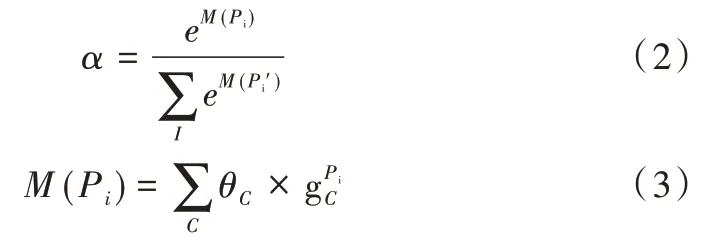

其中,⊗表示元素乘法(Hadamard Product)。
通过这种方法可以使网络模型自发关注重要部位,从而有利于后续动作分类。
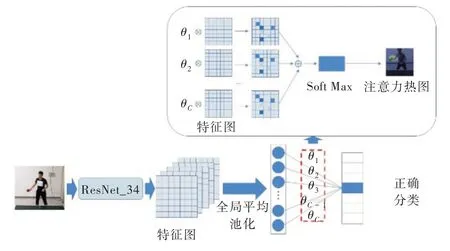
Fig.1 Attention heat map generation图1 注意力热图生成
2 本文方法
2.1 基于骨骼数据的动作识别方法
在具有N个关节点和T帧的骨骼序列上构造空间无向图结构G=(V,E)。其中,节点集合V={vti|t=1,…,T,i=1,…,N}包括了骨骼序列的所有节点。作为网络输入,节点vti上的特征向量X(vti)由第t帧第i个关节点的三维坐标向量组成。根据人体结构的连通性将一帧内的关节用边连接,每个关节将在连续的帧中连接到同一关节点。而边的集合E由两个子集组成:第1 个子集ES={vtivtj|(i,j)∈H}表示每一帧的骨骼连接,其中H是人体关节点的总数;第2 个子集EF={vtiv(t+1)i}表示连续帧中相连的关节点(见图2)。
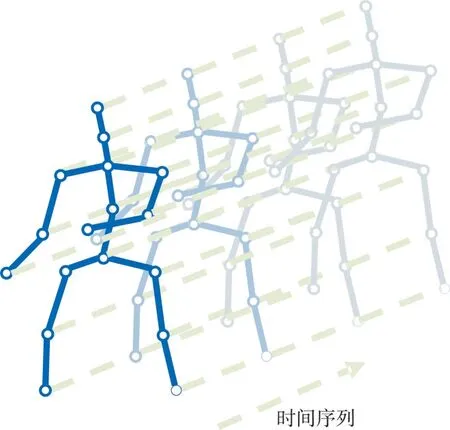
Fig.2 Visual structure of input data图2 输入数据可视化结构
对于输入数据,先使用图卷积编码关节点在空间中的位置关系。在单帧的人体关节点连接结构中,在关节点vti的邻居集上定义采样函数。其中,表示到vti的任意路径的最小长度。设置D=1,即只选取节点vti的一阶邻居节点,这一步称之为采样。同时,保证每次采样N=4 个关节点,对不满足这一条件的采样通过添加节点信息为空的哑节点予以解决。结合式(1),单帧视频的单个节点vti通过图卷积聚合后的特征输出可表示为:
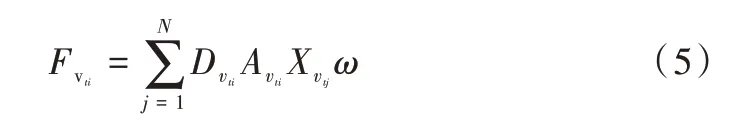
而对于时间维度的关节点连接则简单得多。本文对时间维度按照完全相同的时间间隔采样,因此时间维度的关节连接是规则的,可按照传统卷积方法计算。对于时间维度的关节点连接结构,设计一个大小为3×1 的卷积核,在时序上以步长为1 的方式移动。对所有时间序列进行卷积处理,构建更丰富的信息。这样的模块被称为TCN 模块。
本文方法对于空间维度和时间维度两个不同维度的处理是交替进行的,本文人体动作识别网络结构如图3 所示。
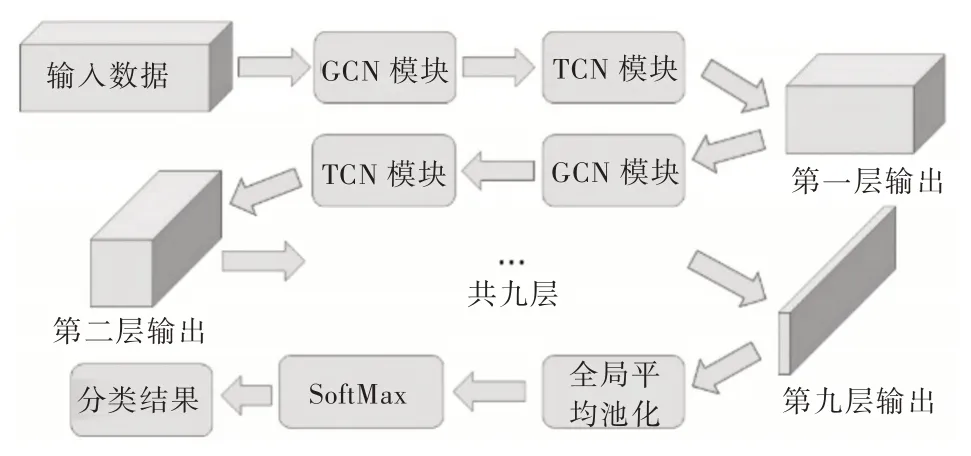
Fig.3 Human action recognition network based on skeleton data图3 基于骨骼数据的人体动作识别网络
2.2 基于视频数据的动作识别方法
基于视频数据的动作识别方法在识别效果上会受到视频背景信息的影响,因此,本文首先对输入的视频数据进行处理,手动裁剪出人员所在区域,并将这些区域的图片作为数据输入识别网络。
将处理过的视频数据按时间序列逐帧输入残差网络[22](ResNet),通过残差网络编码视频帧所包含的色彩信息和轮廓信息,并将添加注意力机制的已编码数据输入conv LSTM[23](对时间序列信息进行编码)。整体网络结构如图4 所示。
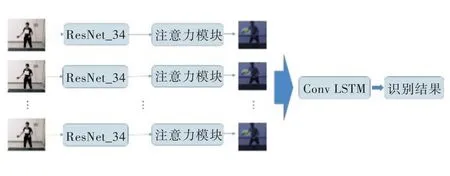
Fig.4 Action recognition network based on video data图4 基于视频数据的动作识别网络
2.3 双流融合的动作识别方法
基于视频数据的双流融合方法会先提取出视频数据的密集光流,使用CNN 同时处理视频数据和光流数据。将使用CNN 编码过后的特征信息输入SoftMax 分类器,该分类器会对每一组用于测试的数据进行分类,并输出该组数据属于某种类别的概率。对两种数据流的输出概率求均值,实现信息融合,信息融合后的综合识别率往往高于单个数据流的识别率。
本文借鉴这种信息融合方法,分别使用时空图卷积框架下的人体动作识别网络和基于视频数据的人体动作识别网络,并对网络进行训练。使用收敛后的参数进行测试,将每个视频片段的分类概率以矩阵形式保存。对两种数据流输出概率求均值后输出最终分类结果,如图5 所示。
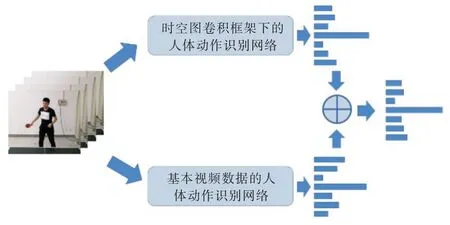
Fig.5 Two-stream fusion method图5 双流融合方法
3 实验结果与分析
使用NTU RGB+D 数据集[3]测试本文方法有效性。该数据集是目前较大的公开动作识别数据集,该数据集由56 880 个动作样本组成,包括40 名人员的60 种日常单人/双人动作(如喝水、脱衣服、键盘打字与走向某人等)。该数据集通过Kinect v2.0 采集包含25 个关节点的三维坐标的骨骼数据,并通过相机采集视频数据。
对于基于骨骼数据的动作识别网络,设置初始学习率为0.1,并且每10 个epochs 学习率缩小为原来的10%。网络训练共80 个epochs,使用标准交叉熵损失函数进行反向传播。
对于基于视频数据的动作识别完成后,设置初始学习率为0.001。网络训练300 个epochs,使用标准交叉熵损失函数进行反向传播。

Table 1 NTU RGB+D data set recognition results表1 NTU RGB+D 数据集识别结果
本文方法识别率达83.76%,比H-RNN、STA-LSTM、ST-GCN 方法的识别率均有不同程度的提升,对比结果如表1 所示。通过多人动作注意力热图可视化(见图6)结果可以发现,对于数据集中的双人动作,注意力热图往往只能关注其中一人,而对另一人关注度不足,导致该识别方法对动作分辨能力不佳,从而影响最终识别精度。

Fig.6 Multi-person action attention heat map visualization图6 多人动作注意力热图可视化
4 结语
本文提出一种针对动作识别的结合骨骼数据与视频数据的双流融合方法。该方法通过对人体动作的骨骼数据和视频数据分别建立网络模型,并对两种网络分类器的输出概率进行融合,有效地实现了骨骼数据与视频数据的信息融合,提高了人体动作识别率。
下一步计划是提出更好的信息融合方式,充分发挥不同类项数据优点,实现信息互补,进一步提高识别率。
