基于LSTM的轨道电路补偿电容故障数量预测
2021-02-03康玄烨赵林海孟景辉高利民
康玄烨,赵林海,孟景辉,高利民
(1. 北京交通大学 电子信息工程学院,北京 100044; 2. 中国铁道科学研究院集团有限公司 基础设施检测研究所,北京 100081; 3. 中国铁道科学研究院集团有限公司 铁路基础设施检测中心,北京 100081)
无绝缘轨道电路在我国高速铁路列车运行控制系统中占有非常重要的地位,其主要被用来检测列车占用和实现地-车间通信,以保障行车安全[1]。补偿电容作为无绝缘轨道电路的组成部分,主要用来改善信号在轨道线路中的传输性能[1]。由于补偿电容安装在室外,受外部环境和列车运行的影响较大,故障率相对较高[2],因此需要相应的运维部门提前准备好足量的备品以备更换。某电务段2017年1—12月所管辖范围内补偿电容的故障情况见图1。

图1 某电务段2017年1—12月补偿电容的故障情况
由图1可知,每月的补偿电容故障数并不相同,存在较大的波动。而由现场调研得知,补偿电容预备品数目是固定的,这往往会导致两种情况:一种是备品不够造成维修不及时;另一种是备品过多造成资源浪费,占用存贮空间。若能够准确预测近期内所辖范围内补偿电容的故障数量,则可更有效地准备备品,节约维修成本,合理安排维修计划。
近年来,随着我国铁路网的进一步发展,铁路基础设备不断增多,越来越多的研究者开始关注铁路设备的故障预测[3-5]。然而,国内外还没有补偿电容故障数量预测研究的相关报导。与此相关的只有文献[6],其基于相空间重构Kalman滤波求解单个补偿电容的剩余寿命,实现的是对单个补偿电容容值下降的故障预测。
本文基于铁路现场补偿电容的故障记录,构建补偿电容故障数量的时间序列,利用长短时记忆(Long Short-Term Memory,LSTM)设计故障数量预测模型,针对LSTM初始化超参数对预测模型性能有较大影响的问题,利用萤火虫算法对超参数进行优化,从而挖掘补偿电容故障数量随时间的变化规律,并实现对补偿电容故障数量的预测。实验表明,本文方法能较准确地预测补偿电容故障数量,误差相对较低,从而可以帮助铁路维护部门提前协调设备、资金和维修人员等资源,为补偿电容的运维提供良好指导。
1 整体思路
通常,铁路现场补偿电容故障历史记录中含有故障日期、故障位置和故障发生区段所属车站等信息。根据这些记录可构建补偿电容的故障数量时间序列,以挖掘该序列随时间的变化规律,从而实现对补偿电容故障数量的预测。考虑到现场是按一定的时间间隔和维修计划对补偿电容进行批量维护[7],故本文以“15天”为单位,即令时间间隔T=15,所构建补偿电容故障数量时间序列X为
(1)
式中:x(i)为补偿电容第i个时间间隔内的故障数量;xD(t)为补偿电容第t天的故障数量。
由于时间序列前后数据之间具有较强的依赖关系,而LSTM具备前馈神经网络不存在的横向连接,上一时刻隐含层的输出作为当前时刻隐含层输入的一部分,这种连接方式使其能够有效处理数据前后的依赖关系,并揭示数据间的长期依赖性[8],故本文基于LSTM构建预测模型,并利用萤火虫算法优化模型的超参数,从而实现对补偿电容故障数量的预测。基于LSTM的补偿电容故障数量预测算法框图见图2,主要包括LSTM预测模型构建和模型优化两部分。

图2 基于LSTM的补偿电容故障数量预测算法框图
由图2可知,LSTM预测模型构建部分主要包括:输入层、隐含层、输出层和网络训练4个环节。输入层根据初始化超参数将数量序列转换为与LSTM相适应的输入;隐含层是由LSTM构成的神经网络;输出层根据LSTM的输出计算补偿电容故障数量的预测值;网络训练根据预测值与实际值之间的损失更新隐含层和输出层的参数。模型优化部分利用萤火虫算法搜索预测模型最优的超参数,从而确定最优的预测模型,得到相应的补偿电容故障数量预测结果。
2 LSTM预测模型构建
2.1 预测模型框架
基于LSTM的预测模型框架见图3,其中:输入层对补偿电容故障数量序列进行预处理,并构建数据集;隐含层是LSTM的循环运算过程;在输出层中,加权平均层是对每一时刻LSTM的输出进行加权求和,Dropout用于提高网络泛化能力和健壮性[9],预测层计算预测结果;网络训练部分根据实际值与预测值之间的误差,利用AdaDelta算法[10]更新网络参数。
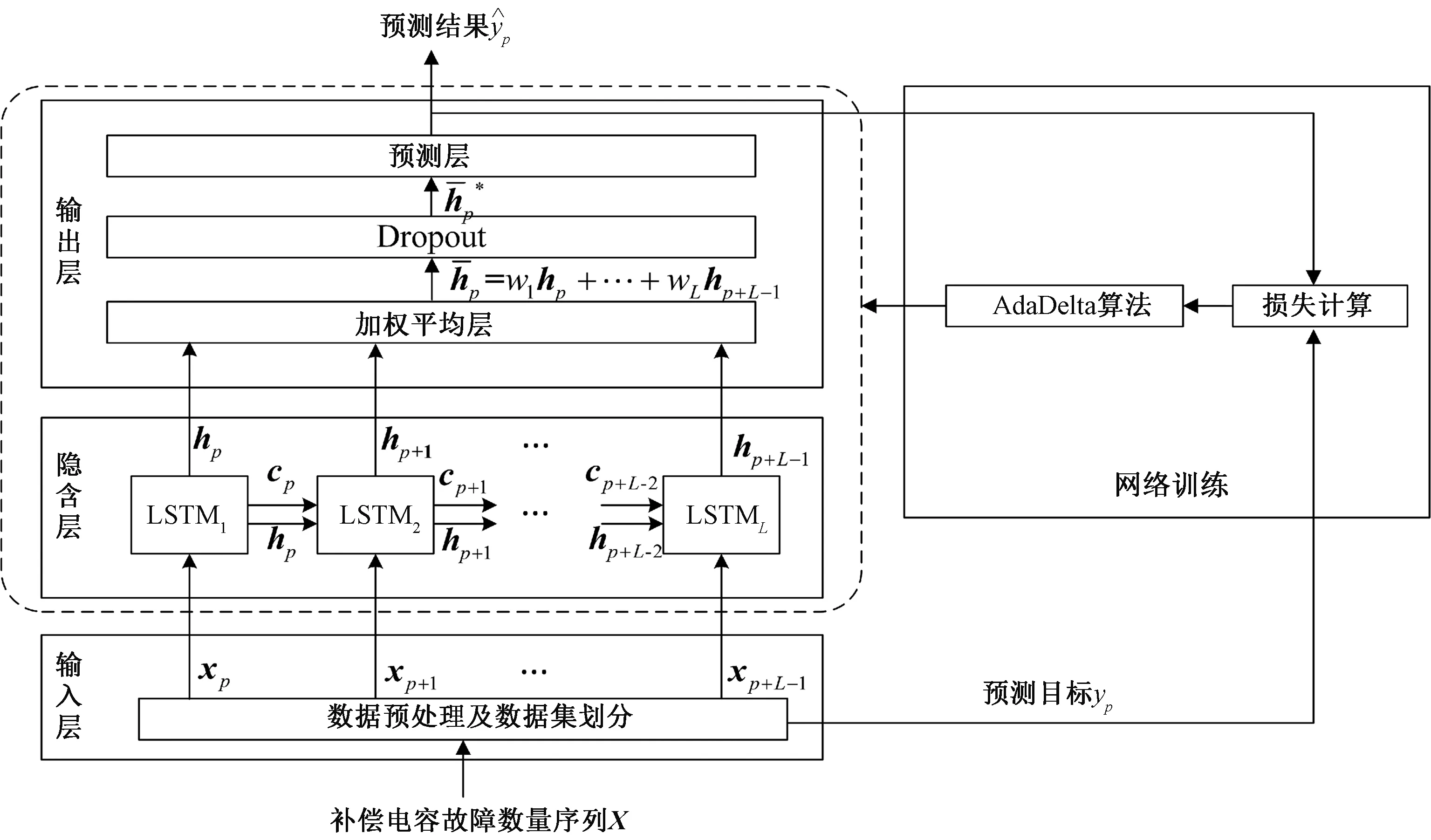
图3 基于LSTM的预测模型框架
2.2 输入层
设LSTM循环次数为L,序列分割窗口长度为m,由式(2)将数量序列X={x(i)|i=1,2,…,n}转换为LSTM的输入特征矩阵Xp及其对应的预测目标yp。
(2)
从而构建补偿电容故障数量的数据集{XB,Y}为
(3)
得到数据集{XB,Y}后,将其划分为训练集{Xtr,Ytr}、验证集{Xva,Yva}和测试集{Xte,Yte},为预测模型的训练和验证提供数据支持。
2.3 隐含层
LSTM的结构见图4,主要包括:信息激活、细胞单元、输入门、输出门和遗忘门等5部分。
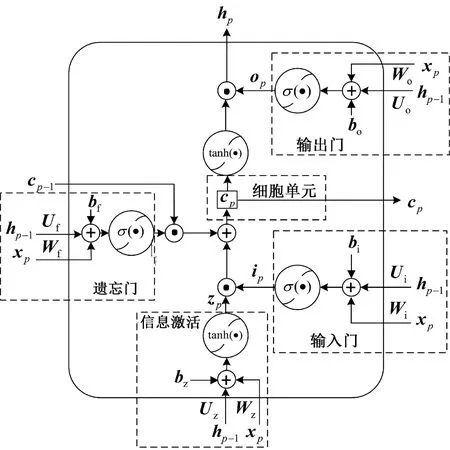
图4 LSTM的结构
图4中:hp-1和xp分别为p-1时刻和p时刻LSTM的输出和外部输入;在输入门、输出门和遗忘门中,hp-1和xp分别与各门对应权值矩阵Ui、Uo、Uf和Wi、Wo、Wf相乘,再与对应的偏置向量bi、bo、bf相加后,经激活函数σ(·)得到各门p时刻输出结果ip,op,fp;信息激活过程中,hp-1和xp分别与对应权值矩阵Uz和Wz相乘,再与对应的偏置向量bz相加后,经激活函数tanh(·)得到p时刻输出结果zp;p-1时刻细胞单元cp-1与遗忘门的输出fp点乘,再与ip和zp点乘的结果相加,得到p时刻细胞单元cp;cp经激活函数tanh(·)后,再与输出门的输出op点乘得到p时刻LSTM的输出hp。上述过程可描述为
(4)
式中:⊙为点乘运算;σ(·)为sigmoid函数;tanh(·)为双曲正切函数。
2.4 输出层
输出层包括:加权平均层、Dropout和预测层3部分。考虑到时间序列前后依赖关系的强弱,为了更充分地描述各时刻LSTM输出对预测结果的影响,对各时刻LSTM的输出进行加权求和,即
(5)
(6)
再经过预测层得到预测结果为
(7)
式中:I为服从P=0.5,0-1分布的随机向量;Wy为预测层的权重矩阵;by为预测层的偏置向量。
2.5 网络训练
(8)

(9)
由AdaDelta算法得到参数θt的更新公式为
(10)

根据式(8)~式(10)更新预测模型中隐含层和输出层的参数,满足停止条件后,终止模型的训练过程,得到完成训练后的预测模型。
3 模型优化
预测模型需要设置的初始化超参数包括:LSTM循环次数L、窗口长度m和神经元个数r。将训练完成的模型记作:LSTM(L,m,r)。由于不同的超参数组合(L,m,r)对模型能够达到的预测精度有较大的影响,为了使模型预测结果达到最优,故利用基于权重的萤火虫算法[11]搜索超参数的最优组合。
3.1 算法流程
在萤火虫群优化算法中,萤火虫不分性别,每只萤火虫被视为解空间的一个解,萤火虫种群作为初始解随机地分布在搜索空间中,它将会被其他比它更亮的萤火虫吸引;萤火虫的吸引力与亮度成正比,对于任何两只萤火虫,其中一只会向着比它更亮的另一只移动,亮度随着距离的增加而减少;如果没有找到一个比给定的萤火虫更亮,它会随机移动,最终萤火虫聚集到亮度高的萤火虫周围。萤火虫算法优化预测模型超参数的流程见图5,主要包括:萤火虫初始化、模型构建、目标函数计算、萤火虫位置更新和最优模型确定等5个环节。

图5 萤火虫算法优化预测模型超参数的流程
3.2 萤火虫初始化
将LSTM循环次数L、窗口长度m和神经元个数r的组合(L,m,r)定义为萤火虫的三维搜索空间,设各超参数的取值范围为
(11)
式中:Z+为正整数集;Lmin,mmin,rmin为取值下限;Lmax,mmax,rmax为取值上限。
设萤火虫数量为M,第i只萤火虫的空间位置为Ai=(Li,mi,ri);光强吸收系数为γ,最大吸引度为β0,步长因子为α;最大、最小权重为wmax,wmin,最大更新代数为Smax。
将萤火虫随机分布于三维空间,并设第i只萤火虫与第j只萤火虫之间的距离dij为欧式距离,即
3.3 模型构建
根据第2节预测模型构建,每一只萤火虫都可构建出与其所处空间位置相对应的预测模型,通过网络训练过程,将第i只萤火虫对应训练完成的预测模型记作:LSTM(Li,mi,ri)。
3.4 目标函数计算
由于预测模型训练过程中是以均方误差作为损失函数,若萤火虫算法依然以均方误差作为目标函数,可能导致预测结果偏向均方误差小的方向,不利于模型预测性能。在保证模型泛化能力的同时,为使得预测结果在平均绝对误差与均方误差之间达到相对最优,故以验证集{Xva,Yva}的平均绝对误差最小作为萤火虫算法的目标函数。
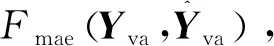

3.5 萤火虫位置更新
萤火虫向着荧光亮度比自身高的萤火虫所在方向移动,它们之间的吸引度决定了萤火虫的移动步长。萤火虫i,j之间的吸引度为
β=β0×e-γdij2
(14)
由式(14)可进一步得到萤火虫的位置更新公式为
(15)
式中:R为[0,1]上服从均匀分布的随机数;S为萤火虫当前更新代数。
3.6 最优模型确定
在满足萤火虫算法停止条件后,计算每一只萤火虫自身的荧光亮度。设(Lz,mz,rz)满足I(Lz,mz,rz)=max[I(L,m,r)],此时预测模型LSTM(Lz,mz,rz)的平均绝对误差取最小值,即为最优预测模型。
4 实例验证
为验证本文所提出方法的准确性和有效性,基于某铁路局电务段2014年8月至 2019年5月约58个月的补偿电容故障记录,其中记录了补偿电容故障时间和数量等信息,按式(1)构建序列长度为112的故障数量时间序列,并用前100个故障数据训练预测模型,再用后12个故障数据检验所构建模型的预测效果。
4.1 模型构建功能验证
由式(1)构建补偿电容故障数量时间序列X={x(i)|i=1,2,…,n},见图6。

图6 补偿电容故障数量时间序列
设LSTM循环次数L∈[2,12],窗口长度m∈[5,30],神经元个数r∈[5,60]。设寻优算法中萤火虫数量M=20,步长因子α=0.2,光强吸收系数γ=1.0,最大吸引度β0=1.0,最大权重wmax=1.1,最小权重wmin=0.2,最大更新代数Smax=15。设测试集{Xte,Yte}样本量为12,将除测试集外的剩余样本按0.8和0.2的比例分为训练集和验证集,按第3节基于萤火虫算法的预测模型超参数优化对超参数进行寻优,得到最优预测模型为LSTM(Lz,mz,rz)=LSTM(6,11,51)。
网络训练过程中,模型LSTM(6,11,51)在训练集、验证集和测试集的损失见图7。

图7 训练过程中模型LSTM(6,11,51)在各数据集上的损失
由图7可知,在AdaDelta算法迭代至110次时,预测模型在验证集的损失达到最小,此时预测模型网络参数相对最优。
4.2 模型预测性能验证
为量化预测模型对故障数量序列的拟合效果,本文引入均方根误差RMSE和平均绝对误差MAE作为模型预测精度的评价指标,误差越小拟合效果越好。
(16)
(17)

由式(16)和(17)求得预测模型的训练集RMSE=0.825,MAE=0.625,测试集RMSE=1.224,MAE=0.833,说明预测模型较准确地挖掘了补偿电容故障数量随时间的变化规律,整体误差相对较小。此外,训练集与测试集的各评价指标之间相差不大,说明预测模型具有良好的泛化能力,并能够达到较好的预测效果。
设训练集均方误差为RMSEtr,为更好地描述补偿电容故障数量,假定模型预测误差服从均值为0,方差为RMSEtr的正态分布,给出故障数量的取值范围为
(18)
从而得到预测模型LSTM(6,11,51)在训练集的拟合结果(见图8)和在测试集的预测结果(见图9)。

图8 训练集拟合结果
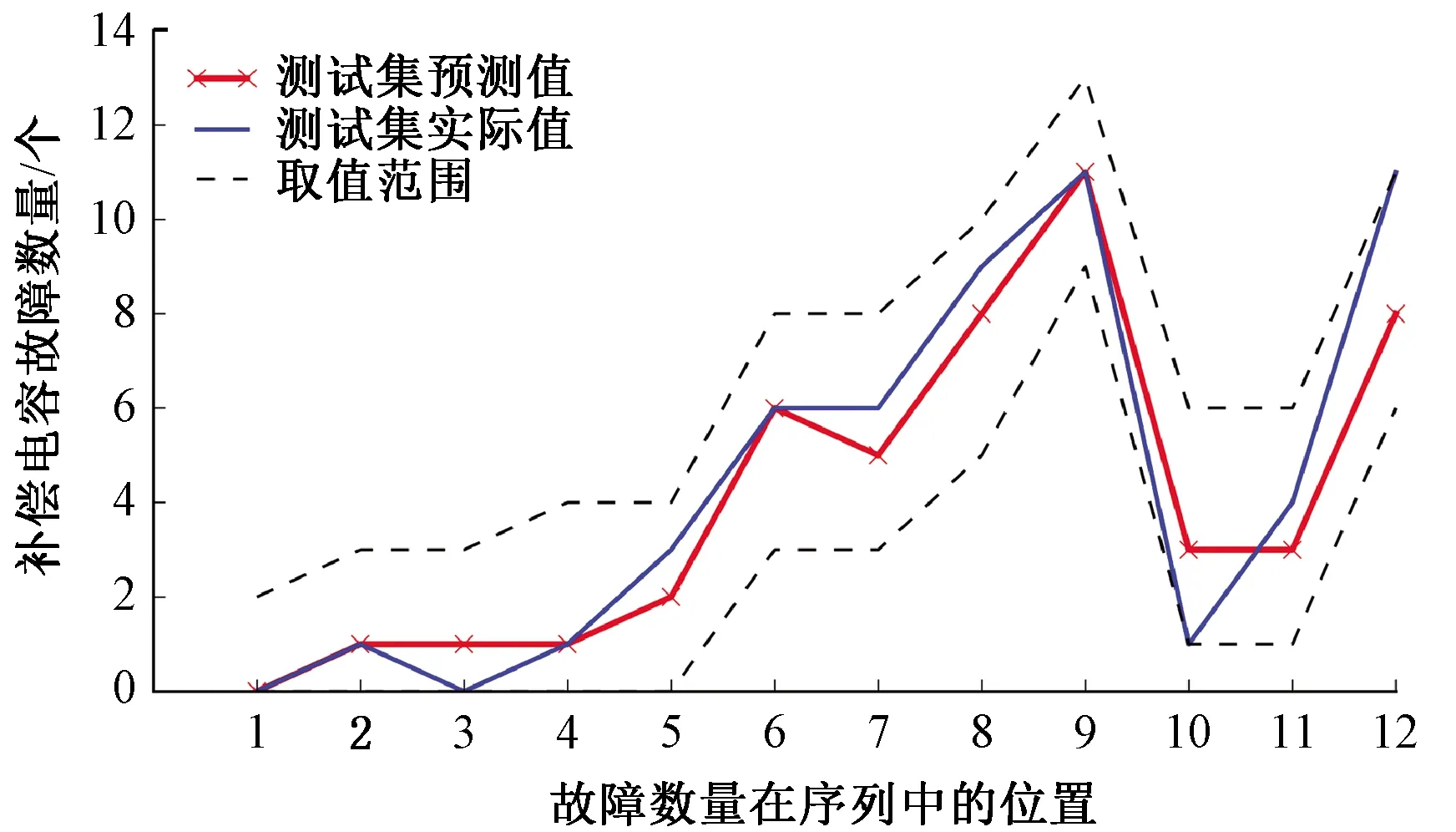
图9 测试集预测结果
由图8可知,预测模型拟合曲线与实际曲线大体吻合,且实际值基本处于取值范围内,表明LSTM能较好地跟踪补偿电容故障数量随时间的变化规律。由图9可知,LSTM模型较好地预测了补偿电容的故障数量,实际值均处于取值范围内,预测值与实际值之间的最大绝对误差为3,取得了良好的预测效果。
5 结束语
基于铁路现场的补偿电容故障记录,本文提出了一种预测补偿电容故障数量的方法。该方法首先根据补偿电容故障记录构建补偿电容故障数量随时间变化的序列;再基于LSTM构建了故障数量预测模型,针对LSTM初始化超参数对预测模型性能有较大影响的问题,利用萤火虫算法对超参数进行优化,从而挖掘补偿电容故障数量随时间的变化规律,并实现对补偿电容未来一段时间内故障数量的预测。实验部分,某路局电务段的实际数据被用来检验本文方法各步骤的功能,实验中对后12个数据点进行了预测,预测结果的均方根误差和平均绝对误差分别为1.224和0.833。可见,使用本文方法可以有效地预测补偿电容故障数量,从而帮助铁路部门提前协调设备、资金和维修人员等资源,为补偿电容运维提供良好的指导,给补偿电容故障预测的研究提供了新思路。
