基于统计建模的HEVC 快速率失真估计算法
2021-02-01孟翔殷海兵黄晓峰
孟翔,殷海兵,黄晓峰
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
1 引言
随着各种对高清视频的需求,JCT-VC 提出了新一代高效视频编码(HEVC)标准[1],其采用高级编码工具,包括基于四叉树的编码单元(coding unit,CU)、变换单元(transform unit,TU)以及预测单元(prediction unit,PU)。与H.264[2]相比,在相同图像质量情况下,HEVC 可以节省高达50%的比特率。
CU/PU/TU 的组合方案可以大大提高编码效率,但是基于率失真优化(rate distortion optimization,RDO)[3]的模式决策都需要为大量候选模式进行RDO 成本计算,其中涉及前向变换、量化、逆量化、逆变换和熵编码,这会造成极大的计算复杂度,阻碍了有效并行技术,导致硬件实现效率降低。
一些学者针对如何减少码率和失真的计算复杂度问题展开研究,Zhao 等[4]提出广义高斯分布模型来估计码率,使用在量化中丢掉的比特来估计失真;Tu 等[5]和Wang 等[6]采用量化系数之和与其对应系数坐标来估计码率;Liu等[7]提出一种基于二元分类的线性模型来估计码率。Sun 等[8]尝试简化RDO 过程,使用变换系数来估计码率和失真,Chen 等[9]和Sharabayko等[10]采用信息熵来估计码率。考虑到硬件资源,一些学者提出了有利于硬件实现的快速RDO 算法[11-14],虽然节省了大量的硬件资源,但是算法过于简单造成了严重的性能损失。现有工作并未充分探索熵编码特性,这会导致压缩质量显著下降[15]。
本文的主要贡献如下:对每个语法元素进行码率分析,并根据结果建立码率模型;提出一种加权量化系数,能够较好地反映码率信息;采用建模的方式估计头信息码率;从变换域建模估计失真,避免多余的重构过程;避免了上下文概率状态的实时更新,有利于硬件实现。
2 码率与失真估计算法
HEVC 原始的码率与失真计算流程如图1 所示,其中熵编码技术会涉及上下文状态的实时更新,系数之间产生较强的依赖性,这不利于硬件并发的实现并会产生很大的编码复杂度,失真计算会经过冗长的重构过程,进一步加剧了编码的复杂性。
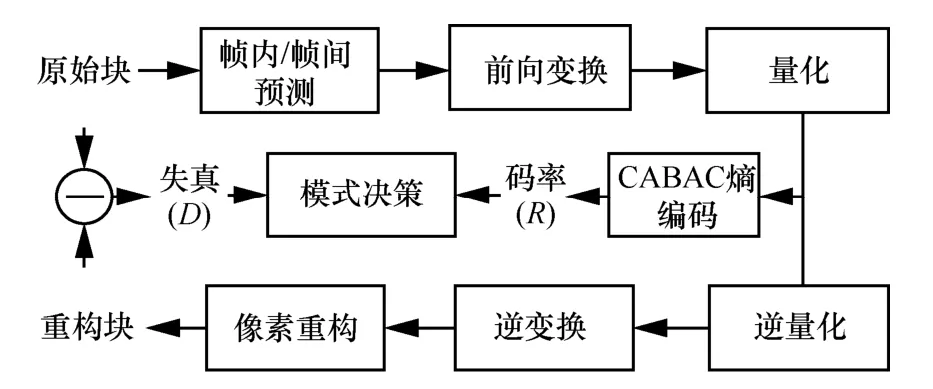
图1 HEVC 原始码率失真计算流程
为了简化编码的复杂度,采用码率与失真预估的方式来替代原有的计算过程。引入码率失真算法后的计算过程如图2 所示,可以看出码率失真预估算法大大简化了原始HEVC 算法的流程,同时避免了上下文概率状态的实时更新和冗长的重构过程,更有利于硬件并发与流水线技术的实施。

图2 引入码率失真算法后的计算过程
在RDO 过程中,码率一般由两部分组成:

其中,Rhead表示编码头信息所需码率,Rres代表编码量化系数所需码率。在编码量化系数时,需要编码多个语法元素。
首先,变换单元会被分为若干个4×4 大小的系数块组(coefficient group,CG),按反向扫描顺序首先扫描到的非零系数为最后一个非零系数位置(last coefficient position,LCP),编码器需要对LCP 信息进行编码,然后对每个CG 进行判断,代码子块标志(code sub block flag,CSBF)表示该 CG 内是否存在非零系数,有效系数标志(significant coefficient flag,SCF)表示当前系数是否非零,系数符号标志(coefficient sign flag,CSF)表示当前系数是否为正,前8 个非零系数中,系数大于1(greater than 1,G1)表示当前系数绝对值是否大于1,对于第一个大于1 的系数,系数大于2(greater than 2,G2)表示该系数绝对值是否大于2,最后系数剩余部分(remaining,RM)会被编码。
为了更加直观地分析码率,本文统计了在不同TU 大小和不同量化参数(quantization parameter,QP)下,各个语法元素所占的码率比重,如图3 所示,编码模式为随机访问(random access,RA)模式,可以看出,在TU 4×4 和TU 8×8 大小下,LCP 语法元素占有较大比重,分别为32.2%与25.8%,G1 与CSF 语法元素码率占比较为均匀,SCF 码率综合占比最大,因此如何着重分析码率占比较大的语法元素非常关键。
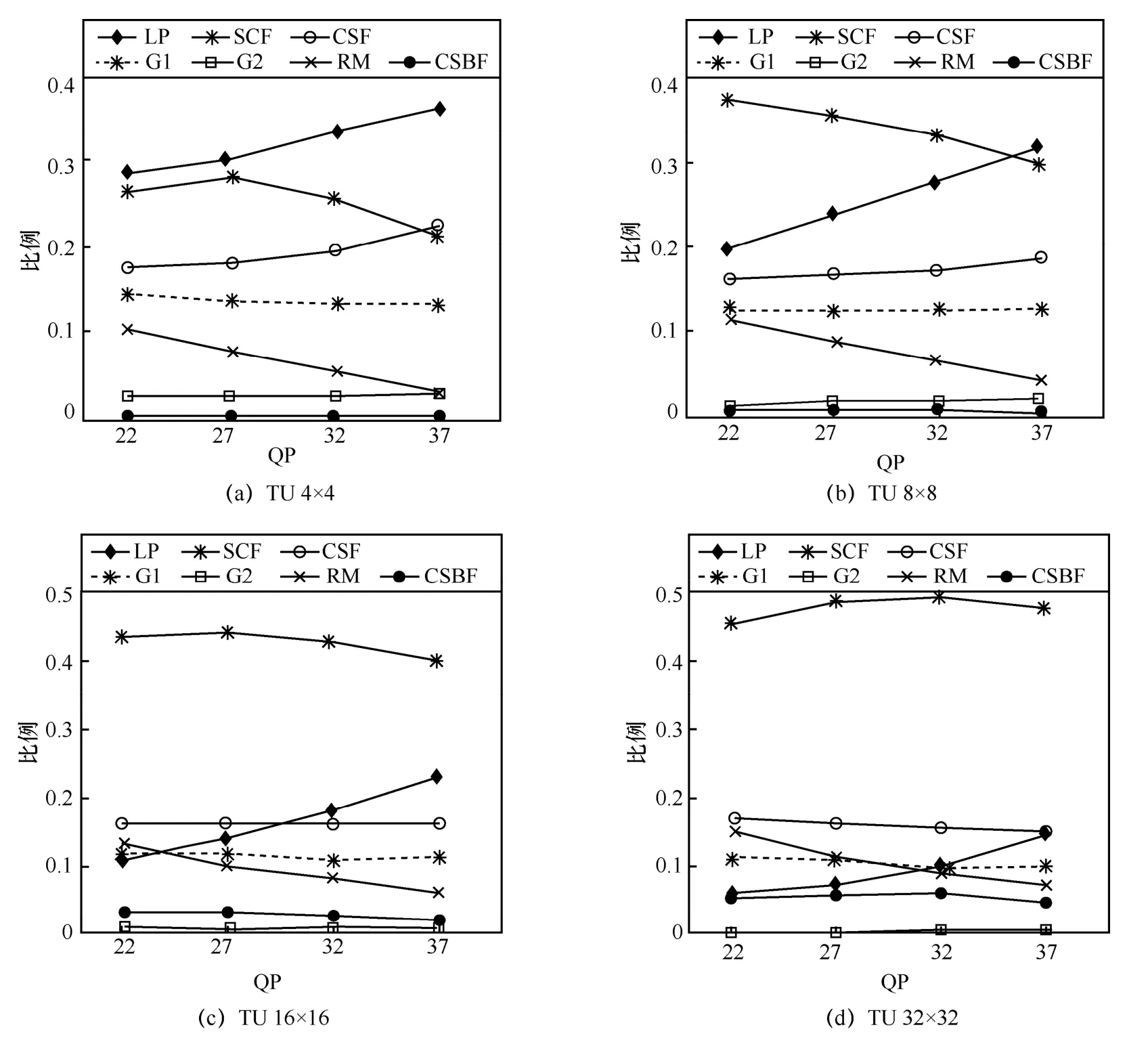
图3 TU 级别下各语法元素码率比重
3 头信息码率预估
3.1 帧间预测跳过标志的码率估计
跳过模式是合并模式的一种特殊情况,其CU 内不包含任何残差信息。对于每个单元,CU跳过标志被用来表示该CU 是否为跳过模式。其根据相邻CU 跳过标志的不同会使用3 种上下文模型。本文实验发现跳过标志所消耗的码率均值在不同QP 下有着较强的线性关系。当相邻单元均为非跳过模式时,码率与QP 之间的关系如图4 所示。

图4 跳过标志码率与QP 的关系
其中,R_0 和R_1 分别表示编码0(非跳过模式)和1(跳过模式)所消耗的码率。实验测试环境为RA 编码模式,测试序列为BasketballPass,测试帧数为30。图4 中的×表示各QP 下码率消耗的平均值。事实上,随着QP 的增加,CU 更有可能被编码为跳过模式。因此,编码1 消耗的比特逐渐减少,编码0 消耗的比特逐渐增加。
因此可以根据QP 进行建模,式(2)中定义了跳过标志的码率估计模型。
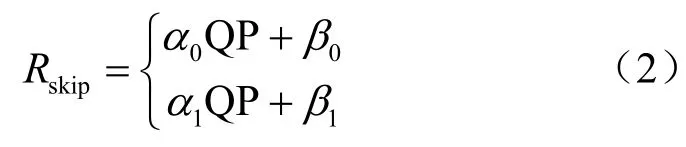
其中,0α与0β表示编码0 时的模型系数,1α与1β表示编码1 时的模型系数,在相邻单元都为非跳过模式时,0α=0.016 89,0β=0.183 3,1α=−0.107 3,1β=5.814。当相邻单元只有一个为跳过模式或都为跳过模式时,其码率模型可以采用相同的方法分析。
3.2 预测模式的码率估计
在头文件码率中,编码预测模式所消耗码率占有较大比例,对亮度块来说,最优预测模式从两类中选出,一类是来自相邻单元的3 种高概率模式(most probability mode,MPM),另一类为低概率模式(low probability mode,LPM)。prev_intra_luma 会被用来描述该模式是否为MPM模式,与跳过标志建模类似,QP 与码率关系如图5所示。
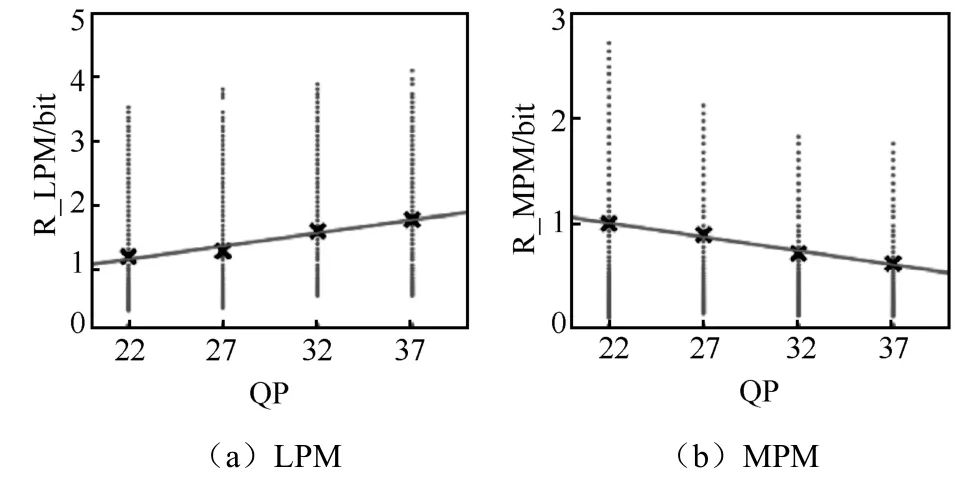
图5 预测模式QP 与码率的关系
最后该部分模型如式(3)所示:
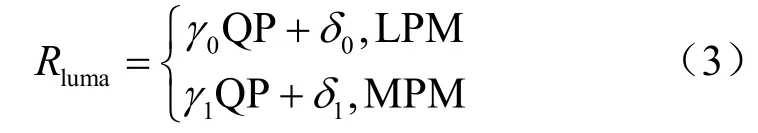
其中,0γ=0.041 73,0δ=0.138 4,1γ=−0.026 8,1δ=1.578。
对于色度块,从5 个候选模式中选择最佳模式。intra_chroma_pred_mode 用于描述最佳模式是否与最佳亮度模式相同,该部分建模类似于prev_intra_luma。
4 残差系数码率估计
4.1 基于加权量化系数的量化系数和
在现有工作中,Sheng[16]采用量化系数总和(sum quantized coefficient,SQC)作为系数部分码率估计的特征。但是,当TU 的SQC 相同时,其码率消耗会有较大的差异。造成这一误差的原因之一是:在编码过程中,上下文概率模型转换会导致严重的系数间串行依赖。为解决此问题,本文提出加权量化系数总和(sum weighted quantized coefficient,SWQC)。
在图3 中,SCF 语法元素总体比其他语法元素占据更大的比例。因此,本文重点分析因编码SCF 语法元素而产生的系数依赖性。实际上,SCF的上下文模型选择受许多因素影响,包括当前块是否为亮度块、下方和右侧的CSBF 值等。因此,本文将CG 分为7 类,如图6 所示。

图6 加权量化系数的分类方法
在图6 中,CSBF(0,0)代表下方和右方CG的CSBF 值均为0。TU 4×4 为第1 类。对于第一个CG,存在DC 系数并且为低频区域,非零系数多于其他CG,因此将第一个CG 分为第2 类。最后一个非零CG 具有LP 语法元素,分为第3 类。根据下方和右方CSBF 取值分为第4、5、6、7 类。
本文使用线性回归方法确定权重,使用CG级别码率进行训练。不同组将获得不同的权重,加权量化系数总和累积作为TU 级码率估计的特征。第3 类中有一个特殊情况,最后一个非零CG具有LP 语法元素,其码率消耗主要来自LP 信息,为了简化算法,将第3 类的权重设置为1。该部分码率模型如式(4)所示:

其中,W kj代表权重系数,k表示由图6 确定的CG 类别,Lij代表量化系数,N为TU 块大小。在QP 为32时,各TU 大小下Rwqc与码率之间关系如图7 所示。

图7 TU 级别加权量化系数总和与码率的关系
权重系数从序列BasketballPass 获得。将其应用于序列BQsquare,其与TU 级别码率的相关系数(R2)与均方差(MSE)见表1,其中拟合方式均为线性拟合,拟合公式为y=ax+b,其中a、b为模型参数。可以看到SWQC 比SQC具有更小的均方差和更高的相关系数。这证明了使用SWQC 在码率估计方面将获得更高的精准度。

表1 均方差与相关系数
4.2 位置参数以及其他特征参数
在熵编码中,高概率事件将消耗较少的比特,而低概率事件将消耗较多的比特。经过变换、量化等步骤后,非零系数出现在低频区域的概率要大于高频区域。因此,码率消耗将随着系数分布的不同而有着较大的变化。本文定义ηc为CG 级别最后一个非零系数的正向扫描位置。当ηc较小时,表示非零系数分布在低频区域。ηz表示CG内第一个与最后一个非零系数之间的零系数个数。当ηz较小时,表示非零系数分布更加集中。这两个特征可以很好地描述系数的分布,该部分码率定义如下:

QP 为32 时,其与码率的关系如图8 所示。
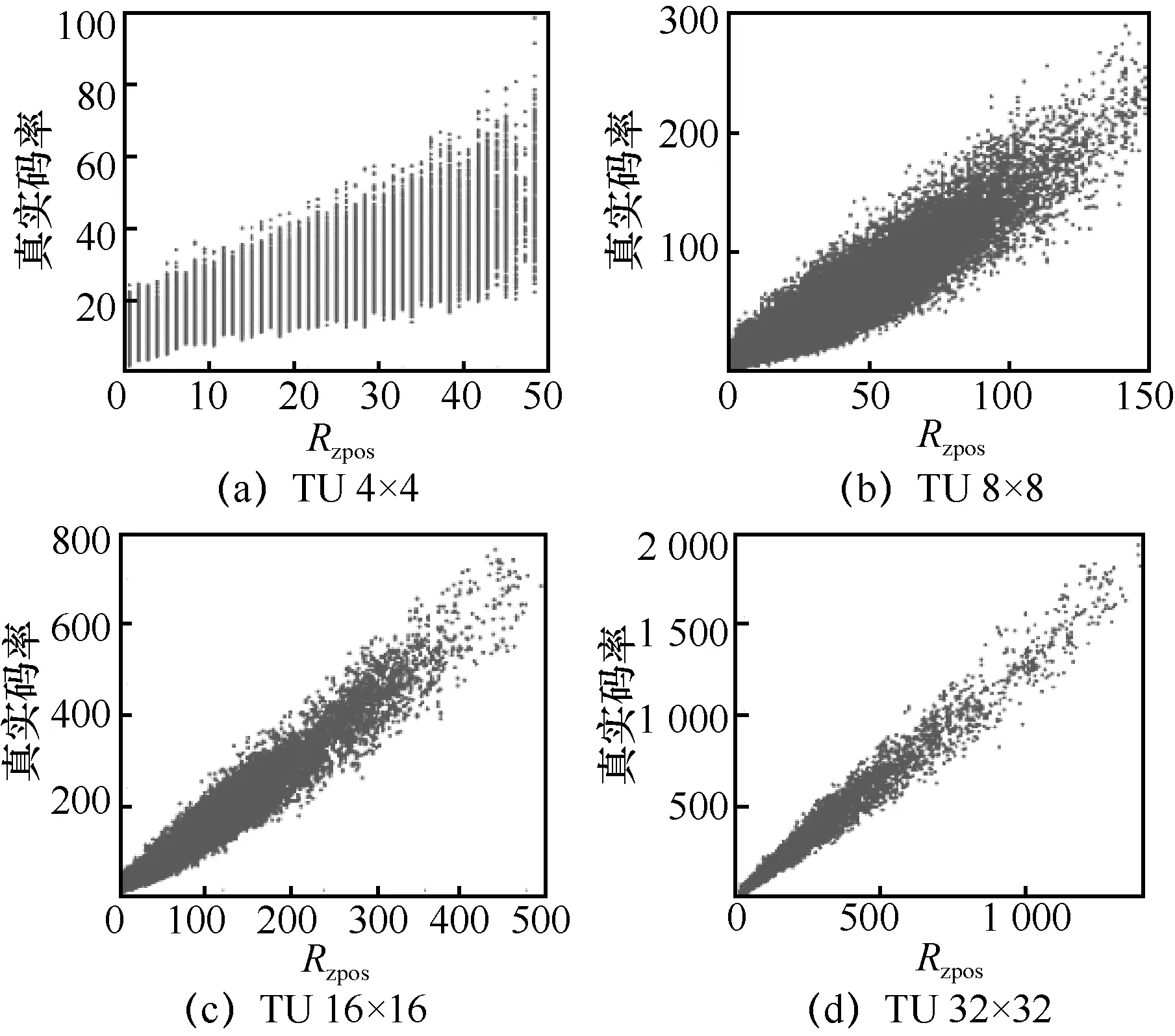
图8 TU 级别位置信息与码率的关系
在TU 4×4 与TU 8×8 两种情况下,编码LCP位置信息时,其码率占比较大,由图3 可知其占比分别达到32.2%与25.8%,但是TU 16×16 与TU 32×32情况下,其码率占比只有16.7%与9.1%。在考虑到模型复杂度与硬件资源的情况下,本文只针对TU 4×4 与TU 8×8 情况考虑LCP 位置信息,LCP 语法元素码率组成如下:

其中,Rpre表示前缀码,采用常规编码模式;Rsuf为后缀码,采用等概率编码模式;本文定义特征bη为前缀码和后缀码的总码元个数,并使用它来估计编码LCP 信息所消耗的码率。
此外,在不同TU 大小下,各个语法元素码率占比波动较大,但CSF 语法元素却很平稳,占比平均为17.1%,因为该语法元素采用等概率编码方式,因此本文定义特征nη为非零系数个数并纳入考虑范围。
4.3 最终码率模型以及码率估计算法实现过程
最终模型如下:

其中,bη只有在TU 大小为4×4 与8×8 的情况下才会使用;0θ~4θ为模型参数,由线性回归训练所得到。图9 为QP 等于32 时,REst与真实码率之间的关系,测试序列为BasketballPass。可以看出,两者之间有着很强的线性关系。
图9 预估码率与真实码率的关系
码率估计算法流程如下。
输入量化系数矩阵L,4×4 权重矩阵kW 。
输出预估码率REst。
说明量化系数矩阵L尺寸取决于当前TU块尺寸,取值范围为4×4、8×8、16×16、32×32。K取值范围为1~7,由图6 所示方法决定。步骤3中C为系数组矩阵,大小为4×4。
步骤1根据式(2)、式(3)计算头信息码率。
步骤2遍历系数矩阵L,确定LCP 位置并计算bη参数。
步骤3当前TU 大小为4×4,计算Rwqc=否则计算
步骤4统计cη参数,同时记录零系数的个数zη,根据式(5)计算出Rzpos。
步骤5统计非零系数个数nη,遍历L结束。
步骤6如果TU 尺寸为4×4、8×8,根据式(7)得出REst;否则令ηb= 0,代入式(7)得出REst。
码率估计算法流程如图10 所示。
5 失真预估
在HEVC 中,计算量化过程如下:

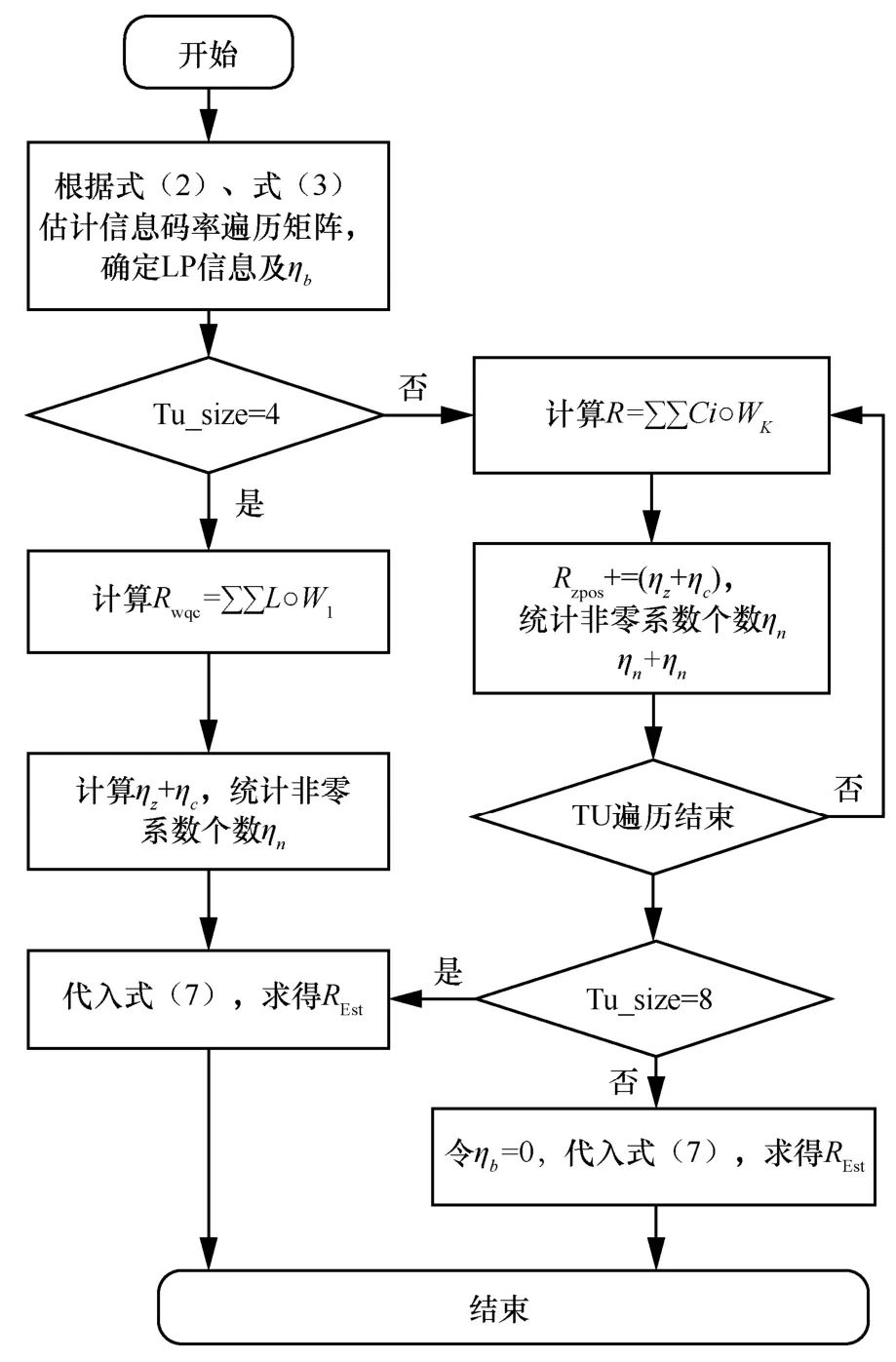
图10 码率估计算法流程
其中,Q ij为量化值,y ij为变换系数,Sc =2qbits/Qstep是和QP 有关的缩放系数。在变换域中,失真可以由式(9)统计:

其中,y为变换系数,yi为重构后的变换系数。为了简化重构过程,本文分别定义了原始缩放后系数Pi j=yij×Sc 和近似重构后的变换系数Ti j=Qij≪iQBits,并统计了两者间的差异,定义如下:

因此被缩放后失真近似为:

将式(11)代入式(9):
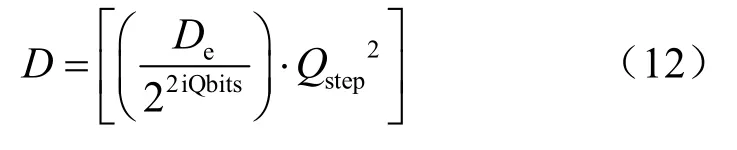
其中,iQbits=qbits+shift,化简后有:

其中,shift 是与TU 大小有关的偏移量。为了更精准地估计码率,本文引入与QP 相关的模型参数α(QP)其在QP 取值为22、27、32、37 时分别等于0.86、0.89、0.92、0.95。预估失真与真实失真关系如图11 所示。
失真估计算法具体流程如下。
输入量化系数矩阵Q,变换系数矩阵Y。
输出预估失真DEst。
步骤1遍历系数矩阵Q,计算Tij=Qij≪iQBits,得到近似重构后的变换系数。
步骤2计算dij=(Pij−Qij≪iQBits)2,为该系数缩放后失真。
步骤3去除缩放比例,由式(13)得到
步骤4矩阵Q遍历结束,引入α(QP)模型参数,累加得
由以上可以看出,失真的计算在进行前向变换量化的时候就已经计算完毕,省去了逆变换、逆量化、重构等过程。这种做法虽然忽视了逆量化、逆变换因取整和位移等操作造成的误差,但是这些误差的数值很小,在可接受范围内,同时可以节省大量的时间。从图11 可以看出,预估失真与真实失真有着很强的线性关系,这也证明了本文失真估计算法的优越性。
6 实验结果分析
为了评估文中所提出的快速码率失真估计算法,采用HEVC 参考代码HM16.0 进行实验,实验配置为:RA 模式,关闭RDOQ 功能,关闭变换跳过功能,其余均为默认配置。实验中QP 取值为:22、27、32、37。实验采用H.265 标准测试序列[17]进行测试,码率变化率(BD-BR)[18]当作评价指标。
为了衡量计算复杂度的变化,本文定义了时间变化率TΔ 定义如下:

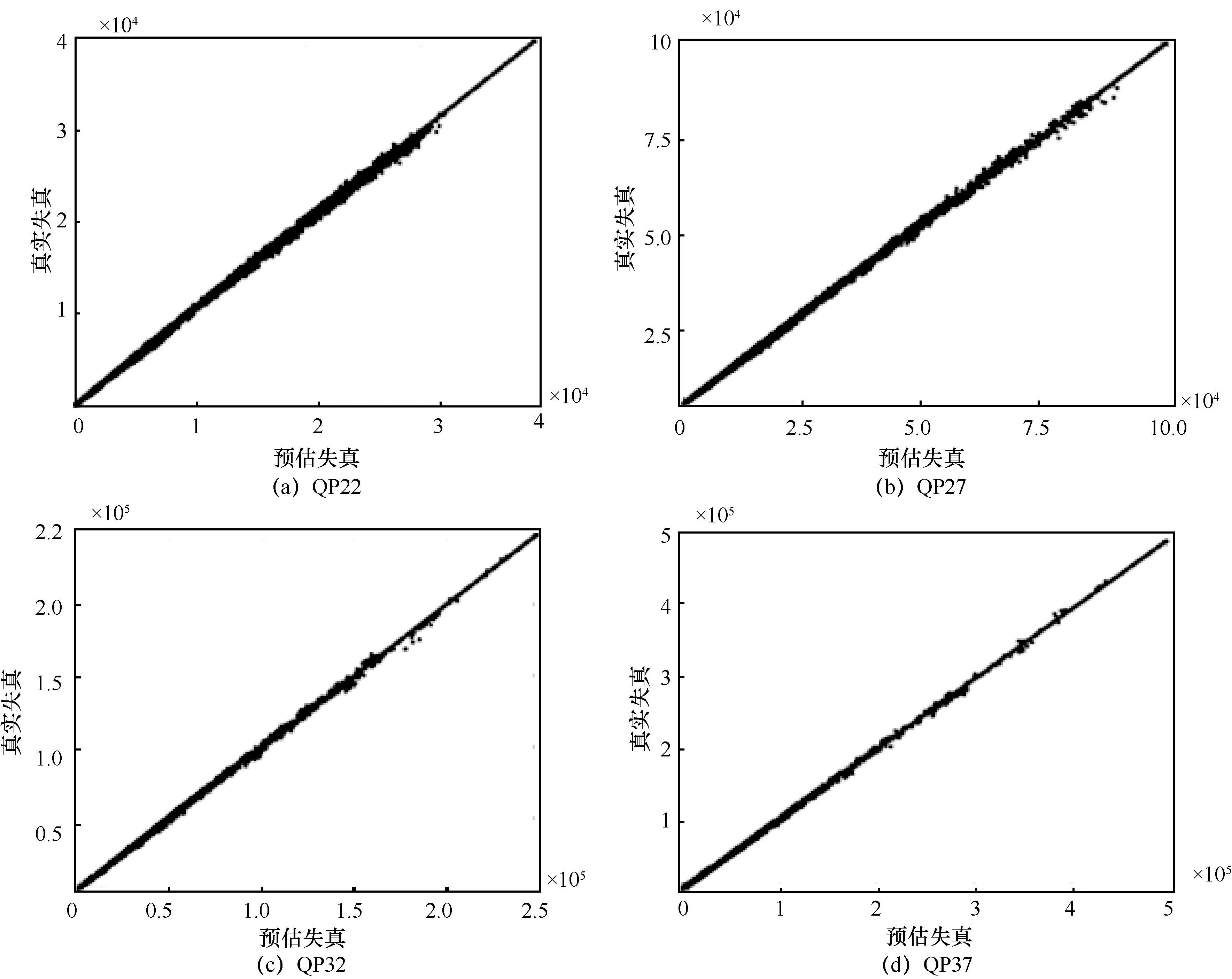
图11 预估失真与真实失真的关系
其中,TProRDO为本算法进行RDO 过程所消耗的时间,THMRDO为原始HEVC 算法进行RDO 过程所消耗的时间,ΔT为正表示编码时间的减少,与HM 算法相比,本文快速算法的率失真性能和整体表现见表2。其中,*表示仅使用码率预估的性能损失,**表示码率与失真预估的性能损失。表2中还列出了近年来典型的码率失真估计算法,并做了比较。
与原始HM 算法相比,只使用码率估计算法,参考文献[9]的算法BD-BR 总体上升1.32%,本文算法BD-BR 总体上升0.96%,性能提升0.36%,对于有较多细节画面的视频序列,例如PartyScene、BQsquare、BasketballPass 和SlideEditing,参考文献[9]的算法BD-BR 分别上升1.92%、1.68%、1.31%、1.81%,性能损失较为严重,本文算法在这些序列下BD-BR 分别上升0.75%、0.43%、0.37%、1.24%,皆优于参考文献[9]。对于平稳的序列,例如 FourPeople、Johnny 和KristenAndSara,参考文献[9]算法BD-BR 分别上升1.17%、1.35%、1.57%。同样地,本文算法BD-BR分别上升1.09%、1.16%、1.12%,因此无论是在具有较多细节还是较为平稳的视频序列中,本文算法皆优于参考文献[9]提出的算法。
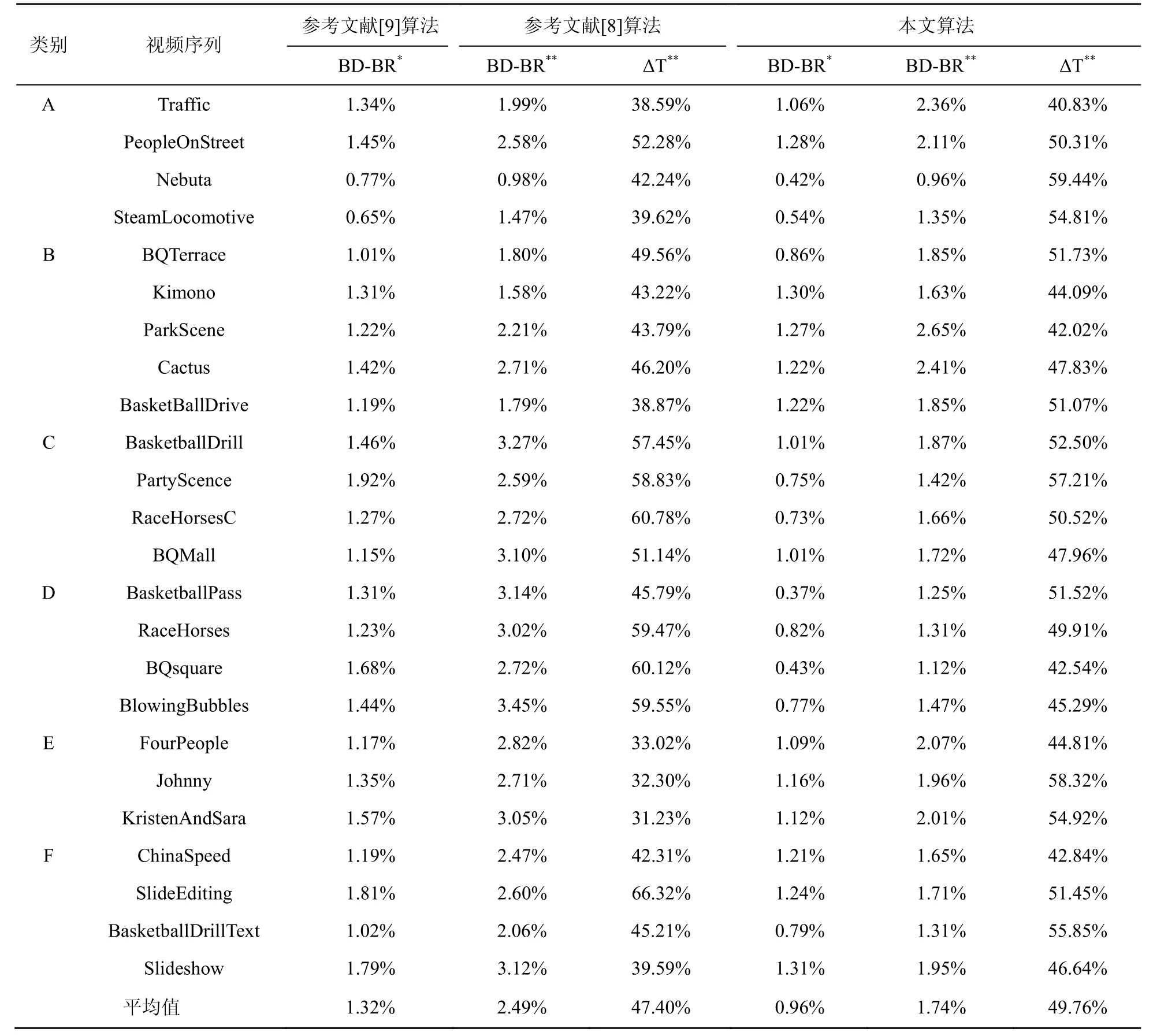
表2 在Random Access 下的模型性能
在同时使用码率估计与失真估计算法时,相较于原始HM 算法,参考文献[8]的算法BD-BR总体上升2.49%,同时RDO 时间节省47.40%。对于高分辨率的视频序列,如Traffic、Nebuta、Kimono,其BD-BR 分别上升1.99%、0.98%、1.58%,性能损失较低;对于低分辨率的序列,即D 类视频序列,其BD-BR 上升分别为3.14%、3.02%、2.72%、3.45%,性能损失较大,这说明参考文献[8]的算法在高分辨率的序列上有着较好的性能。在时间节省方面,参考文献[8]的算法在序列SlideEditing 和RaceHorses 可以达到66.32%和60.78%,但是在Johnny 和KristenAndSara 序列下,其时间节省仅为32.30%与31.23%,最大值与最小值之间相差35%,这说明参考文献[8]的算法时间节省并不均匀,其算法不具有较强的普适性。本文在同时使用码率与失真估计算法时,BD-BR 总体上升了1.74%,RDO 时间节省49.76%,相较于参考文献[8]的算法,性能有0.75%的性能提升,同时多获得了2.36%的时间节省。对于高分辨率的视频序列,如Traffic、Nebuta、Kimono,其BD-BR分别上升2.36%、0.96%、1.63%;在低分辨率视频序列(D 类)下,本文算法BD-BR 仅上升1.25%、1.31%、1.12%、1.47%,这证明了本文算法有着更好的率失真性能。在序列Nebuta 中,本文可以达到59.44%的RDO 时间节省,为测试序列中的最大值;在序列Traffic 中可以达到40.82%的RDO时间节省,为最小值,其相差大约19%,与参考文献[8]算法的35%相比,可以证明本文算法节省时间更加均匀,有着更好的普适性。
在A 类高分辨率视频序列中,由于编码每帧图像所需码率较多,会进行较多的RDO 模式决策过程,这意味着使用码率失真估计算法会产生较大误差,本文算法在A 类视频序列性能平均损失仅为1.69%。在分辨率较低的D 类序列中,在RA 模式下,编码每帧所需的码率较少,但这也意味着更多的系数被量化为0,导致失真计算会有较大的误差,本文算法在D 类序列上平均损失仅为1.28%,表2 数据表明在各个分辨率下,都有着优于参考文献[8]算法和参考文献[9]算法的性能表现。图12~图15 为在各个分辨率下的视频序列R-D 性能曲线,对比了原始的HM16.0 算法和本文的码率失真估计算法,可以看出本文的算法性能在各个分辨率下都极其接近原始HM 算法的性能,这也证明了本文算法的优越性。

图12 序列ParkScene(1 920 dpi×1 080 dpi)的R-D 曲线
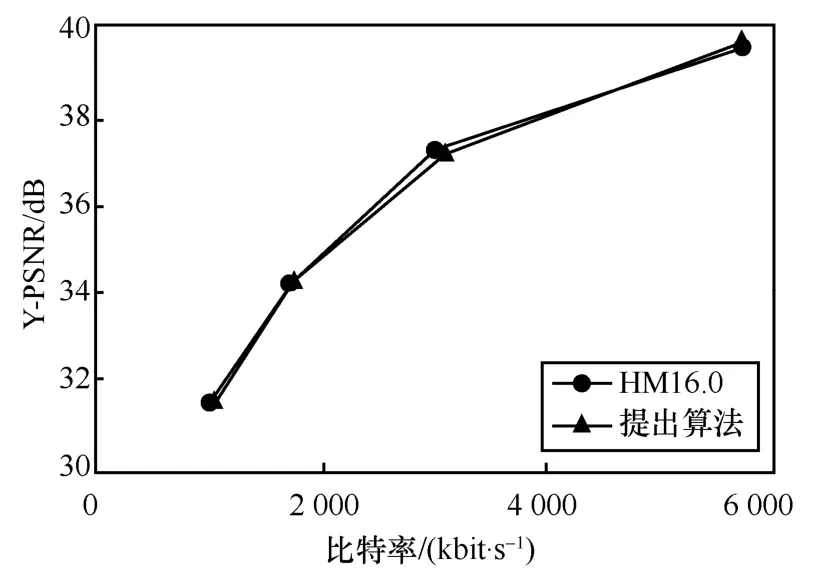
图13 序列BQMall(832 dpi×480 dpi)的R-D 曲线

图14 序列BQsquare(416 dpi×240 dpi)的R-D 曲线
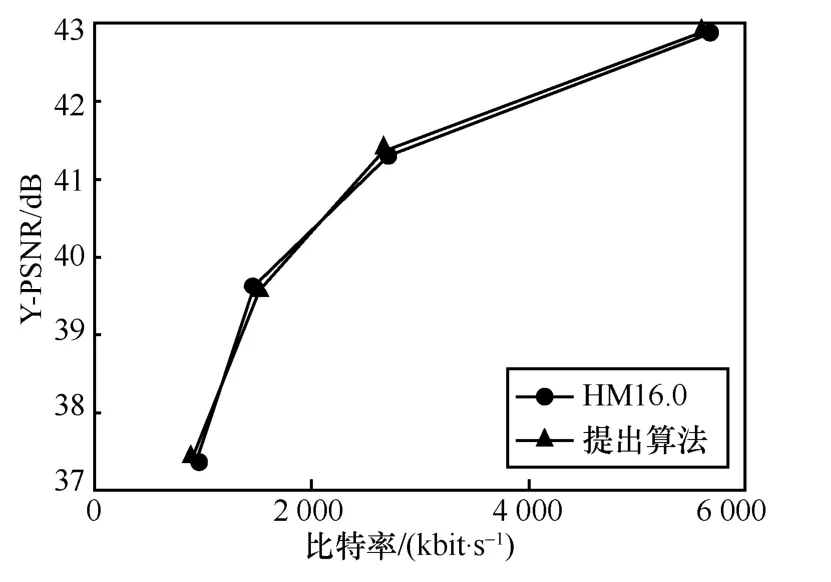
图15 序列Johnny(1 280 dpi×720 dpi)的R-D 曲线
7 结束语
本文针对HEVC 率失真优化过程中复杂的码率与失真计算问题,提出一种快速码率失真估计算法。通过实验证明,本文算法与目前典型算法而言,在性能与时间节省方面都有着较大的提升,后续工作主要有两部分:一是对权重系数进行进一步优化,探索其与位置参数的动态关系,使得码率模型能够更精准地估计码率;二是探索码率与失真模型在全帧内编码中的应用,找出其与帧间编码参数之间的差异,使得模型能够适应更复杂的编码场景。
