TargetedFool:一种实现有目标攻击的算法
2021-01-29高浩然杨兴国李文敏温巧燕
张 华,高浩然,杨兴国,李文敏,高 飞,温巧燕
(北京邮电大学 网络与交换技术国家重点实验室,北京 100876)
对抗样本是指为了使分类器产生错误的分类结果,在原始样本中加入轻微扰动后得到的攻击样本。敌手利用对抗样本可以攻击基于深度神经网络的应用模型。现有的对抗攻击按照敌手对模型的了解程度,可以分为黑盒攻击[1-5]和白盒攻击[6-9]。按照产生扰动的方法,可以分为基于梯度的攻击方法、基于优化的攻击方法和基于决策面的攻击方法[10]。按照对抗攻击的结果,可以分为有目标攻击和无目标攻击。有目标攻击可以实现将攻击目标扰动至特定类别,对于提供识别服务的系统构成了更大的威胁。
2014年,SZEGEDY等[11]首次提出基于L-BFGS优化算法[12]生成有目标对抗样本的L-BFGS攻击算法。由于采用线性搜索方法来寻找最优值,使得攻击时间成本较高。随后,GOODFELLOW等[6]基于梯度思想提出快速梯度符号函数法(Fast Gradient Sign Method,FGSM),能够快速有效地生成对抗样本。由于需要人为选择扰动系数,使得该方法需要添加的扰动量较大。2016年,KURAKIN等[13]基于FGSM提出I-FGSM,利用迭代方式添加扰动,因此在通常情况下表现出比FGSM更强的白盒攻击能力。2016年,PAPERNOT等[14]提出有目标的对抗攻击方法,即JSMA,定义了输入数据和目标类别之间距离的预测度量标准。由于在每次迭代中构建两个敌对映射来选择输入特性非常耗时,因此JSMA的攻击时间成本很高。2016年,MOOSAVI-DEZFOOLI等人[7]提出DeepFool,实现了基于梯度攻击方式的白盒无目标对抗攻击,通过计算图片数据分布到决策面的最小距离,能够较快地产生较小的扰动。2017年,MOOSAVI-DEZFOOLI等[15]基于DeepFool思想,通过计算多个距离的矢量和产生通用对抗扰动。通用对抗扰动使自然图片被错误分类的可能性增高。
目前,很多机器学习平台都具有对抗样本工具包,例如Tensorflow[16]平台的cleverhans[17]。DeepFool算法作为经典的对抗攻击算法,虽然在机器学习平台中具有广泛的应用,但仍然缺少利用DeepFool算法思想进行有目标攻击的研究。如何在高维空间中利用几何关系求解扰动,并在有限的时间内实现特定的攻击效果是本文研究的主要问题。
基于DeepFool算法思想提出TargetedFool算法,通过计算图片数据分布到目标类别决策面的距离,能够在较短的时间内实现有目标的对抗攻击,并且产生的扰动人眼无法观察到。笔者主要的贡献如下:
(1) 基于经典对抗攻击算法DeepFool提出TargetedFool算法,实现对DenseNet、Inception-v3、ResNet和VGG有目标对抗攻击。
(2) 进行了广泛的实验比较,结果表明:笔者提出的算法在不同卷积神经网络下都可以生成有目标的对抗样本,在ImageNet数据集下平均鲁棒性和扰动率指标均优于FGSM、IFGSM和JSMA。
(3) 分析了基于DeepFool的对抗攻击算法无法产生有目标通用扰动的原因,发现不同图片的决策边界以及目标类别所在的空间不相同,相同扰动量无法将不同图片扰动至相同的目标类别。
1 相关工作
SZEGEDY等[11]首次提出在深度神经网络中存在对抗样本,证明了深度神经网络在单个单元的语义和不连续性方面都具有反直觉的特性。他们将生成对抗样本的问题转化为带条件的优化问题,并且使用拟牛顿法中的L-BFGS算法[12]解决生成有目标对抗样本的优化问题。L-BFGS攻击采用线性搜索方法寻找最优值,搜寻过程非常耗时。
GOODFELLOW等人[6]认为神经网络在高维空间中存在线性部分,在构造对抗样本时应当关注扰动的方向而不是扰动的数目,扰动方向的选取根据损失函数梯度方向而定。FGSM通过最大化分类器将原始输入分类到目标类别的概率,实现有目标对抗攻击。由于扰动系数无法确定,FGSM产生的扰动量比较大。
KURAKIN等人[13]基于FGSM提出迭代攻击算法,即I-FGSM。该方法用较小的步长多次应用FGSM算法生成扰动率更高的对抗样本。与FGSM思想相同,I-FGSM最大化分类器将原始输入分类到目标类别的概率,通过迭代的方式实现有目标对抗攻击。
PAPERNOT等人[14]基于雅可比矩阵求出神经网络的前向导数,构造显著性列表用于搜索对分类结果影响最大的输入向量,并将扰动大小限制在l0范数内。由于构造显著性列表比较耗时,因此使用JSMA在大型数据集(例如ImageNet)上生成有目标的对抗样本的时间成本较高。
MOOSAVI-DEZFOOLI等[7]首先分析在二元分类器下如何将原始输入扰动至其他类别。他们使用点到直线距离公式计算出原始输入到决策面的距离,将该距离添加到原始输入后得到可以攻击二元分类器的对抗样本。多元分类器是二元分类器的扩展。针对多元分类器,他们计算原始输入到多个决策面的距离,将最小距离添加到原始输入后得到可以攻击多元分类器的对抗样本。在实际情况下,深度神经网络的决策面具有高维非线性性质。因此,他们使用迭代方式向原始输入添加扰动。随后,MOOSAVI-DEZFOOLI等[15]基于DeepFool思想提出通用扰动。该方法通过计算多个原始输入到决策面距离的矢量和得到通用扰动。利用该算法得到的扰动不仅能够成功地扰动数据集中的大部分图片,而且产生的扰动具有一定的泛化能力。该算法的核心在于通过多次迭代找到最小扰动,并将找到的最小扰动进行矢量和叠加,得到最终的通用扰动。
2 工作流程和符号定义
在已知模型的结构和参数下实现了有目标对抗攻击。如图1所示,有目标对抗攻击根据原始图片和梯度信息,利用TargetedFool算法产生特定的扰动,将该扰动添加到原始图片中来生成对抗样本,从而将卷积神经网络对对抗样本的分类结果扰动至目标类别。本文的攻击目标是人对对抗样本的分类结果仍然是原始类别,而卷积神经网络的分类结果是目标类别。
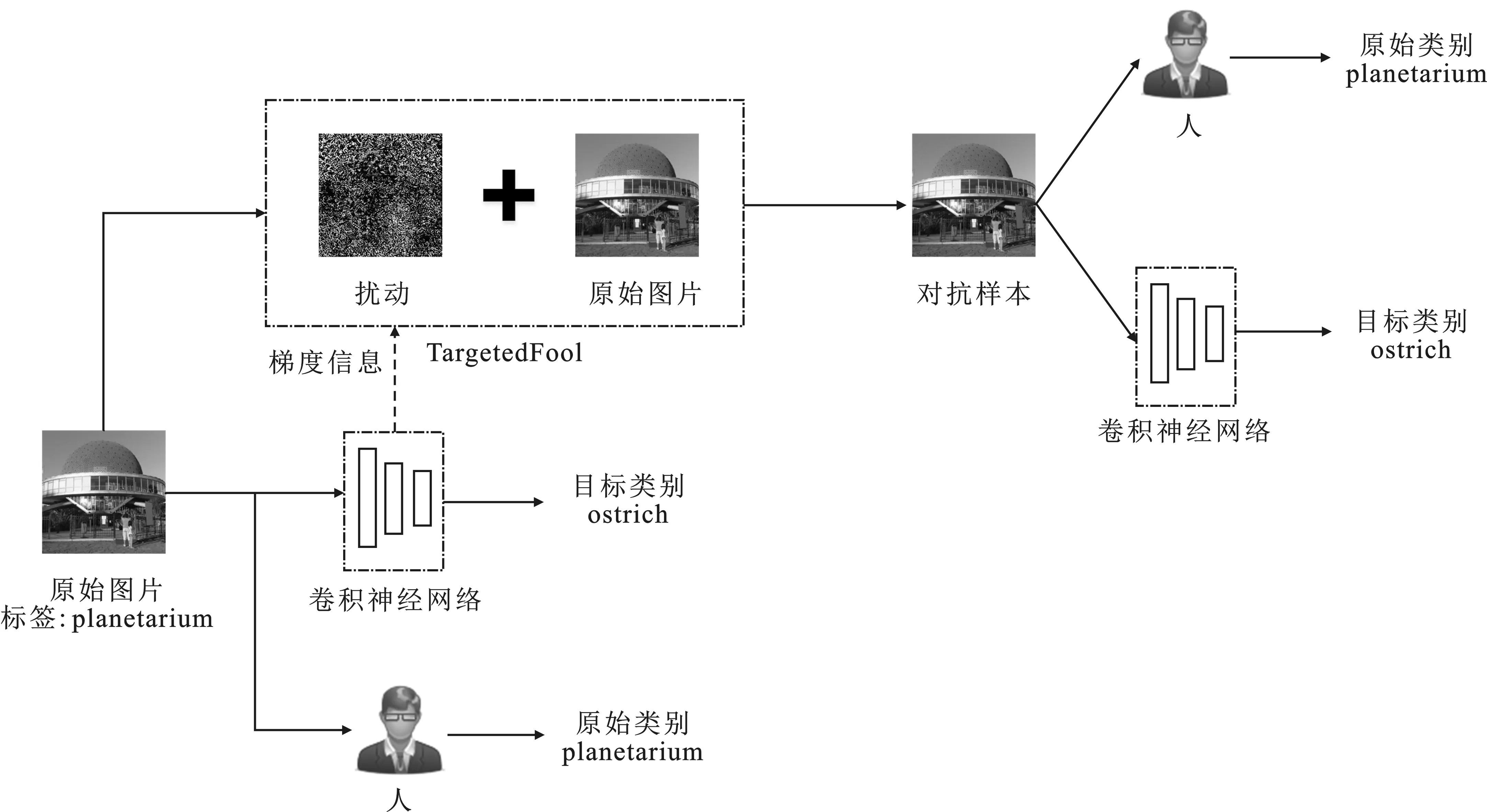
图1 有目标对抗攻击过程示意图
表1对本文所使用的符号进行了描述。该攻击过程符号化描述如下。

表1 符号以及描述
(1)定义符号。I={i1,i2,…,in},是由原始图片(ip,p∈[1,n])组成的集合;L={l1,l2,…,lm},是由原始标签(lq,q∈[1,m])组成的集合;Ilk={x|f(x)=lk,x∈I},k∈[1,m],是由同一类别的图片组成的集合。E={e1,e2,…,en},ej=ij+rj,t,j∈[1,n],集合中的每一项表示一个对抗样本,其中rj,t是由TargetedFool算法产生的扰动。该算法的目的是使对抗样本ej的类别为t。
(2)生成对抗样本。ej=ij+T(ij,lt),∀ij∈I和ij∈Ilk,j∈[1,n],T表示TargetedFool算法。
(3)实现攻击。将对抗样本输入到卷积神经网络中,得到lt=f(ej),其中lt是目标类别标签。人的识别结果为lk=m(ej),其中lk是原始类别标签,m表示人工操作。
3 TargetedFool算法
3.1 TargetedFool用于二分类
二元分类器应用广泛,例如垃圾邮件分类识别。假定分类器f为原始输入到原始标签的映射,Rn→R。分类器可表示为
k(x)=sign(f(x))。
(1)
在线性情况下,设定映射函数f(x)=wTx+b,线性决策面F={x∶wTx+b=0}。基于DeepFool思想,将无目标攻击推广至有目标攻击。如图2所示,数据点x0属于+1类别,目标属于-1类别。由式(2)可以计算出数据点x0至线性决策面FL的最短距离r0(x0):
(2)
在实际情况中,决策面多数为非线性。如图3所示,将r0(x0)添加到输入数据中无法保证分类器一定产生特定的分类结果。因此需要按照式(3)迭代添加扰动:
(3)

图2 一个线性二元分类器的对抗样本示意图 (实直线FL表示线性决策面)

图3 一个非线性二元分类器的对抗样本示意图 (实直线FN表示真实的非线性决策面,线性决策面 FL=f(xi+f(xi)T(x-xi)为FN在xi点的线性近似)
3.2 TargetedFool用于多分类
基于二元分类器下TargetedFool算法的思路提出多元分类器下TargetedFool算法。多元分类器下存在多个决策面,因此多元分类器存在多维的分类结果。假定分类器f是原始输入到原始标签的映射,Rn→Rc,其中c是神经网络输出结果的维度。分类器由式(4)表示,其中fk(x)表示第k个分类器的输出结果:
(4)
(1) 决策面为线性情况下生成有目标对抗样本
设定仿射函数f(x)=WTx+b,当ft(x0+r)≥fk(x0)(x0+r)成立时,arg max(·)函数选择最大值的自变量作为函数结果,最终的分类器结果是目标类别t。实现有目标攻击需要满足
(5)
其中,wt是W的第t列,表示目标类别权值。
多元分类器的决策面构成了式(6)所示的决策空间P:
(6)
当c=4,k(x0)=3时,P如图4所示,其中目标类t为类别2,线性决策面为FLk={x:fk(x)-f3(x)}。
上述问题对应于计算数据点x0与目标决策面FL2的距离,通过计算数据点x0到目标类别决策面的距离,得到扰动:
(7)

图4 k(x0)=3时,决策空间示意图(实线表示线性决策面,虚线表示P的边界)
其中,wt表示目标类别权值。数据点x0通过添加扰动r0(x0)可以使分类器产生特定的分类结果。综上,在线性情况下找到了有目标的对抗样本。
(2)决策面为非线性情况下生成有目标对抗样本。
将TargetedFool算法推广到非线性情况下。对于可微的多元分类器,需要迭代添加扰动。从图5中可知,x0属于类别3,目标类t属于类别2,目标类别的非线性决策面为FNt={x:ft(x)-fk(x)(x)=0}。为了便于计算原始输入到目标类别决策面的距离,通过计算非线性决策面FNt在点xi的线性近似,得到目标类别的线性决策面FLt={x:ft(xi)-fk(xi)xi)+ft(xi)T(x-xi)-fk(xi)(xi)T(x-xi)}。FL2是FN2在点x0的线性近似,在点x0垂直于决策面FL2方向上,FL2与FN2之间距离较大。单步添加扰动无法使数据点移动到目标决策空间,因此需要不断迭代添加扰动,直到数据点x0移动到目标决策空间。

图5 TargetedFool攻击过程示意图
使用分类器函数f(x)在点xi处的线性逼近来获得f(xi)+f(xi)T(x-xi)。当不等式(8)成立时,分类器最终输出类别为t。
ft(xi+ri)+ft(xi+ri)T(x-xi-ri)≥
fk(xi+ri)(xi+ri)+fk(xi+ri)(xi+ri)T(x-xi-ri) 。
(8)
通过计算数据点xi到目标类别决策面的距离得到扰动,扰动的公式如下:
(9)
TargetedFool算法通过计算原始输入到目标类别决策面的最小距离产生扰动,因此TargetedFool算法生成的对抗样本不仅能够达到有目标的攻击效果,同时扰动量也较小。在二范式下计算扰动,具体的算法设计见算法1。
算法1TargetedFool用于多分类。
输入:图片x,分类器f,目标类别t,有目标的对抗样本xadv_t。
输出:扰动r。
① 初始化x0←x,xadv_t←x,i←0。
② whilek(xi)≠tdo
③w'←ft(xi)-fk(xi)(xi)
④f′←ft(xi)-fk(xi)(xi)

⑥xi+1←xi+ri
⑦i←i+1
⑧ end while
⑨xadv_t←xi
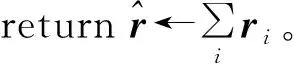
4 实验与结果分析
4.1 实验设置
在典型的卷积神经网络上测试TargetedFool算法,测试环境为:NVIDIA Corporation Gp102 [GeForce GTX 1080 Ti],测试中使用MNIST[18]、CIFAR-10[19]以及ImageNet[20]数据集。下面详细描述不同数据集使用卷积神经网络的具体情况。
MNIST:使用具有两层卷积、两层池化和两层全连接结构的LeNet[21]卷积神经网络。
CIFAR-10:调整了在ILSVRC 2012竞赛中夺得冠军的AlexNet[22]卷积神经网络。
ILSVRC2012:使用Inception-v3[23]、ResNet[24]以及DenseNet[25]预训练模型。
NIPS2017:使用Inception-v3预训练模型。
4.2 评价指标
平均鲁棒性:为了能更好地评估对抗攻击的有效性,将DeepFool文章中提出的平均鲁棒性[7]作为评估标准之一,定义为
(10)
其中,D表示测试集。在相同原始输入和目标类别情况下,分类器的平均鲁棒性越低,说明攻击算法越有效。
扰动量:扰动的大小影响深度学习系统的运行效率,扰动量是对抗攻击领域常用的衡量标准[26]。扰动量越多,越容易被人或检测系统发觉。扰动量的定义如下:
r(x)=‖xadv-x‖p。
(11)
时间:算法生成对抗样本的总耗时,时间可以作为算法运行效率的衡量标准。
4.3 实验结果与分析
在不同卷积神经网络下实现有目标对抗攻击。表2展示了基于不同卷积神经网络在ILSVRC2012验证集上测试TargetedFool算法的效果。Top-1 error表示原始图片在分类器下预测结果第一的类别与原始类别不同的概率。Top-5 error表示原始图片在分类器下预测结果前五的类别与原始类别不同的概率。使用上述的评估标准对TargetedFool算法在不同卷积神经网络下的测试结果进行评估。可以看出,TargetedFool算法能够在平均时间0.45 s下实现对ResNet-34有目标对抗攻击。

表2 测试结果

图6 原始图片的类别标签为“husky”,目标类别标签为“ostrich”
(6个扰动是在不同的卷积神经网络下由TargetedFool算法生成的,这些扰动都可以将原始图片类别标签扰动为“ostrich”)
图6展示了基于Pytorch环境在不同卷积神经网络下将真实类别为“husky”图片扰动到目标类别“ostrich”产生的扰动情况。算法通过不断迭代直到成功将图片扰动至目标类,因此针对不同卷积神经网络TargetedFool算法,都可以产生相应的扰动,得到有效的有目标对抗样本。
与DeepFool算法比较。表3展示了TargetedFool算法与DeepFool算法基于不同数据集和卷积神经网络下生成对抗样本的时间和添加到原始图片的扰动量。TargetedFool算法和DeepFool算法生成对抗样本的时间相近,而TargetedFool算法可以在有限时间内生成有目标的对抗样本。尽管TargetedFool算法产生的扰动量大于DeepFool算法,人眼仍然无法识别笔者提出的算法生成的对抗样本。
与有目标对抗攻击算法比较。将TargetedFool算法与常用的有目标对抗攻击算法进行比较。实验环境:Inception-v3卷积神经网络以及NIPS2017提供的数据集。从表4可知,FGSM在有目标攻击下无法生成具有较高扰动率的对抗样本,IFGSM、JSMA算法生成有目标的对抗样本需要较长的运行时间,TargetedFool算法可以在有限时间内生成较高扰动率的对抗样本。

表3 TargetedFool算法与DeepFool算法的比较

表4 在Inception-v3,NIPS2017,l2范式下,扰动率、时间、平均鲁棒性、最大扰动系数以及 最大迭代次数(对抗样本由FGSM,IFGSM,JSMA和TargetedFool生成)
图7展示了不同对抗攻击算法在Inception-v3网络下生成的有目标对抗样本。

图7 在Inception-v3下使用FGSM、IFGSM-20、IFGSM-30、JSMA和TargetedFool算法生成的有目标对抗样本

图8 分析基于DeepFool的对抗攻击算法 无法产生有目标通用扰动的示意图 (F1,F2,F3分别为原始输入X1,X2和X3的决策面,r1,r2和r3分别为原始输入X1,X2和X3达到同样的目标类别需要添加的扰动量)
图7中第1列第1张原始图片的原始类别是“long-horned beetle”,目标类别是“espresso maker”;第1列第2张原始图片的原始类别是“espresso”,目标类别是“nail”。从图中可知,FGSM没有将原始图片类别扰动到目标类别;IFGSM在迭代次数设定为30时,成功地将原始图片类别扰动至目标类别;JSMA、TargetedFool算法生成的对抗样本能够达到预期效果。仔细观察可知,IFGSM-30、JSMA生成的对抗样本通过人眼识别可以观察到一些扰动。
基于DeepFool的对抗性攻击算法不能产生有目标通用对抗扰动。图8给出了3个不同的原始输入达到同一目标类别需要添加的扰动向量。由Fi={x:fi(x)-fk(x)(x)=0},i∈[1,3]可知,不同原始输入的决策面不同。3个原始输入的目标类别空间分别为A,B和C,3个原始输入通过添加r1,r2和r3的矢量和后被移动到空间E。易知,空间E不是原始输入X1,X2和X3的目标类别空间。综上所述,3个不同的原始输入添加扰动向量r1+r2+r3后能够使分类器产生错误的分类,但无法达到同一目标类别。
使用ILSVRC 2012数据集在ResNet-34卷积神经网络下进行了多组实验。图9给出了10个不同类别的原始图片分别增加10个不同扰动产生的结果,其中10个不同扰动由TargetedFool将10个不同类别的原始图片扰动到目标类别“ostrich”产生。通过观察可以发现,将不同原始图片扰动到目标类别“ostrich”需要添加的扰动明显不同。通过交叉验证发现,原始图片添加交换后的扰动得到的样本,有可能使分类器产生错误的分类,但无法将原始图片扰动到目标类别。
5 缓解措施
针对对抗攻击,常用的防御方法包括对抗训练、网络蒸馏和附加网络方法。对抗训练是指在训练阶段的每一步都生成对抗样本,并将其注入到训练集中。该方法能够有效地提高深度神经网络的鲁棒性。对抗训练对于单步攻击(例如FGSM)防御效果明显,而对于迭代攻击的防御效果并不明显[28]。网络蒸馏最初的设计目的是通过将知识从一个规模较大的网络转移到一个规模较小的网络,来减小深度神经网络的规模。PAPERNOT等[29]使用网络蒸馏来防御深度神经网络对抗样本。这种防御方式之所以有效,是因为深度神经网络在训练期间获得的知识不仅被编码在由网络学习到的权重参数中,而且也被编码在由网络产生的概率向量中。因此,蒸馏这种方式可以从这些概率向量中提取类别知识,从而识别出样本的真实类别。这种方式对于扰动量较小的对抗样本,防御效果不明显。在原有神经网络结构下,附加生成对抗网络(Generative Adversarial Networks,GANs)能够有效防御对抗样本[30]。该防御方法首先使用真实数据训练GANs,然后通过GANs将对抗样本的数据分布映射到真实分布。基于GANs的防御方法需要获取真实数据训练GANs,并且GANs训练时间较长。笔者提出的TargetedFool算法可以实现白盒下的有目标攻击。针对TargetedFool算法可以使用附加网络方式进行防御,然而训练附加网络的时间成本较高。

图9 实验环境为Pytorch,ResNet-34卷积神经网络(第1列表示原始图片,第1行表示由第1列原始图片扰动到目标类别“ostrich”产生的扰动,其余图片表示原始图片增加不同扰动后的结果(例如,第2行第3列的图片是类别为“cougar”的原始图片增加由类别为“white wolf”的原始图片扰动到目标类别“ostrich”产生的扰动)
6 总 结
笔者提出了TargetedFool算法,可以实现在白盒情况下的有目标对抗攻击。通过实验验证,TargetedFool在有限时间内可以达到预期攻击效果。在ImageNet数据下的平均鲁棒性和扰动率都优于FGSM、IFGSM和JSMA。通过理论和实验分析了基于DeepFool的对抗攻击算法无法产生有目标通用扰动的具体原因。如何提升有目标攻击下对抗样本的迁移性,将是后续研究的一个重要内容。
