基于邻层传播的相对重要节点挖掘方法
2021-01-22彭西阳聂永杰
赵 娜,李 杰,王 剑,彭西阳,景 铭,聂永杰,郁 湧*
(1. 云南大学软件学院 昆明 650091;2. 云南大学云南省软件工程重点实验室 昆明 650091;3. 云南电网有限责任公司电力科学研究院 昆明 650217;4. 昆明理工大学信息工程及自动化学院 昆明 650504)
分析复杂网络中的节点重要性,是一个被广泛关注且具有重要意义的研究方向。目前,节点重要性的研究方法主要是针对网络中的所有节点做全局排序,以判断节点重要性[1-3]。然而,“相对于一个或一组特定的节点,网络中哪些节点是最重要的?”这类问题显示了节点的相对重要性、局部重要性同样具有较强的现实意义,尤其是当网络的规模非常大的时候。解决这类问题的一种典型办法就是先量化一个节点相对于一个已知重要节点的重要性(称为相对重要性,有时也称为接近性或者相似性),再计算一个节点相对已知的重要节点集的重要性,从而找到相对重要节点,即相对重要节点挖掘[4]。如在罪犯关系网络中,通过已知罪犯查找其余罪犯[5-7];在蛋白质网络中,通过已知致病基因查找未知致病基因[8],或通过已知染病节点查找或预测风险节点[9];在传染病网络中,可针对已知感染人员,优先找出易感人群进行治疗、隔离,有效防止病毒的传播和扩散;在电力网络中,通过已知重要断路器或发电单元找出相对重要的断路器、发电单元等进行保护,可有效防止由相继故障引起的大范围停电。可见,挖掘网络中的相对重要节点具有重要的应用价值。
1 相对重要节点挖掘算法研究现状
相对重要节点挖掘的工作可以追溯到文献[10]在2000 年提出的一种个性化的变种HITS 算法研究工作。其后,文献[11-12]分别提出了个性化变种PageRank 算法,开始更多地考虑网络中节点的相对重要性。2003 年,文献[13]定义了相对重要节点挖掘算法的通用框架,还明确提出了网络中节点的相对重要性是相对于一个或一组指定的特定节点集的重要性。随后相对重要节点的算法不断被提出。文献[14]提出了路径概率求和的方法,该方法将节点s相对于最近邻居节点s′的重要性定义为随机游走过程中从节点s跳到节点s′的概率。文献[15]提出集群粒子传播法来评价节点的相对重要性。文献[16]采用最短距离本身作为相对重要性衡量指标,文献[17]采用最短路径距离的P范数的倒数作为相对重要性衡量指标。文献[18]在介数中心性的基础上提出了信赖值的方法查找犯罪网络中的其余罪犯。尽管相对重要性挖掘方法已有一些成果,但仍存在诸多问题,如方法的效率和准确性有待提高;在不同网络上,方法的参数也需要明确如何选取等。
2 基于邻层传播的相对重要节点挖掘方法
在现实生活中,人类遗传病通常由多种致病基因(含未知和已知的基因)引起,由于它们导致相同或相似的疾病表型,因此未知的致病基因与已知的致病基因功能相关性越强,即某一基因与已知致病基因有越多的关联,该基因为致病基因的概率越大[19]。基于此思想,本文提出一个新的基于邻层传播(neighbor layout diffuse, NLD)的方法来挖掘相对重要节点,该算法的核心思想是:在网络中,与已知重要节点连接越多的节点,该节点与已知重要节点具有的共同特征越多,其为已知重要节点的相对重要节点的概率越大。
2.1 问题定义
对于由N个节点构成的网络G(V,E),其中,N1个 节点构成重要节点集V1,N2个节点构成非重要节点集V2。 重要节点集V1=R∪U,其中R是已知重要节点集,U是未知重要节点集。
本文的工作是:基于已知重要节点集R,分析目标节点集T=V-R中任意节点t相对于已知重要节点集R的重要性,最终找出目标节点集T中top-k个相对重要节点,并对结果进行AUC、准确率和召回率分析。
2.2 NLD 算法中的分层
NLD 算法分为分层和传播两个步骤,传播是在分层的基础上进行的。分层是将已知重要节点作为第一层,放入集合L1,将第一层节点的邻居节点作为第二层,放入集合L2,将第二层节点的邻居节点(不在第一层)作为第三层,放入集合L3,以此类推,直到将所有节点进行分层,得到分层结果Layer={L1,L2,···,Lm}。
2.3 NLD 算法的传播
在上述分层过程完成后,算法进入传播步骤。NLD 算法的传播采用相对重要性分数值来量化节点重要性的传播情况。分层后,只有第一层节点为已知重要节点,且相邻两层的节点间有链接。设第一层的相对重要性分数值为1,其他节点的值为0。第一次传播时,由于第二层节点与第一层节点有链接,因此将第一层节点的相对重要性分数值通过链接传给第二层,即将第一层节点的重要性传给第二层,第二层任意节点与第一层节点联系越多,被传给的值就越多,即被传给的重要性越大。第二次传播时,把第二层节点作为传播源,第二层节点通过链接会传给相邻的第三层,同时会回传给相邻的第一层,以此类推。需要说明的是回传影响的仅是上一层,而下一层的节点值往往小于上一层的,所以回传的值会更小,回传不会影响整体的排序结果,并且能对上一层节点的相对重要性进行区分。NLD 算法描述如下:令传播轮数为S,初始时,S=0,令已知重要节点集R中任意节点r的相对重要性分数值Zr(0)=1,目标节点集T中的任意节点t的相对重要性分数值Zt(0)=0。
第一轮传播时,S=1,对于第一层中任意节点i,其相对重要性分数Zi(0)≠0 ,将Zi(0)/k传递给邻居,k为节点度数;第二轮传播时,S=2,对于第二层中任意节点i,其相对重要性分数Zi(1)≠0,将Zi(1)/k传递给邻居,以此类推,当S=m-1 时,网络中任意节点i的相对重要分数Zi(S)≠0,停止传播。对于任意节点i,相对重要性分数值Zi(S)的公式表示如下:


传播结束后,比较所有节点的相对重要性分数值,相对重要性分数值越大的越可能是相对重要节点。
2.4 方法示例
以图1 所示的网络为例,说明邻层传播算法的计算过程。

图1 示例网络
把图中节点按顺序编号为[1, 2, 3, 4, 5, 6, 7, 8,9, 10]。设节点1 为已知重要节点。首先根据已知重要节点对网络进行分层。节点1 属于第一层,节点2, 3, 4 属于第二层,节点5, 6, 7, 8 属于第三层,节点9, 10 属于第四层。
初始时,根据节点编号顺序,节点对应的相对重要性分数值为[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]。经过第一轮传播后,各节点对应的相对重要性分数值为[1, 0.333 3, 0.333 3, 0.333 3, 0, 0, 0, 0, 0, 0]。
经过第二轮传播后,各节点对应的相对重要性分数值为[1.388 9, 0.333 3, 0.333 3, 0.333 3, 0.277 8,0.111 1, 0.111 1, 0.111 1, 0, 0]。
经过第三轮传播后,各节点对应的相对重要性分 数 值 为[1.388 9, 0.463 0, 0.425 9, 0.5, 0.277 8,0.166 7, 0.148 1, 0.111 1, 0.037 0, 0.092 6]。
此时,所有节点都有了相对重要性分数值,传播结束。然后,根据相对重要性分数值对节点进行排序。从示例网络的计算结果可得,对于节点1,相对重要节点可能性的顺序应为4, 2, 3, 5, 6, 7, 8,10, 9。
3 实 验
3.1 数据集
实验采用了4 个真实网络数据集,忽略网络连边的权重与方向,分别是:
1) 国际航空网络[20],节点为国家,边代表两个国家有航线,SARS 病毒爆发早期传播到的国家为重要节点集。
2) 人类蛋白质相互作用网络PPI[21],节点代表蛋白质,边代表蛋白质之间存在相互作用,重要节点集是心脏病基因翻译的蛋白质。
3) Human 人类蛋白质相互作用网络[22],节点代表人类蛋白质,边代表蛋白质之间存在相互作用,人类蛋白激酶这类蛋白质为重要节点集。
4) Mouse 小鼠蛋白质相互作用网络[22],节点代表小鼠蛋白质,边代表蛋白质之间存在相互作用,小鼠蛋白激酶这类蛋白质为重要节点集。
以上网络数据集的基本拓扑特征如表1 所示。

表1 网络基本拓扑特征
其中N表示网络节点个数,N′表示网络中重要节点个数,M表示网络的边数,K表示网络平均度,C表示网络平均聚类系数。
3.2 评价指标

3.3 实证比较



图2 网络的AUC 结果
对比不同的算法可知,KSmar 的结果会把距离所有已知重要节点更近的节点的相对重要性分数调高。通过Ksmar 的公式KS=[TP+T2P+····+TkP]也可看出,转移概率矩阵会给k步内已知重要节点所能到达的节点赋予重要分数,k越小时,所获得的相对重要分数越高。PPR 是PageRank 的改进方法,在无向图中,对于度大的节点往往会获得更多的相对重要性分数。PHITS 是HITS 算法的改进,在无向图中,已知重要节点是权威节点也是中心节点,因此它往往给已知重要节点的邻居更高的重要性分数。NLD 则会给每层共同邻居越多的节点更多的重要性分数。在SARS 网络中,SARS 爆发的国家与某个国家有越多的航班,该国家成为下一个爆发的国家的可能性更大,这符合NLD 的思想,因此NLD 在SARS 网络上表现的较好。对于PPI网络,某一基因与已知致病基因有越多的关联,该基因为致病基因的概率越大[19],符合NLD 的思想,因此在PPI 网络上表现也较好。
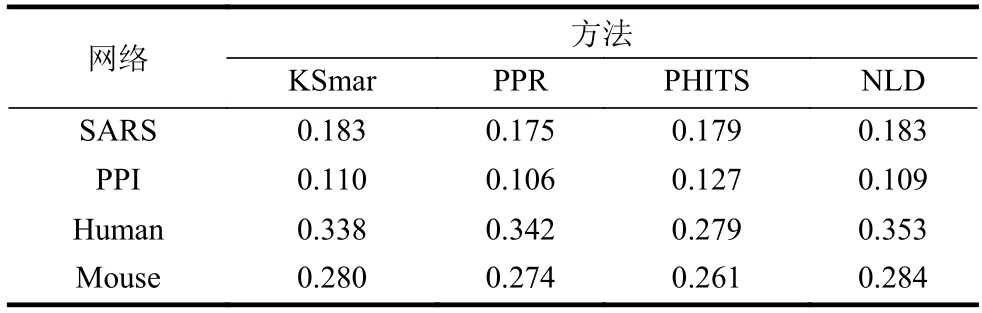
表2 不同的方法在4 个网络的平均准确率

表3 不同的方法在4 个网络的平均召回率
从实验的数据集来看,总体而言,NLD 方法优于其他方法,这说明NLD 在相对重要节点挖掘方面具备准确性与适用性。由于这些方法的优劣一定程度上取决于网络结构本身,根据网络结构确定研究方法这也是今后研究的一个问题。
4 结 束 语
本文提出了一种挖掘相对重要节点的方法——NLD,该方法基于与越多已知重要节点关联,其为相对重要节点的概率越大的假设。本文将NLD与已有的挖掘相对重要节点较好的方法KSmar、PPR、PHITS 进行对比,实验结果证明NLD 在一定程度优于这些方法。同时,NLD 方法也为网络信息挖掘提供了新思路。在今后的工作中仍然有很多问题值得深入研究:1) 现有的各种度量网络中节点相对重要性的指标,比如路径长度的倒数、介数等,它们之间是否具有一定的联系。2) 现实世界中虽然很多网络都可以抽象为复杂网络,但针对不同网络设计其适用的挖掘算法仍是亟待研究的。
本文研究工作得到昆明市卫健委项目(2020-09-04-112)的资助,在此表示感谢。
