基于项目评分行为序列的群组攻击检测算法
2021-01-18胡玉琦曲越奇
胡玉琦,李 雪,曲越奇
(1. 燕山大学 信息与工程学院,河北 秦皇岛 066004;2. 燕山大学 里仁学院,河北 秦皇岛 066004)
0 引言
推荐系统通过在海量信息中为用户寻找所需要的信息,进行个性化推荐,有效地解决信息过载问题,但系统的开放性使得其很容易被恶意用户攻击。目前攻击行为正逐渐由个体攻击行为转变为群组攻击行为[1],群组攻击行为通过多个用户共同作用的方式有目的地对系统注入攻击概貌以增加或减少目标项目被推荐的频率[2-3]。相对于个体攻击行为而言,攻击群组中的各个用户互相协作和掩护,攻击的迷惑性更强,传统的检测算法逐渐失效,推荐系统的鲁棒性正受到挑战。
针对攻击群组的检测算法中,Wan等人采用AP聚类对用户进行群组划分,将每个群组表示为评分向量,并根据压缩后的评分向量矩阵找出被攻击的目标项目,根据目标项目找出攻击群组。该算法可以检测多种类型的攻击,但对分段攻击类型的小攻击规模数据集检测效果不稳定[4]。Dou等人采用了矩阵分解和决策树检测攻击用户,用特征向量表示用户的信息,利用决策树对用户进行分类。该算法需要事先获得用户标签,并且如果在数据集中正常用户和攻击用户比例相差较大的情况下检测性能会降低[5]。Zhang等人需要事先了解攻击规模并标记种子用户,而实际的攻击规模具有随机性难以获取,该条件影响了算法的实用性。另外,该算法还受种子用户比例的影响,如果选取的种子用户少,检测性能将降低[6]。Gao等人采用时间序列检测攻击用户,计算每个时间区间的评分分布与其他区间评分分布的差值,差值较大被判定为可疑区间,即攻击群组[7]。Zhou等人首先根据共同评分项目计算每个用户的特征值,根据特征值利用K-means算法对用户聚类,判定攻击群组,但该方法不能有效地检测共同评分项目很少或利用严格攻击模型注入的攻击用户[8]。Mehta等人提出了PCA-VarSelect算法,该算法利用主成分分析降维的方法过滤攻击概貌,可以有效地检测多种类型的攻击,但受限于评分矩阵的密度[9]。Cai等人通过构建用户有序评分序列来挖掘用户特征,利用PCA方法提取主成分组成矩阵,然后通过计算用户向量和预测向量的差值来检测可疑用户[10]。
与群组攻击检测算法相关的是对电商平台中虚假评论群组的检测。Mukherjee等人提出了采用频繁项集挖掘的方法来寻找候选群组,并依据群组、个体和商品的特征计算候选群组得分,按群组得分进行排序,筛选虚假群组,并提出了8个虚假群组的特征,弥补了以往检测特征过少的缺点[11-12]。韩忠明等人通过构建用户关系图,对邻接矩阵特征分解,找出异常特征向量,通过异常特征向量来检测攻击群组,该方法在建图时需要共同评分项目数量不小于3,而现实中无论是正常用户还是攻击用户之间很少甚至没有共同评分项目,因此该方法会丢失很多信息[13]。Wang等人提出通过检测图的拓扑结构来检测虚假群组,根据用户评论数据建立用户关系图,寻找图中双连通分量和最小分割图,判定虚假群组,但该方法会产生大量的孤立节点[14]。Ye等人根据邻居节点多样性和节点与网络的相似性这两个特征分析评论者,通过2-hop子图寻找群组中评论者的异常行为,并采用层次聚类判定虚假群组[15]。
本文针对已有群组攻击检测方法的局限性,提出了一种基于项目评分行为序列的群组攻击检测算法,称为IRBS(Item Rating Behavior Sequence)算法。
1 IRBS检测算法结构
如图1所示,IRBS有以下3个步骤:步骤一,根据评分数据集提取每个项目的评分行为序列,按时间先后顺序对序列中的元素进行排列。设置时间长度固定的时间窗口依次交叉划分评分行为区间,并在划分过程中筛选出区间内元素个数不小于2的区间;步骤二,计算区间的评分中值偏离度,根据偏离度利用层次聚类[16]筛选区间,计算区间可疑度;步骤三,对区间可疑度进行指数缩放处理,根据可疑度利用K-means聚类[17]判定攻击群组。

图1 IRBS检测算法框架Fig.1 Frame of IRBS detection algorithm
2 IRBS检测算法
2.1 评分行为区间的划分
2.1.1项目评分行为序列的提取
在推荐系统中,攻击用户为了隐蔽而快速地达到攻击目的,通常在短时间内以群体协作的方式对目标项目进行攻击,并且根据攻击概貌的类型对其他项目进行评分,以增强隐蔽性。但无论采用哪种攻击概貌,攻击群组对目标项目的“评分极端”和“时间集中”特性不会改变,因此通过提取数据集中每个项目的评分行为集合,按照时间先后顺序对序列中的元素进行排列,生成有序的项目评分行为序列。
定义1项目评分行为序列(IRBSi)指对项目i∈I的所有评分行为的顺序集合,评分行为包括评分用户、评分级别和评分时间,表示为
(1)
其中,m表示项目i的评分行为序列中评分行为的数量。
2.1.2评分行为区间的交叉划分
根据攻击群组的“攻击时间集中”的特性,设置固定时间长度的窗口对每个项目的评分行为序列进行划分,窗口时间长度设置为30天,采用交叉划分的方法,即窗口每次滑动步长为1,使区间之间有交集,从而避免了因窗口时间长度固定而导致某些攻击用户被排除掉。另外,同一序列中的区间之间不能存在包含关系,避免序列被划分的过于精细而使区间冗余导致的计算量增大。

划分群组后,由于个别用户不能构成群组,因此需要根据区间中用户的数量对区间进行筛选,将筛选出的区间用户数量不小于2的区间作为候选区间。
文中使用的参数说明如表1所示。

表1 参数说明Tab.1 Notes of parameters
由2.1.1和2.1.2节总结出划分评分行为区间的算法1描述如下:
算法1 划分评分行为区间
输入:数据集D(U,I,R,T),评分行为窗口RBW
输出:评分行为区间集合IRBIS
1.IRBIS←∅
2. for each itemi∈Ido
3.IRBSi←项目i的评分行为序列
4. while True do
5.IRBIi←∅,startelen←IRBSi[n]

[|IRBSi|]} do


9. end if
10. end for
11. if |IRBIi|≥2 andIRBIiIRBISi[|IRBISi|] then
12.IRBISi←IRBISi∪IRBIi
13. end if
14. ifIRBIi[|IRBIi|]=IRBSi[|IRBSi|] then
15. break
16. end if
17.n←n+1
18. end while
19.IRBIS←IRBIS∪IRBISi
20. end for
returnIRBIS
算法1主要包括两部分:第一部分(第1~3行)生成项目评分行为序列,第二部分(第4~18行)划分项目评分行为区间并筛选区间。
算法1的时间复杂度分析:生成项目评分行为序列(第1~3行)的时间复杂度为O(|I|2),划分项目评分行为区间并筛选区间(第4~18行)的时间复杂度为O(|U|·|I|),因此算法1的时间复杂度为O(|I|2+|U|·|I|)。
2.2 区间可疑度
2.2.1区间评分中值偏离度
攻击群组对目标项目进行极端评分,通过计算区间用户对该项目评分的平均值与数据集评分中值的偏离程度,即可知道该区间为攻击群组的可能性。
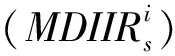
(2)

在计算偏离度之后,滤掉偏离度很小攻击区间,缩小检测范围,因此设置一个阈值,如果某区间的项目评分中值偏离度大于该阈值,将该区间作为备选区间,否则过滤掉。
确定该阈值的方法利用层次聚类自动确定。由于所有区间的项目评分中值偏离度可能有重复值,而大量的重复值不但会增加计算量,而且会对检测结果造成干扰,因此在计算之前去掉重复值,然后利用层次聚类对偏离度值进行聚类,聚类数量为2,选取平均值最大的类别中的最小值作为阈值。该方法的优点是可以根据数据集或数据量的不同,自动确定阈值,同时避免了重复项对检测结果的干扰。
2.2.2区间可疑度
在筛选出候选区间后,针对攻击群组和攻击用户的特征,提出了区间的可疑度的性能指标,以此检验可疑群组。
在固定的时间窗口长度内,如果该区间占用评分行为的比例大,说明该区间的用户评分时间比较密集,该区间用户的行为就越可疑。

(3)
式中,Ni,s是项目i评分行为序列中区间s所包含用户的数量,Ni是对项目i评分的用户数量。
为了增强群组攻击的隐蔽性,除目标项目外,攻击用户力求和正常用户行为相似,因此用户之间在评分均值相似。如果每个用户的历史评分的均值和该用户对区间所属产品的评分相差较大,则该项目可能是目标项目,该区间的可疑度也比较大。

(4)

正常用户是通过自己对项目的喜好去评分,而攻击用户是有目的地对项目进行评分,因此攻击用户之间具有更高的相似性,攻击用户的历史评分的分布也非常相似,这里采用变异系数来衡量。通过实验发现,攻击用户的历史评分的变异系数比较密集,通过变异系数来衡量区间用户变异系数的密集程度,密集程度越大,该区间就越可疑。

(5)
(6)
σs,c是区间用户评分变异系数的标准差,μs,c是区间用户评分变异系数的均值,μc是数据集所有用户评分变异系数的均值,σs,u,r是区间用户历史评分的标准差,μs,u,r是区间用户历史评分的均值。


(7)
由2.2.1和2.2.2节总结出区间可疑度的算法2,描述如下:
算法2 计算区间可疑度
输入:评分行为区间集合IRBIS,聚类数k=2
输出:区间可疑度集合IRBIAndSuss
1.IRBIAndSuss←∅,SusDegrees←∅




6. end for
7.SusDegrees←Set(SusDegrees)
8. MAX_Values1,MIN_Values2←
AgglomerativeClustering(SusDegrees,2)
9.threshold←MIN(MAX_Values1)



13. else



17. end if
18. end for
returnIRBIAndSuss
算法2主要包括3部分:第一部分(第1~6行)计算区间评分中值偏离度,第二部分(第7~9行)计算偏离度阈值,第三部分(第10~18行)筛选区间并计算区间可疑度。
算法2的时间复杂度分析:计算区间评分中值偏离度(第1~6行)的时间复杂度为O(|U|2·|I|),计算偏离度阈值(第7~9行)的时间复杂度为O(|I|3),筛选区间并计算区间可疑度(第10~18行)的时间复杂度为O(|I|3),因此算法2的时间复杂度为O(|I|3)。
2.3 攻击群组
2.3.1指数缩放的区间可疑度
现有的对数据进行缩放处理的方法通常是线性缩放处理,如数据归一化处理。这种数据缩放处理方法通常在对一维数据进行缩放处理时,通常只能同等比例地改变数据点之间的距离。在攻击群组的可疑度和正常群组的可疑度相差很小时,后续的检测方法通常很难区分这两种不同的群组。针对数据线性缩放处理的局限性,本文提出了数据指数缩放处理的方法。该方法通过设置一个指数,将可疑度作为底数,计算一个新的可疑度值,在不改变数据点分布顺序的情况下使不同的两数据点之间的距离增加或减少的比例不同。该方法可以有效地扩大攻击群组与正常群组之间的距离,使得后续的检测方法更容易检测出攻击群组。

(8)
在最终判定攻击群组之前,需要对区间可疑度做缩放处理。通过指数缩放处理,在不改变可疑度值原来分布顺序的情况下,让可疑度值不同程度地增加或减小,数值越大,增加或减少的程度就越大。本文通过设定一个缩放系数x作为指数对可疑度做缩放处理。该方法弥补了线性缩放只能线性的扩大数据间距的缺陷,本文取x=2.1。
2.3.2非攻击评分的排除
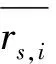
2.3.3攻击群组的判定
区间可疑度越大,说明越有攻击性,通过设定可疑度阈值,将大于该阈值的区间定位攻击群组。采用K-means聚类自动设定阈值,由于区间可疑度值可能会有重复,因此我们对可疑度值进行去重,之后利用K-means聚类对去重后的可疑度值进行聚类,聚类数为2,然后选取可疑度均值最大的类别中的最小值作为阈值,最后将可疑度不小于该阈值的区间判定为攻击群组。该方法的优点是阈值可以根据数据集或数据量的不同自动确定。
由2.3.1~2.3.3节总结出判定攻击群组的算法3,描述如下:
算法3 判定攻击群组
输入:区间可疑度集合IRBIAndSuss,系统评分中值rmid
输出:攻击群组集合AttGs
1.AttGs←∅,SusValues←∅
rmid) then
8. end if
9. end for
12. end for
13.SusValues←set(SusValues)
14. MAX_Values1,MIN_Values2←Kmeans(SusValues,2)
15.threshold←MIN(MAX_Values1)



19. end if
20. end for
returnAttGs
算法3主要包括3部分:第一部分(第1~3行)通过指数缩放处理区间可疑度,第二部分(第4~9行)过滤非攻击评分,第三部分(第13~19行)利用K-means聚类方法判定攻击群组。
算法3的时间复杂度分析如下:指数缩放处理区间可疑度(第1~3行)的时间复杂度为O(|U|·|I|),删除区间评分目的不同的行为(第4~9行)的时间复杂度为O(|U|2·|I|),K-means聚类判定攻击群组(第13~19行)的时间复杂度为O(|U|·|I|log(|U|·|I|)),因此算法3的时间复杂度为O(|U|2·|I|)。
3 实验结果分析
3.1 实验数据集
本文使用Amazon和Netflix数据集作为实验数据来检验算法的性能。Amazon数据集是由电商平台Amazon.cn提供的真实数据,在该数据集中抽取了具有标签的5 055名用户对17 610件产品的53 777条评分数据,评分范围为1~5分,表示用户对产品的满意程度。Netflix数据集是由电影网站netflix.com提供的真实数据,采用松散群组攻击模型,攻击类型为随机攻击和均值攻击,攻击规模和填充规模分别为10%和2.5%。
3.2 评价指标
采用精确率J、召回率Z和F1值作为评价指标,计算公式为
(9)
(10)
(11)
式中,C表示正确检测的攻击用户数量,C0表示被错误地当作攻击用户的数量,P表示数据集中所有攻击用户的数量。
3.3 对比实验分析
将IRBS算法与现有典型的6个攻击检测算法CoDetector[5]、CBS[6]、DeR-TIA[8]、PCA-VarSelect[9]、IRM-TIA[10]以及URGSSGD[13]进行对比实验,如表2和表3所示。

表2 Amazon数据集下算法对比Tab.2 Comparisons of algorithms on Amazon datasets

表3 Netflix数据集下算法对比Tab.3 Comparisons of algorithms on Netflix datasets
本文的IRBS算法根据攻击群组对目标项目评分的“时间集中”特性,对项目评分序列交叉划分评分区间。该方法不仅可以直接划分候选群组,还减少了通过序列用户分布的密度或通过固定时间窗口非交叉划分区间所造成的影响,提高了候选群组的质量。另外,根据攻击群组“对目标项目评分极端”的特性、个体行为相似性等特性对候选群组进行检测,提高了检测质量。通过对比结果发现,IRBS算法的检测结果优于其他几种算法。
4 结论
本文提出了一种基于项目评分行为序列和双聚类的群组攻击检测算法IRBS,与CoDetector相比,该算法不需要划分训练集和测试集,更不会因为正常用户和攻击用户的比例而使检测结果受到影响;与CBS相比,该算法不需要事先标记种子用户;与URGSSGD相比,该算法不会过滤掉用户,也不需要根据向量是否符合正态分布去检测异常向量;与PCA-VarSelect相比,能够更有效地检测攻击群组;与DeR-TIA相比,不会受限于用户之间共同评分项目数量,而是根据攻击群组的“时间集中”和“评分极端”特性检测攻击群组;与IRM-TIA相比,不会损失用户信息从而影响检测性能。
IRBS算法根据攻击群组的“时间集中性”“目标项目评分极端性”“同一群组中攻击用户个体特征相似性”以及双聚类不断对群组进行检测和筛选,从而确定攻击群组。通过对Amazon数据集和Netflix数据集的检测验证了该算法的有效性。
虽然该方法可以有效地检测攻击群组,但仍然需要人工提取特征,而人工提取的特征会使得特征覆盖不全面,从而影响检测结果。因此在未来工作中,拟采用生成对抗网络不断自动提高生成网络的生成能力和对抗网络的检测能力,从而在训练过程中自动提取特征来提高检测效果。
