基于孤立森林挖掘算法的入侵检测系统研究
2021-01-11吴元君
吴元君
(安徽财贸职业学院 云桂信息学院,安徽 合肥 230601)
从网络发展现状看,现阶段的互联网入侵风险表现出新的特征[1]。首先,网络拓扑结构越来越复杂,数据量表现为海量性特征[2-3],为恶意数据、恶意代码的隐藏提供了空间,入侵检测难度增大;其次,网络攻击手段多样化[3],现有的攻击手段和病毒类型不仅仅局限于早期的DDoS等的单一模式[4],而是出现了病毒变异并朝着复合病毒的方向变化[5];再次,从事网络攻击的黑客专业化素质提升,网络攻击的破坏性极大[6-7]。新型的网络攻击手段对于网络安全机制和入侵检测系统的性能提出了更高的要求,即如何实现在大数据和复杂的网络结构下精准定位和检测入侵的病毒。
网络入侵检测系统的设计目标包括优化设计模型以提高检测率,同时降低入侵检测的误报率。入侵检测过程本质上是对系统内部、外部的异常行为进行全方位的识别。陈露露等[8]提出基于优化信息熵的入侵检测预测模型,利用反向神经网络预估系统参数值,进而检测网络数据是否存在异常,该种方案的缺点是计算复杂度过高,样本训练次数过大,迭代效果过低;王伦文等[9]采用阈值法判定一组原始数据是否包含恶意数据或恶意代码,该种方案缺点是实际检测中恶意数据与有用数据之间的差别较小,界限和标准不易划分,导致准确的阈值范围确定难度极大,使得阈值法具有较低的检测率和过高的误检率,且随着样本数据集合总量的增加,该方法的检测率值衰减过快。
针对现有入侵检测系统存在的问题,本文基于数据挖掘技术,利用优化的IF(孤立森林)挖掘算法设计了一种入侵检测系统,利用孤立森林算法的无监督性和快速集成性,提升对恶意数据的入侵检测效率。
1 孤立森林挖掘算法原理及优化
孤立森林算法作为数据挖掘算法的一个分支,其主要思想是采用空间异常点递归的解决方案,因为孤立的异常数据点在特征属性上与正常数据存在差异,更容易被访问到[10]。
随机选定一个数据集X,对其样本空间进行分割得到两个子样本空间,继续细化切分直到子样本空间包含的数据点类别唯一。令分层的节点集合为N,层数为i,从左到右的节点数为j,则数据集Xij应满足以下条件:
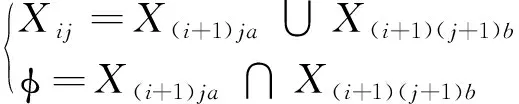
(1)
式中a和b主要用于区分左节点和右节点。为了孤立异常的数据点,需要对原始数据集进行多次切分,如果异常数据点刚好处于数据集中密度较低的区域,切分过程很快就能停止;如果异常的数据点位于密度较高的区域,孤立异常数据点的难度会明显增大。
针对现有孤立森林算法分割过于随机的问题,本文基于蒙特卡洛准则限定一个最低的收敛值,具体步骤如下:
从数据集X中选y个样本点作为二叉树的根节点,记为nXk,随机选择一个样本属性τ和切分点η,根节点nXk覆盖了样本属性的全部区间,即
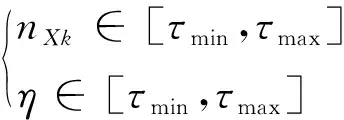
(2)
通过比较属性τ和切分点η之间的大小关系,将y个样本点分配给根节点,完成节点二叉树结构的构建。以样本点在每个二叉树的高度为评价标准,设置一个最优的阈值用于评价和识别异常数据。对随机森林中全部二叉树的高度作归一化处理,得到一个数据点集合[0,1],如果反复迭代分割后得到的数值越接近于1,表明该数据是异常入侵数据的概率越高。当指定数据的二叉树构建完成后,通过反复训练原始数据,在剔除每个区域内的异常数据点后组成森林。基于蒙特卡洛准则限定后的二叉树个体相互独立,互不干扰,因此单独的个体都可以独立执行,提高了迭代训练的效率。
二叉树森林模型构建完成后输出全部原始互联网数据集,基于IF算法分割原始数据集,遍历模型集合中的每个二叉树个体,计算当前个体的高度,并递归叠加高度。对数据集X中的任意一个样本点xi,如果切分函数η(x)的平均值E(η(x))趋近于零,此时对异常样本集合的评分趋近于1,则该类样本为异常样本的概率较大;当E(η(x))趋近于n-1时,异常样本的综合评分低于0.5,则该样本极有可能是正常的样本。优化IF算法在处理海量不均匀分布的大数据时,相对于现有的检查方法优势更为明显,本文基于优化的IF算法原理,设计了互联网数据入侵检测系统的硬件模块结构和软件算法流程。
2 入侵检测系统的硬件模块设计
孤立森林挖掘算法的系统规则,主要分为规则要素和规则选项两个部分,其层次关系如图1所示。本文设计的入侵检测系统具有良好的兼容性,能够支持IP、TCP、ICMP等多重协议。检测时,在多规则匹配中良好的兼容性可以保证数据集切分具有良好的精度;来源于源地址的原始数据按照指定的端口和IP地址选择不同类别的规则要素;数据特征按规则匹配,数据库的规则选项提供了完整详细的对照信息内容,规则的内容可以按照管理员的需求自定义,只有全部字段的所有要素完全相同才能够匹配成功;个别数据包中存在干扰信息导致误报率升高,经过优化的IFMA算法在特征点阈值范围的标定方面更为准确,能够按照特征数据库和规则库逐条匹配。
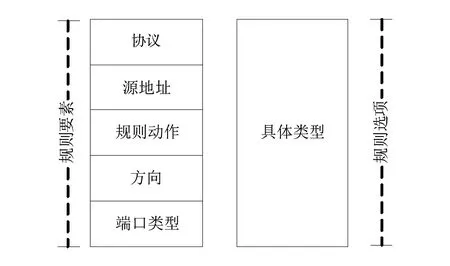
图1 系统规则的整体结构 Fig 1 The overall structure of the system rules
按照孤立森林挖掘算法的系统规则,设计入侵检测系统的硬件模块结构,如图2所示。为了更好地发挥优化IF算法的优势,本文采用了模块化的设计思维,增加了系统的灵活性,达到最优的异常数据预测和类别划分效果。
图2中入侵检测系统各模块的功能如下:
(1)数据采集模块,主要负责全部待检测数据的采集,并将采集的数据输入解码预处理模块和检测引擎模块。
(2)解码预处理模块,按照数据的类型和规则库对原始数据作初步的预处理,例如剔除与协议不符合的数据,对原始数据进行降噪处理等。解码和预处理模块是后续运用优化IF算法进行异常检测的基础,解码和数据预处理的目的是按照协议的规则,使原始数据更适合于二叉树的匹配模式,以便在调整之后可以提供完整的数据包。
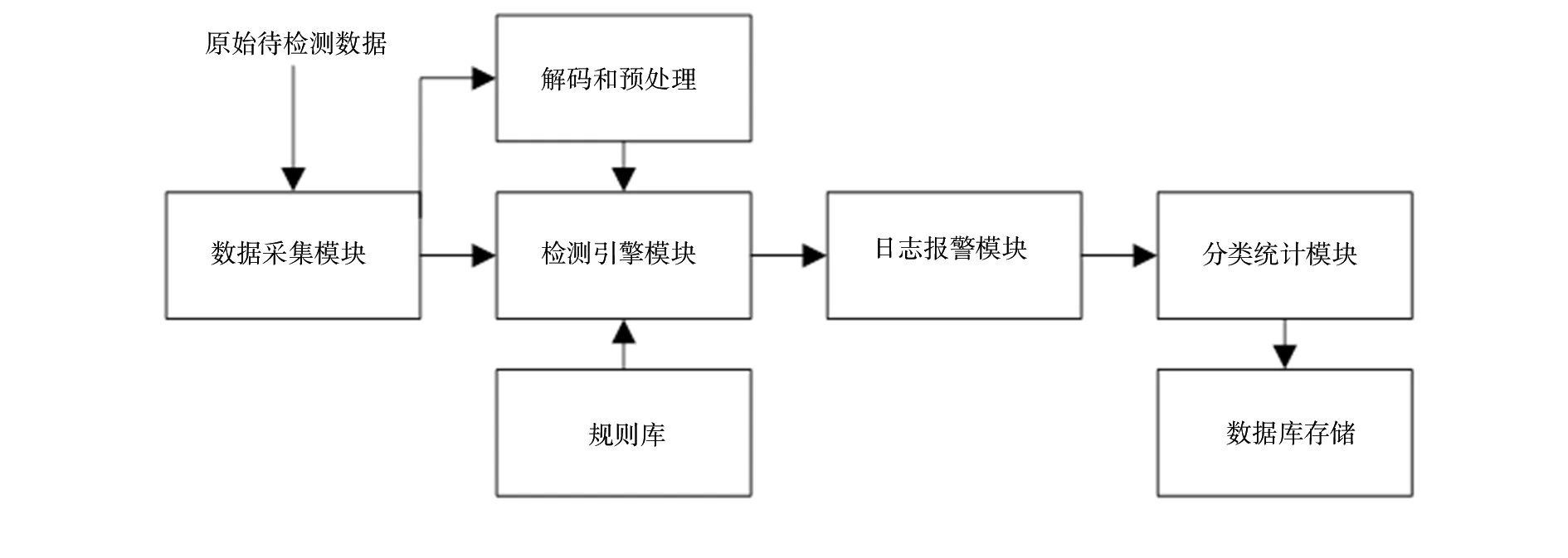
图2 基于优化IF算法的数据入侵检测系统硬件模块构成 Fig 2 The hardware module composition of the data intrusion detection system based on the optimized IF algorithm
另外,协议解码和预处理后的相关数据组,还可以在后续模式匹配中提高样本属性切分的合理性。
(3)检测引擎模块,是入侵检测系统的核心,内置了97C51型高性能的MCU单元。检测引擎模块根据优化的IFMA算法和数据包的不同协议标准,利用97C51型芯片强大的数据在线处理功能,对进入系统的经预处理完成的数据进行阈值判定和逐层迭代反复寻优,提高了对孤立特征点的搜索能力,即使入侵数据与正常数据的特征点较为相近,也能够通过多次迭代和多次的内容匹配,在较短时间内实现对全部数据包的遍历和检测。如果一组原始数据被识别出存在异常点,则将此信息传递到日志报警模块,并记录相关规则于本地数据库,同时提醒管理员系统存在隐患。而对一些重要性较低的统计数据、日志数据等则转为离线处理,以缓解MCU单元的数据处理压力。
(4)日志报警模块,主要用于发现异常数据点的信息报警。入侵检测的报警方式和报警周期可以按照管理员的不同需求分类设置。
(5)规则库模块,在优化的IF算法下检测规则都以系统文件的形式存在于规则库中,规则库功能随着处理数据总量的增加而不断完善。如果规则库中已有的规则能够与异常数据的特征相匹配,则可以节省大量的检测时间,系统可以自动防御各种不同类型的网络攻击。
(6)分类统计与存储模块,主要用于规则的分类统计与存储。分类统计之后,如果有新的入侵病毒类型出现,则将其存入系统自带的数据库中,并与已有的规则库相融合,便于下一次入侵检测时直接滤除。
3 系统软件流程设计
基于优化的IF算法的入侵检测系统采用集中式控制与分布式管理相结合的方法,其软件实现流程如图3所示。
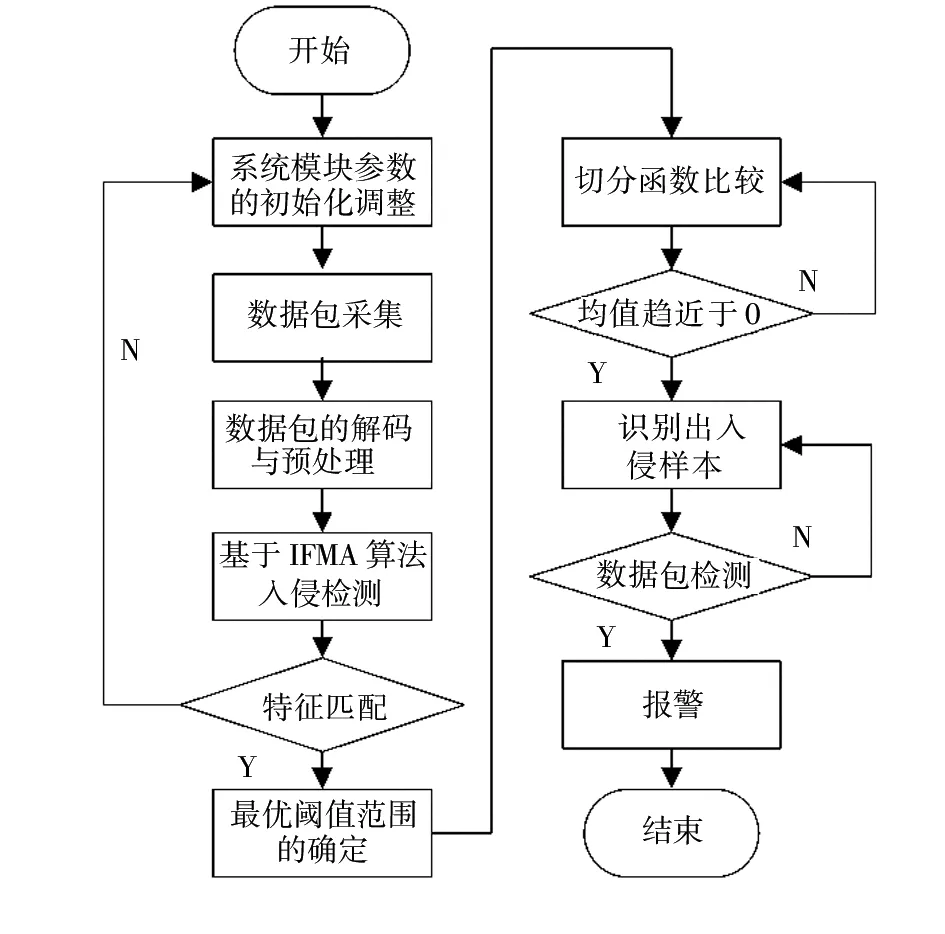
图3 系统软件的整体实现流程Fig 3 The overall realization process of the system software
数据包解码预处理后的最重要流程是基于优化IF算法逐层分割数据集并寻找孤立的异常入侵数据点。入侵检测的过程包括对规则库的解析和对模式匹配方式的认定,基于优化的IF算法的特征匹配成功且切分函数的值趋近于0,即可以依据孤立森林挖掘算法规则检测出孤立的数据点,报警并提示系统管理员当前的数据组内含有异常的数据。算法的实现过程可以用关键代码描述如下所示:
ifx≥kor |x|≤1 then
return ex note {size←|x|}
else
randonmly select anxinX
xt←filter(x≤k)
return
end if
4 系统测试
入侵系统测试是将经过集成测试的软件,作为计算机系统的一个部分,与系统中的硬件部分结合起来,在计算机实际运行环境下对计算机系统进行一系列严格有效的测试,以便及时识别出软件潜在的问题,保证入侵检测系统的正常运行。入侵检测系统的测试过程包括系统功能测试和系统性能测试两个部分,其中,功能测试主要是检测系统的硬件部分和软件功能能否较好地满足用户的实际需求;而性能测试主要是研究基于优化IF算法的入侵检测系统在入侵检测方面相对于传统方式的具体优势所在。系统测试前需要对其运行环境进行设置,具体设置如表1所示。

表1 入侵检测系统的环境设置Table 1 Environment settings of intrusion detection system
4.1 系统功能测试
入侵检测系统的功能测试首先检测系统各主要模块的基础功能。测试次数与测试结果如表2所示,如果检测通过则用★表示。
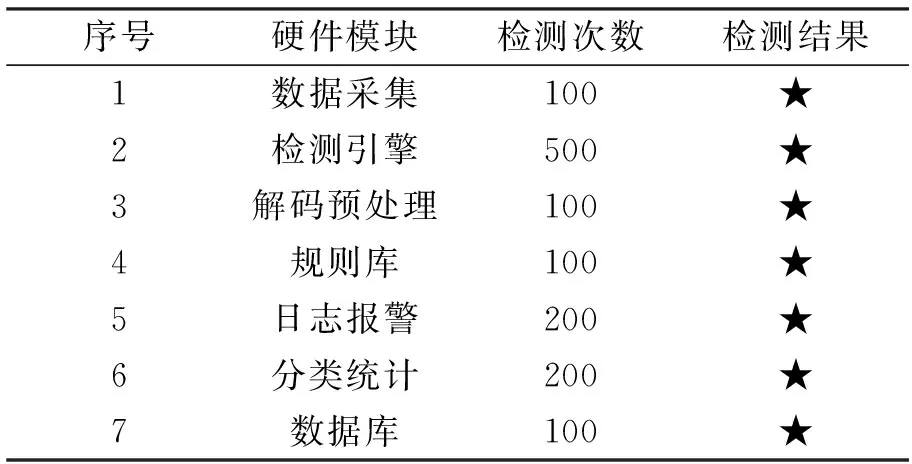
表2 入侵检测系统模块的功能测试Table 2 Functional test of intrusion detection system module
由表2可知,各硬件模块的功能检测全部通过。表明入侵检测系统各硬件模块功能正常,能够满足系统功能上的各种需求。入侵检测系统的软件功能测试主要采用黑盒测试方式,该方法能更好、更真实地从用户角度考察被测系统功能性需求的实现情况。在黑盒测试过程中,将主控程序和各个子程序视为未知的黑盒子,暂时不考虑各级控制程序的内部逻辑关系、结构特征与其他特性。测试时,系统软件运行环境为Windows10专业版,数据库类型选用MySQL型标准数据库;检测的子程序包括数据采集程序、数据预处理程序、基于优化IFMA算法的入侵检测程序、日志报警程序和数据库存储程序,测试的重点在于程序接口能否正常工作,程序执行完毕之后能否输出正确的信息。检测结果如表3所示。
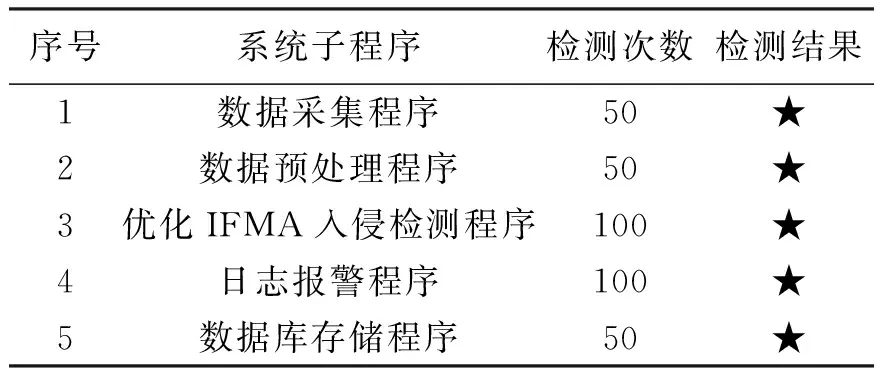
表3 系统子程序的用例测试Table 3 Use case test of system subroutine
由表3可知,各子程序均通过了的功能检验,表明系统的软件程序功能完好。
4.2 系统性能测试
由于网络数据中经常包含一定数量的恶意入侵代码,入侵检测系统的性能测试主要围绕不同规模的网络日志数据展开,并通过检测率与误检率两个指标来表达。随着网络日志总体规模的不断扩大,如果系统处理数据的速率衰减较慢,表明系统的性能较为强大,可以为用户带来更好的使用体验及安全体验。
为了比较不同检测方式的检测性能,将经预处理的数据总量30 556条(其中包括恶意代码1 230条)分为10组,分别利用基于优化IFMA算法的检测系统、基于信息熵的检测系统和基于阈值法设计的检测系统遍历全部的样本数据,统计其检测率和误检率情况,结果如表4、表5所示。
表4、表5中的检测率、误检率指标计算公式如下:

(3)

(4)
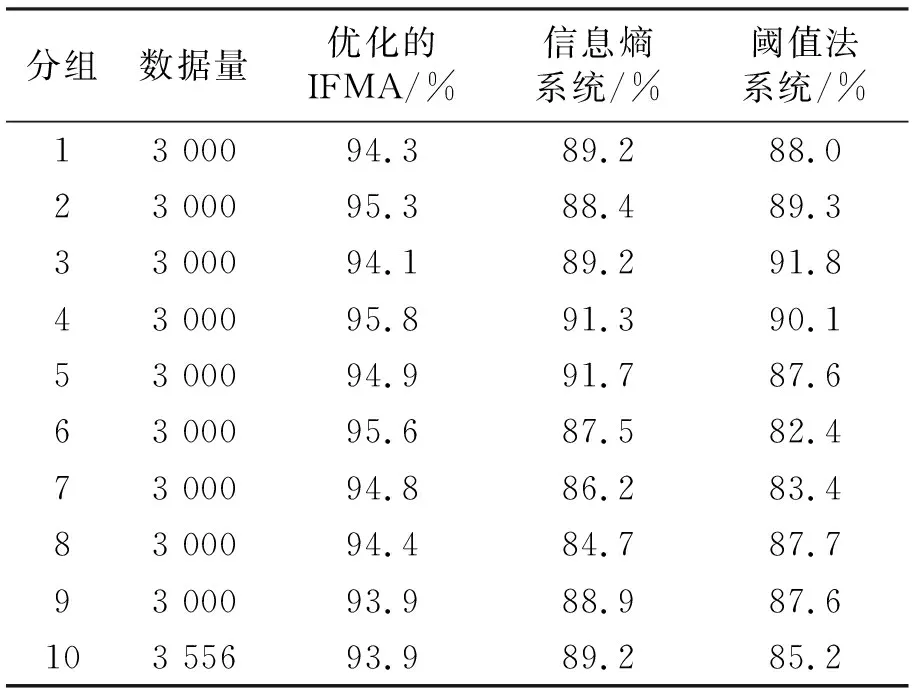
表4 入侵检测率水平对比Table 4 Comparison of intrusion detection rate levels
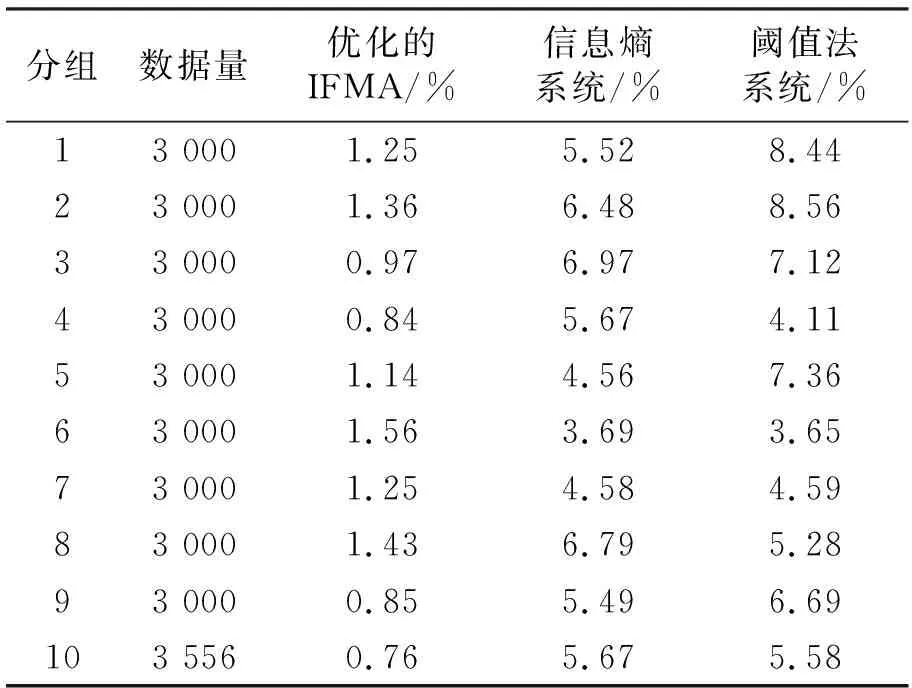
表5 入侵检测误检率水平对比Table 5 Comparison of false detection rate of intrusion detection
理论条件下检测率水平值为95.98%,显然表4中的基于优化IFMA算法的检测系统的各组数据检测值最接近于理论值,而远高于其他两种传统系统方案。从表5中各组误检率的指标值分布情况看,基于优化的IF算法的系统误检率水平要低于其他两种传统方案,这主要得益于最低收敛值的设定,避免了切分过程中出现过多的系统偏差。
随着网络数据集总体规模的不断扩大,检测系统的效率问题成为衡量系统性能的重要指标之一。上述三种检测系统对上面检测数据集的耗时随数据集规模的变化趋势如图4~图6所示。
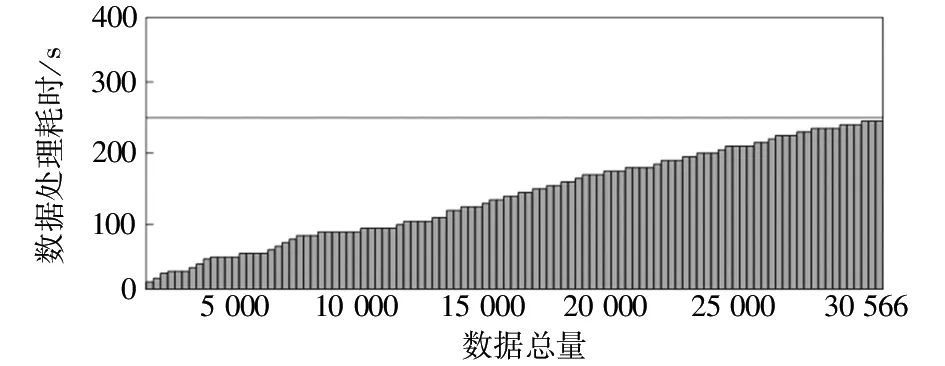
图4 基于优化的IFMA算法的系统检测耗时变化 Fig 4 System detection time-consuming changes based on optimized IFMA algorithm
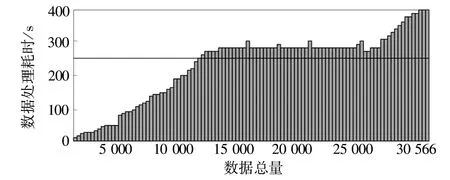
图5 基于信息熵的系统检测耗时变化趋势 Fig 5 Time-consuming change trend of system detection based on information entropy
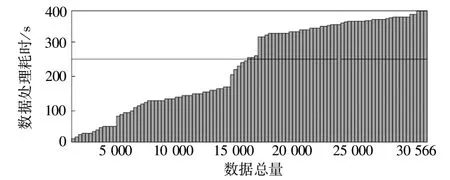
图6 基于阈值法的系统检测耗时变化趋势Fig 6 Time-consuming change trend of system detection based on threshold method
由图4可知,图中直方图变化趋势总体平稳,未出现明显的波动,数据检测的耗时总体上与数据规模呈现出线性变化的趋势。而图5、图6中的直方图变化趋势显示,当待检测的数据规模超过15 000条时,检测效率明显降低,且基于信息熵的检测系统还出现了异常波动;与文中设计的检测系统相比,基于信息熵的检测系统总体检测耗时明显增加。
5 结论
随着互联网的快速发展,网络在人们工作和生活中发挥着决定性的作用,但网络的开放性也会带来大量的安全隐患。本文基于优化的IF算法设计了针对网络恶意攻击和恶意代码的入侵检测系统,该系统利用多层数据分割能够快速定位孤立的数据点,因此在应对海量规模数据样本时,与传统方案相比该系统具有更为明显的优势。在未来互联网的发展过程中,网络攻击行为会更加地隐匿,系统的软硬件需要不断地升级,并完善系统的规则库和数据库,以提高入侵检测系统的适应能力。
