基于相容关系的局部多粒度粗糙集模型
2021-01-08周悦丽林国平
周悦丽,林国平*
(1.闽南师范大学 数学与统计学院,福建 漳州 363000;2.数字福建气象大数据研究所,福建 漳州 363000)
0 引言
粗糙集理论是我们对于不确定信息进行近似处理的一种模型。该理论[1]的主要内容是通过不可分辨关系对信息系统进行粒化,从而构建目标概念中有关样本的上下近似集。
为了适应社会的发展要求,粗糙集模型的推广与应用是许多学者讨论和研究的重点。由经典粗糙集的定义可以了解到经典粗糙集是在等价关系的基础上进行定义的,且主要是面对属性值完备且单一的信息系统,利用上下近似集来探寻信息系统中数据的相关性。但是实际应用中,由于考虑到现实问题的复杂性、数据的不完整性与不精确性,许多学者通过扩展等价关系建立了许多扩展粗糙集模型,比如:建立邻域关系和邻域粗糙集模型[2-3]来处理数值型数据;建立相容关系和相容类[4-5]来处理集值型的数据问题;建立容差关系和相似关系[6-7]等来处理缺失数据。此外,因为经典粗糙集模型的主要缺点是欠缺对噪声数据和分类的容错能力,因此众多学者将概率论与经典粗糙集结合起来并进行推广,例如Pawlak建立了概率粗糙集模型[8],Ziako提出了变精度粗糙集模型[9]。同时在实际生活的应用中,考虑到从不同角度观察和分析同一问题,钱宇华等研究了多粒度粗糙集模型[10]。
大数据时代已经到来,在监督学习的策略下,经典粗糙集及其扩展模型需要大量标记数据。面对大数据时代带来的挑战,标记数据无疑会耗费大量时间, 所以钱宇华提出了局部粗糙集模型[11]和局部多粒度决策粗糙集模型[12]。因为以上模型均建立在等价关系的基础上,过于严格,不适用于其他数据类型。于是,Wang等人提出了局部邻域粗糙集模型[13],Zhang等人在有序信息系统上建立了基于优势关系的局部粗糙集和局部多粒度决策粗糙集[14]。为了处理集值型的数据问题,Xu等人提出了两类基于相容关系的多粒度粗糙集模型[15]。当这两类模型在处理数据的时候,要通过预览整个论域中全部样本的相容类才能进行处理,这样的处理方式在面对海量数据时,其效率比较低。于是本文在文献[15]的基础上,在集值信息系统上建立两类局部多粒度相容粗糙集模型,进一步有效处理此类数据,这样可以把我们筛选的信息范围缩小至局部,排除那些与目标概念完全无关的全局中冗余的信息,减少时间的消耗和简化计算步骤。
基于以上分析,本文首先基于集值信息系统给出局部多粒度相容粗糙集模型的定义,并探讨了该模型的有关性质, 然后给出下近似的算法,并通过具体实例说明算法的有效性。
1 相关基础知识

如果一个系统不是一个单值信息系统,那么称之为集值信息系统。其定义如下:
定义2[16]设S=(U,AT,V,f)为一个集值信息系统,U为论域,AT是属性集,V为值域,f是U×AT到V的映射,而且满足以下条件f:U×AT→2V是一个集值映射。在此条件下,∀a∈AT,x∈U,|f(x,a)|≥1。
定义3[4-5]设S=(U,AT,V,f)为一个集值信息系统,∀b∈AT,相容关系Tb定义如下:
Tb={(x,y)|f(x,b)∩f(y,b)≠ø}。
(1)
对∀B⊆AT,相容关系TB定义为:
TB={(x,y)|∀b∈B,f(x,b)∩f(y,b)≠ø}
即
(2)
当(x,y)∈TB,则x与y是不可分辨的或x与y是相容的。
定义TB(x)={y|y∈U,yTBx},则TB(x)为x在TB下对象x的相容类。
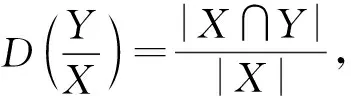

2 局部多粒度相容粗糙集模型
在现实中,集值型的数据问题比较常见,比如当我们在对一个项目进行投资之前,我们可以通过多位专家对项目的评价指标进行评估,这些评价指标可以是收入、风险、社会效益、市场效应等方面,当不同的专家依次对各项指标作出评价时,可以得到对应的评价意见。而将这些评价意见结合起来,这些不同意见也就成为对应指标的可能取值。因为文献[10]中定义的多粒度粗糙集模型是在完备信息系统上提出的,对于集值信息系统上出现的集值型数据,很显然这些多粒度粗糙集模型并不适用。因此为了对比研究,在文献[15]的基础上,将论域U上第1型多粒度相容粗糙集模型和第2型多粒度相容粗糙集模型进行推广,提出集值信息系统上的乐观多粒度相容粗糙集模型和悲观多粒度相容粗糙集模型。
定义5 设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则X基于相容关系Ti,i=(1,2,…,m)的乐观下近似和乐观上近似分别为:

(3)

(4)
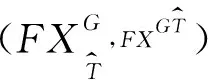
定义6 设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则X基于相容关系Ti,i=(1,2,…,m)的悲观下近似和悲观上近似分别为:

(5)
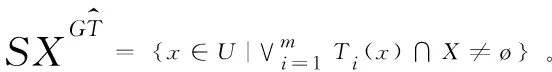
(6)

为了区分这两种模型和接下来我们构建的两种模型,下文称以上的乐观多粒度相容粗糙集为全局乐观多粒度相容粗糙集,悲观多粒度相容粗糙集为全局悲观多粒度相容粗糙集。
将局部粗糙集与多粒度相容粗糙集模型结合起来,建立以下两种局部多粒度相容粗糙集,分别是局部乐观多粒度相容粗糙集模型和局部悲观多粒度相容粗糙集模型。
2.1 局部乐观多粒度相容粗糙集模型
首先讨论基于m种相容关系的局部乐观多粒度相容粗糙集。
定义7 设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则X基于相容关系Ti,i=(1,2,…,m)的局部α-乐观下近似和局部β-乐观上近似分别为:
(7)
D(X/Ti(x))>β,x∈X}。
(8)

当α=1,β=0时,
D(X/Ti(x))>0,x∈X}=
从上述分析可知,当α=1,β=0时,局部乐观多粒度相容粗糙集模型可退化为全局乐观多粒度相容粗糙集模型,也就是说,局部乐观多粒度相容粗糙集与全局乐观多粒度相容粗糙集具有相同的形式与语义。从这个角度来看,这两种模型具有一致的处理集值型数据的能力。因此,我们可以把全局乐观多粒度相容粗糙集模型看作是局部乐观多粒度相容粗糙集模型的一种特殊情形。
下面给出局部乐观多粒度相容粗糙集的相关性质及其证明。
性质1设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则对于任意的X,Y⊆U,0≤β<α≤1,有以下性质成立:
证明

(2)β∈[0,min{D(X/Ti(x)):
(3)a)|Ti(x)∩ø|=0
⟹D(ø/Ti(x))=0,∀i≤m
⟹D(ø/Ti(x))≤β<α,∀i≤m
b)Ti(x)∩U=Ti(x)
⟹D(U/Ti(x))=1,∀i≤m
⟹D(U/Ti(x))≥α>β,
∀i≤m(0≤β<α≤1)
(4)X⊆Y
⟹D(X/Ti(x))≤D(Y/Ti(x)),∀i≤m
⟹∃i≤m,s.t.D(Y/Ti(x))≥D(x|Ti(x))≥α
D(Y/Ti(x))≤D(Y|Ti(x))≤β
⟹∃i≤m,s.t.D((X∩Y)/Ti(x))≥α
⟹∃i≤m,s.t.D(X/Ti(x))≥α,
⟹∃i≤m,s.t.D((X∪Y)/Ti(x))≤β
⟹∃i≤m,s.t.D(X/Ti(x))≤β,
⟹∃i≤m,s.t.D(X/Ti(x))≥αor
D(Y/Ti(x))≥α
⟹∃i≤m,s.t.D(X∪T)/Ti(x))≥α
⟹∃i≤m,s.t.D(X∩Y/Ti(x))≤βor
D(Y/TB(x))≤β⟹∃i≤m,s.t.D((X∩Y)/Ti(x))≤β
⟹∃i≤m,s.t.D(X/Ti(x))≥α2
⟹∃i≤m,s.t.D(X/Ti(x))≥α1
⟹∃i≤m,s.t.D(X/Ti(x))≤β1
⟹∃i≤m,s.t.D(X/Ti(x))≤β2
2.2 局部悲观多粒度相容粗糙集模型
定义8 设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则X基于相容关系Ti,i=(1,2,…,m)的局部α-悲观下近似和局部β-悲观上近似分别为:
D(X/Ti(x))≥α,x∈X},
(9)
D(X/Ti(x))>β,x∈X}。
(10)

性质2设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),则对于任意的X,Y⊆U,0≤β≤α≤1,有以下性质成立:
(2)β∈[0,min{D(X/Ti(x)),
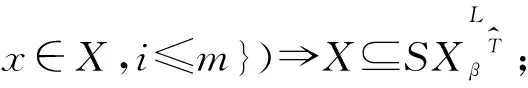
(7)0.5<α1<α2≤1
(8)0≤β1<β2<0.5
局部乐观多粒度相容粗糙集和局部悲观多粒度相容粗糙集联系的分析:
定理1 设S=(U,AT,V,f)是一个集值信息系统,T1,T2,…,Tm为论域U上的m个相容关系,由T1,T2,…,Tm诱导出的相容类为T1(x),T2(x),…,Tm(x),且X⊆U,则我们可以得到:
其实,局部悲观多粒度相容粗糙集模型和局部乐观多粒度相容粗糙集模型类似。在一定条件下,也可以退化为全局悲观多粒度相容粗糙集模型。因此,可以看出两种局部多粒度相容粗糙集模型在本质上并没有改变两种全局多粒度相容粗糙集模型。不过,在两种局部多粒度相容粗糙集模型中,计算目标概念的下、上近似不需要事先获取论域中全部样本的相容类,而只需要计算目标概念中样本的相容类,这大大减少了计算的时间。接下来用相关算法和例子分析对此进行具体说明。
3 算法
与全局多粒度相容粗糙集模型进行比较,可以发现局部多粒度相容粗糙集模型在对下近似的计算中效率较高,在这里给出局部乐观多粒度相容粗糙集和全局乐观多粒度相容粗糙集的下近似算法,并进行比较。
算法1给定集值信息系统中的局部乐观多粒度相容粗糙集的目标概念的下近似
输入:集值信息系统S=(U,AT,V,f)和目标概念X⊆U以及参数α
输出:目标概念的局部下近似LLA。
1: 从i=1到m
从j=1到|X|进行循环运算,计算出xi的相容类Ti(xj)。
2:LLA⟸ø,j=1;
3: 从j=1到|X|做循环
{
如果∪D(X/Ti(xj))≥α,i=1,2,…,m
然后LLA⟸LLA∪{xj}
}
4. 返回LLA,算法结束。
算法2给定集值信息系统中的全局乐观多粒度相容粗糙集的目标概念的下近似
输入:集值信息系统S=(U,AT,V,f)和目标概念X⊆U以及参数α
输出:目标概念的全局下近似GLA.
1: 从i=1到m
从j=1到|U|进行循环运算,计算出xi的相容类Ti(xj)。
2:GLA⟸ø,j=1;
3: 从j=1到|U|做循环
{
如果∪D(X/Ti(xj))=1,i=1,2,…,m
然后GLA⟸GLA∪{xj}
}
4: 返回GLA,算法结束。
在算法1中只需要计算X中每个样本在m个相容关系下的相容类,因此它的时间复杂度包括算法1中的步骤1,步骤3和其他步骤的时间复杂度。设其他步骤时间复杂度为常数,即计算其下近似的时间复杂度等于O(|m||X||U|)+O(|m||X|2)+常数;在算法2中需要计算U中每个样本在m个相容关系下的相容类,因此它的时间复杂度包括算法2中的步骤1,步骤3和其他步骤的时间复杂度,即O(|m||U|2)+O(|m||X||U|)+常数。

证明根据以上分析,可以得到:

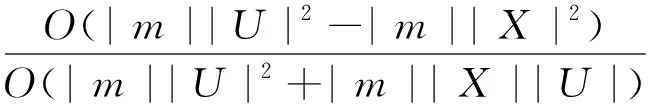
基于以上理论分析,可以得到局部多粒度下近似算法在处理大规模数据时是十分高效的。从上述结果看出时间效率t提升和时间节约率p均随着论域U的增大而增大,U越大,算法1相比算法2越高效。
4 例子分析
通过一个例子来说明以上的有关概念,给定一个集值信息系统,如表1所示。

表1 集值信息系统
在S=(U,AT,V,f)中,取A={a1,a2},B={a2,a3},和C={a3,a4}为AT的属性子集,这三个属性子集可以确定论域U上三个相容关系,分别记为T1,T2和T3,对于给定目标概念X={x1,x3,x4,x8,x9},取α=0.6,β=0.1,若计算X的局部乐观多粒度相容粗糙集下、上近似,我们只需要计算X中样本的相容类,通过定义计算可得:
T1(x1)={x1,x2,x3,x4},
T1(x3)={x1,x3},
T1(x4)={x1,x2,x4,x6,x7,x8,x9},
T1(x8)={x2,x4,x6,x8},
T1(x9)={x2,x4,x5,x6,x7,x9},
T2(x1)={x1,x2,x3,x4,x6},
T2(x3)={x1,x2,x3,x4,x6},
T2(x4)={x1,x2,x3,x4,x5,x6,x7,x8,x9},
T2(x8)={x2,x4,x6,x8},
T2(x9)={x2,x4,x7,x9},
T3(x1)={x1,x2,x3,x4,x6,x8},
T3(x3)={x1,x2,x3,x4,x6,x8},
T3(x4)={x1,x2,x3,x4,x5,x6,x7,x8,x9},
T3(x8)={x1,x2,x3,x4,x6,x8},
T3(x9)={x2,x4,x7,x9}。
因此根据包含度公式可得:
{D(X/T1(xn),n=1,3,4,8,9}=
{D(X/T2(xn),n=1,3,4,8,9}=
{D(X/T3(xn),n=1,3,4,8,9}=
由α=0.6,β=0.1可得:
对于全局乐观多粒度相容粗糙集,需要计算全部样本的相容类,通过计算可以得到:
T1(x1)={x1,x2,x3,x4},
T1(x2)={x1,x2,x4,x6,x7,x8,x9},
T1(x3)={x1,x3},
T1(x4)={x1,x2,x4,x6,x7,x8,x9},
T1(x5)={x5,x6,x7,x9},
T1(x6)={x2,x4,x5,x6,x7,x8,x9},
T1(x7)={x2,x4,x5,x6,x7,x9},
T1(x8)={x2,x4,x6,x8},
T1(x9)={x2,x4,x5,x6,x7,x9},
T2(x1)={x1,x2,x3,x4,x6},
T2(x2)={x1,x2,x3,x4,x6,x7,x8,x9},
T2(x3)={x1,x2,x3,x4,x6},
T2(x4)={x1,x2,x3,x4,x5,x6,x7,x8,x9},
T2(x5)={x4,x5,x6},
T2(x6)={x1,x2,x3,x4,x5,x6,x8},
T2(x7)={x2,x4,x7,x9},
T2(x8)={x2,x4,x6,x8},
T2(x9)={x2,x4,x7,x9},
T3(x1)={x1,x2,x3,x4,x6,x8},
T3(x2)={x1,x2,x3,x4,x6,x7,x8,x9},
T3(x3)={x1,x2,x3,x4,x6,x8},
T3(x4)={x1,x2,x3,x4,x5,x6,x7,x8,x9},
T3(x5)={x4,x5,x6},
T3(x6)={x1,x2,x3,x4,x5,x6,x8}
T3(x7)={x2,x4,x7,x9},
T3(x8)={x1,x2,x3,x4,x6,x8},
T3(x9)={x2,x4,x7,x9}。
由包含度公式可得:
{D(X/T1(xn),n=1,2,3,4,5,6,7,8,9}=
{D(X/T2(xn),n=1,2,3,4,5,6,7,8,9}=
{D(X/T3(xn),n=1,2,3,4,5,6,7,8,9}=
由定义可得:
在例子中,我们可以看到计算目标概念X的上下近似时,局部乐观多粒度相容粗糙集只需要计算15个相容类。然而,全局乐观多粒度相容粗糙集则需要计算27个相容类。从这里可以看出,就计算相容类的个数而言,局部多粒度相容粗糙集降低了计算目标概念X的上下近似的时间。
集值型数据的研究颇具实际意义,比如在对投资项目进行风险评估时,通过综合不同专家对于各项评估指标的评价意见,会降低投资失败的风险,争取利益最大化。由以上例子可以看出,局部多粒度相容粗糙集模型处理集值型的数据问题时能够提高计算效率,减少计算量。
