1种改进长短期记忆神经网络的风电功率预测
2021-01-05任文凤冯志亮杜艳丽段昱臻
任文凤,冯志亮,杜艳丽,段昱臻
(北华大学电气与信息工程学院,吉林 吉林 132021)
风能,因避免了火电的环境污染及水电的生态影响,在我国得到了广泛应用.为了保证电网的安全运行,有必要也必须对风力发电系统进行有效的规划和控制,因此,风电场短期功率预测相关研究的重要性显而易见[1].针对风电功率预测问题,学者们提出了多种预测方法,大致可以分为物理法和统计法[2-5]两类,常用的有持续法(Persistence Approach)[6]、时间序列法(Time Series Method)[7]、支持向量机法(Support Vector Machine,SVM)[8]、人工神经网络法(Artificial Neural Network,ANN)[9]、模糊逻辑法(Fuzzy Logic)[10]以及这些方法的组合方法等[11-12].比如,文献[13]采用SVM预测了风电功率,结果显示,作为机器学习算法,SVM有较好的数学理论支撑,且对于小数据集预测有较好的预测精度和泛化能力,但在大数据集下,SVM的特征提取比较困难,导致精度下降;文献[14]对比了深度学习算法长短期记忆(Long Short-Term Memory,LSTM)与自回归移动平均模型(Autoregressive Integrated Moving Average Mode,ARIMA),证明了基于神经网络LSTM的风力发电功率时序预测方法可以更好地拟合原始风力发电功率曲线,但对于变化复杂的发电功率而言,单一的网络并不能充分提取原始数据信息,导致预测精度并不是很好;文献[15]采用了小波变换(Wavelet Transform,WT)和LSTM相结合的方法预测风电功率,结果表明,WT可以消除模态混叠现象,相比单一神经网络性能要更好,但是在高频下预测精度并不是很理想;文献[16]提出了天气状况与双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)相结合的预测方法,整体预测效果很好,但是由于风电功率和天气状况都需要预测,可变因素增多,且由于特征值太多导致神经网络预测结果有较强的滞后性.尽管使用组合方法预测风电功率的方法已经很普遍,但尚未见将分解方法和多种神经网络相结合预测风电功率的研究成果.基于此,本文提出1种将变分模态分解(Variational Mode Decomposition,VMD)和深度神经网络(Deep Neural Network,DNN)及BiLSTM相结合的风力发电功率预测方法.采用VMD技术将不规则、波动性较大的风电功率曲线分解为多个光滑、平稳的曲线组合,对这些曲线分别建立DNN或BiLSTM预测模型,将各个曲线的预测结果进行线性叠加.为了确保所提出方法的预测准确性,利用预测值与原始数据计算预测误差,并根据我国某风电场的实际数据,运用深度学习框架Keras对其进行仿真.
1 风电功率预测
风电功率预测系统包括模型训练和预测推理两部分,总体框架见图1.
1)模型训练.首先对原始风电功率数据进行预处理,然后对处理后的数据进行VMD分解,将分解得到的数据转化为有监督学习问题,利用训练数据集和验证数据集训练模型,经过多次迭代后得到最终模型;
2)预测推理.测试数据集数据经VMD分解后放入已经训练完成的模型中,得到预测功率值,计算误差.
2 神经网络预测模型对比
DNN神经网络是层与层之间全连接的神经网络,算法相对简单,在训练和预测时运算速度较快,非常适合对预测速度和精度有要求的风电功率预测,但由于是全连接,导致网络极易过拟合,所以在构建网络时需要更好地调节超参数.
循环神经网络(Recurrent Neural Network,RNN)是一种适合处理序列问题的神经网络,能够结合“上下文”信息预测新信息,但容易出现梯度消失;而LSTM在充分利用时间序列数据的同时,可以克服RNN梯度消失的问题,弥补不具有长期记忆能力的不足;BiLSTM比LSTM多了1个反向隐含层,利用输入特征与下一时刻预测值间的联系提高模型的特征学习强度.BiLSTM的优势在于利用两个方向的网络预测同一节点的数据,两层神经网络独立计算,分别生成各自的状态向量和输出,最终将两层网络输出简单拼接得到最终输出,模型的预测能力得到了提高.
为了选取合适的神经网络模型,在选取合适超参数的情况下,分别建立了DNN、LSTM、BiLSTM预测模型.预测结果对比见图2(每次间隔15 min,下同),模型训练网络超参数选取及测试集误差分别见表1、表2(选择在迭代过程中Loss最小的模型进行保存,所以网络训练迭代次数不同).其中,评价指标均方根误差(Root Mean Squared Error,RMSE)[3]、平均绝对误差(Mean Absolute Error,MAE)计算公式[5]分别为
式中:ft为t时刻的实际功率;ht为t时刻的预测功率;P为风机的开机容量;N为所有样本数量.
由预测数据与原始风电功率数据的重合度以及测试数据集的误差可知:DNN和BiLSTM相对于LSTM来说能够更好地实现风电功率预测,但是由于原始数据特征过多,导致单独的神经网络并不能将特征完整提取出来,体现在预测结果上表现为产生时间滞后.
3 VMD分解
单一网络虽然能够预测风电功率,但其单步预测时的误差已经达到了14.6%,多步预测时误差会更高,很难满足国家风电功率预测精度的要求,因此,需要充分提取原始数据,以提高预测精度.
3.1 VMD分解原理
VMD是Dragomiretskiy等于2014年提出的一种新的分解方法[17],它结合了Wiener filtering、Hilbert变换和混频技术,能够更准确地分解波动信号,减少模态混合,VMD分解的目的在于将一个波动性较强的信号分解为K个规律性较明显的信号.假设每个模态分量uk(t)都有中心频率和有限带宽,则原始风电信号f(t)可以表示为K个IMF分量的和,并且所有模态分量的带宽之和最小.IMF表达式为
uk(t)=Ak(t)cos[φk(t)],
式中:φk(t)为uk(t)的相位;Ak(t)为uk(t)的瞬时幅值;k为第k个固有模态分量.
VMD分解过程:


3)依次更新uk、wk、λ[17]:
4)提高迭代次数并返回到步骤2),直到收敛.收敛准则[17]:
3.2 K值选取
VMD需要预设K值,对不同K值进行仿真得到各个分解结果及平均绝对百分比误差(Mean Absolute Percentage Error,MAPE).K取不同值时的MAPE见表3.评价指标MAPE[16]计算公式为

表3 K取不同值时的MAPETab.3 MAPE when K takes different values
MAPE在5%以内为可接受范围.由表3可知:MAPE开始低于5%时的分解数量为15个,由于分解次数过多会导致虚假分量的产生,因此,在进行最终的风电功率预测时,K取15,也就是最终风电功率序列被分解成15个IMF和的形式.将分解得到的15个IMF分量数据存入csv文件,以便在建立风电功率预测模型时调用.
3.3 VMD分解的优势
为了验证VMD的效果,分别对DNN、BiLSTM以及经过VMD分解的DNN、BiLSTM进行仿真.4种模型预测结果对比见图3,不同预测模型得到的RMSE和MAE见表4.由图3和表4可知:经过VMD分解,DNN和BiLSTM的误差有了明显降低,证明VMD对风电功率预测起到了重要作用.

表4 不同预测模型得到的RMSE和MAE
4 仿真分析
为了验证VMD-DNN-BiLSTM混合算法的优势,以我国某风电场为研究对象进行仿真分析.该风电场装机容量为58.5 MW,以其中1台风机第2季度的发电数据为依据进行算例分析.根据设计的风电功率预测模型,运用深度学习框架Keras进行仿真.
4.1 数据预处理
1)剔除异常数据;
2)对大于额定功率的数据用额定功率代替,小于0的数据用0代替;
3)将低于切入风速的数据置0,超出切出风速的数据整体剔除;
4)在数据缺失处,将其前后的数据取均值作为缺失数据.
4.2 仿真试验
为了评估DNN和BiLSTM在不同IMF分量的表现,对VMD分解得到的不同IMF分量分别建立DNN和BiLSTM滚动多步预测模型,其中,第1个IMF分量特征较少,第15个IMF分量特征较多.不同IMF分量误差见表5.
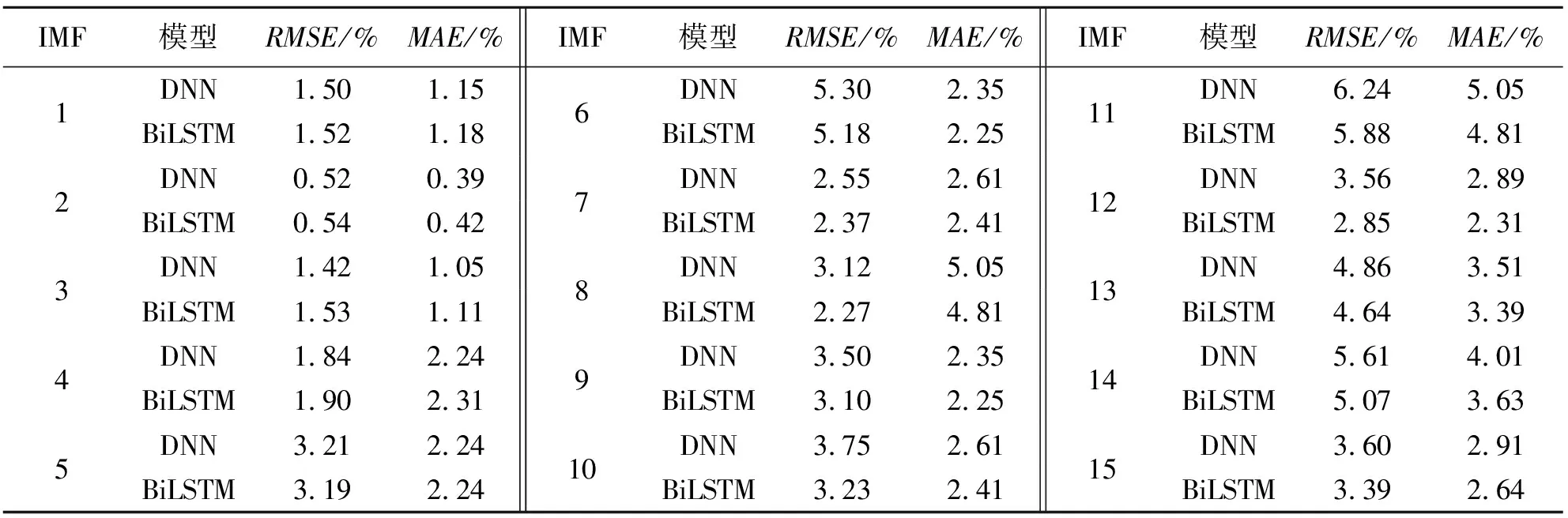
表5 DNN和BiLSTM在不同IMF分量的误差Tab.5 Error results of DNN and BiLSTM in different IMF components
由表5可知:DNN对分量IMF1~4预测效果更好,BiLSTM对分量IMF5~15预测效果更好.因此,为了更好地实现风电功率预测,采用将DNN和BiLSTM相结合的方式进行预测,对分量IMF1~4建立DNN滚动多步预测模型,对分量IMF5~15建立BiLSTM滚动多步预测模型.对于不同超参数,神经网络表现出的拟合能力与准确率都不尽相同,因此,要选择更优的超参数,如学习率选择10-3的准确率要优于10-2;第1层网络的神经元选择64个节点可以在充分提取特征的同时不影响训练速度,而选择128个节点会造成网络过拟合.为了评估VMD-DNN-BiLSTM预测模型的预测性能,将其与VMD-DNN及VMD-BiLSTM模型进行对比,3种模型单步预测结果见图4,多步预测误差结果见表6.
滚动多步预测虽然可以对风电功率进行长时间预测,但是会产生累积误差,时间越长,误差越大.由图4、表6可知:总体上,3种方法都能较好地预测风电功率.在滚动多步预测中,虽然VMD-DNN-BiLSTM在滚动单步时RMSE和MAE与VMD-DNN和VMD-BiLSTM方法相近,但随着滚动步数的增加,VMD-DNN-BiLSTM的优势得到了更好体现,RMSE和MAE都与另外两种方法逐渐拉开差距,表明VMD-DNN-BiLSTM相对于其他两种方法而言,能更好地拟合出风电功率序列.
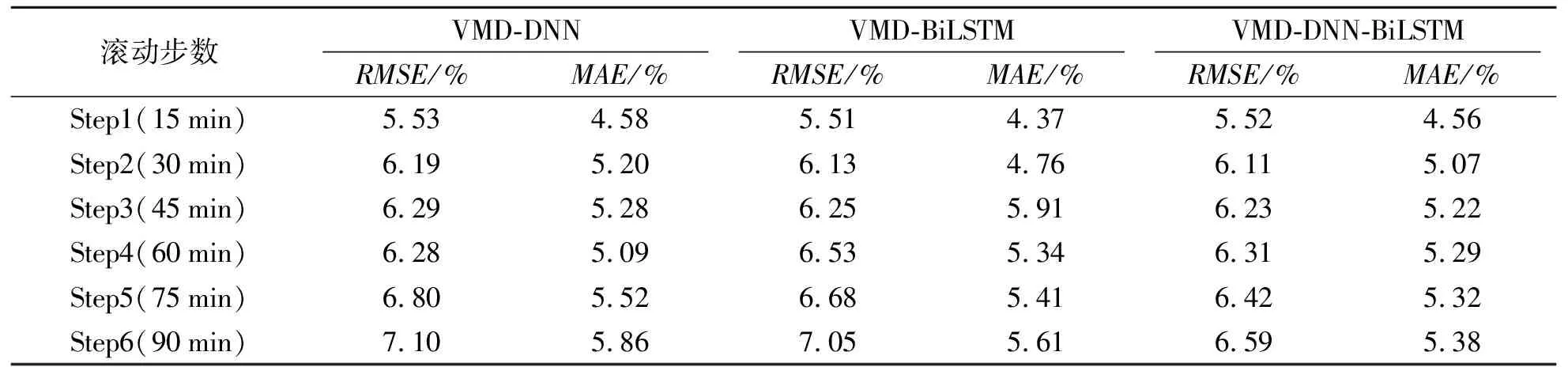
表6 3种模型多步预测误差Tab.6 Error results of multi-step prediction of three models
5 小 结
为了提高短期风电功率的预测精度,提出了1种基于VMD-DNN-BiLSTM的预测方法.结果表明,相对于直接对原始风电功率数据进行预测,本文方法可在一定程度上提高预测精度,并且可以解决预测滞后问题.
1)采用VMD分解风电功率数据,可以减少特征,降低后续的预测难度;同时,可以减少神经网络参数,降低网络深度,提高预测速度.
2)LSTM神经网络能够有效利用历史风电功率序列信息,通过优选参数提高模型预测性能,实现对风电功率的短期预测;BiLSTM相对于LSTM能从两个方向捕捉时间序列的特征信息,更充分地利用时间序列提高预测精度.
3)VMD和DNN与BiLSTM结合,能够有效利用各自优势,将直接对波动性较强的风电功率预测转化为对规律较为明显的数据进行预测,并在不同的IMF分量上使用不同的预测网络,进一步提高了整个预测模型的准确率.
现阶段的研究仅仅是围绕风电功率历史数据展开的,下一步将把风电场的物理气候信息也作为特征输入,建立更加完善的风电功率预测系统.
