专注度识别技术在教学监测中的应用研究
2020-12-28王鹏程王迪
王鹏程 王迪


摘要:建立规范化、科学化、制度化的教学质量监测评估体系是保证教育教学质量提高的重要前提之一。然而,当前教师主要采用课堂观察和提问的方式与学生交互,无疑会因个人经历不足等原因,造成信息传递与反馈的片面性与滞后性。本文利用人脸识别技术及专注度分析技术,通过整合MTCNN 模型、Insightface 模型、静态表情识别模型力,将其应用于高校教育领域,图解决如何客观精确地体现学生群体在课堂教学中的专注程度,为课堂教学质量评价体系提供有效参考依据,为弥补现存的教学评价问题提供了可能。
关键词:智慧课堂;人脸识别;专注度分析;MTCNN;Insightface
中图分类号: TP311 文献标识码:A
文章编号:1009-3044(2019)31-0038-05
Abstract: The establishment of standardized, scientific, and institutionalized teaching quality monitoring and evaluation system is one of the important preconditions to ensure the improvement of teaching quality. However, at present, teachers mainly use the way of classroom observation and questioning to interact with students, which will undoubtedly lead to the one-sided and lagging of information transmission and feedback due to the lack of personal energy and other reasons. This paper uses face recognition technology and focus analysis technology to integrate MTCNN model and insight face The model and static expression recognition model are applied to the field of higher education, to figure out how to objectively and accurately reflect the focus of students in classroom teaching, to provide an effective reference for the classroom teaching quality evaluation system, and to make up for the existing teaching evaluation problems.
Key words: Intelligent classroom; face recognition; Focus analysis; MTCNN; Insight face
1 概述
在高校傳统的教育中,教师通常采取大班授课的形式,由于上课学生的数量众多,又因教师教学进度的需要,往往不能保证每个学生的教学质量,高校学生也因此面临着疑难知识点无法解答,听课效率低下等问题。现如今,随着计算机技术的迅速发展,人工智能相关技术已经开始应用到各个领域。
现如今,人工智能已经成为人们常常谈论的话题,人们也将智慧教育从过去的翻转课堂等概念中抽离出来,重新定义智慧教育为将传统的教育优势和当今先进的技术高度融合的方案。构建一个充满数字化智能化的教育环境,最大限度地提高学生的学习效率,即学生在学习过程中所产生的数据信息,通过监控摄像头等信息采集设备及时掌握,并且能够清晰地实现学习数据的可视化展示。
本文所阐述的系统就是以人脸识别技术为基础,在已有学生证件照数据的基础上,利用教师监控摄像头对学生身份进行识别,并且对学生的上课专注度状态进行监测并且利用得到的数据进行分析,给出可视化的分析结果,这个系统的成功实现,一方面可以帮助高校学生实现个性化学习,另一方面可以帮助教师制定合适的教学计划,促进老师和学生课堂交互,实现真正的智慧教学。
2 技术背景
2.1MTCNN模型
MTCNN是中科院深圳研究院于2016年提出的一个深度卷积多任务的框架,如图1所示,这个框架利用了检测和对准之间固有的关系来增强他们的性能,在预测人脸及脸部标记点的时候,通过 3 个 CNN 级联的方式对任务进行从粗到精的处理。
如图输入待检测图片,第一步使用的P-Net是由一个全卷积网络,1个池化层和4层卷积层构成,它的作用是用来生成候选窗和边框回归向量。使用Bounding box regression的方法来校正这些候选窗,然后使用非极大值抑制合并高度重叠的候选框。由于其使用的是全卷积网络,所以在测试的时候输入是任意大小的图片,输出为N个边界框的4个坐标信息和 score,如图2(b)。
第二步使用R-Net改善候选窗,它由2个池化层和3层卷积层以及1层全连接层构成,将通过P-Net的候选窗输入R-Net中,边界框的大小都是24×24×3,这些都可以通过缩放得到,P-Net的功能是拒绝掉大部分false的窗口后,继续使用Boundingboxregression和NMS合并,然后输出精度更高的人脸框,如图2(c)。第三步使用O-Net输出最终的人脸框和特征点位置,O-Net由3个池化层和4层卷积层以及1层全连接层构成,和第二步类似,但是不同的是生成5个特征点位置。通过MTCNN模型,可以得到人脸的双眼,鼻子以及嘴巴的五个关键点的坐标以及人脸边框的坐标,其中截取到的人脸图片可以供h后续人脸识别使用,如图2(d)。
2.2 Insightface模型
2018年由英国帝国理工大学邓建康团队提出的Insightface模型别的模型不同,在损失函数上选择ArcFace提出的一种新的用于人脸识别的损失函数:dditiveangularmarginloss函数,其使用角边距最大化类间距离、最小化类内距离。该模型使用的CNN网络为改进的ResNet-100网络结构,使得其能够更加适合学习人脸特征。详细步骤如图3所示。
第一步,首先输入的图片是3×224×224,也就是3个通道,图片尺寸为224×224,然后进入第一个卷积层,卷积核大小为7*7,卷积核个数为64,步长为2,padding为3,输出向下取整得到112,所以输出是64×112×112,maxpool层会改变维度,但是不会影响个数。到了实线框中,每一个实线框包含了3个Bottleneck,其中每个Bottleneck里面包含了一个ConvBlock和一个IdentityBlock,在ConvBlock中,总体的思路是先通过1×1的卷积对特征图像进行降维,做一次3×3的卷积操作,最后再通过1×1卷积恢复维度,后面跟着BN和ReLU层,虚线处用256个1×1的卷积网络,将maxpool的输出降维到255×56×56。在IdentityBlock中,不经过卷积网络降维,直接将输入加到最后的1×1卷积输出上,经过后面的Block,经过平均池化和全连接,用softmax实现回归。
第二步,利用L2实现特征和权重归一化,将图像的特征映射到一个关于特征的超球面上,球的半径为单位长度。
第三步,再去优化这些特征,在这里提出了一个新的损失函数,arcface损失函数,其原理利用的是角度距离比余弦距离在对角度的影响更加直接,由于几何上有恒定的线性角度,ArcFace直接在角度空间θ中最大化分类界限。由于其提出的加性角度间隔惩罚与测地线距离间隔惩罚在归一化的超球面上相等。
2.3 静态表情识别模型
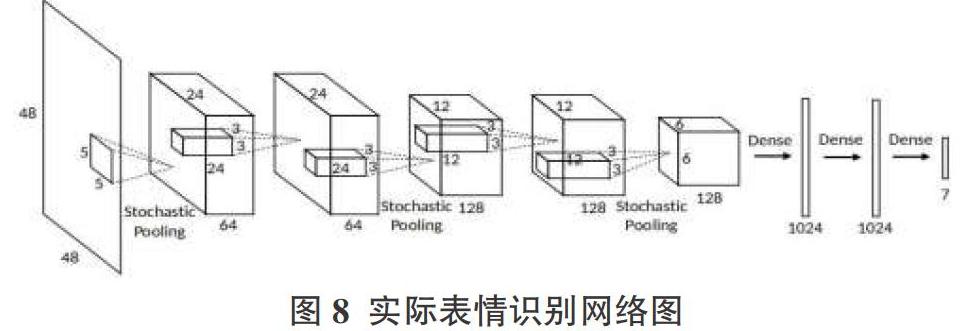
本文模型主要采用基于图像的静态面部表情识别网络,模型的基本结构如图4所示。
模型包含了五个卷积层,三个随机池层和三个完全连接层,其级联了三个state-of-the-art的人脸检测算法,从而保证人脸检测的正确性。其中卷积层的参数只允许在完全连接的图层上更新参数。此处采用自适应地为每个网络分配不同的权重,即要学习集合权重w。采用独立地训练多个不同初始化的CNN并输出他们的训练响应。在加权的集合响应上定义了损失,其中w优化以最小化这种损失,在测试中,学习的w也被用来计算整体的测试响应,架构最后有P个Dense(7),这P个扰动样本的输出结果的平均投票,作为该图像的预测值。在本模型中,为了能够一定程度上做到数据增强,图像尺寸归一化,直方图均衡化,去均值除方差。样本生成公式如下:
[x'y'=c00ccos(θ)sin(θ)-sin(θ)cos(θ)1s2s11x-t1'y-t2]
其中θ是从三个不同值随机采样的旋转角度:{-π/18,0,π/18}。s1和s2是沿着x和y方向的偏斜参数,并且都是从{-0.1,0,0.1}随机采样的,c是随机尺度参数。定义为c=47/(47-δ),其中δ是[0,4]上随机采样的整数。
3 专注度识别的实现
3.1 课堂环境下学生人脸提取
本模型采用的视频都是用录影机在课堂学生正前方录制,分辨率为1980*1080,由于MTCNN的效果非常好,故在学生人脸提取部分主要还是利用MTCNN模型,它的实际效果已经在各大公开的数据集中得到证明,由于没有自己的数据集,所以训练模型的过程还是跟着官网文档训练的过程,在训练MTCNN模型的时候,使用wider和celeba两个公开的数据库,其中wider提供人脸检测数据,在大图上標注了人脸框,groundtruth的坐标信息,celeba提供了5个landmark点的数据,图像的预处理使用opencv提供的图像处理工具,在训练时,将人脸识别损失函数、框回归函数、关键点损失函数按照不同权重联合起来,利用以下的函数,将欧氏距离最小化。
[minNi=1j∈{det,box,landmark}?jβjiLjiβji∈{0,1}P-Net R-Net(?det=1,?bax=0.5,?landmark=0.5)O-Net(?det=1,?bax=0.5,?landmark=1)]
在训练的时候利用Wider_face中9000张标记人脸做检测任务的训练,利用CelebA中包含的5000张LFW数据集做关键点的训练,训练集分为四种:负样本,正样本,部分样本,关键点样本,三个样本的比例为3:1:1:2。对于三个网络,其提取过程类似,本模型对每个人脸输出160*160大小的图像。
在模型训练结束后,使用模型应用于课堂环境下,通过对采集的1980*1080分辨率视频帧的分析,可以得到学生的面部截图坐标以及五个关键点坐标。其中人脸框提取如图5所示,在人脸关键点可见的情况下,面部检测率非常高。
人脸关键点标注的检测会因为低头、遮挡等因素而失效。与此同时,需要注意的是,人眼和鼻子关键点的位置关系也可以作为一个判断上课状态的重要依据,这个关系将应用于本作品的疑惑度分析模块。
利用本模块,可以输出160*160像素的人脸截取图片提供给人脸识别模块提取图片特征,如图6所示。
3.2课堂环境下学生人脸识别
在课堂人脸识别中,在比较了Facenet模型Insightface模型对于单个人身份匹配的实际效果,可以观察到Facenet在课堂环境下由于单张人脸像素太低,人脸身份匹配率较低,不能满足本系统所需功能的要求。但是Insightface模型的实际效果很好,而且计算代价更低,所以采用Insightface模型。本模型的实现主要在mxnet框架下进行,数据集使用VGG2和MS-Celeb-1M,在去除噪声数据后进行训练,验证集则使用LFW。
本模型使用的网络结构是ResNet100,首先需要申明图片尺寸为MTCNN输出的160*160,这里需要使用tensorflow的resize工具调整图片的大小让它适应网络的输入,利用封装好的get_model(ctx,image_size,model_str,layer)函数将截取的低像素人脸给Insightface提取人脸特征。
在初始化FaceImageIter数据迭代器后初始化各类迭代用的参数,如batch_size。在初始化评价函数上使用AccMetric,之后初始化神经网络,定义SGD优化器,在得到图像特征的函数中,根据ResNet50的结构构建主体网络计算图,输入112×112×3的图像,输出是embedding为512维度,然后初始化类别空间,计算CosFaceLoss,最后将fc7和真值放入传统Softmax中输出得到结果。
在修正的ResNet中传入的主要参数为网络层数:num_layers=50,卷积层的Unit:filter_list=[64,64,128,256,512],没有1×1的filter:bottle_neck=False,网络有四个部分:num_stages=4,四个部分分别是:[3,4,14,3]。整个网络分为四个步骤,分别为i=0,1,2,3。i=0的时候:body=上述网络结构[body,filter=64,步长(2,2),dim_match=False],经历3个卷积层。j进行0,1两次循环,两次进行body=上述网络结构[body,filter=64,步长(1,1),dim_match=True],经历4个卷积层一共经历7个卷积层。i=1的时候,body=上述网络结构[body,filter=128,步长(2,2),dim_match=False],经历3个卷积层。j进行0,1,2三次循环,这三次网络结构[body,filter=128,步长(1,1),dim_match=True],经历6个卷积层,一共经历9个卷积层。i=2的时候:body=上述网络结构[body,filter=256,步长(2,2),dim_match=False],经历3个卷积层,j进行0,1,2,一直到13次循环。这个网络结构一共经历29个卷积层,i=3的时候,上述网络结构[body,filter=512,步长(2,2),dim_match=False],经历3个卷积层,j进行0,1两个循环,两次进行body=上述网络结构[body,filter=512,步长(1,1),dim_match=True],经历4个卷积层,整个过程总共经历卷积层7+9+29+7=52个卷积层,再加上初始化的卷积层,一共有53个。本模型经过归一化后特征尺度为64,最后输出特征层的维度为512维。最后根据特征向量的距离进行身份的判断。在人脸匹配时,身份数据库中的原照片每张大小为1M左右。
如图7所示,在实际测试时,比较图片特征向量在超球面的角度差异,最小化类内距离,最大化类间距离,定义findNear函数,在数据库中寻找和低分辨率人脸图片特征向量最相似的向量特征,可以看到在人脸3个以上关键点能够识别和遮挡不超过70%的情况下,只要检测出人脸,就能够匹配出数据库中学生身份,在1000帧有3-5帧出现误差。
def findNear(feature, f, threshold,Name):
dist_list = []# 遍历特征库
for feature_unit in feature:
dist = np.sum(np.square(feature_unit - f))
# dist_list 作用是将所有距离都保存下来,以便获得最小距离
dist_list.append(dist)#寻找到最小距离
minDist = np.min(dist_list)#如果最小距离小于等于阈值
if minDist<= threshold:#求出最小距离对应的索引
minIdx = np.argmin(dist_list)# 找到姓名
return Name[minIdx]
else:
return 'none'
3.3专注度分析模块
本文的专注度识别模块主要在静态表情识别模型的基础上引入人眼张合度的机制进行状态评判。
3.3.1简单表情识别
在实际测试上表情分类CNN使用模型图8,其采用数据增强和投票模式使得网络能够自动的决定级联CNN的权重分配問题。损失函数为softmaxWithLoss,计算的时候一个样本会与其生成的样本loss一起计算,整个网络用FER数据库进行预训练,当loss突然增加25%或者连续5次观察loss发现loss上升,则手动的减小学习率,最小的学习率设置为0.0001。相比较简单的加权投票平均的思想,在这里使用学习策略来决定网络的具体权重。模型预训练上使用FER2013数据库,测试集则使用SFEW数据库给出的静态图像,其中为了减弱背景复杂度带来的影响,级联了JDA、DCNN、MOT三个人脸检测算法。在数据预处理上为了去除样本间的无关噪声,并能够一定程度的做到数据增强,图像尺寸归一化(48x48)。
其中,输入的图片大小为160*160,通过此模型可以得到高兴(happiness)、正常(neutral)、惊讶(surprise)、奇怪(odd)、厌恶(disgust)和悲伤(sadness)六种表情结果。
x1,y1,x2,y2=int(bbox_unit[0]),int(bbox_unit[1]),int(bbox_unit[2]),int(bbox_unit[3])
gray_face = gray_image[y1:y2, x1:x2]
try:
gray_face = cv2.resize(gray_face, (emotion_target_size))
except:
continue
gray_face = preprocess_input(gray_face, True)
gray_face = np.expand_dims(gray_face, 0)
gray_face = np.expand_dims(gray_face, -1)
emotion_prediction = emotion_classifier.predict(gray_face)
emotion_probability = np.max(emotion_prediction)
emotion_label_arg = np.argmax(emotion_prediction)
emotion_text = emotion_labels[emotion_label_arg]
emotion_window.append(emotion_text)
其中x1,y1,x2,y2分别为人脸框四个点坐标,因为对表情的标签进行了修改,将6个表情分为3类,分别为neutral、no_confused、confused,并且将此作为一个课堂状态的初步判断,将表情结果视频化分析结果如图9所示。
3.2 专注度评价机制
在课堂条件下,可以观察到学生眼睛的张合度和学生的上课状态密切相关,如果仅仅简单地通过基本表情的评判作为学生专注度分析的结果,有效性较低,因此本文决定将人眼张合度纳入学生疑惑度状态评价之中。由于人眼是呈现椭圆状,为了图形处理方便将眼睛面积视为长方形,张合度考虑为人眼长方形中宽度和长度的比值。
其中高度与宽度的比值越大则表示学生越专注,比值越小表示学生专注度越低。但是实际训练中,因为课堂学生较为密集,单张人脸分辨率较低,人眼面积更小,故考虑使用双眼和鼻子三个关键点的角度关系来代替眼睛张合度评价。其中双眼和鼻子的三点坐标简化如图10所示,本文主要考虑角度C的变化情况。
经过数据处理发现得知,鼻子的位置相对固定,在监控摄像头位置不变的情况下,学生抬头,低头,侧身等动作都会影响到实际截取人脸中双眼和鼻子的角度关系,若低头,则监控摄像截取人眼面积较小,鼻子位置相对较高,则夹角C相对较大。若学生抬头,监控摄像截取人眼面积仍然较小,鼻子位置相对不变,夹角C也会变大。若学生侧脸,则某一只眼睛和鼻子的距离就会变小,从而导致角度C变大。采取三点检测法可以极大地降低计算量的同时提升系统疑惑度分析的准确度。
在角度C的计算上,根据三角形的定义,可以得到平面上三点的坐标点,假设这三个坐标点如图所示为A(a,b),B(c,d),C(e,f),其长度分别为a,b,c,由余弦定理可以得到:
cosC=(a2+b2-c2)/(2*a*b)
带入图中已有的坐标,可以得到:
[cosC=(x3-x1,y3-y1)*(x2-x3,y2-y3)(x3-x1,y3-y1)*(x2-x3,y2-y3)]
在这里通过已有数据的分析,将角度C的阈值设置为66度最适合,则cosC的阈值为0.41,故若通过MTCNN得出的人眼以及鼻子的三個关键点坐标计算的角度C余弦值大于0.41则可判定为专注状态,否则为不专注状态。实际效果如图11所示。正脸状态下相对于低头和侧脸状态角度两眼和鼻子关键点角度位置更正,处于角度66度评价范围之间。
最后本模块在最基本的静态表情判断上结合专注度评判准则进行修正,若情绪判断为疑惑状态并且脸部状态眼鼻关键点角度正常,则修正为正常状态,若眼鼻关键点异常,则仍然为疑惑。若情绪判断为正常且眼鼻关键点角度正常,则为专注,否则为正常态。若情绪判断为正常态,则保持不变,最终的结果给出正常、专注、困惑三种状态。实际测试结果如图12所示。
4 结束语
本文通过整合 MTCNN 模型、Insightface模型、静态表情识别模型初步实现了专注度的识别分析。通过在静态表情识别模型的基础上引入人眼张合度的机制,能够相对稳定地判断学生的专注状态。
但是,在课堂的复杂环境下,学生由于遮挡、光线、侧身等原因造成身份难以识别,学生人脸状态分析评判指标还没有统一标准的问题将是今后的研究方向。
参考文献:
[1] Zhang K P,Zhang Z P,Li Z F,et al.Joint face detection and alignment usingmultitaskcascaded convolutional networks[J].IEEE Signal Processing Letters,2016,23(10):1499-1503.
[2] Zhu Z Y,Luo P,Wang X G,et al.Recover canonical-view faces in the wild with deep neural networks[EB/OL].2014:arXiv:1404.3543[cs.CV].https://arxiv.org/abs/1404.3543
[3] Karen Simonyan,Andrew Zisserman.Very Deep Convolutional Networks f or Large-Scale Image Recognition[EB/OL].2015,https://arxiv.org/abs/1 502.03167.
[4] Y.Taigman,M.Yang,M.Ranzato,and L.Wolf. Deepface:Closing the gap to human-level performance in face verification.In IEEE Conf on CVPR,20 14.1,2,5,7,8,9.
[5] I.Bayer,X.He,B.Kanagal,and S.Rendle.A generic coordinate descent f ramework for learning from implicit feedback.In www,2017.
[6] T.Chen,X.He,and M.-Y.Kan.Context-aware image tweet modelling and r ecommendation.In MM,2016:1018-1027.
[7] Wang H,Wang N Y,Yeung D Y.Collaborative deep learning for recommendersystems[EB/OL].2014:arXiv:1409.2944[cs.LG].https://arxiv.org/abs/1409.2944
[8] The Third Emotion Recognition in the Wild (EmotiW)2015 Grand challenge. http://cs.anu.edu.au/few/emotiw2015.html
[9] Dhall A,Goecke R,LuceyS,et al.Collecting large,richly annotated facial-expression databases from movies[J].IEEE MultiMedia,2012,19(3):34-41.
[10] Du S, Tao Y,Martinez A M.Compound Facial Expressions of Emotion[J]. Proceedings of the National Academy of Sciences of the United States of America,2014(111):1454-1462.
【通聯编辑:唐一东】