轨迹数据预处理方法综述
2020-12-28蔡郑贾利娟孙扬清
蔡郑 贾利娟 孙扬清

摘要:随着大数据技术的发展和移动终端设备的普及,大量轨迹数据得以被采集并存储到互联网上。现今较易获得的轨迹数据使其越来越受到研究者的关注,由于这些原始的轨迹数据受到采样频率、采样精度以及法律法规的影响,而通常不能直接应用到各类挖掘算法中,因此通常需要先进行预处理。该文对轨迹数据的预处理进行了综述。首先,介绍了轨迹数据的概念和用途;其次,总结了轨迹数据的常见特征;再次,归纳了常用的轨迹数据预处理方式;最后,论述了轨迹数据处理面临的挑战并对未来研究方法进行了展望。
关键词: 轨迹数据;预处理;滤波;geohash;停留点
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)31-0009-04
Abstract:With the development of big data technology and the popularization of mobile terminal devices, a large amount of trajectory data can be collected and uploaded to the internet.In recent years,more and more scholars pay attention to the trajectory data easy to be obtained. These original trajectory data affected by sampling frequency, sampling accuracy and laws and regulations, can not be directly applied to various mining algorithms, so, pretreatment is usually needed first. This paper reviews trajectory data pretreatment. Firstly, the concept and application of trajectory data are introduced. Secondly, the common characteristics of trajectory data are summarized. Thirdly, the common track data pretreatment methods are summarized. Finally, the challenges of trajectory data pretreatment are discussed and the future research methods are prospected.
Key words:trajectory data;pretreatment;filter;geohash;stopping point
近些年来,随着移动终端设备的普及、社交网络的兴起以及4G技术的广泛运用,轨迹数据被大量采集并存储到互联网上。这些轨迹数据包含但不限于:社交网络打卡信息[1]、手机信令数据[2]、打车信息[3]、交通卡口过车信息[4]、出租车定位信息[5]、公交车实时数据[6]、动物迁移数据等。这些轨迹数据的应用领域十分广泛,包括且不限于:智慧城市[7]、交通路网优化、社交推荐、生活模式发掘、公安破案、套牌检测[8]等方面。轨迹数据的分析与挖掘已经成为一个热门的研究方向。
但是,随着越来越多的轨迹数据被采集上来,人们发现不仅不同类型的轨迹数据之间数据格式和采样频率不统一,并且相同类型的轨迹数据也存在采样频率不稳定、采样精度不稳定、大量的噪音点和异常点等问题。例如,社交网络打卡数据[1]通常使用地点编号来代表位置信息,而出租车数据和信令数据则使用经纬度来表示位置信息;城市地形因为高楼的阻挡,会存在位置漂移而产生的噪音点;出于省电目的,一些定位设备在夜间会降低采样频率,导致白天和夜间的采样频率不同。
这些问题不仅导致相同的挖掘模型不能直接应用到不同类型的轨迹数据上,而且对于相同类型的轨迹数据也需要人工设置不同的参数来进行预处理。
针对这些情况,本文从轨迹数据的预处理入手,重点介绍了各种不同类型的轨迹数据以及常用的预处理方法,对轨迹数据的预处理进行相应的总结和综述性阐述。在文末结合目前的最新研究进展,归纳出通用的预处理流程和方案。
本文第2节对轨迹数据进行概要性描述;第3节对已有的轨迹数据预处理方法进行了系统性介绍,并给出了轨迹数据预处理的通用方案;第4节总结全文,展望了未来轨迹数据预处理需要解决的问题以及热点研究方向。
1轨迹数据概述
轨迹数据是通过对移动对象的轨迹进行采样来获取的,每条轨迹数据通常由时间戳、位置信息、采样对象编号三部分组成,具有明显的时序特征。轨迹数据的来源和格式多种多样:GPS定位设备会定时上传经纬度信息,用户使用社交App时会上传打卡信息,车辆通过交通卡口时会产生实时过车信息等,这些信息都是轨迹数据。
一些轨迹数据会使用经纬度来表示位置信息,例如Gowalla社交网络打卡数据[9]和北京出租车数据[5]。以Gowalla社交网络打卡数据为例,Gowalla是一个基于位置的社交网站, 用户可以在网站上通过签到和朋友们分享自己的位置,其每条签到记录包含以下5 个字段:
其中USER_ID对应着采样对象编号,CHECKIN_TIME字段对应着采样时間,LONGITUDE、LATITUDE和PLACE_ID字段则表示位置信息。
北京出租车数据是微软研发中心公布的8900辆出租车1周的时空轨迹数据,其每条数据记录包含了以下字段:
其中PID对应着采样对象编号,TIME字段对应着采样时间,LONGITUDE和LATITUDE字段则表示位置信息。
但是出于隐私保护、法律法规以及数据脱敏的要求,许多时空轨迹数据并不是使用经纬度而是使用位置编号来表示位置信息,例如,一些社交网络签到信息是用兴趣点的编号来表示位置信息,一些手机信令数据直接使用手机连接的基站号来代表位置,有些数据甚至直接使用地点名称来代表位置信息。这类轨迹数据的位置信息通常是离散的,无法直接计算轨迹点之间的距离,无法直接应用到各类挖掘算法中。以城市交通卡口数据[4]为例,其数据格式通常为:
其中CARD对应着采样对象编号,TIME字段对应着采样时间,PLACE_ID字段则表示位置信息。
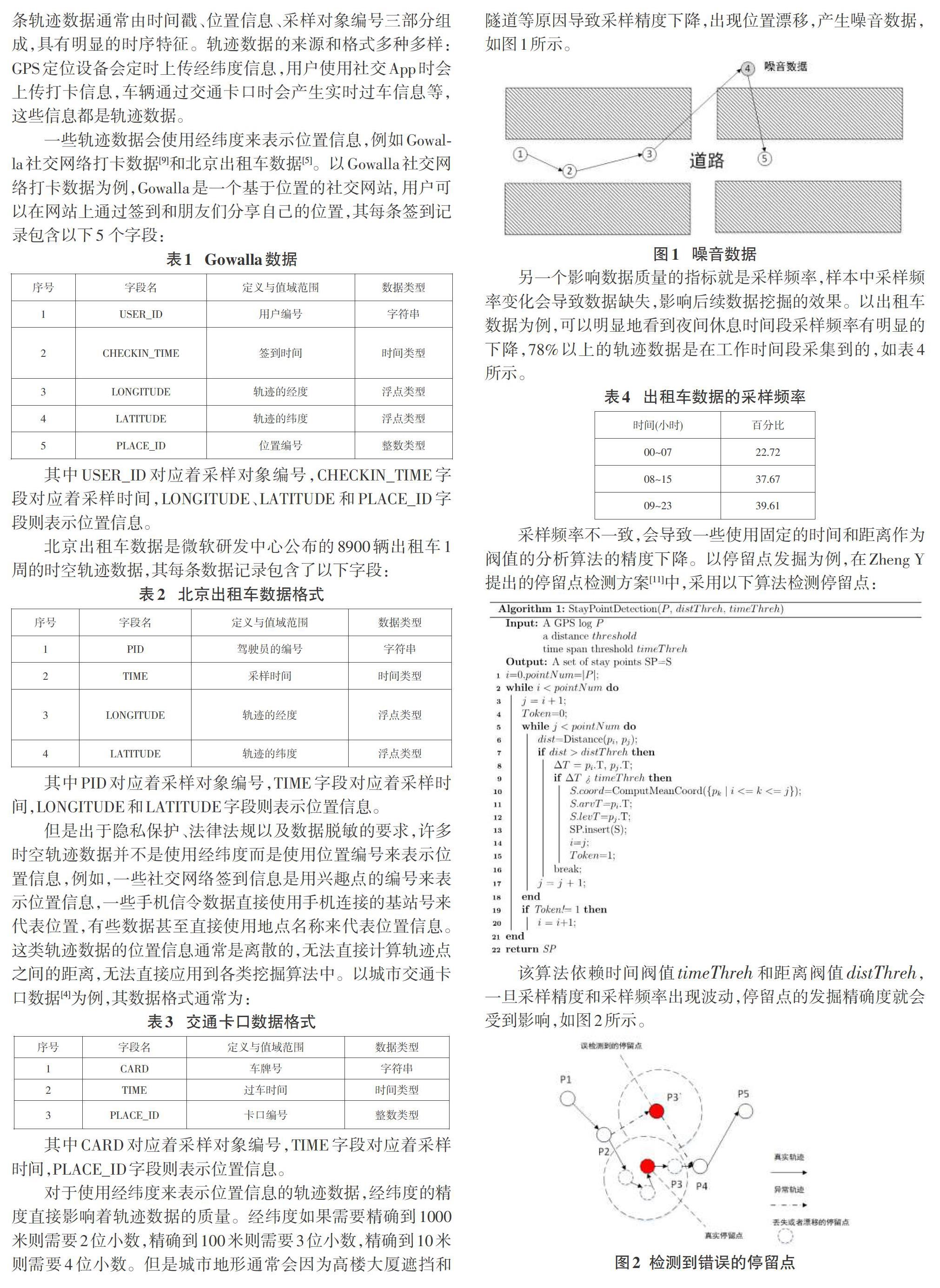
对于使用经纬度来表示位置信息的轨迹数据,经纬度的精度直接影响着轨迹数据的质量。经纬度如果需要精确到1000米则需要2位小数,精确到100米则需要3位小数,精确到10米则需要4位小数。但是城市地形通常会因为高楼大厦遮挡和隧道等原因导致采样精度下降,出现位置漂移,产生噪音数据,如图1所示。
另一个影响数据质量的指标就是采样频率,样本中采样频率变化会导致数据缺失,影响后续数据挖掘的效果。以出租车数据为例,可以明显地看到夜间休息时间段采样频率有明显的下降,78%以上的轨迹数据是在工作时间段采集到的,如表4所示。
采样频率不一致,會导致一些使用固定的时间和距离作为阀值的分析算法的精度下降。以停留点发掘为例,在Zheng Y提出的停留点检测方案[11]中,采用以下算法检测停留点:
该算法依赖时间阀值[timeThreh]和距离阀值[distThreh],一旦采样精度和采样频率出现波动,停留点的发掘精确度就会受到影响,如图2所示。
可以看到,采样频率过低会导致轨迹点的丢失,采样精度降低会导致轨迹点漂移,最终导致检测出挖掘出的停留点不准确。
轨迹数据分析时还有一个需要重点考虑的因素就是计算量,使用经纬度表示位置信息的轨迹数据在计算轨迹点之间的距离时通常使用haversine公式[10]进行计算,其具体公式为:
这种计算距离的方式在大批量计算轨迹点之间的距离时非常耗费资源,计算10万个点之间的距离时就至少需要10毫秒,当数量级达到100万时,就需要150毫秒以上,尤其是在需要从海量的轨迹数据中找出相似轨迹点的场景下,其性能是不可接受的。
可见过滤因采样频率和采样精度导致的噪音数据,寻找降低计算距离时的计算量是轨迹数据预处理的主要目标之一。对于使用编号来表示位置信息的轨迹数据,其轨迹点之间距离的计算也是轨迹数据预处理时需要考虑的。
2轨迹数据的预处理
从第2节可以知道,轨迹数据通常解决以下三个问题:1)过滤因采样频率和采样精度产生的噪音数据;2)降低计算距离时的计算量;3)解决无法计算距离的问题。
针对噪音点,通常可以采用均值滤波、中值滤波、卡尔曼滤波来进行移除。均值滤波的具体流程为:对于每个轨迹点[pn],如果其周围的轨迹点数量小于阀值,则将[pn]视为噪音点,并使用[p1~pn-1]的均值来代替[pn];中值滤波的具体流程则为:对于每个轨迹点[pn],如果其周围的轨迹点数量小于阀值,则将[pn]视为噪音点,并使用[p1~pn-1]的中值来代替[pn];卡尔曼滤波因为会考虑更多的状态向量,例如速度,所以相对中值和均值滤波来说会在处理连续噪音点时具有一定的优势。文献[12-13]中详细介绍了如何使用中值滤波和均值滤波对轨迹数据进行预处理;文献[14-15]中不仅使用卡尔曼滤波对轨迹中的噪音数据进行了检测和抑制,还详细介绍了其在轨迹数据处理中的应用。
针对使用haversine公式[10]计算轨迹点之间距离时计算量过大的问题,目前通用的做法是将经纬度映射为geohash[16-18],当轨迹点的geohash相同时,可以认为轨迹点之间的距离是接近的,如图3所示,利用geohash找出相似的轨迹。
其原理是将经度和纬度转换为固定长度的二进制并合并在一起后,再通过base32编码转换为geohash编码,geohash编码越长精度越高。当两个经纬度的geohash编码相同时,它们的位置就是相近的。文献[19]通过将轨迹转换为geohash,实现了对出租汽车轨迹的存储和分析;文献[20]通过geohash,实现了地图路线规划和行程匹配算法;文献[21]则通过geohash实现了船舶入区检测告警方法。这些论文都通过geohash编码的方式,减少甚至避免了直接计算轨迹点之间的距离。
但是使用geohash编码又会引入边界问题[22-24],如图3所示。针对这种情况,在计算两个轨迹点的距离时不仅要使用轨迹点之间的geohash编码进行比较,还需要利用起轨迹点周围8个区域的geohash编码,只有待比较的轨迹点落在相同或者相邻的geohash区域时才使用haversine公式[10]计算其与当前轨迹点之间的实际距离。
对于那些使用地点编号来表示位置信息的轨迹点,就无法使用havsine[10]公式以及geohash编码的方法计算这些轨迹点之间的距离。针对这种情况,研究人员则直接利用轨迹点之间的连通性,参考自然语言处理的思路,引入表示学习的方法,将这些位置编号映射到低维的致密嵌入向量中[25-30]。
Perozzi[30]发现如果对轨迹点进行随机游走,顶点出现次数的冥律分布与自然语言处理中单词出现次数的冥律分布一致且遵循zipfs定律[30],可以使用表示学习的思想,根据轨迹点之间的连通性,使用轨迹点的上下文来表示该轨迹点。在这种情况下,连通次数越多的轨迹点之间的嵌入向量越相似,噪音点因与正常轨迹点的连通次数较少会导致他们之间的距离在训练过程中逐渐变大,很容易被区分并过滤掉,其具体效果如图5和图6所示。
Perozzi[30]通过表示学习,在海量的社交网络打卡信息中得到了轨迹点的嵌入向量,并对这些轨迹点进行了多标签分类,分类的效果与实际数据保持了一致;文献[31]在预测用户的下一个位置以及位置的下一时刻流量时,通过表示学习将轨迹点映射为嵌入向量,显著地提升了预测准确率;文献[32]通过表示学习对数据进行了预处理,有效地从轨迹数据中挖掘出了学生个体行为特征。
综合以上给出的预处理方法,轨迹数据的预处理流程可以归纳为图7。
3总结与展望
大数据处理技术的发展与移动互联设备的普及使得轨迹数据处理获得了越来越多的研究人员的青睐。本文介绍了常见的轨迹数据的类型,列举了轨迹数据常用的预处理方法。重点阐述了轨迹数据预处理是为了解决哪些问题,并归纳出了轨迹数据预处理的总体流程。本文一方面,旨在让广大研究人员快速了解轨迹数据;另一方面,旨在为噪音点处理、降低运算量以及无经纬度时轨迹数据的预处理提供研究思路。
随着大数据时代的到来,追求更快的轨迹数据预处理会是未来的重点。另外,随着人工智能的发展,如何将轨迹数据预处理的工作通过机器自动化完成也是未来关注的重点方向。
参考文献:
[1] 李敏,王晓聪,张军,等.基于位置的社交网络用户签到及相关行为研究[J].计算机科学,2013,40(10):72-76.
[2] 董路熙,贾梅杰,刘小明,等.基于手机信令数据的居民工作日出行链判别方法[J].桂林理工大学学报,2019,39(4):958-966.
[3] 胡蓓蓓,孔亚文,赵丽欣,等.基于滴滴轨迹数据的城市出租车服务利润率对比研究[J].统计与信息论坛,2018,33(5):107-113.
[4] 顾人舒.交通卡口车辆检测与自动识别技术研究[D].南京:南京大学,2014.
[5] 齐观德,潘遥,李石坚,等.基于出租车轨迹数据挖掘的乘客候车时间预测[J].软件学报, 2013,24(S2):14-23.
[6] 马连韬,王亚沙,彭广举,等.基于公交车轨迹数据的道路GPS环境友好性评估[J].计算机研究与发展,2016,53(12):2694-2707.
[7] 李德仁,姚远,邵振峰.智慧城市中的大数据[J].武汉大学学报·信息科学版,2014,39(6):631-640.
[8] 卢晓春,周欣,蒋欣荣,等.基于網格化监控的套牌车检测系统[J].计算机应用,2009,29(10):2847-2848.
[9] 周永.基于签到数据的用户行为轨迹相似度分析[D].成都:西华大学,2016.
[10]Robusto C C. Classroom Notes: The Cosine-Haversine Formula[J].Amer.math.monthly, 1957(1):38-40.
[11] Ye Y, Zheng Y, Chen Y, et al. Mining Individual Life Pattern Based on Location History[C]// Tenth International Conference on Mobile Data Management: Systems. IEEE, 2009.
[12] 赵倩倩.基于目标特征点跟踪与聚类的车辆检测算法研究[D].西安:长安大学,2015.
[13]吕亚辉,严雨灵. Trajectory planning of industrial robot based on gesture trajectory[J].智能计算机与应用, 2019, 009(001):122-126.
[14] 孙娟,程艳群,吴洪昊.基于卡尔曼滤波的GPS轨迹跟踪[J].黑龙江科技信息,2017(1):150.
[15] 黎蓉.卡尔曼滤波在组合导航数据处理中的应用[J].电子测量技术,2017,40(3):158-162.
[16] ZoranBalki?, Damir ?o?tari?, Horvat G .GeoHash and UUID Identifier for Multi-Agent Systems[M]//Agent and Multi-Agent Systems. Technologies and Applications. Springer Berlin Heidelberg, 2012.
[17] Miller F P, Vandome A F, Mcbrewster J. Geohash[M]. Alphascript Publishing, 2010.
[18] Gutierrez J M, Jensen M, Henius M, et al. Smart Waste Collection System Based on Location Intelligence[J]. Procedia Computer Science, 2015: 120-127.
[19] 王翔,杨国东.基于Geohash的出租车汽车轨迹的存储与应用研究[J].科技资讯,2015,13(35):69-71.
[20] 钟克华,游东宝,苏炳辉.一种基于Geohash方法和地图路线规划的行程匹配算法[J].汽车电器,2019(8):16-18.
[21] 赵士龙,田伟,余佥.基于GeoHash的船舶入区检测告警方法研究[J].电脑编程技巧与维护,2020(4):151-153.
[22] Liu J, Li H, Gao Y, et al. A geohash-based index for spatial data management in distributed memory[C]. international conference on geoinformatics, 2014:1-4.
[23] Verma J P V , Mankad S H , Garg S . GeoHashtag based mobility detection and prediction for traffic management[J]. SN Applied Sciences, 2020, 2(8).
[24] Suwardi I S, Dharma D, Dicky P, et al. Geohash index based spatial data model for corporate[C]// The 5th International Conference on Electrical Engineering and Informatics. IEEE, 2015.
[25] Yang J, Eickhoff C. Unsupervised Spatio-Temporal Embeddings for User and Location Modelling[J]. arXiv: Information Retrieval, 2017.
[26] Hu B, Jamali M, Ester M. Spatio-Temporal Topic Modeling in Mobile Social Media for Location Recommendation[C]// IEEE International Conference on Data Mining. IEEE, 2014.
[27] Daokun Z, Jie Y, Xingquan Z, et al. Network Representation Learning: A Survey[J]. IEEE Transactions on Big Data, 2017(99):1-1.
[28] Crivellari A, Beinat E. From Motion Activity to Geo-Embeddings: Generating and Exploring Vector Representations of Locations, Traces and Visitors through Large-Scale Mobility Data[J]. International Journal of Geo-Information, 2019,8(3).
[29] Xu Q, Chen H, Zhi H, et al. Algorithm research for user trajectory matching across social media networks based on paragraph2vec[C]//International Conference on Advances in Materials. 2018.
[30] PerozziB, Al-RfouR,SkienaS. Deepwalk: Online Learning of Social Representations[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, 2014:701-710.
[31] 李付琛.基于時空轨迹的位置表示学习方法研究[D].北京:北京交通大学,2019.
[32] 赵蕾. 基于行为轨迹数据的用户网络构建及演化分析[D].青岛:山东科技大学,2018.
【通联编辑:代影】