复杂场景下基于特征融合的车辆跟踪
2020-12-14赵春晖
赵春晖, 任 杰, 宿 南
(哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001)
智能化交通是计算机视觉中最基本、最具挑战性的任务之一.车辆跟踪是智能化交通的重要组成部分,其应用场景广泛,能够保护城市公共安全,对违规、逃逸车辆进行及时跟踪和抓捕,是保持城市交通畅通的有力手段.但在跟踪过程中,受到恶劣天气、环境污染、黑夜等复杂的拍摄场景影响,导致目标与背景相似、局部遮挡、背景模糊、光线变化等诸多问题,使得在跟踪过程中出现漂移,给车辆跟踪增加了难度.所以设计一个具有高性能的车辆跟踪器是有挑战性的[1].
近几年,为解决目标跟踪问题,出现了多种基于深度卷积网络的实时跟踪器.孪生网络就是其中的重要分支,其本质是将目标跟踪建模为一个相似性比较的问题[2].这种方法不需要或几乎不需要在线训练,能够节省大量时间、确保跟踪器的实时性.最先使用孪生网络框架的是SINT(基于孪生实例搜索的跟踪)算法,在一个图像中抽取非常多的候选目标,将所有候选目标经过同一个网络去和初始帧作比较,选择距离最小的就是目标的位置,该方法操作简单,但耗时长、速度慢.2016年提出的SiamFC算法[3]引入了全连接层,通过滑窗去做卷积,大大减少了计算时间,提高了跟踪速度.但是其特征提取网络简单,没有模型更新模块,导致跟踪精确度及鲁棒性降低.2018年提出的SA-Siam[4](用于实时目标跟踪的双分支孪生网络)利用双重孪生网络和通道注意力机制提高跟踪器的泛化能力.2019年提出的SiamRPN++(基于极深孪生视觉跟踪网络的演变)算法[5],将ResNet[6](残差网络)作为特征提取网络,提高了获取语义特征的能力及跟踪精度.通过以上方法可以看出,孪生网络因为有较好的实时性,在视觉目标跟踪领域被广泛应用.
本文算法主要针对SiamFC跟踪器存在的特征提取网络简单、无法解决复杂场景下目标与背景相似、没有模型更新导致跟踪器的鲁棒性差等问题进行改进.首先,本文算法在孪生网络的框架下提出利用VGG16网络的covn4-2(第4个卷积的第2层)、covn4-3(第4个卷积的第3层)和FC1(全卷积的第1层)、FC2(全卷积的第2层)这2组卷积层,用特征融合的方式,分别对初始图片和搜索图片提取目标的表观特征和语义特征,确保特征的复杂度和多样性.其次,对表观特征和语义特征进行权重分配,获得更完善的特征图,可以更有效地解决目标与背景相似的问题.最后,通过不断试验的方法,观察在不同相似度时本文算法的成功率和精确度,找到成功率和精确度达到最高值的点,确定所在位置的相似度,作为模型更新的阈值,每当相似度达到阈值时,对模型更新一次,既可以避免重复更新又能提高整体算法的鲁棒性.
1 本文算法
图1给出了本文算法的整体流程图.算法步骤如下:①利用VGG16网络的covn4-2、covn4-3和FC1、FC2这2组卷积层,通过特征融合的方式获取目标的表观特征和语义特征;②对获取到的表观特征和语义特征进行加权平均,得到整体特征图;③对初始图片和搜索图片的整体特征图进行相似性比较,找出相似度最大的位置,就是搜索图片中目标所在的位置;④确定位置之后,判断相似度是否小于0.89,如果是就要进行模型更新,用当前帧的图片替换掉初始图片,再进行下一帧图片的跟踪,反之,则直接进行下一帧图片的跟踪;⑤重复以上步骤直到视频的最后一帧结束.
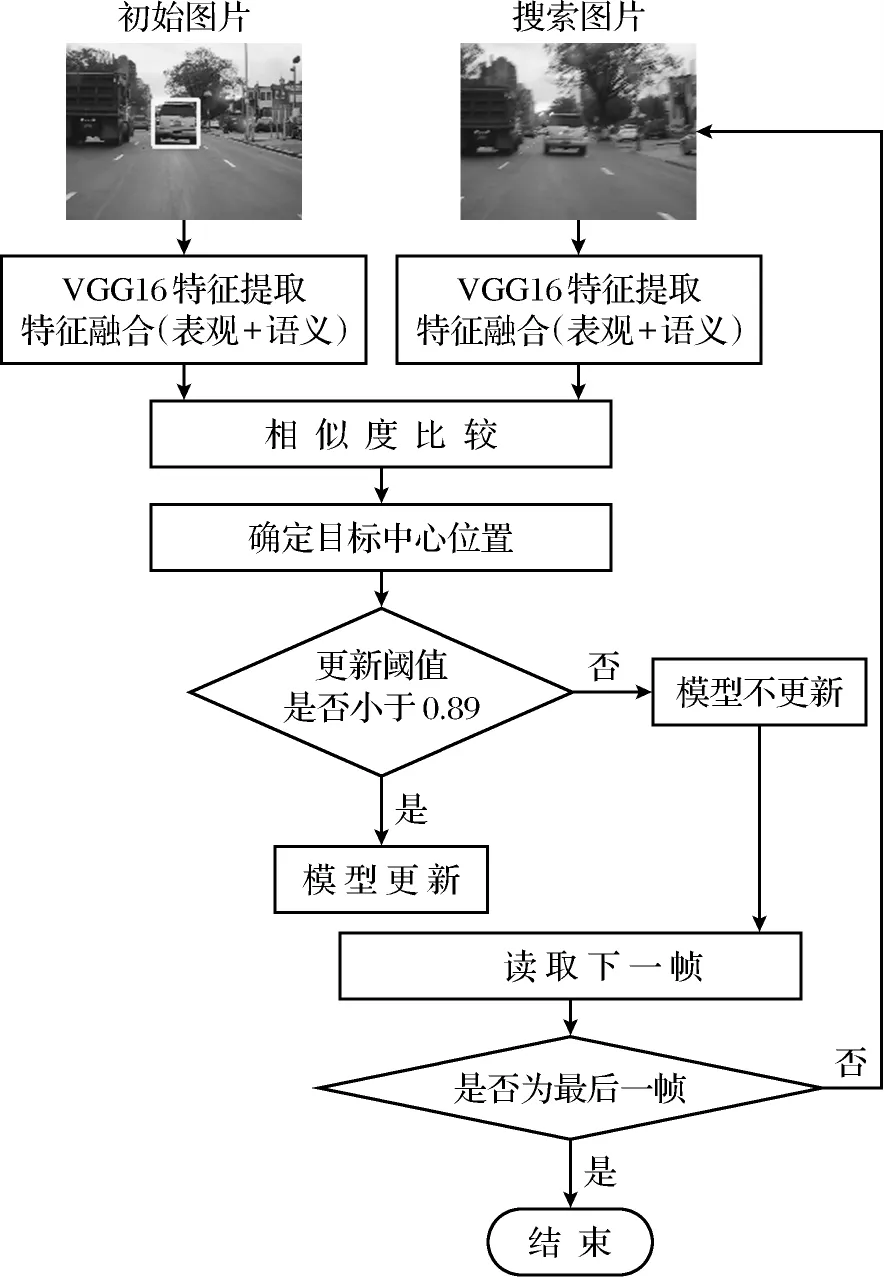
图1 本文算法整体流程Fig.1 Overall flow chart of the proposed algorithm
1.1 特征提取
SiamFC是将孪生网络用在视觉跟踪上,并且得到了具有很强实时性的视觉跟踪算法.SiamFC在初始离线阶段把CNN看成一个相似性学习问题,然后在跟踪时对相似性问题在线进行简单估计.用AlexNet[7]网络进行特征提取,引入了全连接层的结构,通过计算2个输入的互相关和插值,可以得到有效的滑动窗口估计.在VOT2016[8]的视觉跟踪视频数据集上进行了端到端的测试,算法非常简单,实时性强,在多个数据集上达到最优的性能.但是SiamFC中特征提取模块的网络简单,不能获取更深层次和多样性的特征,泛化能力弱,不能解决目标与背景相似的问题.
本文算法的特征提取网络由2个分支组成,专注于不同类型的CNN特征.因为不同层上的CNN特征可以针对不同的跟踪问题,对单目标跟踪使用所有特征既没有效率也没有效果,所以可以利用CNN的不同层特性来制作一个强大的跟踪器.首先本文采用稀疏表示的方法[9]分析每层输出的特征图谱,观察不同层的CNN特征能够表达不同水平的目标特征.越深层的特征越抽象,并且具有语义信息,对于形变,目标与背景相似,具有很强的鲁棒性.而浅层的特征更多的是局部特征,可以描述目标的外观信息.车辆跟踪过程中,其实质是从众多背景中区分出变化的目标物体,将语义特征与表观特征互补结合,用一个语义分支过滤掉背景,同时用一个表观特征分支来泛化目标的变化,如果一个物体被语义分支判定为不是背景,并且被表观特征分支判断为该物体由目标物体变化而来,即可认为这就是需要被跟踪的车辆.因此本文算法以孪生网络框架在确保跟踪过程能够保证实时性的条件下,使用VGG16网络分别输出covn4-2、covn4-3这2个卷积层的特征和FC1、FC2这2个卷积层的特征.在covn4-2、covn4-3和FC1、FC2两组网络层特征提取之后插入一个完整的融合模块,也就是加入了一个1*1的卷积和,使得covn4-2和covn4-3的特征融合到一起,获取目标的表观特征;FC1和FC2的特征融合到一起,获取目标的语义特征.通过改进的特征提取网络后,利用上采样处理 FC1、FC2输出特征图,使其与 covn4-2、covn4-3层的特征图尺寸大小相同.最后,对获取到的表观特征和语义特征进行权重分配,原因是语义特征对区分目标与背景的变化具有较强的鲁棒性,使跟踪器更通用.为了增强语义分支的识别能力,本文算法添加了加权平均模块进行权重分配,所以整体特征图是由语义特征和表观特征2个分支的加权平均构成的,公式为
式中:φ()表示特征提取;φ(x)表示初始图片的整体特征;φ(z)表示搜索图片的整体特征;φ(s)、φ(s*)分别是初始图片和搜索图片的语义特征;φ(a)、φ(a*)分别是初始图片和搜索图片的表观特征;λ为平衡语义特征和表观特征2个分支重要性的权重参数.在试验中,λ的大小是由训练集估计得到的,训练次数越多,所得到的值越准确,这就是利用VGG16网络通过特征融合获取表观特征和语义特征进行特征提取的全过程.
1.2 相似性比较
目标跟踪问题可以表示为回归问题,公式为
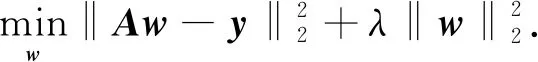
(3)
式中:矩阵A代表训练样本的特征向量;向量y是对应的标签;‖‖2代表L2正则化;向量w为最优滤波器,
w=(ATA+λI)-1ATy.
(4)
由于逆矩阵的计算需要很高的计算代价,直接使用式(4)进行目标跟踪比较困难.上述问题也可以用对偶形式求解,
w=ATα.
(5)
由式(5)可以看出,对偶形式将特征表示与判别器学习分开,α反映了判别器部分.对于基于回归的跟踪算法,如KCF[10](基于核相关滤波器的视觉跟踪)算法、ECO[11]、C-COT[12],核心问题是如何学习α的估计.
作为对比,在孪生网络跟踪器中是学习一个函数f(z,x)来比较大小相同的初始图像和搜索图像的特征x和特征z.通过比较初始图像和搜索图像中所有的候选框之间的相关性来实现,其公式为
f(z,x)=φ(z)*φ(x)+b1.
(6)
式中:z为搜索图片;x为初始图片;φ()为特征提取;*为互相关;b1为每个像素点的信号值.
通过式(6)可以看出孪生网络中的视觉目标跟踪的核心问题是相似性的比较.比较初始图片和搜索图片特征图的相似性大小,如果2个图像描述相同的对象,则返回一个高分,反之,则返回一个低分.为了找到物体在搜索图像中的位置,本文利用了快速滑窗技术,在搜索图片中生成多个候选框,对初始图片的标准框与所有候选框进行详尽的测试,并选择与初始图片最相似的候选框的位置,作为目标在搜索图片中的新位置.
1.3 模型更新阈值优化
在车辆跟踪过程中目标所处的环境在不断地变化, 目标也发生或多或少的变化, 因此一直用第一帧作为对比图片, 容易造成精确度下降. SaimFC算法因为没有添加模型更新模块, 导致跟踪效果随着时间的增长而变差. 但是如果每次对比之后都更新, 容易引入噪声等干扰信息,降低成功率. 本文利用重复试验的方法, 分别在相似度为98%、96%、94%、92%、90%、89%、88%、87%、86%、85%时进行一次模型更新, 记录相应的速度、成功率、精确度. 如表1所示,为方便阈值确定,将相似度的百分制换算成小数制. 可以发现,当相似度为0.89时,精确度和成功率最高, 相似度大于或小于0.89,精确度和成功率都会有不同程度的下降, 说明在相似度为0.89时进行一次模型更新是最有效的. 所以将相似度为0.89作为模型更新的阈值, 这样既节省了重复多次更新所用的时间, 也提高了算法整体的精确度和鲁棒性.
2 试 验
为了验证本文算法的工作效率,采用KITTI[13]公开的车辆运动视频数据集及LaSOT[14]中20段车辆运动视频,其中包含了目标与背景相似、局部遮挡、形变、快速运动、背景杂乱、光照变化等多种目标跟踪过程中可能出现的复杂情况,采用了分组对比的方法对进行详细的分析.
2.1 评价指标和算法参数
本试验采用2个标准评价指标[15]:①成功率是计算跟踪成功视频所占视频的比例,就是对于每帧图片,计算被跟踪图片中的候选框和groundtruth(标准框)之间的IoU(重叠度),通过评估不同IoU阈值下的成功率,可以得到一个成功率曲线图;②精确度是跟踪目标的中心位置和手工标定的准确位置之间的平均欧氏距离,就是一个序列中所有帧像素之间的平均中心位置误差,通过评估不同像素阈值下的精确度,可以得到一个精确度曲线图.这2个指标都可以根据AUC(曲线下面积)的大小来判断算法的效果,AUC越大效果越好.
在训练阶段采用了ILSVRC15的数据集对VGG16网络进行了预训练,采用了随机梯度下降的优化算法,用高斯分布初始化参数,训练50个epoch(循环),每个epoch有5万个样本,学习率从10-1降到10-7,语义特征和表观特征的权重分配是7∶3,模型更新阈值为0.89,其他参数与VGG16预训练网络中的参数相同.
2.2 与Siam FC算法的对比试验
本文算法是在SiamFC算法的基础上,对SiamFC算法中存在的特征提取网络简单、无模型更新模块这2个问题进行改进,所以将本文算法中只包含利用特征融合进行特征提取这一单一模块的算法命名为Ours-1,将利用特征融合进行特征提取和模型更新2个模块结合的算法命名为Ours-2,分别与SiamFC算法进行比较.表2是各算法的评价指标,Ours-1相对于SiamFC算法,其成功率提高了0.118,精确度提高了0.086,说明加入特征融合模块后算法的总体性能得到提高;Ours-2与SiamFC比较,其成功率提高了0.140,精确度提高了0.117,3种算法的速度没有太大的差别,说明加入特征融合和模型更新模块之后的算法在保证实时性的条件下,提高了跟踪算法的精确度及鲁棒性.
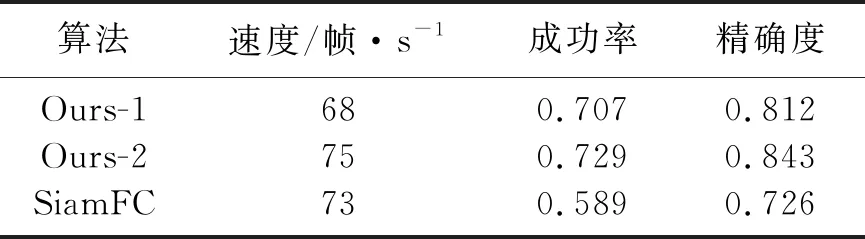
表2 各算法的评价指标Table 2 Evaluation indicators of each algorithm
图2是本文算法与SiamFC算法的跟踪效果视频序列,分为3组,分别是清晰场景、阴天、黑夜,每一组的第一行为SiamFC,第二行为本文算法,可以看到SiamFC算法在清晰场景视频中跟踪效果很好,而在阴天、黑夜这些目标与背景相似的复杂场景,就会出现跟踪框在不停的抖动甚至脱离目标的情况.本文算法无论是在清晰还是复杂场景的视频中都能准确确定目标位置,没有出现漂移或抖动的情况.说明本文算法能够解决由阴雨天、黑夜等复杂的拍摄场景导致的目标与背景相似的问题.

(a) 清晰场景(b) 阴天(c) 黑夜
2.3 不同复杂场景下多种孪生算法对比试验
为了确保本文算法的稳定性,本文算法与同样以孪生网络为框架的7个优秀算法SINT[1]、CFNet[16]、DCFNet[17](用于视觉跟踪的判别相关滤波器网络)、DSiam[18](学习动态孪生网络的视觉跟踪算法)、SINT++[19](基于对抗性正实例生成的跟踪算法)、CREST[20](基于卷积残差学习的跟踪算法)、RASNet[21](基于残差注意力孪生网络的在线视觉目标跟踪)进行比较.各算法在车辆跟踪视频上的跟踪性能如表3所示,从表3中可以看到,本文算法(Ours)的精确度为0.843,位列于所有算法的第3位,成功率为0.729,位列于所有算法的第1名.与SINT相比精确度提高了7.5%,成功率提高了15.5%;与DCFNet相比精确度提高了31.6%,成功率提高了29.3%.总体的跟踪性能在所有对比算法中名列前茅,在具有较高跟踪性能的同时保证了算法的实时性.

表3 各算法的性能Table 3 Performance of each algorithm
为了便于观察,图3(见封3)中显示了跟踪性能存在差异的4种算法(Ours、SINT++、RASNe、DCFNet)的跟踪效果视频序列,验证各种算法在阴天、黑夜、雪天、雾霾天、雨天这些受到外界影响导致的复杂的视频场景下的跟踪情况.图3中红色框为本文算法的检测结果.可以看到在各种复杂场景和外界干扰下,本文算法的跟踪框依然紧紧地贴合目标车辆,实现准确跟踪,而其他算法均有不同程度的位置偏移.可以看出本文算法不仅可以解决由复杂拍摄场景造成的目标与背景相似的问题,还具有很强的鲁棒性.
3 结 论
针对复杂场景下车辆跟踪问题,本文提出了以孪生网络为框架用特征融合实现目标跟踪的算法,利用了语义特征和表观特征的互补,解决复杂场景中目标与背景相似的问题.此外,本文还设计了更新阈值参数优化模型来实现算法的间隔更新,从而提高跟踪算法的鲁棒性.试验结果表明,本文所提算法在公开的车辆视频数据集上的表现要远远好于其他实时跟踪算法.
